DPLL алгоритм
Алгоритм Девіса-Патнема-Логемана-Лавленд — це повний алгоритм пошуку з поверненням для визначення здійсненності булевих формул, записаних в кон'юнктивній нормальній формі (КНФ) для вирішення завдання CNF-SAT[1].

Алгоритм був опублікований в 1962 році Мартіном Девісом, Гіларі Патнемом, Джорджем Логеманом й Дональдом Лавленд та представляє собою удосконалення більш раннього алгоритму Девіса-Патнема, методу, заснованого на правилі резолюцій, розробленого Девісом та Патнемом в 1960 році.
DPLL — високо-ефективний алгоритм якому вже 50 років але все ще лежить в основі більшості ефективних вирішувачів для SAT, а також для систем автоматичного доведення теорем та фрагментів логіки першого порядку.
Реалізації та додатки
Завдання здійсненності булевих формул важливо як з теоретичної, так й з практичної точок зору. В теорії складності це перше завдання для якої були доведена приналежність клас NP-повні задачі. Також вона може з'являтися в самих різних практичних додатків, наприклад перевірка моделей, складання розкладів, діагностика.[2]
Даний напрямок був та залишається областю досліджень, що розвивається. Щорічно проводяться змагання між різними людьми котрі вирішують SAT[3]. Сучасні реалізації алгоритму DPLL, такі як Chaff and zChaff[4], GRASP або MINISAT[5] займають перші позиції протягом останніх років. Інший тип додатків, в яких часто використовується DPLL — це системи автоматичного доведення теорем.
Опис алгоритму
Основний алгоритм з поверненням починається з вибору змінної, присвоєння їй значення «істина», спрощення формули та потім рекурсивним чином перевірити спрощення формули на здійсненність; якщо вона здійсненна, то вихідна формула теж здійсненна. Інакше, процедура повторюється, але для обраної змінної встановлюється значення «брехня». Цей підхід називається «правилом розбивки», так як він розбиває завдання на дві більш прості підзадачі. Крок спрощення полягає в тому, що з формули дістаються всі диз'юнкти, які стають істинними після присвоєння обраній змінній значення «істина», та видалення від решти диз'юнкт всіх входжень цієї змінної зі значенням «брехні»[6].
Алгоритм DPLL дозволяє поліпшити основний алгоритм з поверненням за рахунок використання наступних правил на кожному кроці:
Поширення змінної
Якщо диз'юнкта містить рівно одну змінну, якій ще не задали значення, ця диз'юнкта може прийняти значення «істина» тільки в разі присвоєння змінній значення, яке зробить її істинною («істина», якщо змінна входить в диз'юнкт без заперечення та «брехня», якщо змінна з запереченням). Таким чином, не потрібно робити вибір на даному етапі. На практиці за цим слідує багато присвоєнь змінним значень, та через це істотно скорочується кількість варіантів перебору.
Виняток «чистих» змінних
Якщо деяка змінна входить в формулу тільки з однієї «полярністю», тобто без заперечень, або тільки з запереченнями, вона називається чистою. «Чистим» змінним завжди можна задати значення так, що всі утримуючи її диз'юнкти стануть істинними. Таким чином, ці диз'юнкти не впливатимуть на простір варіантів та їх можна буде видалити.
Нездійсненність, при даних конкретних значеннях змінних, визначається коли одна з диз'юнкт стає «порожня», тобто всім її змінним задаються значення таким чином, що їх входження стають помилковими. Здійснимість формули констатується або коли всім змінним задані значення так, що не виникає «порожніх» диз'юнкт, або (в сучасних реалізація) кожна диз'юнкта дорівнює істини. Нездійсненність формули може бути встановлена тільки після закінчення перебору. Алгоритм DPLL може бути виражений за допомогою наступного псевдокоду, де знаком Φ позначена формула в кон'юнктивній нормальній формі (КНФ):
Алгоритм DPLL
Вхідні дані: Набір диз'юнкт формули Φ.
Вихідні дані: Значення істинностіfunction DPLL(Φ)
if Φ - набір виконуваних диз'юнкт
then return true;
if Φ містить порожню диз'юнкту
then return false;
for each диз'юнкти з однією змінною l in Φ
Φ ← unit-propagate(l, Φ);
for each l яка зустрічається в "чистому" вигляді in Φ
Φ ← pure-literal-assign(l, Φ);
l ← choose-literal(Φ);
return DPLL(Φ&l) or DPLL(Φ¬(l));У цьому псевдокоді unit-propagate(l, Φ) й pure-literal-assign(l, Φ) — це функції, які повертають результат застосовуваний до змінної l в формулі Φ — поширення змінної та правила виключення «чистої змінної». Іншими словами, вони замінють кожне входження змінної lзначенням «істина» та кожне входження змінної з запереченням not l значенням «брехня» у формулі Φ, а потім спрощують результативну формулу. Наведений псевдокод повертає тільки відповідь — чи виконує формулу останній з присвоєних наборів значень чи ні. У сучасних реалізаціях, часткові виконувані набори, теж повертаються у разі успіху.
