Комп'ютеризація контент-аналізу
На відміну від ручного контент-аналізу, комп'ютеризований контент-аналіз виробив свою власну методику та технології та розвинувся своїм шляхом.
Варто зазначити, що в іноземній та вітчизняній літературі поки що немає консенсусу з приводу того, що вважати комп'ютерним контент-аналізом. Так, наприклад, Іванов зазначає: "В англомовній літературі вирізняють комп’ютерний контент-аналіз, що застосовується у якісних (computer- aided) та кількісних (computer-assisted) контент-аналітичних дослідженнях. Ми пропонуємо перекладати дані терміни як "комп’ютеризований" та "автоматизований", відповідно"[1].
У даній статі будуть використовуватись визначення Юськіва та розуміти під комп'ютеризованим контент-аналізом "аналіз текстових матеріалів, у якому всі кроки виявлення змістовних властивостей (характеристик) і визначення сукупностей концептуальних показників тексту здійснюються за допомогою алгоритмів, тобто явних логічних або статистичних операцій"[2].
Перші спроби механізувати і автоматизувати контент-аналіз
Як зазначає Юськів: "Перші контент-дослідження з використанням технічних засобів у гуманітарній сфері пов'язані з роботами італійського священика Роберто Бузи. Отець Р.Буза ставив перед собою завдання з допомогою технічних засобів створити конкорданси повного зібрання листів італійського теолога XIII ст. Фоми Аквінського. Докторська дисертація Р.Бузи, захищена в 1946 р., присвячена вивченню поняття "присутність" у розумінні домініканського мислителя. Створивши і проаналізувавши друковані індекси латинських слів praesens і praesentia, Р.Буза дійшов висновку, що їхнє використання у Ф.Аквінського було тісно пов'язане прийменником in. Більше того, Р.Буза готовий був повірити, що подібні функціональні слова дають чимало інформації про зв’язок між концептуальним світом автора і словами, які він використовує для його опису. Однак достатніх дослідницьких ресурсів для створення ручним способом конкордансу таких загальних латинських слів, як in, sum або et (у перекладі відповідно "в", дієслово-зв’язка "бути", "і"), Р.Буза не мав.
Попри труднощі, наприкінці 1940-х років. він поставив перед собою набагато грандіозніше завдання – створити "Index Thomisticus", який би містив повний конкорданс 10,6 млн. слів Фоми Аквінського. Вирішення цього завдання без використання певного виду технічних пристроїв було неможливим. Робота, розпочата з використанням перфораторів і сортувальних машин, була практично завершена через 33 роки на базі великих універсальних ЕОМ серії IBM. Разом з іншою інформацією, Індекс складався з майже 70000 сторінок. Було створено два конкорданси. Один, який формувався безпосередньо машиною, містив повний список відповідностей для всіх словоформ і отримав назву "нелематизованого". Другий конкорданс утворювали так звані "лематизовані" відповідності, у списку яких кожне слово зустрічалося лише один раз у стандартній формі, наприклад, іменники – лише в однині, дієслово – у невизначеній формі і т.д. Створити "лематизовану" відповідність без допомоги людини ЕОМ була не в змозі. За оцінками Бузи, на всю роботу використано понад 1 млн. людиногодин, головним чином для введення і перевірки даних, а також здійснення лематизації. Спроби механізувати окремі операції в процесі здійснення контент-аналізу не призвели і не могли призвести до істотних змін у його використанні і методиці. Водночас, слідом за збільшенням кількості самих текстів зростала потреба в контент-аналізі, який би швидко й ефективно аналізував тексти різної природи і великих обсягів. Поява комп’ютерної техніки створила реальні, хоча спочатку неявні і неусвідомлені за своїми майбутніми наслідками, можливості побороти "прокляту проблему розмірності"[3].
