Паралельні обчислення
Паралельні обчислення — це форма обчислень, в яких кілька дій проводяться одночасно[1]. Ґрунтуються на тому, що великі задачі можна розділити на кілька менших, кожну з яких можна розв'язати незалежно від інших.

Є кілька різних рівнів паралельних обчислень: бітовий, інструкцій, даних та паралелізм задач. Паралельні обчислення застосовуються вже протягом багатьох років, в основному в високопродуктивних обчисленнях, але зацікавлення ним зросло тільки недавно, через фізичні обмеження зростання частоти.[2]. Оскільки споживана потужність (і відповідно виділення тепла) комп'ютерами стало проблемою в останні роки,[3] паралельне програмування стає домінуючою парадигмою в комп'ютерній архітектурі, основному в формі багатоядерних процесорів.[4]
Паралельні комп'ютери можуть бути грубо класифіковані згідно з рівнем, на якому апаратне забезпечення підтримує паралелізм: багатоядерність, багатопроцесорність — комп'ютери, що мають багато обчислювальних елементів в межах одної машини, а також кластери, MPP, та ґрід — системи що використовують багато комп'ютерів для роботи над одним завданням. Спеціалізовані паралельні архітектури іноді використовуються поряд з традиційними процесорами, для прискорення особливих задач.
Програми для паралельних комп'ютерів писати значно складніше, ніж для послідовних[5], бо паралелізм додає кілька нових класів потенційних помилок, серед яких найпоширенішою є стан гонитви. Комунікація, та синхронізація процесів зазвичай одна з найбільших перешкод для досягнення хорошої продуктивності паралельних програм.
Максимальний можливий приріст продуктивності паралельної програми визначається законом Амдала.
Передумови
Колись паралельне програмування було справою тільки тих одинаків, яких цікавили завдання для великих суперкомп'ютерів. Але тепер, коли звичайні додатки почали працювати на багатоядерних процесорах, паралельне програмування швидко стає технологією, яку повинен освоїти і вміти застосовувати будь-який професійний розробник ПЗ. Паралельне програмування може бути складним, але його легше зрозуміти, якщо рахувати не «важким», а просто «трохи іншим».
Традиційно, програми пишуться для послідовних обчислень. Для розв'язку задачі придумують алгоритм, який реалізовується в вигляді послідовності інструкцій. Ці інструкції виконуються одним процесором комп'ютера. У кожен момент часу може виконуватись тільки одна інструкція, після завершення її виконання починається виконання наступної.[6]
З іншого боку, в паралельному програмуванні одночасно використовують кілька обчислювальних елементів для розв'язання однієї задачі. Це уможливлюється розбиттям задачі на підзадачі, кожна з яких може бути вирішена незалежно. Процесорні елементи бувають різними та включають різні ресурси, як наприклад один комп'ютер з багатьма процесорами, кілька з'єднаних у мережу комп'ютерів, спеціалізоване апаратне забезпечення, чи будь-яку комбінацію перерахованого вище.[6]
Приріст частоти був основним чинником збільшення продуктивності комп'ютерів з середини 1980-тих до 2004. Час роботи програми дорівнює числу інструкцій, помноженому на середній час виконання інструкції. Тому збільшення частоти зменшує час виконання всіх процесорно-залежних (коли основним ресурсом виступає час процесора) програм.[7]
Тим не менш, споживана потужність чипу задається рівнянням P = C × V2 × F, де P — потужність, V — напруга живлення, C — ємність, що перезаряджається за один такт процесора (пропорційна числу транзисторів, які перемикаються у цьому такті), а F — тактова частота.[8] Збільшення частоти збільшує потужність, що використовується процесором. Збільшення споживаної потужності призвело до того, що в травні 2004 Intel відмінило розробку процесорів Tejas та Jayhawk, на які зазвичай посилаються як на знак кінця збільшення частоти, як домінуючої парадигми в комп'ютерній архітектурі.[9]
Закон Мура — це емпіричне спостереження про те, що щільність транзисторів в мікропроцесорах подвоюється кожних 18-24 місяці.[10] Незважаючи на проблеми зі споживанням енергії та постійні передбачення кінця, закон Мура все ще працює. З кінцем зростання частоти, ці додаткові транзистори (що вже не збільшують частоту) будуть використовуватись щоб додати додаткове апаратне забезпечення для паралельних обчислень.
Закони Амдала та Густафсона
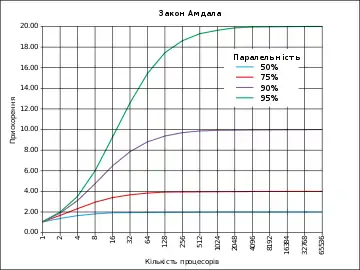
Оптимальним прискоренням від розпаралелювання могло б бути лінійне — збільшення кількості процесорів вдвічі має вдвічі скорочувати час виконання. Наступне збільшення кількості процесорів вдвічі мало б знову прискорювати програму. Тим не менш, лиш кілька паралельних алгоритмів досягають такого прискорення. Більшість з них мають майже лінійне прискорення при невеликій кількості процесорів, яке сповільнюється до константи при великій кількості обчислювальних елементів.
