Класифікація паралельних комп'ютерних систем
Класифікація паралельних комп'ютерних систем
Класифікація Шора
Одна з перших класифікацій комп'ютерних систем була запропонована Д. Шором на початку 70-х років. Вона цікава тим, що є спробою виділення типових способів компонування комп'ютерних систем на основі фіксованого числа базових блоків: пристрою керування, арифметико-логічного пристрою, пам'яті команд і пам'яті даних. Додатково передбачається, що вибірка з пам'яті даних може здійснюватися словами, тобто вибираються всі розряди одного слова, і/або бітовим шаром - по одному розряду з однієї і тієї ж позиції кожного слова (іноді ці два способи називають горизонтальною і вертикальною вибірками відповідно). Звичайно ж, при аналізі даної класифікації треба робити знижку на час і появи, оскільки передбачити велику різноманітність паралельних систем теперішнього часу тоді було у принципі неможливо. Отже, згідно з класифікацією Д. Шора, всі комп'ютери розбиваються на шість класів, перший з яких дістав назву машини І, другий - машини II, і т. д.
На поданих нижче рисунках позначено: ПІ - пам'ять команд (інструкцій), ПК - пристрій керування, АЛП - арифметико-логічний пристрій, ПД - пам'ять даних. Машина І - це комп'ютерна система, яка містить пристрій керування, арифметико-логічний пристрій, пам'ять команд і пам'ять даних із послівною вибіркою (рис. 1.1).
{kind=link}
Зчитування даних здійснюється вибіркою всіх розрядів деякого слова для їх паралельної обробки в арифметико-логічному пристрої. Склад АЛП спеціально не вказується, що допускає наявність декількох функціональних пристроїв, в тому числі конвеєрного типу. За цими міркуваннями до даного класу потрапляють як класичні послідовні машини (ІВМ 701, PDP-11, VAX 11/780), так і конвеєрні скалярні (CDC 7600) і векторно-конвеєрні (CRAY-1).
Якщо в машині І здійснювати вибірку не по словах, а по одному розряду з усіх слів, то одержимо машину II (рис. 1.2). Слова в пам'яті даних, як і раніше, розташовуються горизонтально, але доступ до них здійснюється інакше. Якщо в машині І відбувається послідовна обробка слів при паралельній обробці розрядів, то в машині II - послідовна обробка бітових шарів при паралельній обробці множини слів.
{kind=link}
Структура машини II лежить в основі асоціативних комп'ютерів (наприклад, так побудовано центральний процесор машини STARAN), причому фактично такі комп'ютери мають в складі арифметико-логічного пристрою множину порівняно простих операційних пристроїв порозрядної обробки даних. Іншим прикладом служить матрична система ICL DAP, яка може одночасно обробляти по одному розряду з 4096 слів.
Якщо об'єднати принципи побудови машин І і II, то одержимо машину III (рис. 1.3). Ця машина має два арифметико-логічні пристрої - горизонтальний і вертикальний, а також модифіковану пам'ять даних, яка забезпечує доступ як до слів, так і до бітових шарів. Вперше ідею побудови таких систем у 1960 році висунув У Шуман, що називав їх ортогональними (якщо пам'ять представляти як матрицю слів, то доступ до даних здійснюється в напрямі, "ортогональному" традиційному - не по словах (рядках), а по бітових шарах (стовпцях)). У принципі, як машину STARAN так і ICL DAP можна запрограмувати на виконання функцій машини III, але оскільки вони не мають окремих АЛП для обробки слів і бітових шарів, віднести їх до даного класу не можна. Повноправними представниками машин класу III є обчислювальні системи сімейства OMEN-60 фірми Sanders Associates, побудовані в прямій відповідності до концепції ортогональної машини.
