Комп'ютерний кластер
Комп'ютерний кластер або просто кла́стер — це декілька незалежних обчислювальних машин, що використовуються спільно і працюють як одна система для вирішення тих чи інших задач, наприклад, для підвищення продуктивності, забезпечення надійності, спрощення адміністрування тощо. Обчислювальний кластер потрібен для збільшення швидкості обрахунків за допомогою паралельних обчислень.

Визначення
У системах оброблення інформації:
- описувач абстрактного типу даних;
- підмножина об'єктів з певними наборами ознак;
- група алгоритмічно ідентичних розрахунків;
- група накопичувачів на магнітному носію, відеопристроїв або терміналів з загальним контролером.
Один з перших архітекторів кластерної технології Грегорі Пфістер дав кластеру наступне визначення: «Кластер — це різновид паралельної або розподіленої системи, яка:
- складається з декількох зв'язаних між собою комп'ютерів;
- використовується як єдиний, уніфікований комп'ютерний ресурс».
Зазвичай розрізняють наступні основні види кластерів:
- відмовостійкі кластери (High-availability clusters, HA, кластери високої доступності)
- кластери з балансуванням навантаження (Load balancing clusters)
- обчислювальні кластери (High perfomance computing clusters)
- grid-системи
В інформаційних технологіях використовуються також наступні визначення поняття «кластер»:
- Кластер — підмножина результатів пошуку, зв'язаних єдністю теми.
- Кластер — одиниця зберігання даних на гнучких і жорстких дисках комп'ютерів.
- Кластер — група комп'ютерів, об'єднаних високошвидкісними каналами зв'язку, і що представляє з точки зору користувача єдиний апаратний ресурс.
- Кластер — група серверів, об'єднаних логічно, здатних обробляти ідентичні запити, і що використовуються як єдиний ресурс.
- Кластер — об'єкт, що забезпечує фізично об'єднане зберігання даних з різних таблиць для прискорення виконання складних запитів, використовуваний в Oracle Database.
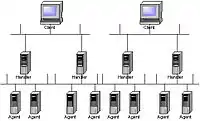
Обчислювальний кластер — це масив серверів, об'єднаних деякою комунікаційною мережею. Кожний обчислювальний вузол має свою оперативну пам'ять і працює під керуванням своєї операційної системи.
Архітектура кластера
Найпоширенішим є використання однорідних кластерів, тобто таких, де всі вузли абсолютно однакові по своїй архітектурі й продуктивності.
Для кожного кластера є виділений сервер — керуючий вузол (frontend). На цьому комп'ютері встановлене програмне забезпечення, яке активізує обчислювальні вузли при старті системи й управляє запуском програм на кластері.
Властиво обчислювальні процеси користувачів запускаються на обчислювальних вузлах, причому вони розподіляються так, що на кожний процесор доводиться не більш одного обчислювального процесу.
Користувачі мають домашні каталоги на сервері доступу — шлюзі (цей сервер забезпечує зв'язок кластера із зовнішнім світом через корпоративну мережу або Інтернет), безпосередній доступ користувачів на керуючий вузол виключається, а доступ на обчислювальні вузли кластера можливий (наприклад, для ручного керування компіляцією завдання).
Обчислювальний кластер, як правило, працює під керуванням однієї з різновидів ОС Unix — багатокористувацької багатозадачної мережевої операційної системи. Зокрема, в ІК НАН України кластери працюють під керуванням ОС Linux — вільно розповсюджуваного варіанта Unix.
Використання
Існує декілька способів зайняти обчислювальні потужності кластера:
- Запускання багатьох однопроцесорних завдань. Це може бути сприятливим варіантом, якщо потрібно провести багато незалежних обчислювальних експериментів з різними вхідними даними, причому час проведення кожного окремого розрахунків не має значення, а всі дані розміщаються в об'ємі пам'яті, доступному одному процесу.
- Запускати готові паралельні програми. Для деяких завдань доступні безкоштовні або комерційні паралельні програми, які при необхідності Ви можете використовувати на кластері. Як правило, для цього досить, щоб програма була доступна у вихідних текстах, реалізована з використанням інтерфейсу MPI на мовах C/C++ або Фортран.