Потенційне прискорення алгоритму при збільшенні числа процесорів задається законом Амдала, що вперше був сформульований Джином Амдалем у 1960-тих.[11] Він стверджує, що невелика частина програми що не піддається паралелізації обмежить загальне прискорення від розпаралелювання. Будь-яка велика математична чи інженерна задача зазвичай буде складатись з кількох частин що можуть виконуватись паралельно, та кількох частин що виконуються тільки послідовно. Цей зв'язок задається рівнянням:

Де — прискорення програми (як відношення до її початкового часу роботи), а — частка яку можна виконувати паралельно. Якщо послідовна частина програми виконується 10 % всього часу роботи, ми не можемо прискоритись більш ніж в 10 разів, незалежно від того скільки процесорів застосуємо. Це ставить верхню межу корисності збільшення кількості обчислювальних елементів. «Коли задача не може розпаралелюватись через обмеження послідовної частини, прикладання додаткових зусиль не має ніякого ефекту для розкладу. Щоб виносити дитину потрібно дев'ять місяців, незалежно від того, скільки жінок цим займаються.»[12]


Закон Густафсона це інший комп'ютерний закон, що сильно пов'язаний з законом Амдала. Його можна сформулювати так:
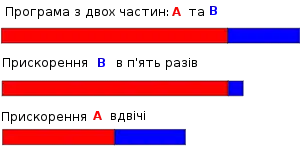

де це кількість процесорів, — прискорення, а нерозпаралелювана частина процесу.[13]. Закон Амдала базується на припущенні того, що задача має фіксований розмір, і що розмір послідовної частини незалежний від кількості процесорів, в той час як закон Густафсона не робить таких припущень.

Залежності
Розуміння залежностей даних дуже важливе для розробки паралельних алгоритмів. Жодна програма не може працювати швидше ніж найдовший ланцюг залежних обчислень (відомий як критичний шлях), бо обчислення, що залежать від попередніх обчислень в ланцюгу мають виконуватись одне за одним. Тим не менш, більшість алгоритмів не складаються лиш з довгого ланцюга залежних обчислень; зазвичай є шанси виконувати незалежні обчислення паралельно.
Хай та — два фрагменти програми. Умови Бернштейна[14] описують коли вони паралельні та можуть виконуватись паралельно. Для , хай — вхідні змінні, а — вихідні. Для — аналогічно. та незалежні, коли вони задовольняють такі умови:







Порушення першої умови створює залежність потоку, результат роботи першої частини використовується другою. Друга умова представляє антизалежність, коли друга частина програми переписує змінну, що потрібна першій програмі. Третя, та остання умова представляє залежність виводів: коли дві частини програми записують дані в одну й ту ж змінну, кінцевий результат має отримуватись від частини, що логічно виконується останньою.[15]
Давайте придумаємо деякі функції, що демонструють кілька типів залежностей:
1: function Dep(a, b) 2: c := a·b 3: d := 2·c
Оператор 3 в Dep(a,b) не може бути виконаним перед (чи навіть одночасно з) оператором 2, бо операція 3 використовує результат роботи операції 2. Вона порушує умову 1, тому маємо залежність потоку.
1: function NoDep(a, b) 2: c := a·b 3: d := 2·b 4: e := a+b
В цьому прикладі між операціями немає залежностей, тому вони можуть виконуватись паралельно.
Умови Бернштейна не дозволяють ділити пам'ять між різними процесами. Тому, потрібне примусове впорядкування доступу до даних, як семафори, бар'єри, та інші методи синхронізації.
Стан гонитви, взаємне виключення, синхронізація та паралельне сповільнення
Підзадачі в паралельній програмі часто називають нитками. Деякі паралельні архітектури використовують менші, легші версії ниток, що називаються волокнами, в той час як інші використовують більші версії, що називаються процесами. Тим не менш, «нитки» зазвичай приймаються як загальний термін для підзадач. Нитки часто потребують зміни деяких змінних що діляться між ними. Інструкції між двома програмами можуть розшаровуватись в будь-якому порядку. Наприклад, хай маємо таку програму:
| Нить A | Нить B |
| 1A: Прочитати змінну V | 1B: Прочитати змінну V |
| 2A: Додати 1 до змінної V | 2B: Додати 1 до змінної V |
| 3A: Записати назад у змінну V | 3B: Записати назад у змінну V |
Якщо інструкція 1B виконається між 1A та 3A, чи якщо інструкція 1A виконається між 1B та 3B, програма буде продукувати неправильні дані. Це відоме як стан гонитви. Програміст має використовувати блокування (англ. lock) щоб створити взаємне виключення. Замок — це конструкція мови програмування, що дозволяє одній ниті отримати контроль над змінною і запобігти читанню чи запису в цю змінну від інших ниток, аж поки ця змінна не буде розблокована. Нить що створила замок може вільно виконувати свою критичну секцію (секцію програми що вимагає ексклюзивного доступу до певної змінної), і розблокувати дані коли секція закінчиться. Тому, щоб гарантувати правильне виконання, програма дана вище може бути переписана з використанням замків:
| Нить A | Нить B |
| 1A: Замкнути змінну V | 1B: Замкнути змінну V |
| 2A: Прочитати змінну V | 2B: Прочитати змінну V |
| 3A: Додати 1 до змінної V | 3B: Додати 1 до змінної V |
| 4A Записати назад у змінну V | 4B: Записати назад у змінну V |
| 5A: Розблокувати змінну V | 5B: Розблокувати змінну V |
Одна нить успішно заблокує змінну V, поки інша буде замкнена — не зможе продовжити роботу, поки V не розблокується. Це гарантуватиме правильне виконання програми. Замки необхідні щоб гарантувати коректне виконання програми, але можуть сильно її сповільнити.