{kind=link}
Якщо в машині І збільшити кількість пар арифметико-логічний пристрій <==> пам'ять даних (іноді цю пару називають процесорним елементом), то одержимо машину IV (рис. 1.4). Єдиний пристрій керування видає команду за командою відразу всім процесорним елементам. З одного боку, відсутність з'єднань між процесорними елементами робить подальше нарощування 'їх числа відносно простим, але з іншого боку, сильно обмежує застосовність машин цього класу. Таку структуру має обчислювальна система РЕРЕ, яка об'єднує 288 процесорних елементів.
{kind=link}
Якщо ввести безпосередні лінійні зв'язки між сусідніми процесорними елементами машини IV, то одержимо структуру машини V (рис. 1.5). Будь-який процесорний елемент тепер може звертатися до даних як у своїй пам'яті, так і в пам'яті безпосередніх сусідів. Подібна структура характерна, наприклад, для класичної матричної багатопроцесорної системи ILLIAC IV.
{kind=link}
Відмітимо, що у всіх машинах з 1-ї по V-у дотримана концепція розділення пам'яті даних і арифметико-логічних пристроїв, припускаючи наявність шини даних або якого-небудь комутуючого елемента між ними. Машина VI, названа матрицею з функціональною пам'яттю (або пам'яттю з вбудованого логікою), є іншим підходом, що передбачає розподіл логіки процесора по всьому запам'ятовувальному пристрою (рис.1.6). Прикладом можуть служити як прості асоціативні запам'ятовувальні пристрої, так і складні асоціативні процесори.
{kind=link}
Класифікація Фліна
Одну з перших практично корисних класифікацій паралельних комп'ютерних систем подав у 1966 році співробітник фірми IBM Майкл Флін, який зараз є професором Стенфордського університету (США). Його класифікація базується на оцінці потоку інформації, який поділено на потоки даних між основною пам'яттю та процесором, та потік команд, які виконує процесор. При цьому потік даних та команд може бути як одиничним, так і множинним. Згідно з М. Фліном, усі комп'ютерні системи поділяють так:
- ОКОД - комп'ютерні системи з одиничним потоком команд та одиничним потоком даних (SISD - Single Instruction Single Data stream).
- МКОД - комп'ютерні системи з множинним потоком команд та одиничним потоком даних (MISD - Multiple Instruction Single Data stream).
- ОКМД - комп'ютерні системи з одиничним потоком команд та множинним потоком даних (SIMD - Single Instruction Multiply Data stream).
- МКМД - комп'ютерні системи з множинним потоком команд та множинним потоком даних (MIMD - Multiple Instruction Multiply Data stream).
Розглянемо запропоновану М. Фліном класифікацію детальніше. На поданих нижче малюнках позначено: ПК - пристрій керування, ПР - процесор, ПД - пам'ять даних.
До класу комп'ютерних систем з одиничним потоком команд та одиничним потоком даних належить, зокрема, комп'ютер з архітектурою Джона фон Неймана, яким, наприклад, є розповсюджений персональний комп'ютер. Структура цієї системи представлена на рис. 1.7а. Організація роботи комп'ютерних систем цього класу була розглянута в попередніх розділах книги.
{kind=link}
Рис. 1.7. Структура комп'ютерної системи типу ОКОДа), МКОД b), ОКМД с), МКМД d)
Структура комп'ютерної системи з множинним потоком команд та одиничним потоком даних показана на рис. 1.7Ь. Комерційні універсальні комп'ютерні системи цього типу в наш час[коли?] невідомі, проте вони можуть з'явитися у майбутньому. До цього типу систем з деякими умовностями можна віднести спеціалізовані потокові процесори, зокрема систолічні, які використовують, наприклад, при обробці зображень.
В комп'ютерній системі з одиничним потоком команд та множинним потоком даних (рис. 1.7 с) одночасно обробляється велика кількість даних. До цього класу, зокрема, належать раніше розглянуті векторні процесори. До комп'ютерних систем з одиничним потоком команд та множинним потоком даних можна віднести також апаратну підсистему процесорів Pentium, яка реалізовує технологію MMX опрацювання даних для графічної операційної системи Windows.