Покоління розвитку комп’ютеризованого контент-аналізу
Юськів виділяє чотири покоління програмного забезпечення контент-аналізу, причому критеріями для такого поділу автор визначає "не стільки часові рамки, скільки та роль, яку відіграють програмні засоби в процесі аналізу".[4]
Програми І покоління (1950-ті – 1960-ті роки)
("вузькоспеціалізовані програми для проведення окремих розрахунків або програми загального користування (текстові і табличні процесори, системи керування базами даних)
– призначені для проведення числових розрахунків, статистичного аналізу, побудови примітивних графіків
– можливість виконання окремих менеджерських функцій щодо тексту (зберігання, копіювання, формування індексів)
Програми ІІ покоління (1966 – середина 1980-х років)
(спеціалізовані програми кількісного аналізу, обмежені обробкою текстів і які не виходять за межі ручної технології)
– основна увага на кодування, пошуку ключових слів і фраз, виведення інформації у формі різноманітних індексів, конкордансів
– дозволяють здійснювати ручне, автоматизоване і автоматичне кодування з використанням словників
– реалізуються різноманітні стратегії пошуку, формування таблиць конкордансу, здійснення аналізу колокацій
– можливість роботи з електронними текстами
– використовують винятково кількісні аналітики
Програми ІІІ покоління (середина 1980-х років – 1990-ті роки)
(спеціалізовані програми, обмежені обробкою текстів у рамках якісної та кількісної технології аналізу)
– характеризується надзвичайним розмаїттям програм
– виходить за межі ручної технології і значно посилює аналітичні можливості дослідника, програма виступає своєрідним досвідченим експертом
– реалізуються функції всіх етапів досліджень, збільшилося число виконуваних функцій (структуризація даних, візуалізація результатів, формування та перевірка гіпотез, формування висновків і звітів), принципові зміни в реалізації тих функцій, які були реалізовані раніше (кодування, конкорданс)
– активно застосовуються кількісними дослідниками, привернули увагу "якісників"
Програми IV покоління (від середини 1990-х років)
(вийшли за межі винятково обробки текстів)
– технологічні програми, які в основі мають контент-аналіз і реалізуються для роботи в режимі реального часу
– реалізуються у вигляді масштабних систем зі складними математичними і лінгвістичними алгоритмами аналізу, для яких характерний розвинений графічний інтерфейс, доступ до різних джерел даних, функціонування в архітектурі клієнт-сервер" [5]
Перше покоління розвитку контент-аналізу
Перше покоління, на думку Юськіва, важко назвати програмами контент-аналізу, "оскільки це лише використання різноманітних програм для цілей контент-аналізу. За влучним висловом Г.Бернарда і Г.Раяна, "подібно до ранніх текстових редакторів і систем управління базами даних, перше покоління текстових процесорів проектувалося як допомога нам робити те, що ми і так уже робили"[6]. Виходячи з можливостей перших універсальних ЕОМ, дослідники "доручали" їм виконувати числові розрахунки, здійснювати статистичний аналіз, будувати примітивні графіки вже після того, як прочитані і закодовані людьми тексти були введені з кодувальних карток на машинні носії. Як правило, спочатку це були спеціально написані під конкретні завдання програми, а дещо пізніше з'явилися більш універсальні програми: спеціалізовані пакети прикладних програм, системи управління базами даних, табличні процесори тощо. Що стосується безпосередньої обробки текстів, програми першого покоління дозволяли зберігати і архівувати самі тексти, будувати і видруковувати прості індекси і конкорданси, підшуковувати цитати і виводити їх на друк у форматі на зразок KWIC-таблиць"[7].