Алгоритм залежить від вибору «змінної розгалуження», тобто змінної, яка вибирається на черговому кроці алгоритму з поверненням присвоєння їй певного значення. Таким чином, це не один алгоритм, а ціле сімейство алгоритмів, по одному на кожен можливий спосіб вибору «змінних розгалуження». Ефективність алгоритму сильно залежить від цього вибору. Час роботи алгоритму (для яких може бути або рости експоненціально) в залежності від вибору «змінних розгалуження». Методи вибору — евристичні техніки, які називаються також «евристиками для розгалуження» (branching heuristics).

Візуалізація
Девіс, Логемана, Лавленд (1962) розробили цей алгоритм. Деякі властивості алгоритму:
- Він засновується для пошуку.
- Він є основою для багатьох сучасних вирішувачів SAT.
- Він не використовує джерела введено в 1996 році.
Приклад з візуалізацією алгоритму DPLL, що має хронологічні джерела:
 Всі можливі випадки КНФ формул.
Всі можливі випадки КНФ формул. Вибираємо змінну.
Вибираємо змінну.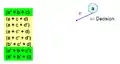 Приймаємо рішення, змінна а = False (0), таким чином, зелені положення стають True.
Приймаємо рішення, змінна а = False (0), таким чином, зелені положення стають True.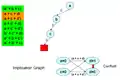 Після кількох рішень, ми знаходимо імплікаційний граф, який призводить до конфлікту.
Після кількох рішень, ми знаходимо імплікаційний граф, який призводить до конфлікту.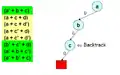 Тепер повертаємося назад та надаємо значення змінній.
Тепер повертаємося назад та надаємо значення змінній.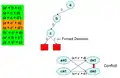 Рішення все ще приводить до іншого конфлікту.
Рішення все ще приводить до іншого конфлікту.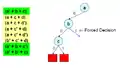 Повертаємося на попередній рівень.
Повертаємося на попередній рівень.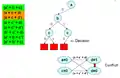 Зробили нове рішення але це призводить до конфлікту також.
Зробили нове рішення але це призводить до конфлікту також.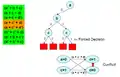 Зробили ще одне зміщення але знову це призводить до конфлікту.
Зробили ще одне зміщення але знову це призводить до конфлікту.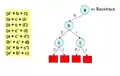 Повертаємося на попередній рівень.
Повертаємося на попередній рівень. Продовжуємо таким же чином до остаточного імплікаційного графу.
Продовжуємо таким же чином до остаточного імплікаційного графу.
Сучасні дослідження
Поточні дослідження щодо поліпшення алгоритму виконуються в трьох напрямках:
- визначення різних оптимізуючих методів вибору «змінної розгалуження»;
- розробка нових структур даних для прискорення роботи алгоритму, особливо для поширення змінної;
- розробка різних варіантів базового алгоритму перебору з поверненням.
Останній напрям включає «нехронологічні повернення» та запам'ятовування помилкових випадків. Ці поліпшення можна описати як метод повернення після досягнення помилкових диз'юнкт, при якому запам'ятовується, яке саме привласнення значення змінної спричинило цей результат, щоб в подальшому уникнути даремних обчислень, тим самим скоротити час роботи.
Новіший алгоритм — метод Сталмарка — відомий з 1990 року, використовується для вирішення задачі SAT. На основі DPLL-алгоритму в середині 1990-х був створений CDCL-алгоритм.
Зв'язок з іншими
Алгоритми DPLL оснований на нездійсненних випадках котрі відповідають доказам спрощення дозволу дерева.
Див. також
- Доказ складності
- Алгоритм Чаффа
- Алгоритм Девіса-Патнема
- Поширення змінної
Посилання
- LLC, Revolvy,. "Davis–Putnam algorithm" on Revolvy.com. www.revolvy.com (англ.). Процитовано 28 квітня 2017.
- Handbook of Knowledge Representation. dai.fmph.uniba.sk (амер.). Процитовано 28 квітня 2017.
- committee, SATComp Organizing. SAT Competitions. www.satcompetition.org. Процитовано 19 квітня 2017.
- Boolean Satisfiability Research Group at Princeton. www.princeton.edu. Процитовано 19 квітня 2017.
- MiniSat Page. minisat.se. Процитовано 19 квітня 2017.
- Лекториум (24 липня 2013). DPLL алгоритм с вероятностным отсечением: оценка времени работы | Елена Иконникова | CSC | Лекториум. Процитовано 28 квітня 2017.
Література
- R. Dechter; I. Rish. «Directional Resolution: The Davis–Putnam Procedure, Revisited». In J. Doyle and E. Sandewall and P. Torasso. Principles of Knowledge Representation and Reasoning: Proc. of the Fourth International Conference (KR'94). Starswager18. pp. 134—145.
- John Harrison (2009). Handbook of practical logic and automated reasoning. Cambridge University Press. pp. 79–90. ISBN 978-0-521-89957-4.