Характерним прикладом комп'ютерної системи з одиничним потоком команд та множинним потоком даних може служити система, яка складається з двох частин: зовнішнього комп'ютера з архітектурою Джона фон Неймана, який виконує роль пристрою керування, і масиву ідентичних синхронізованих елементарних процесорів, здатних одночасно виконувати ту ж саму дію над різними даними. Кожен процесор у масиві Має місцеву пам'ять невеликої ємності, де зберігаються дані, які обробляються паралельно.
З масивом процесорів з'єднано шину пам'яті зовнішнього комп'ютера таким чином, що він може довільно звернутися до кожного процесора масиву. Програма може виконуватися традиційно послідовно на зовнішньому комп'ютері, а її частина може паралельно виконуватися на масиві процесорів. У комп'ютерній системі з множинним потоком команд та множинним потоком даних кожен процесор оперує із своїм потоком команд та своїм потоком даних (рис.1.7d).
Як правило, окремі процесори багатопроцесорної системи є серійними пристроями, що дозволяє значно зменшити вартість проекту. У класі МКМД треба відрізняти сильно зв'язані системи, власне багатопроцесорні системи, від мереж комп'ютерів, тобто слабо зв'язаних систем; тобто багатопроцесорні системи та комп'ютерні мережі потрапляють до різних підкласів класу MIMD.
В 1978 році Д. Куком було запропоновано розширення класифікації Фліна. У своїй класифікації Д. Кук розділив потоки команд та даних на скалярні та векторні потоки. Комбінація цих потоків приводить в підсумку до 16 типів архітектури паралельних комп'ютерних систем.
Класифікація Хокні
Р. Хокні - відомий англійський фахівець в області паралельних обчислювальних систем, розробив свій підхід до класифікації, введеної їм для систематизації комп'ютерів, що потрапляють в клас MIMD по систематиці Фліна.
Клас MIMD надзвичайно широкий, причому поряд з великим числом комп'ютерів він об'єднує безліч різних типів архітектур. Хокні, намагаючись систематизувати архітектури усередині цього класу, отримав ієрархічну структуру, представлену на рис.1.8.
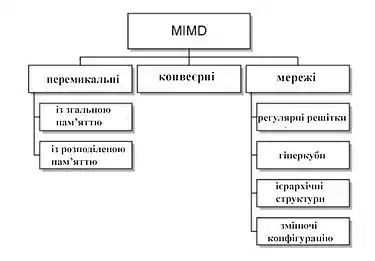
Основна ідея класифікації полягає в наступному. Множинний потік команд може бути оброблений двома способами: або одним конвеєрним пристроєм обробки, що працює в режимі поділу часу для окремих потоків, або кожен потік обробляється своїм власним пристроєм. Перша можливість використовується в MIMD комп'ютерах, які називаються конвеєрними (наприклад, процесорні модулі в Denelcor HEP). Архітектури, використовують другу можливість, у свою чергу знову діляться на два класи:
- MIMD комп'ютери, в яких можливий прямий зв'язок кожного процесора з кожним, реалізований за допомогою перемикача;
- MIMD комп'ютери, в яких прямий зв'язок кожного процесора можливий тільки з найближчими сусідами по мережі, а взаємодія віддалених процесорів підтримується спеціальною системою маршрутизації через процесори-посередники.
Далі, серед MIMD машин з перемикачем Хокні виділяють ті, в яких вся пам'ять розподілена серед процесорів як їх локальна пам'ять (наприклад, PASM, PRINGLE). У цьому випадку спілкування самих процесорів реалізується за допомогою дуже складного перемикача, що становить значну частину комп'ютера. Такі машини звуться MIMD машин з розподіленою пам'яттю. Якщо пам'ять це розподілений ресурс, доступний всім процесорам через перемикач, то такі MIMD є системами із загальною пам'яттю (CRAY X-MP, BBN Butterfly). Відповідно до типу перемикачів можна проводити класифікацію : простий перемикач, багатокаскадний перемикач, загальна шина.
Багато сучасних обчислювальних систем мають як загальну поділювану пам'ять, так і розподілену локальну. Такі системи автор розглядає як гібридні MIMD c перемикачем.