- Викликати у своїх програмах паралельні бібліотеки. Для деяких областей, наприклад, лінійна алгебра, доступні бібліотеки, які дозволяють вирішувати широке коло стандартних підзадач з використанням можливостей паралельної обробки. Якщо звертання до таких підзадач становить більшу частину обчислювальних операцій програми, то використання такої паралельної бібліотеки дозволить одержати паралельну програму практично без написання власного паралельного коду. Прикладом такої бібліотеки є ScaLAPACK, яка доступна в стандартних дистрибутивах Linux.
- Створювати власні паралельні програми. Це найбільш трудомісткий, але й найбільш універсальний спосіб. Існує кілька варіантів такої роботи, зокрема, вставляти паралельні конструкції в готові послідовні програми або створювати з «нуля» паралельну програму.
Програмне забезпечення
Паралельні програми на обчислювальному кластері працюють у моделі передачі повідомлень — message passing. Це значить, що, хоч програма складається з багатьох процесів, кожен з яких працює на своєму процесорі й має власний захищений адресний простір, ці процеси можуть обмінюватися повідомленнями за допомогою структур операційної системи, таких як семафори та спільно використовувана пам'ять. Тобто процес, який повинен одержати дані, викликає операцію receive (прийняти повідомлення), і вказує, від якого саме процесу він повинен одержати дані, а процес, який повинен передати дані іншому, викликає операцію send (послати повідомлення) і вказує, якому саме процесу потрібно передати ці дані.
Цю модель реалізує, поміж інших, стандартний інтерфейс MPI. Існує кілька реалізацій MPI, у тому числі безкоштовні й комерційні, переміщені й орієнтовані на конкретну комунікаційну мережу. На кластерах СКІТ-1 та СКІТ-2 використовується комерційна реалізація Scali (для мережного з'єднання через SCI) і безкоштовна Open MPI (для мережного з'єднання через Infiniband).
Як правило, MPI-програми побудовані по моделі SIMD (single instruction — multiple data), тобто для всіх процесів є тільки один код програми, а різні процеси зберігають різні дані й виконують свої дії залежно від порядкового номера процесу.
Для прискорення роботи паралельних програм варто прийняти заходи для зниження накладних витрат на синхронізацію при обміні даними. Можливо, прийнятним підходом виявиться сполучення асинхронних пересилань і обчислень.
Для виключення простою окремих процесорів потрібно найбільш рівномірно розподілити обчислення між процесами, причому в деяких випадках може знадобитися динамічне балансування. Важливим показником, який говорить про те, чи ефективно в програмі реалізований паралелізм, є завантаження обчислювальних вузлів, на яких працює програма.
Якщо завантаження на всіх або на частині вузлів далеке від 100 % — виходить, програма неефективно використовує обчислювальні ресурси, тобто створює більші накладні витрати на обміни даними або нерівномірно розподіляє обчислення між процесами. Користувачі СКІТ-1 і СКІТ-2 можуть подивитися завантаження через веб-інтерфейс для перегляду стану вузлів.
В деяких випадках для розуміння, в чому причина низької продуктивності програми і які саме місця в програмі необхідно модифікувати, щоб добитися збільшення продуктивності, має сенс використовувати спеціальні засоби аналізу продуктивності — профіліровщики і трасувальники.
Призначення
Обчислювальний кластер, як і будь-яка система паралельних обчислень, є ефективним, коли обчислювальна задача, яку необхідно вирішити, принципово не може бути вирішена за допомогою комп'ютерів широкого вжитку (наприклад, персональних комп'ютерів), або вирішення задачі за допомогою поширених систем вимагає тривалого часу. До таких задач належать:
- Задачі, що «не вміщуються» в оперативну пам'ять (вимагають десятки гігабайт і більше)
- Обчислення, що вимагають значної кількості операцій і відповідно тривалого часу (дні, тижні, місяці)
- Коли потрібно обрахувати велику кількість задач (десятки, сотні) за короткий проміжок часу
- Кластер є ефективним не для всіх задач. Якщо задача ефективно вирішується за допомогою поширених систем, то використання кластеру може бути неефективним.
Чому потрібен кластер?