Блокування багатьох змінних з використанням неатомарних замків створює можливість взаємного блокування. Атомарний замок замикає всі змінні за раз. Якщо він не може замкнути всі з них, він не замикає жодної. Якщо дві ниті потребують замкнути однакові дві змінні використовуючи неатомарні замки, можливий випадок коли одна нить замикає одну змінну, а інша другу. В такому випадку жодна з нитей не може продовжувати роботу, що приводить до взаємного блокування.
Багато паралельних програм вимагають того, щоб їхні підзадачі виконувались синхронно. Це потребує використання бар'єра. Бар'єри зазвичай реалізуються з використанням програмного замка. Один клас алгоритмів, що відомі під назвою беззамкові та беззупинкові алгоритми (англ. lack-free and wait-free algorithms), уникають використання замків та бар'єрів. Правда такий підхід зазвичай важко реалізувати і вимагає правильно сконструйованих структур даних.
Не кожне розпаралелювання спричинює прискорення. Загалом, коли задача розбивається на більше та більше ниток, ті нитки витрачають все більше і більше часу на комунікації між собою. Зрештою, час на комунікацію переважає час, що витрачається на розв'язання задачі, і подальше розпаралелювання (поділ на ще більшу кількість ниток) скоріше збільшує аніж зменшує протяжність часу потрібного щоб закінчити роботу. Це відоме як паралельне сповільнення.
Дрібнозернистий, крупнозернистий, та приголомшливий паралелізм
Програми часто класифікуються відповідно до того, як часто їхні підзадачі мають синхронізуватись чи спілкуватись один з одним. Програма проявляє дрібнозернистий паралелізм якщо її підзадачі мають обмінюватись даними багато разів на секунду; вона проявляє крупнозернистий паралелізм, якщо вони не мусять обмінюватись даними багато разів на секунду, і вона проявляє приголомшливий паралелізм, якщо вони рідко, чи взагалі ніколи не мають обмінюватись даними. Приголомшливо паралельні програми вважаються такими що розпаралелюються найлегше.
Моделі узгодженості
Паралельні мови програмування та паралельні комп'ютери мають мати модель узгодженості (також відому як модель пам'яті). Модель узгодженості описує правила проведення різноманітних операцій з пам'яттю, та що ми отримуємо в результаті цих операцій.
Однією з перших моделей узгодженості була модель послідовної щільності Леслі Лампорта. Послідовна узгодженість — це властивість паралельної програми давати такий самий результат що і її послідовний аналог. Конкретніше, програма послідовно узгоджена, якщо "… результат будь-якого запуску такий самий, як був би якщо операції на кожному окремому процесорі виконувались так, ніби вони виконуються в певній послідовності заданій програмою.[16]
Транзакційна пам'ять це типовий приклад моделі узгодженості. Транзакційна пам'ять взяла у теорії баз даних принцип атомарної транзакції та застосувала його при доступі до пам'яті.
Математично, ці моделі можуть представлятись кількома способами. Мережі Петрі, що були вперше представлені Карлом Адамом Петрі у 1962-гому, були ранніми спробами систематизувати правила узгодженості моделей. На їхній основі побудована теорія потоків даних, а їхня архітектура була створена, щоб реалізувати ідеї цієї теорії фізично. Починаючи з кінця 1970-х, були розроблені числення процесів, такі як Числення Систем, що Спілкуються та Послідовні Процеси, що Спілкуються, щоб уможливити алгебраїчне обґрунтування систем складених з взаємодіючих компонентів. Новіші доповнення до сім'ї числень процесів, такі як π-числення, додали можливість обґрунтування динамічних топологій. Такі логіки як TLA+, та математичні моделі такі як траси та діаграми подій актора, також були розвинені щоб описати поведінку конкурентних систем.
Таксономія Флінна
Майкл Дж. Флінн створив одну з найперших класифікацій систем паралельних (та послідовних) комп'ютерів та програм, що нині відома як Таксономія Флінна. Флінн поділяв програми та комп'ютерами залежно від того чи вони використовували один чи багато потоків команд, та чи команди оперували одним чи багатьма множинами даних.
| Одиночний потік інструкцій Single Instruction | Множинний потік інструкцій Multiple Instruction | |
| Одиночний потік даних Single Data | SISD | MISD |
| Множинний потік даних Multiple Data | SIMD | MIMD |
Клас single-instruction-single-data (SISD) еквівалентний цілковито послідовній програмі. Single-instruction-multiple-data (SIMD) еквівалентний виконанню однієї та тієї ж операції повторювано над великим масивом даних. Це зазвичай відбувається у задачах обробки сигналів. Клас Multiple-instruction-single-data (MISD) використовується рідко. Поки придумувались архітектури, що стосуються цього класу (як наприклад систолічні масиви), з'явилось лише кілька програм, що підпадають під цей клас. Multiple-instruction-multiple-data (MIMD) найтиповіші представники паралельних програм.