При розгляді MIMD машин з мережевою структурою вважається, що всі вони мають розподілену пам'ять, а подальша класифікація проводиться відповідно до топології мережі: зіркоподібні мережі (lCAP), регулярні решітки різної розмірності (Intel Paragon, CRAY T3D), гіперкуби (NCube, Intel iPCS ), мережі з ієрархічною структурою, такою, як дерева, піраміди, кластери (Cm *, CEDAR) і, нарешті, мережі, змінюючі свою конфігурацію.
Класифікація Скіллікорна
У 1989 році була зроблена чергова спроба розширити класифікацію Флінна і, тим самим, подолати її недоліки. Д. Скіллікорн розробив підхід, придатний для опису властивостей багатопроцесорних систем і деяких нетрадиційних архітектур, зокрема dataflow і reduction machine.
Пропонується розглядати архітектуру будь-якого комп'ютера, як абстрактну структуру, що складається з чотирьох компонентів:
- процесор команд (IP - Instruction Processor) - функціональний пристрій, що працює, як інтерпретатор команд; в системі, взагалі кажучи, може бути відсутнім;
- процесор даних (DP - Data Processor) - функціональний пристрій, що працює як перетворювач даних, у відповідності з арифметичними операціями;
- ієрархія пам'яті (IM - Instruction Memory, DM - Data Memory) - запам'ятовувальний пристрій, в якому зберігаються дані та команди, що пересилаються між процесорами;
- перемикач - абстрактний пристрій, що забезпечує зв'язок між процесорами і пам'яттю.
Функції процесора команд багато в чому схожі з функціями пристроїв управління послідовних машин і, згідно Д. Скіллікорну, зводяться до наступних:
- на основі свого стану і отриманої від DP інформації IP визначає адресу команди, яка буде виконуватися наступна;
- здійснює доступ до IM для вибірки команди;
- отримує і декодує обрану команду;
- повідомляє DP команду, яку треба виконати;
- визначає адреси операндів і посилає їх в DP;
- отримує від DP інформацію про результат виконання команди.
Функції процесора даних роблять його, багато в чому, схожим на арифметичний пристрій традиційних процесорів:
- DP отримує від IP команду, яку треба виконати;
- отримує від IP адреси операнди;
- вибирає операнди з DM;
- виконує команду;
- запам'ятовує результат в DM;
- повертає в IP інформацію про стан після виконання команди.
У термінах таким чином певних основних частин комп'ютера структуру традиційної фон-неймановської архітектури можна представити в наступному вигляді (рис 1.9.).
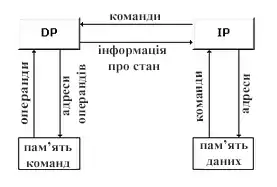
Це один з найпростіших видів архітектури, що не містить перемикачів. Для опису паралельних обчислювальних систем зафіксувавали чотири типи перемикачів, без будь-якого явного зв'язку з типом пристроїв, які вони з'єднують:
- 1-1 - перемикач такого типу пов'язує пару функціональних пристроїв;
- n-n - перемикач пов'язує пристрій з одної множини пристроїв з пристроєм з іншої множини;
- 1-n - перемикач з'єднує один виділений пристрій з усіма функціональними пристроями з деякого набору;
- nxn - кожний функціональний пристрій одної множини може бути пов'язано з будь-яким пристроєм іншої множини, і навпаки.
Прикладів подібних перемикачів можна навести дуже багато. Так, всі матричні процесори мають перемикач типу 1-n для зв'язку єдиного процесора команд з усіма процесорами даних. У комп'ютерах сімейства Connection Machine кожен процесор даних має свою локальну пам'ять, отже, зв'язок буде описуватися як n-n. У той же час, кожен процесор команд може зв'язатися з будь-яким іншим процесором, тому даний зв'язок буде описаний як nxn.