The General Inquirer і особливості другого покоління програм контент-аналізу
"Появу другого покоління програм комп’ютеризованого контент-аналізу пов’язують з Гарвардським університетом (США), група науковців якого під керівництвом Ф.Стоуна в 1961 р. почала розробку принципів систематичного комп’ютеризованого контент-аналізу. Уже в 1966 р. була завершена перша версія спеціалізованої програми кількісного контент-аналізу текстів the General Inquirer, яка розвіяла міф про те, що універсальні ЕОМ можуть використовуватися лише для статистичного аналізу"[8]. Як зазначає Іванов, це— "перша широко застосовувана програма для автоматичного контент-аналізу — досі працює, переписана з оригінальної мови IBM PL/1 у середовищі Java".[9]
"Перевіряючи можливості програми, автори проекту повторили чимало своїх і чужих досліджень, використовуючи категорійний апарат попередніх ручних методик. Була проведена серія аналізів текстів газет, наукових робіт і публіцистичних творів, промов кандидатів на президентську посаду від демократичної і республіканської партій США, особистих документів (листів, щоденників, автобіографій). Одне з оригінальних завдань, яке не було дублюванням ручного дослідження і на якому тестувалася система, є дослідження 66 посмертних записок самогубців, з яких 33 – написані тими, хто справді здійснив самогубство, а решта – особами, що лише його симулювали. The General Inquirer проаналізувала тексти і в 91% випадків виявила записки справжніх самогубців. Процес аналізу в the General Inquirer відбувався таким чином. На початковому етапі компілюється словник категорій аналізу. Другим етапом і новим завданням комп’ютера виступає кодування тексту, яке полягає в тому, що система переглядає кожне слово і порівнює його з словоформами (категоріями) словника. Якщо словоформа віднайдена, то лічильник для відповідної словоформи збільшується на одиницю. У кінцевому підсумку отримують частотний розподіл категорій. Залежно від системи, у даний базовий алгоритм можуть уводитися нові правила, наприклад, для врахування контексту використання слів, усунення їхнього двозначного розуміння, виявлення в тексті не лише слів, а й цілих фраз. На третьому етапі програма виводить результати аналізу. Оскільки the General Inquirer є інструментарієм недіалоговим, то результатом стає, окрім звичайних таблиць з даними розрахунків, видруковування індексів і конкордансів. Як правило, інформація виводиться у форматі KWIC (ключові слова в контексті). Крім того, the General Inquirer дає можливість проводити нескладний статистичний аналіз. Якщо виникає потреба, то він дозволяє експортувати дані у формати інших програм (статистичних пакетів, електронних таблиць або програм ділової графіки).
Підхід Ф.Стоуна добре спрацьовує для задач на зразок аналізу тем, пов'язаних із визначенням категорій аналізу, але він є недостатнім при вирішенні проблем, у яких потрібно відшукувати співвідношення між поняттями. Тим не менше, система стала прототипом програм комп’ютеризованого контент-аналізу і була величезним досягненням соціальних наук. Вона та її наступники продемонстрували широкі можливості маніпулювання текстами, їхнього кодування, виділення категорій аналізу, пошуку відповідностей тощо"[10].
Узагальнюючи, на думку Юськіва: "Програми другого покоління за своїми функціями так і не вийшли за межі логіки ручної технології контент-аналізу і практично не змінили її. Вони були допоміжним інструментарієм, який просто полегшував виконувати рутинну роботу, яку аналітик робив і до їхньої появи. Як правило, це були програми кількісного контент-аналізу, однак деякі елементи якісного аналізу вже можна було виконати. Свою увагу програми насамперед зосереджували на кодуванні, а також пошуку ключових слів або фраз і виведенні результатів пошуку на друк. Досвід реалізації цих елементів методики комп’ютеризованого контент-аналізу дістав теоретичне продовження і призвів до появи нових різновидів контент-аналізу"[11].
Особливості комп’ютеризованого контент-аналізу
Іванов виділяє такі переваги комп'ютеризованого контент-аналізу:
1. "Витрати на кодувальників дуже малі. Замість цілої групи можна використовувати одного.
2. Програма не має ні переконань, ні упереджень. Кодування відбувається за попередньо прописаною кодувальною схемою, без будь-якої реінтерпретації.