Згідно з Девідом Паттерсоном та Джоном Геннесі, «Деякі машини є гібридами цих категорій, щоправда ця класична модель вижила через те, що вона проста, легка для розуміння, та дає гарне перше наближення. Вона також, можливо через її зрозумілість — найпоширеніша схема.»[17]
Рівні паралелізму
Паралелізм бітового рівня
З винайденням у 1970-тих технології створення надвеликих інтегральних схем прискорення в комп'ютерній архітектурі відбувалось з допомогою подвоєння розміру машинного слова — кількості інформації, яку комп'ютер може обробляти за один цикл.[18] Збільшення розміру слова зменшує кількість інструкцій необхідних виконати операцію над даними чий розмір більший ніж розмір вхідного слова. Наприклад коли восьмибітний процесор має додати два шістнадцятирозрядні числа, процесор має спочатку додати 8 біт нижчого розряду з кожного числа, використовуючи стандартну інструкцію додавання, потім додати 8 бітів вищого розряду, використовуючи інструкцію додавання з переносом та біт переносу від виконання попереднього додавання. Тому восьмибітний процесор потребує дві інструкції для виконання однієї операції, в той час як шістнадцятибітний лиш одну.
Історично, чотирьохрозрядні процесори були замінені на восьмирозрядні, потім на шістнадцятирозрядні, потім на 32-х розрядні. Ця тенденція припинилась з введенням тридцятидвохрозрядних процесорів, які стали стандартом для персональних комп'ютерів на два десятиліття. Аж поки недавно (2003—2004), з винайденням архітектури x86-64, не з'явились 64-x розрядні процесори.
Паралелізм рівня інструкцій

Комп'ютерна програма, по суті, є потоком інструкцій, що виконуються процесором. Іноді ці інструкції можна перевпорядкувати, та об'єднати в групи, які потім виконувати паралельно, без зміни результату роботи програми, що відомо як паралелізм на рівні інструкцій. Такий підхід до збільшення продуктивності обчислень переважав з середини 80-тих до середини 90-тих.[19]
Сучасні процесори мають багатоетапні конвеєри команд. Кожен етап конвеєра відповідає іншій дії, що виконує процесор. Процесор що має конвеєр з N-ступенями, може одночасно обробляти N інструкцій, кожну на іншій стадії обробки. Класичним прикладом процесора з конвеєром є процесор архітектури RISC, що має п'ять етапів: завантаження інструкції, декодування, виконання, доступ до пам'яті, та запис результату. Процесор Pentium 4 має конвеєр з 35 етапами.[20]
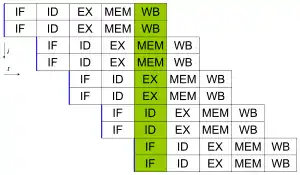
На додачу до паралелізму на рівні інструкцій деякі процесори можуть виконувати більш ніж одну інструкцію за раз. Вони відомі як суперскалярні процесори. Інструкції групуються разом, якщо між ними не існує залежності даних. Щоб реалізувати паралелізм на рівні інструкцій використовують алгоритми Scoreboarding та Tomasulo algorithm (який аналогічний до попереднього, проте використовує перейменування регістрів).
Паралелізм даних
Паралелізм даних — це паралелізм властивий циклам програм, які фокусуються на доставці даних різним обчислювальним вузлам для паралельної обробки. "Розпаралелювання циклів часто приводить до подібних (не обов'язково ідентичних) послідовностей операцій, чи обчислення функцій над елементами великих структур даних.[21] Багато наукових, та інженерних програм проявляють паралелізм даних.
Циклічна залежність — залежність ітерації циклу, від результатів попередньої, чи кількох попередніх ітерацій. Циклічні залежності перешкоджають розпаралелюванню циклів. Розглянемо псевдокод, що обчислює кілька перших чисел фібоначчі:
1: PREV1 := 0 2: PREV2 := 1 4: do: 5: CUR := PREV1 + PREV2 6: PREV1 := PREV2 7: PREV2 := CUR 8: while (CUR < 10)
Такий цикл не може бути розпаралелений, бо CUR залежить від себе (PREV2), та PREV1, які обчислюються в кожній ітерації. Тому, кожна ітерація залежить від результатів попередньої, вони не можуть виконуватись паралельно. Коли розмір задачі стає більшим, кількість доступних для розпаралелювання даних зазвичай теж зростає.[22]
Паралелізм задач
Паралелізм задач — характеристика паралельної програми, яка полягає в тому, що «цілком різні обчислення можуть виконуватись над одними, чи різними даними».[21] Це відрізняє паралелізм задач від паралелізму даних, при якому одне і те ж обчислення виконується над одними і тими ж даними. Паралелізм задач, зазвичай не зростає зі зростанням розміру задачі.[22]
Апаратне забезпечення
Пам'ять та комунікації
Основною пам'яттю в паралельному комп'ютері є як спільна пам'ять (розподілена між всіма обчислювальними елементами в одному адресному просторі), чи розподілена пам'ять (в якій кожен обчислювальний елемент має свій власний локальний адресний простір).[23] Розподілена пам'ять відсилається до того факту, що пам'ять є логічно поділеною, хоча часто натякає і на те, що вона також розділена і фізично. Розподілена спільна пам'ять та віртуалізація пам'яті комбінують обидва підходи, де обчислювальний елемент має свою власну локальну пам'ять, та доступ до пам'яті інших процесорів. Доступ до локальної пам'яті зазвичай швидший ніж доступ до нелокальної.