Класифікація Д. Скіллікорна складається з двох рівнів. На першому рівні вона проводиться на основі восьми характеристик:
- кількість процесорів команд (IP);
- число запам'ятовувальних пристроїв (модулів пам'яті) команд (IM);
- тип перемикача між IP і IM;
- кількість процесорів даних (DP);
- число запам'ятовувальних пристроїв (модулів пам'яті) даних (DM);
- тип перемикача між DP і DM;
- тип перемикача між IP і DP;
- тип перемикача між DP і DP.
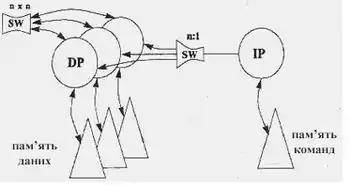
Розглянемо комп'ютер Connection Machine 2. У термінах даних характеристик його можна описати:
(1, 1, 1-1, n, n, nn, 1-n, nxn),
Умовне зображення архітектури наведено на рис.1.9.1.
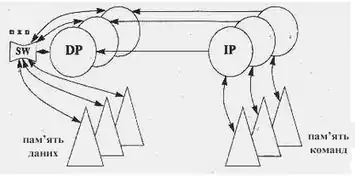
Для сильно пов'язаних мультипроцесорів (BBN Butterfly, C.mmp) ситуація інша. Такі системи складаються з безлічі процесорів, з'єднаних з модулями пам'яті за допомогою динамічного перемикача. Затримка при доступі будь-якого процесора до будь-якого модулю пам'яті приблизно однакова. Зв'язок і синхронізація між процесорами здійснюється через загальні (колективні) змінні. Опис таких машин в рамках даної класифікації виглядає так: (n, n, nn, n, n, nxn, nn, ), а саму архітектуру можна зобразити так, як на рис.1.9.2.
Використовуючи введені характеристики і припускаючи, що розгляд кількісних характеристик можна обмежити лише трьома можливими варіантами значень: 0, 1 і n (тобто більше одного), можна отримати 28 класів архітектур.
У класах 1-5 знаходяться комп'ютери типу dataflow і reduction, що не мають процесорів команд у звичайному розумінні цього слова. Клас 6 це класична фон-нейманівська послідовна машина. Всі різновиди матричних процесорів містяться в класах 7-10. Класи 11 і 12 відповідають комп'ютери типу MISD класифікації Флінна. Класи з 13-го по 28-й займають всілякі варіанти мультипроцесорів, причому в 13-20 класах знаходяться машини з досить звичною архітектурою, в той час, як архітектура класів 21-28 поки виглядає екзотично.
На другому рівні класифікації Д. Скіллікорн просто уточнює опис, зроблений на першому рівні, додаючи можливість конвеєрної обробки в процесорах команд і даних.
Класифікація Дункана
У роботі Р. Дункан викладає свій погляд на проблему класифікації архітектур паралельних обчислювальних систем, причому відразу визначає той набір вимог, на який, з його точки зору, може спиратися шукана класифікація:
З класу паралельних машин повинні бути виключені ті, в яких паралелізм закладений лише на самому низькому рівні, включаючи:
- конвеєризацію на етапі підготовки та виконання команди (instruction pipelining), тобто часткове перекриття таких етапів, як дешифрування команди, обчислення адрес операндів, вибірка операндів, виконання команди і збереження результату;
- наявність в архітектурі декількох функціональних пристроїв, що працюють незалежно, зокрема, можливість паралельного виконання логічних і арифметичних операцій;
- наявність окремих процесорів введення / виводу, що працюють незалежно і паралельно з основними процесорами.
Причини виключення перерахованих вище особливостей пояснються наступним чином. Якщо розглядати комп'ютери, що використовують тільки паралелізм низького рівня, нарівні з усіма іншими, то, по-перше, практично всі існуючі системи будуть класифіковані як «паралельні» (що явно не буде позитивним фактором для класифікації), і, по-друге, такі машини будуть погано вписуватися в будь-яку модель чи концепцію, яка відображатиме паралелізм високого рівня.