3. Комп’ютер може аналізувати величезні масиви даних, на кодування і аналіз яких людині потрібні були б місяці, а то й роки"[9].
З недоліків дослідник виділяє наступне:
1. "Комп’ютер кодує послідовність символів, заданих у аналітичному словнику, а не значення, яке вкладає в цю послідовність дослідник. З цього постає проблема семантичної валідності: чи може комп’ютер у відриві від контексту на основі послівної бази адекватно проаналізувати зміст тексту відповідно до поставлених дослідником задач?
2. Перед застосуванням аналітичного словника його слід перевірити на валідність, що все одно вимагає певних затрат на кодувальників".[9]
Загалом, на думку, Юськіва: "Комп’ютеризований контент-аналіз запропонував два принципово відмінних підходи до автоматичного кодування, які умовно називають "a-priori" (або дедуктивний) та "a posteriori" (або індуктивний). Підхід "a-priori", запропонований Ф.Стоуном при розробці the General Inquirer, більш відомий і поширений. Модель контент-аналізу, яка реалізується подібного роду системами, належить до категорії інструментального контент-аналізу. У чистому вигляді первинним тут виступає теорія, покладена в основу дослідження. Саме теорія визначає всі структурні компоненти дослідження: схему класифікації категорій аналізу, послідовність правил наступного кодування текстів, а також висновки, що будуть отримані в результаті дослідження. Фактично релевантність категорій базується на розумінні контексту аналітиком, його інтересів, інтуїції, досвіду і вмінь, цілей дослідження. Зауважимо, що аналітик у процесі дослідження може вносити зміни в класифікаційну схему, залежно від нового, глибшого розуміння тексту після отримання перших результатів, знаходження і виправлення недоречностей, помилок тощо.
Формалізоване представлення правил і умов кодування значною мірою реалізувалося через словники. Уже з перших спроб використання електронно-обчислювальних пристроїв для роботи з текстом ставали очевидними переваги і недоліки обробки текстового матеріалу за допомогою машин – вони забезпечували адекватність аналізу величезних текстових матеріалів, однак вимагали значних зусиль для підготовки програм до роботи – складання "словника з урахуванням усіх синонімічних варіантів понять, які треба буде відшукувати в тому морі слів, які пропускаються через машину. Cловник являє собою сукупність кількох тисяч словоформ, що належать до різних категорій. Категорії утворюють систему, яка виражає сутність певної проблеми, описує деяку тему або комплекс тем. Зазвичай, у словнику задаються слова для 60-150 категорій. Категорії підбираються або індуктивним способом, на основі тексту, або дедуктивно, на основі більш загальних теоретичних міркувань, які диктують вибір категорій. Кожній категорії як розшифрування задаються своєрідні "носії" змісту в реальній мові – слова в усіх своїх формах вираження або словоформи. Побудова такого словника аналогічна побудові "тезауруса" – мови певної галузі людського знання, коли ключовим словам цієї сфери знань відповідає синонімічний ряд загальновживаних слів. Комп’ютерний словник, по суті, являє собою різновид комп’ютеризованої кодувальної книги (codebook)"[12].
“Тотальний контент-аналіз”
"Різновид контент-аналізу, який отримав назву "тотальний", був запропонований Ю.Лаффалем. Ю.Лаффаль намагався кодувати майже кожне слово тексту, за винятком функціональних слів, які мають найбільшу частоту в мові, тобто аналіз охоплював широкий діапазон змістовно пов’язаних іменників, прикметників, дієслів тощо. Його словник спочатку включав 114 категорій. За інформацією Г.Бернард і Г.Раян, станом на початку 1990-х років словник Лаффаля включав 43 тис. слів, кожне з яких асоціювалося з 1-5 категоріями із 168 можливих. Для порівняння: аналіз, пропонований Ф.Стоуном, використовував для кодування близько 10% тексту, тоді як за Ю.Лаффалем покриття тексту категоріями складало майже 90%. Зауважимо, що "тотальний" контент-аналіз знайшов найбільше застосування в психотерапії, коли акцент робиться на вивченні мови пацієнтів.