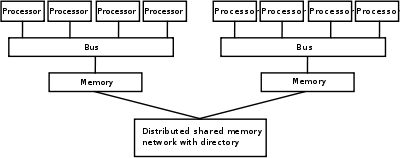
Комп'ютерні архітектури в яких доступ до кожного елементу основної пам'яті займає однаковий час та трафік називаються системами з однорідним доступом до пам'яті Uniform Memory Access (UMA). Зазвичай, це досягається тільки з спільною пам'яттю, в якій пам'ять не є фізично розподілена. Система що не володіє такою властивістю називається архітектурою з неоднорідним доступом до пам'яті (Non-Uniform Memory Access (NUMA)). Системи з розподіленою пам'яттю мають неоднорідний доступ до пам'яті.
Комп'ютерні системи використовують маленькі, швидкі, кеш-пам'яті, що розміщуються близько до процесора, та зберігають тимчасові копії змінних пам'яті (як у фізичному, так і логічному смислах). Паралельні комп'ютери мають проблеми з кешами, що можуть зберігати одні і ті ж значення в кількох місцях, що створює можливості для неправильного виконання обчислень. Такі комп'ютери вимагають систему когеренції кешу, яка слідкує за кешованими змінними та вчасно очищує їх, забезпечуючи коректне виконання програми. Пронюхування шини один з найзагальніших методів слідкування за тим, які змінні використовуються та які треба зачистити. Конструювання великих, продуктивних систем когеренції кешу є складною задачею з галузі комп'ютерних архітектур. В результаті, архітектури з спільною пам'яттю не масштабуються так добре, як з розподіленою пам'яттю.[23]
Комунікація між процесорами, та між процесорами та пам'яттю може бути реалізована апаратно кількома способами, включаючи спільну (мультипортову чи Мультиплексну) пам'ять, матричний перемикач, спільну шину чи мережа однієї з тисяч топологій, включаючи зірку, кільце, дерево, гіперкуб, жирний гіперкуб (гіперкуб з більш ніж одним процесором у вершині), чи n-вимірну сітку.
Паралельні комп'ютери що базуються на зв'язаних мережах мають мати певну маршрутизацію щоб забезпечити передавання повідомлень між елементами що не є зв'язані напряму. Медіа що використовується для зв'язку процесорів часто буває ієрархічним у великих багатопроцесорних машинах.
Види паралельних комп'ютерів
Паралельні комп'ютери можна грубо класифікувати за рівнем, на якому апаратне забезпечення підтримує паралелізм. Така класифікація майже аналогічна відстані між основними обчислювальними елементами.
Багатоядерні обчислення
Багатоядерний процесор — це процесор, що містить кілька ядер. Ці процесори відрізняються від суперскалярних процесорів, які можуть виконувати кілька інструкцій за такт з одного потоку інструкцій (нитки); на відміну від багатоядерних, що можуть за такт виконувати кілька інструкцій з різних ниток. Кожне ядро багатоядерного процесора потенційно може бути суперскалярним, тобто виконувати по кілька інструкцій з одної нитки.
Синхронна багатонитевість (найвідомішою з яких є технологія HyperThreading від Intel) була ранньою формою псевдо-багатоядерності. Процесор, що здатен до синхронної багатонитевості має лиш одне ядро, але при простоях ядра (наприклад під час очікування підвантаження даних в стек), використовує це ядро для роботи з іншою ниттю. Мікропроцесор Cell від IBM, що створений для використання в консолях Sony PlayStation 3 є іншим прикладом багатоядерного процесора.
Симетрична багатопроцесорність
Симетричний мультипроцесор (SMP) це комп'ютерна система з багатьма ідентичними процесорами, що поділяють пам'ять, та з'єднуються через шину.[24] Шинна суперечка (англ. bus contention) перешкоджає масштабуванню шинних архітектур. В результаті, SMP зазвичай не містить більше 32-x процесорів.[25] «Через малий розмір процесорів, та значне зменшення вимог до пропускної здатності шини, що досягається завдяки великим кешам, такі симетричні багатопроцесорні системи є дуже рентабельними за умови, що існує достатня кількість пропускної здатності у пам'яті».[24]
Розподілені обчислення
Розподілений комп'ютер (також відомий як мультипроцесор з розподіленою пам'яттю) це комп'ютерна система з розподіленою пам'яттю, у якій обчислювальні елементи з'єднані мережею. Розподілені комп'ютери чудово масштабуються.
