Мови паралельного програмування
Процес розробки паралельної[уточнити] програми відрізняється від процесу розробки послідовної програми. Необхідно попередньо проаналізувати і виявити ті фрагменти програми, які займають найбільше процесорного часу — саме їх розпаралелення дозволяє підвищити швидкість виконання програми.[джерело?] Розпаралелення зв'язане з виявленням підзадач, розв'язання яких можна доручити різним процесорам. Вимагається організація взаємодії між такими підзадачами, що можна зробити шляхом обміну повідомленнями-посилками[джерело?] (містять вхідні дані, проміжні і кінцеві результати роботи). Спеціальні прийоми вимагаються і при відлагодженні паралельної програми.
На ефективність розробки програм впливає і наявність відповідного програмного інструментарію. Розробнику паралельних програм необхідні засоби аналізу і виявлення паралелізму, транслятори, операційні системи (ОС), які забезпечують надійну роботу багатопроцесорних конфігурацій. Необхідні також засоби відлагодження і профілювання (побудова каркаса програми, прив'язаного до часових параметрів, що дозволяє оцінити продуктивність програми та окремих її частин). Середовищем виконання паралельних програм є ОС, які підтримують мультипроцесування, багатозадачність і багатопотоковість.
При розпаралеленні, яке ведеться на рівні алгоритмів необхідно виміряти часові параметри, визначити необхідну кількість пересилань та необхідні об'єми пам'яті.[джерело?] Засоби відлагодження повинні забезпечити можливість безтупикової перевірки програм.
Класифікація мов і систем паралельного програмування
Вибір технології паралельного програмування є складним завданням. Мов і систем розробки паралельних програм є[коли?] понад 100 і їх кількість невпинно зростає. Відповідно до цього є різні підходи до їх узагальнення і класифікації.
Паралельні мови та системи програмування можна розкласифікувати за такими видами:
- Для систем зі спільною пам'яттю: OpenMP, Linda, Orca, Java, Pthreads, Opus, SDL, Ease, SHMEM, CSP, NESL.
- Для систем з розподіленою пам'яттю: PVM, MPI, HPF, Cilk, C, ZPL, Occam, Concurrent C, Ada, FORTRAN M, sC++, pC++.
- Паралельні об'єктно-орієнтовані: HPC++, MPL, CA, Distributed Java, Charm++, Concurrent Aggregates, Argus, Presto, Nexus, uC++.
- Паралельні декларативні: Parlog, Multilisp, Sisal, Concurrent Prolog, GHC, Strand, Tempo.
Деякі мови паралельного програмування машинно-залежні і створені для конкретних систем. Використовуються і універсальні мови програмування високого рівня, такі як сучасні версії мови FORTRAN і мова С.
FORTRAN D — розширення мови FORTRAN 77/90, за допомогою якої можна визначити машинно-незалежним чином як треба розподілити дані між процесорами. Мова дозволяє використовувати спільний простір імен. Транслятори можуть генерувати код як для SIMD, так і для MIMD-машин. FORTRAN D є попередником мови High Perfomance FORTRAN (HPF).
В мовах випереджувальних обчислень паралелізм реалізовано за допомогою паралельного виконання обчислень ще до того, як їх результат потрібний для продовження виконання програми. Прикладами таких мов є: MultiLisp — паралельна версія мови Lisp, QLisp, Mul-T.
Мови програмування в моделі паралелізму даних: С, APL, UC, HPL. PARLOG є паралельною версією мови Prolog. Erlang — паралельна мова для застосувань в режимі реального часу. Elixir — паралельна мова для застосувань в режимі реального часу, побудована на Erlang VM. Maisie — мова, яка базується на С. Scheme — один з діалектів Lisp. Cilk — алгоритмічна багатопотокова мова.
Середовища розробки паралельних програм: aCe — середовище розробки і виконання програм в рамках моделі паралельних даних. ADAPTOR — система основана на мові HPF. Arjuna — об'єктно-орієнтована система програмування розподілених додатків. CODE — візуальна система паралельного програмування.
При розробці паралельних програм в рамках моделі паралелізму задач найчастіше використовуються спеціалізовані бібліотеки і системи паралельного програмування PVM і MPI. PVM існує для різних платформ, є реалізації для мов Java і Python, і включає різні засоби створення паралельних програм.
Особливості організації паралельної програми
Технологія OpenMP
Стандарт OpenMP розроблений для мов FORTRAN (77, 90,95), C, C++ і підтримується практично всіма виробниками великих обчислювальних систем. Реалізація стандарту доступна як на UNIX-платформах, так і в середовищі Windows NT[1].
В стандарті за основу береться послідовна програма, а для створення її паралельної версії користувачу надається набір директив, процедур і навколишніх змінних.
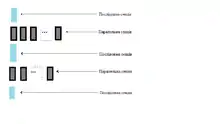
Текст програми розбивається на послідовні і паралельні області (див. рис.). В початковий момент часу породжується нитка-майстер (основна нитка), яка починає виконувати програму з стартової точки. Основна нитка, і тільки вона, виконує всі послідовні області програми. Для підтримки паралелізму використовується схема FORK/JOIN. При вході в паралельну нитку-майстер створюються додаткові нитки (виконується операція FORK). Після створення кожна нитка отримує свій унікальний номер, причому нитка-майстер завжди має номер 0. Всі створені нитки використовують однаковий код, який відповідає паралельній області. При виході з паралельної області основна нитка дочікується завершення решту ниток, і подальше виконання програми продовжує тільки вона.