- Класифікація повинна бути узгодженою із класифікацією Флінна, що показала правильність вибору ідеї потоків команд і даних.
- Класифікація повинна описувати архітектури, які однозначно не вкладаються у систематику Флінна, але, тим не менш, відносяться до паралельних архітектур (наприклад, векторно-конвейєрні).
Враховуючи вище викладені вимоги, Дункан дає неформальне визначення паралельної архітектури, причому саме неформальність дала йому можливість включити в даний клас комп'ютери, які раніше не вписувалися у систематику Флінна. Отже, паралельна архітектура - це такий спосіб організації обчислювальної системи, при якому допускається, щоб безліч процесорів (простих або складних) могло б працювати одночасно, взаємодіючи в міру потреби один з одним. Слідуючи цьому визначенню, все розмаїття паралельних архітектур Дункан систематизує так, як показано на рис.2.0.
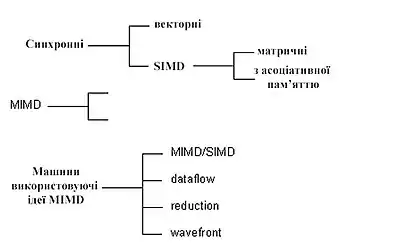
По суті, систематика дуже проста: процесори системи працюють або синхронно, або незалежно один від одного, або в архітектуру системи закладена та чи інша модифікація ідеї MIMD. На наступному рівні відбувається деталізація в рамках кожного з цих трьох класів. Дамо невелике пояснення лише до тих з них, які на сьогоднішній день не настільки широко відомі.
Сістолічні архітектури (їх найчастіше називають систолічним масивами) представляють собою безліч процесорів, об'єднаних регулярним чином (наприклад, система WARP). Звернення до пам'яті може здійснюватися тільки через певні процесори в межах масиву. Вибірка операндів з пам'яті і передача даних по масиву здійснюється в одному і тому ж темпі. Напрямок передачі даних між процесорами фіксований. Кожен процесор за інтервал часу виконує невелику інваріантну послідовність дій.
Гібридні MIMD / SIMD архітектури, dataflow, reduction і wavefront обчислювальні системи здійснюють паралельну обробку інформації на основі асинхронного управління, як і MIMD системи. Але вони виділені в окрему групу, оскільки всі мають ряд специфічних особливостей, якими не володіють системи, традиційно пов'язані з MIMD.
MIMD / SIMD - типово гібридна архітектура. Вона припускає, що в MIMD системі можна виділити групу процесорів, що представляє собою підсистему, що працює в режимі SIMD (PASM, Non-Von). Такі системи відрізняються відносною гнучкістю, оскільки допускають реконфігурацію відповідно до особливостей розв'язуваної прикладної задачі.
Решта три види архітектур використовують нетрадиційні моделі обчислень. Dataflow використовують модель, в якій команда може виконаються відразу ж, як тільки обчислені необхідні операнди. Таким чином, послідовність виконання команд визначається залежністю за даними, яка може бути виражена, наприклад, у формі графа.
Модель обчислень, застосовувана в reduction машинах, інша і полягає в наступному: команда стає доступною для виконання тоді і тільки тоді, коли результат її роботи потрібно інший, доступній для виконання, команді як операнд.
Wavefront array архітектура поєднує в собі ідею систолічної обробки даних і модель обчислень, яка у dataflow. У цій архітектурі процесори об'єднуються в модулі і фіксуються зв'язки, по яких процесори можуть взаємодіяти один з одним. Проте, на противагу ритмічній роботі систолічних масивів, дана архітектура використовує асинхронний механізм зв'язку з підтвердженням (handshaking), через що «фронт хвилі» обчислень може міняти свою форму у міру проходження по всьому безлічі процесорів
Див. також
Джерела
Мельник А. О. «Архітектура комп'ютера» Наукове видання. — Луцьк: 2008. 470 с.
Воеводин В.В., Воеводин Вл. В. Параллельные вичисления.—СПб:БХВ-Петербург, 2002.—608 с.