Кластерні обчислення

Кластер — це група слабо зв'язаних комп'ютерів, що тісно співпрацюють, так що в певною мірою, вони можуть розглядатись як один комп'ютер.[26] Кластери складаються з багатьох окремих машин, з'єднаних мережею. І хоча машини в кластері не мають бути симетричними, якщо вони не є, то це ускладнює балансування навантаження. Найпоширенішим типом кластера є кластер Beowulf, який є кластером, реалізованим на багатьох ідентичних фабричних комп'ютерах, з'єднаних в локальну мережу TCP/IP Ethernet.[27] Вперше технологію Beowulf розробили Томас Стерлінг та Дональд Беккер. Більшість суперкомп'ютерів зі списку TOP500 є кластерами.[28]
Масово паралельні обчислення
Масивно паралельний процесор (MPP) це один комп'ютер з багатьма процесорами з'єднаними в мережу. MPP мають багато спільного з кластерами, та MPP мають спеціалізовані з'єднувальні мережі (тоді як кластери використовують стороннє обладнання для мережі). MPP також в основному більші ніж кластери, зазвичай мають «набагато більше ніж 100 процесорів».[29] В MPP, «кожен процесор має свою власну пам'ять та копію операційної системи з програмами. Кожна підсистема спілкується з іншою через високошвидкісне з'єднання.»[30]

Blue Gene/L, має рейтинг четвертого найшвидшого суперкомп'ютера у світі, згідно з рейтингом TOP500 11/2008. Blue Gene/L масивно паралельний процесор.
Обчислення Ґрід
Обчислення Ґрід — найбільш розподілена форма паралельних обчислень. Вона використовує для розв'язання задачі зв'язані мережею Інтернет комп'ютери. Через низьку швидкість передачі даних, та відносно великий час доступу до даних в Інтернет, ґрід обчислення проводять тільки для приголомшливо паралельних задач. Створена багато застосувань ґрід системам, найвідомішими з яких є SETI@home та Folding@Home[31]
Більшість програм ґрід обчислень використовують проміжне програмне забезпечення, що слугує інтерфейсом між операційною системою, та програмою, та керує ресурсами мережі, і стандартизує інтерфейс. Найпоширенішим програмним забезпеченням цього типу є Berkeley Open Infrastructure for Network Computing (BOINC). Часто програми ґрід обчислень користуються «запасними циклами», виконуючи обчислення під час простою системи. Тому їхні реалізації під виглядом екранних заставок доволі поширені.
Спеціальні паралельні комп'ютери
У галузі паралельних обчислень є спеціальні паралельні пристрої, що займають свої ніші. І хоча вони не є предметно-орієнтованими, та все ж вони зазвичай застосовуються лише для певних класів паралельних задач.
- Обчислення загального призначення на графічних співпроцесорах (GPGPU)

Загальні обчислення на графічних процесорах це порівняно нова тенденція в комп'ютерній інженерії. Графічні процесори — допоміжні процесори, що були сильно оптимізовані для обчислень комп'ютерної графіки.[32] Обчислення в комп'ютерній графіці це галузь, в якій панує паралелізм даних, зокрема операції з матрицями в лінійній алгебрі.
На початку, відеокарти використовували графічні API для виконання свої програм. Щоправда тепер з'явилось кілька нових мов програмування та платформ збудованих для виконання обчислень загального призначення на відеокартах як на середовищах CUDA для Nvidia так і на CMT для AMD. Іншими мовами для загальних обчислень на відеокартах є BrookGPU, PeakStream, та RapidMind. Nvidia також випустила спеціальні засоби для обчислень на своїх відеокартах серії Tesla.
Програмне забезпечення
Мови паралельного програмування
Паралельні мови програмування, бібліотеки, API і паралельні моделі програмування, були створені для програмування паралельних комп'ютерів. В цілому їх можна поділити на класи, засновані на припущеннях, основа яких лежить в будові, загальної пам'яті основної пам'яті, розподіленої пам'яті, або загальної розподіленої пам'яті. Однією з концепцій, які використовуються в програмах паралельного програмування, є концепція майбутності, в якій одна частина програми зобов'язується поставити потрібні дані іншій частині програми в якийсь момент в майбутньому.
CAPS entreprise та Pathscale також координують зусилля, щоби зробити директиви гібридного багатоядерного паралельного програмування (англ. hybrid multi-core parallel programming, HMPP) відкритим стандартом під назвою OpenHMPP. Модель програмування на основі директив OpenHMPP пропонує синтаксис ефективного розвантаження обчислень на апаратних прискорювачах і оптимізацію переміщення даних в/з апаратної пам'яті. Директиви OpenHMPP описують виклик віддалених процедур (англ. remote procedure call, RPC) на прискорювані (наприклад, ГП) або, в загальнішому випадку, на наборі ядер. Ці директиви роблять нотатки в коді C або Fortran для опису двох наборів функціональних можливостей: розвантаження процедур (що позначаються codelets) на віддалений пристрій, та оптимізацію передавання даних між основною пам'яттю ЦП та пам'яттю прискорювача.
Автоматичне розпаралелювання
Автоматичне розпаралелювання послідовної програми компілятором є святим граалем паралельних обчислень. Незважаючи на десятиліття роботи дослідниками компіляторів, автоматичне розпаралелювання має обмежений успіх.