Альтернативним до систем, побудованих за зразком Ф.Стоуна, проте більш "просунутим", виявився різновид систем автоматичного контент-аналізу "a posteriori", який не потребував попередньої побудови словника, тим самим виключаючи присутність людини навіть на рівні формування категорій. Цей різновид комп’ютеризованого аналізу Г.П.Айкер і Н.І.Гарвей ще наприкінці 1960-х років назвали аналізом, якого "не торкається рука людини"[13]. На відміну від підходу "a priori", він насамперед "керується" даними, а не якоюсь теорією. Тут схема категорій аналізу формується в результаті перегляду досліджуваного тексту. При цьому від аналітика на вході не вимагається жодної додаткової інформації, окрім досліджуваного тексту. Фактично такі системи реалізують репрезентативну модель контент- аналізу.
Сьогодні, за твердженням П.Мохлера і Ц.Зуеля, автоматичні системи цього різновиду контент-аналізу переживають період ренесансу. Прикладом їх можуть бути програми the Words, TextSmart, DICTION. Логіка the Words, розроблена Г.П.Айкером і Н.І.Гарвеєм наприкінці 1960-х років, полягає в наступному. Спочатку текст поділяється на окремі сегменти, для яких формується таблиця частот усіх слів, за винятком функціональних і з урахуванням синонімів. По кожному сегменту відбирається n слів з найбільшою частотою, які утворюють n міні-категорій. Далі обчислюється на основі всіх сегментів матриця взаємних кореляцій між цими категоріями, яка піддається факторному аналізу. У результаті визначаються актуальні або неактуальні міні-категорії (або теми) тексту."[14]
Таблиці конкордансу
Визначальною компонентою програм другого покоління, на думку Юськіва, є реалізація стратегій пошуку даних, серед яких виділяється побудова таблиць конкордансу[15]. "Важливість їх яскраво свідчить хоча б те, що в назвах багатьох програм присутнє слово конкорданс. Так, програма COCOA (Count and Concordance generation for the Atlas) є складовою програми the Atlas. У 1978 р. комп’ютерний центр Оксфордського університету на зміну COCOA випустив OCP (the Oxford Concordance Program), а пізніше Micro-OCP для мікрокомп’ютерів. Добре відома система TACT (Text-Analysis and Concordance Tools) у своїй назві також має слово конкорданс.
Основна ціль конкордансів – спрямувати увагу на безпосереднє лінгвістичне середовище вибраного слова. Логіка пошуку полягає в тому, що спочатку дослідник виявляє потенційно цікаве слово, далі знаходить відповідний йому конкорданс, що дає змогу визначити шаблони (патерни), характерні для даного слова і в яких даному слову відводиться цілком визначена роль.
Існує декілька форматів конкордансу. Один із способів демонстрації контексту зустрічання слів є формат KWOC (keyword-out-of-context – ключове слово поза контекстом) – перелік слів із вказанням місцезнаходження. У ньому ключове слово показується справа або зліва від контексту, а контекст подається у вигляді цілого речення, яке може займати декілька рядків. Більш поширеним є альтернативний формат KWIC (keyword-in-context – ключове слово в контексті), який займає лише один рядок із ключовим словом у центрі цього рядка (однакова кількість слів справа і зліва від ключового слова).[16]
Загалом, "можливості програм контент-аналізу другого покоління насамперед привернули увагу дослідників, що працювали у сфері формалізованих методів досліджень текстів. Якісні ж дослідники навіть не робили спроб застосовувати їх у своїй аналітичній роботі. Тим не менше, численні контент-дослідження, як правило, мас-медійних джерел і в основному англомовних текстів, дозволили виробити методологічні засади нового підходу до емпіричних досліджень у рамках суспільних наук. Однак зусилля й оптимізм, інвестовані в 1960-х роках. у комп’ютеризований контент-аналіз, на 1970-ті роки не поширилися. Головним чином це пов'язують, на думку М.Алекси, із повільним розвитком обчислювальної техніки, обмеженістю доступу до ЕОМ (доступ в межах обчислювальних центрів), а також відсутністю достатньої бази електронних текстів, не кажучи вже про труднощі з переведення в машинний формат розмовних текстів. Відтак зменшилася кількість наукових публікацій, теоретичні дослідження поступилися маломасштабним прикладним, поступово наростав методологічний застій. Щоправда, саме в це десятиріччя комп'ютеризований контент-аналіз почав застосовуватися в психології та психотерапії, а також отримав ширше розповсюдження в Європі. Така ситуація зберігалася аж до середини 1980-х років.[17]
Третє покоління програм контент-аналізу
Від середини 1980-х років намітився значний прогрес у розвитку комп’ютеризованого контент-аналізу. Його стимулювали декілька переходів:
- від великих ЕОМ до персональних комп'ютерів (1980 р.)