Основна мета використання кластера — забезпечення високої доступності бази даних. Сьогодні для додатків все частіше висуваються такі бізнес-вимоги, щоб був забезпечений доступ до даних в режимі 24 години на добу 7 днів на тиждень, і недоступність бази даних в зв'язку з будь-якими причинами часто просто неприпустима. Використання кластера серверів баз даних може допомогти запобігти недоступності даних через вихід з ладу сервера, викликаного збоєм у програмному забезпеченні, необхідністю виконання операцій з обслуговування сервера або через втрату мережного з'єднання з сервером. Однак кластер не гарантує, що ніколи не відбудеться відмова сервера, він допомагає зменшувати число виходів з ладу і надає адміністраторам бази даних і сервера можливості вивести сервер зі стану відмови без втрат.
Класифікація кластерів
Кластери високої доступності
Позначаються абревіатурою HA (англ. High Availability — висока доступність). Створюються для забезпечення високої доступності сервісу, що надається кластером. Надмірна кількість вузлів, що входять в кластер, гарантує надання сервісу у разі відмови одного або декількох серверів. Типове число вузлів — два, це мінімальна кількість, що приводить до підвищення доступності. Створено безліч програмних рішень для побудови такого роду кластерів.
Відмовостійкі кластери та системи взагалі будуються по трьом основним принципам:
- З холодним резервом або активний / пасивний. Активний вузол виконує запити, а пасивний чекає його відмови і включається в роботу, коли така відбудеться. Приклад — резервні мережеві з'єднання, зокрема, алгоритм зв'язуючого дерева. Наприклад зв'язку DRBD та HeartBeat.
- З гарячим резервом або активний / активний. Всі вузли виконують запити, в разі відмови одного навантаження перерозподіляється між рештою. Тобто кластер розподілення навантаження з підтримкою перерозподілу запитів при відмові. Прикладами є практично всі кластерні технології, наприклад, Microsoft Cluster Server, OpenSource проект openMosix.
- З модульною надмірністю. Застосовується тільки у випадку, коли простій системи абсолютно неприпустимий. Всі вузли одночасно виконують один і той же запит (або частини його, але так, що результат досяжний і при відмові будь-якого вузла), з результатів береться будь-який. Необхідно гарантувати, що результати різних вузлів завжди будуть однакові (або відмінності гарантовано не вплинуть на подальшу роботу). Приклади — RAID та Triple modular redundancy.
Конкретна технологія може поєднувати дані принципи в будь-якій комбінації. Наприклад, Linux-HA підтримує режим обопільної поглинаючої конфігурації (англ. takeover), в якому критичні запити виконуються усіма вузлами разом, інші ж рівномірно розподіляються між ними.
Кластери розподілу навантаження
Принцип їх дії будується на розподілі запитів через один або кілька вхідних вузлів, які перенаправляють їх на обробку в інші, обчислювальні вузли. Початкова мета такого кластера — продуктивність, однак, у них часто використовуються також і методи, що підвищують надійність. Подібні конструкції називаються серверними фермами. Програмне забезпечення (ПЗ) може бути як комерційним (OpenVMS, MOSIX, Platform LSF HPC, Solaris Cluster Моава Cluster Suite, Maui кластера Scheduler), так і безкоштовним (openMosix, Oracle Grid Engine, Linux Virtual Server).
Обчислювальні кластери
Кластери використовуються в обчислювальних цілях, зокрема в наукових дослідженнях. Для обчислювальних кластерів вагомими показниками є висока продуктивність процесора в операціях над числами з рухомою комою (flops) і низька латентність об'єднувальної мережі, і менш вагомими — швидкість операцій введення-виведення, яка більшою мірою важлива для баз даних та web-сервісів. Обчислювальні кластери дозволяють зменшити час розрахунків, порівняно з одиночним комп'ютером, розбиваючи завдання на паралельно виконувані гілки, які обмінюються даними через мережу. Одна з типових конфігурацій — набір комп'ютерів, зібраних із загальнодоступних компонентів, з встановленою на них операційною системою Linux, і пов'язаних мережею Ethernet, Myrinet, InfiniBand або іншими відносно недорогими мережами. Таку систему прийнято називати кластером Beowulf.
Окремо виділяють високопродуктивні кластери (позначаються англ. абревіатурою HPC Cluster — High-performance computing cluster). Список найпотужніших високопродуктивних комп'ютерів (також може позначатися англ. абревіатурою HPC) можна знайти в світовому рейтингу ТОП500.