Головні мови паралельного програмування залишаються або явно паралельними або (в кращому випадку), частково неявно паралельними, в яких програміст дає директиви для розпаралелювання компілятору. Повністю явно паралельні мови існують — SISAL, Parallel Haskell, SequenceL, System C (для ПКВМ), Mitrion-C, VHDL, і Verilog.
Контрольні точки програми
З ростом складності комп'ютерної системи середній наробіток між відмовами, як правило, зменшується. Контрольні точки програми — це метод, за допомогою якого комп'ютерна система робить «знімок» застосунку, — запис усіх поточних виділених ресурсів і станів змінних, схожий на дамп ядра. Цю інформацію може бути використано для відновлення програми, якщо комп'ютер збійне. Контрольні точки програми дають змогу розпочати з останнього збереження, а не з самого початку. В той час як контрольні точки забезпечують переваги в різних ситуаціях, вони особливо корисні у високорозвинених паралельних системах з великим числом процесорів, використовуваних в області високопродуктивних обчислень.
Алгоритмічні методи
Оскільки паралельні комп'ютери стають все кращі і швидші, стає можливим вирішити проблеми, які раніше займали багато часу. Паралельні обчислення використовується в різних сферах життя, від біоінформатики (згортання білків і аналіз послідовності) до економіки (фінансової математики). Найбільш поширеними типами проблем, виявлених в паралельних обчислювальних є:
- щільна лінійна алгебра;
- розріджена лінійна алгебра;
- спектральні методи (такі як перетворення Кулі-Тьюки швидкого перетворення Фур'є);
- проблеми N-тіла (наприклад, Barnes-Hut моделювання);
- структуровані ґрід проблеми (наприклад, методи Латтісе Больцмана);
- неструктуровані ґрід проблеми (наприклад, знайти в аналізі кінцеві елементи);
- метод Монте Карло;
- комбінаційної логіки (такі як грцби криптографічні методи);
- графік обходу (наприклад, алгоритми сортування);
- динамічне програмування;
- метод гілок і меж;
- графові моделі (наприклад, виявлення прихованих марковських моделей і побудови мереж Байєса);
Відмовостійкість
Паралельні обчислення також можуть бути застосовані до проектування відмовостійких обчислювальних систем, зокрема, за допомогою Lockstep системи, що виконують ті ж операції паралельно. Це забезпечує надлишковість у разі падіння одного з компонентів і також дозволяє автоматично визначати та виправляти помилки якщо результати різняться. Ці методи можуть бути використані, щоб допомогти запобігти поодиноким подіям, які викликають тимчасові помилки. Хоча додаткові заходи можуть знадобитися у вбудованих або спеціалізованих системах, цей метод може забезпечити економічно ефективний підхід до досягнення п-модульної надмірності в комерційних системах.
Історія

Витоки істинної (MIMD) паралельності пішли від Луїджі Федеріко Менабреа і його «Ескізу Аналітичного двигуна Винайденого Чарльзом Беббіджем».
У квітні 1958 року С. Гілл (Ferranti) обговорили паралельне програмування і необхідність розгалуження і очікування. Крім того, в 1958 році дослідники IBM Джон Кок і Даніель Слотнік вперше обговорили використання паралелізму в численних розрахунках. Burroughs Corporation представила D825 в 1962 році, чотирьох процесорний комп'ютер, він надавав доступ до 16 модулів пам'яті через комутатор. У 1967 році Амдал і Слотнік опублікували дискусію про можливість паралельної обробки на конференції Американської федерації товариств з обробки інформації. Саме в ході цієї дискусії був придуманий закон Амдаля, щоб визначити межу прискорення завдяки паралельності.
У 1969 році компанія Honeywell представила свою першу Multics, симетричну систему, мультимікроконтроллерну, здатну працювати до восьми процесорів паралельно. З 1970-х років багатопроцесорний проект Університету Карнегі-Меллона, був одним з перших мультипроцесорів з більш ніж кількома процесорами.
Історію паралельних комп'ютерів SIMD можна простежити з 1970-х років. Мотивацією ранніх комп'ютерів SIMD був амортизувати затримку управління процесора кількома інструкціями. У 1964 році Слотнік запропонував будувати МВС для Ліверморської національної лабораторії. Його проект був профінансований ВВС США. Ключем до його конструкції був досить високий паралелізм, аж до 256 процесорів, що дозволило машинам працювати на великих наборах даних в тому, що пізніше буде відоме як вектор обробки. Проте, ILLIAC IV був названий «самим сумнозвісної суперкомп'ютерів», тому що проект був тільки на чверть завершений, але пішло 11 років і коштував майже в чотири рази більше первісної оцінки. Коли він, нарешті, готовий до запуску (перший реальне застосування в 1976 році) він програвав існуючим комерційним суперкомп'ютерам, таким як Cray-1.
Див. також
Примітки
- Almasi, G.S. and A. Gottlieb (1989). Highly Parallel Computing. Benjamin-Cummings publishers, Redwood City, CA.