В паралельній області всі змінні програми діляться на два класи: загальні (SHARED) і локальні (PRIVATE). Загальні змінні завжди існують тільки в одному екземплярі для всієї програми і доступні всім ниткам під однаковим іменем. Оголошення локальних змінних викликає створення свого екземпляра кожної змінної для кожної нитки.
Система програмування DVM
Система об'єднує моделі паралелізму за даними та керуванням, і складається з 5-ти основних компонентів: компілятори з мов FORTRAN — DVM i C — DVM, системи підтримки виконання паралельних програм, відлагоджувача паралельних програм, аналізатора продуктивності, передбачувача продуктивності.
Відображення віртуальних процесорів на фізичні здійснюється засобами операційної системи.
Для розподілення масивів використовується директива DISTRIBUTE (має описовий статус).
Для організації погодженого відображення деяких масивів використовується механізм вирівнювання одного масиву відносно іншого за допомогою директиви ALING.
Директива паралельного виконання циклів PARALLEL вбудована в мову Fortran у виді спецкоментара.
Директива MAP вбудована в мову Fortran і специфікує то, що n-а задача деякого вектора Т буде виконуватися секцією віртуальних процесорів Р(i1:i2, …,j1:j2). Всі відображені на цю задачу масиви (директива DISTRIBUTE) і обчислення (директива PARALLEL) будуть автоматично відображені на цю ж секцію віртуальних процесорів.
В DVM передбачені дві форми відображення блоків програми на задачі. Статична форма є безпосереднім аналогом паралельних секцій в інших мовах, зокрема, директиви SECTIONS в мові OpenMP. В динамічній формі ітерація циклу відображається на задачу.
Спільними даними в DVM є дані, що обчислюються на одних процесорах, а використовуються іншими.
DVM-програма може виконуватися на довільній кількості процесорів, починаючи з одного. Це є наслідком того, що директиви паралелізму в DVMне залежать ні від кількості процесорів, ні від конкретних номерів процесорів. Єдиним винятком є рівень задач. За вимогою директиви MAP користувач повинен явно описати масив віртуальних процесорів. При цьому кількість процесорів, що описані в програмі не повинен перевищити кількості процесорів, що задаються при запуску програми.
Технології паралельного програмування Message Passing Interface (MPI)
MPI - бібліотека функцій, яка забезпечує взаємодію паралельних процесів за допомогою механізму передачі повідомлень і не має ніяких засобів для розподілення процесів по обчислювальних вузлах і для запуску їх на виконання. МРІ не містить механізмів динамічного створення і знищення процесів під час виконання програми.
Для ідентифікації наборів процесів вводиться поняття групи і комунікатора.
Процеси об'єднуються в групи, можуть бути вкладені групи. Усередині групи всі процеси понумеровані. З кожною групою асоційований свій комунікатор. Тому при здійсненні пересилок необхідно вказати ідентифікатор групи, усередині якої проводиться це пересилка.
Процедури MPI:[2]
- Ініціалізація та закриття MPI-процесів;
- реалізація комутаційних операцій типу «точка-точка»;
- реалізація колективних операцій;
- для роботи з групами процесів і комунікаторами;
- для роботи з структурами даних;
- формування топології процесів.
До базових функцій MPI належать
- ініціалізація MPI;
- завершення MPI;
- визначення кількості процесів в області зв'язку;
- визначення номера процесу, який виконується;
- передача повідомлень;
- приймання повідомлень;
- функції відліку часу.
Кожна MPI — функція характеризується способом виконання:
- Локальна функція — виконується всередині процесу, що її викликав. Її завершення не вимагає комунікації.
- Нелокальна функція — для її завершення необхідно виконати MPI — процедуру іншим процесом.
- Глобальна функція — процедуру повинні виконати всі процеси групи. Невиконання цієї умови може призвести до «зависання» задачі.
- Блокуюча функція — повернення керування з процедури гарантує можливість повторного використання параметрів, які брали участь у виклику. Ніяких змін в стан процесу, що викликав блокуючий запит до виходу з процедури не може відбуватися.
- Неблокуюча функція — повернення з процедури відбувається негайно, без очікування завершення операції. Завершення неблокуючих операцій здійснюється спеціальними функціями.
Примітки
- Parallel Programming with MPI. www.cs.usfca.edu. Процитовано 30 листопада 2016.
- http://parallel.ru/docs/mpi1.1/mpi-report.html
Література
- Воеводин В. В., Воеводин Вл. В. Параллельные вычисления. — СПб: БХВ-Петербург, 2002.
- Ортега Дж. Введение в параллельные и векторные методы решения линейных систем. М.:Мир, 1991.
- Программирование на параллельных вычислительных системах: Пер с англ./Под ред. Р.Бэбба. М.:Мир, 1991.
- Бройнль Т. Паралельне програмування: Початковий курс: Навчальний посібник. — К.:Вища школа.,1997.
- Воеводин В. В. Математические основы параллельных вычислений.- М.: Изд-во МГУ, 1991.
- Векторизация программ: теория, методы, реализация: Пер. с англ. и нем. /Под ред. Г. Д. Чинина. — М:. Мир, 1991.
- Корнеев В. В. Параллельные вычислительные системы. М.: Нолидж, 1999
- С. Немнюгин, О.Стесик Параллельное программирование для многопроцессорных вычислительных систем. — СПб: БХВ-Петербург, 2002.
- Питерсон Дж. Теория сетей Петри і моделирования систем: Пер. с англ. -М.: Мир, 1984. -264 с., ил.