Системи розподілених обчислень
Такі системи не прийнято вважати кластерами, але їх принципи в значній мірі схожі з кластерною технологією. Їх також називають grid-системами. Головна відмінність — низька доступність кожного вузла, тобто неможливість гарантувати його роботу в заданий момент часу (вузли підключаються і відключаються в процесі роботи), тому завдання повинне бути розбите на ряд незалежних один від одного процесів. Така система, на відміну від кластерів, не схожа на єдиний комп'ютер, а служить спрощеним засобом розподілу обчислень. Нестабільність конфігурації, в такому випадку, компенсується великим числом вузлів.
Кластер серверів, організованих програмно
Кластер серверів (в інформаційних технологіях) — група серверів, об'єднаних логічно, здатних обробляти ідентичні запит и і використовуються як єдиний ресурс. Найчастіше сервери групуються за допомогою локальної мережі. Група серверів володіє більшою надійністю і більшою продуктивністю, ніж один сервер. Об'єднання серверів в один ресурс відбувається на рівні програмних протоколів.
На відміну від апаратного кластера комп'ютерів, кластери організовувані програмно, вимагають:
- Наявності спеціального програмного модуля (Cluster Manager), основною функцією якого є підтримка взаємодії між усіма серверами — членами кластеру:
- Синхронізації даних між усіма серверами — членами кластеру;
- Розподіл навантаження (клієнтських запитів) між серверами — членами кластеру;
- Від уміння клієнтського програмного забезпечення розпізнавати сервер, що являє собою кластер серверів, і відповідним чином обробляти команди від Cluster Manager;
- Якщо клієнтська програма не вміє розпізнавати кластер, вона буде працювати тільки з тим сервером, до якого звернулася спочатку, а при спробі Cluster Manager перерозподілити запит на інші сервери, клієнтська програма може взагалі позбутися доступу до цього сервера (результат залежить від конкретної реалізації кластера).
Типи кластерів
Служба кластера Windows пропонує кілька різних типів і режимів роботи кластера:
- кластер з одним вузлом;
- кілька вузлів в кластері;
- мажоритарна група вузлів (Majority NodeSet) кластера;
- кластер з географічно рознесеними вузлами.
Найширшого використання набули два перші типи кластерів. Розглянемо їх принципи.
Кластер одного вузла
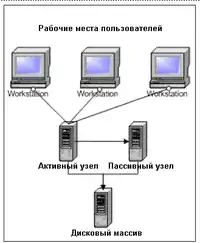
Кластер з одного вузла — це така кластерна конфігурація, в якій активний тільки один сервер, а ще один або кілька серверів «неактивні». Неактивний сервер — це такий сервер, на якому немає активних (таких, що виконуються) додатків, але операційна система запущена. Неактивний сервер «чекає», коли активний сервер потрапить у неактивний стан, що зазвичай викликано виходом обладнання або програмного забезпечення з ладу. В такому випадку неактивний сервер стає активним і починає сам обслуговувати додаток, що обслуговувався попереднім активним сервером. При цьому всі необхідні додаткам ресурси передаються для монопольного управління новому активному серверу, у той час як всі підключення, які існували на старому активному сервері, повторно переустановлюються з новим активним сервером.
Кластер декількох вузлів
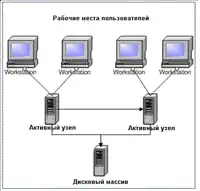
Такий кластер може включати від двох до восьми активних серверів, які працюють в одній кластерної групі. Всі ці активні сервери обслуговують свої додатки і кожен зайнятий своєю роботою. Кожен активний сервер може бути налаштований хостом додатків для одного або декількох інших активних серверів, в разі їх відмови, кожен активний сервер можна налаштувати так, щоб він використав один активний або неактивний сервер як хост додатків, якщо відбудеться відмова.
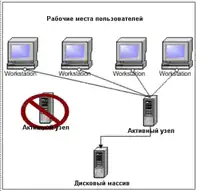
Кластери з декількох вузлів дозволяють адміністраторам використовувати всі або тільки частину ресурсів кожного сервера у групі кластера. Працюючи з таким кластером потрібно бути гранично обережним, оскільки робота серверів будується так, що сервер може не тільки бути запасним хостом для іншого сервера, але він також повинен обслуговувати і свої власні програми.
Примітки
Посилання
- Обчислювальний кластер Київського національного університету ім. Т. Г. Шевченка
- Конференція «Кластерні обчислення 2013»