- S.V. Adve et al. (Листопад 2008). «Parallel Computing Research at Illinois: The UPCRC Agenda» Архівовано 9 грудня 2008 у Wayback Machine. (PDF). Parallel@Illinois, University of Illinois at Urbana-Champaign. «Основні технології збільшення продуктивності обчислень — збільшення частоти тактового генератора, та хитріші, проте відповідно набагато складніші архітектури, сьогодні стикаються з так званою стіною потужності. Комп'ютерна промисловість прийняла факт, що майбутні зростання продуктивності обчислень будуть пов'язані зі зростанням кількості процесорів (чи ядер), аніж зі спробами змусити одне ядро працювати швидше».
- Asanovic et al. Старий принцип економії: Електрика безплатна, транзистори дорогі. Новий принцип економії: електрика дорога, але транзистори «безплатні».
- Asanovic, Krste et al. (Грудень 18, 2006). «The Landscape of Parallel Computing Research: A View from Berkeley» (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. «Старий принцип вирішення проблем: Збільшення тактової частоти — основний метод покращення продуктивності. Новий принцип: Збільшення паралелізму це основний метод збільшення продуктивності процесора… Навіть представники Intel, компанії, що зазвичай асоціюється з позицією — „чим більша частота тим краще“, попереджують, що традиційні підходи до збільшення продуктивності через збільшення тактової частоти досягли своєї межі.»
- Patterson, David A. and John L. Hennessy (1998). Computer Organization and Design, Second Edition, Morgan Kaufmann Publishers, p. 715. ISBN 1-55860-428-6.
- Barney, Blaise. Introduction to Parallel Computing. Lawrence Livermore National Laboratory. Архів оригіналу за 29 червня 2013. Процитовано 9 листопада 2007.
- Hennessy, John L. and David A. Patterson (2002). Computer Architecture: A Quantitative Approach. 3rd edition, Morgan Kaufmann, p. 43. ISBN 1-55860-724-2.
- Rabaey, J. M. (1996). Digital Integrated Circuits. Prentice Hall, p. 235. ISBN 0-13-178609-1.
- Flynn, Laurie J. «Intel Halts Development of 2 New Microprocessors». The New York Times, May 8, 2004. Retrieved on April 22, 2008.
- Moore, Gordon E. (1965). Cramming more components onto integrated circuits (PDF). Electronics Magazine. с. 4. Архів оригіналу за 18 лютого 2008. Процитовано 11 листопада 2006.
- Amdahl, G. (April 1967) «The validity of the single processor approach to achieving large-scale computing capabilities». In Proceedings of AFIPS Spring Joint Computer Conference, Atlantic City, N.J., AFIPS Press, pp. 483-85.
- Фред Брукс Міфічний людино-місяць. Розділ 2 — Міфічний людино-місяць. ISBN 0-201-83595-9
- Reevaluating Amdahl's Law Архівовано 27 вересня 2007 у Wayback Machine. (1988). Communications of the ACM 31(5), pp. 532-33.
- Bernstein, A. J. (October 1966). «Program Analysis for Parallel Processing,' IEEE Trans. on Electronic Computers». EC-15, pp. 757-62.
- Roosta, Seyed H. (2000). «Parallel processing and parallel algorithms: theory and computation». Springer, p. 114. ISBN 0-387-98716-9.
- Lamport, Leslie (September 1979). «How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs», IEEE Transactions on Computers, C-28,9, pp. 690-91.
- Patterson and Hennessy, p. 748.
- Culler, David E.; Jaswinder Pal Singh and Anoop Gupta (1999). Parallel Computer Architecture — A Hardware/Software Approach. Morgan Kaufmann Publishers, p. 15. ISBN 1-55860-343-3.
- Culler et al. p. 15.
- Patt, Yale (April 2004). The Microprocessor Ten Years From Now: What Are The Challenges, How Do We Meet Them? Архівовано 14 квітня 2008 у Wayback Machine. (wmv). Distinguished Lecturer talk at Carnegie Mellon University. Retrieved on November 7, 2007.
- Culler et al. p. 124.
- Culler et al. p. 125.
- Patterson and Hennessy, p. 713.
- Hennessy and Patterson, p. 549.
- Patterson and Hennessy, p. 714.
- What is clustering? Webopedia computer dictionary.
- Beowulf definition. PC Magazine
- Architecture share for 06/2007 Архівовано 14 листопада 2007 у Wayback Machine.. TOP500 Supercomputing Sites. Clusters make up 74.60 % of the machines on the list. Retrieved on November 7, 2007.
- Hennessy and Patterson, p. 537.
- MPP Definition. PC Magazine. Retrieved on November 7, 2007.
- Kirkpatrick, Scott (January 31, 2003). «Computer Science: Rough Times Ahead». Science, Vol. 299. No. 5607, pp. 668 — 669. DOI: 10.1126/science.1081623
- Boggan, Sha'Kia and Daniel M. Pressel (August 2007). GPUs: An Emerging Platform for General-Purpose Computation (PDF). ARL-SR-154, U.S. Army Research Lab. Retrieved on November 7, 2007.
- Patterson and Hennessy, pp. 749–50: «Although successful in pushing several technologies useful in later projects, the ILLIAC IV failed as a computer. Costs escalated from the $8 million estimated in 1966 to $31 million by 1972, despite the construction of only a quarter of the planned machine . It was perhaps the most infamous of supercomputers. The project started in 1965 and ran its first real application in 1976.»