- від операційної системи MS DOS до MS Windows із його графічним інтерфейсом і дружнім ставленням до користувача.
Ці зміни дали можливість більшого залучення людини до дослідження. Також свій вплив мали розвиток Інтернет, розповсюдження електронних архівів-бібліотек, доступність електронних текстів і можливість доступу до текстових архівів через Інтернет у режимі on-line.
Завдяки третьому поколінню програм контент-аналізу з’явились можливості неформалізованої обробки текстів [18]. «Стало зрозуміло, що … комп’ютери … можуть надавати значну допомогу в процесі інтерпретації" [19]. Це особливо виявилося очевидним, коли виникла потреба обробки значної кількості неструктурованих текстових даних.
Приклади програм третього покоління: Atlas.ti, HyperResearch, Aquad, NUD'IST [20].
Вони мають засоби для:
- формування текстів і створення на їхній основі цілих проектів;
- вивчення частоти і контексту використання слів (як часто категорії присвоюються словам або текстовим сегментам? які категорії і як часто вони з'являються разом? які зв’язки існують між категоріями або текстовими сегментами);
- створення і підтримка категорій і схем класифікації;
- присвоєння однієї або більше категорій рядкам символів, словам, фразам, реченням, параграфам або цілим текстам;
- зберігання приміток ("мемо") до текстів, кодування текстових сегментів;
- отримання різних форматів перегляду текстів, частин текстів або груп текстів;
- експортування кодів для подальшої обробки їх іншими програмами, а також формування звітів з проведеного аналізу;
- підтримка командної або спільної роботи в рамках проекту і злиття в один кількох проектів [21].
Найпершим завданням, яке постало перед програми якісного контент-аналізу, стало управління неструктурованими текстовими базами даних. Ідея програм полягала в тому, що окрім бази даних з основним текстом, створювалися спеціальні файли або бази даних, які містили адреси сегментів тексту (наприклад, номер запису початку і номер кінця) та імена кодів, які асоціювалися з даним сегментом. За допомогою такого файлу можна виводити окремо ті сегменти тексту, в яких присутні потрібні коди. Він використовувався для пошуку і виділення потрібних фрагментів тексту. Доповнюючи ці файли новими записами, можна постійно розширювати пошукову базу, не зачіпаючи самого тексту. Такий принцип був закладений у перших пакетах програм Qualpro, the Ethnograph, Textbase Alpha [22].
Вирішення цього завдання дозволило виконувати й інші функції аналізу:
- пошук фрагментів тексту;
- побудова конкордансів; здійснення колокацій;
- перевірка інтерпретуючих гіпотез шляхом пошуку сегментів з однаковими кодами;
- введення, редагування та зберігання теоретичних коментарів до фрагментів текстів і т.д
Істотним доповненням до них стали різноманітні представлення взаємопов’язаних категорій шляхом різних способів візуалізації. Із допомогою допоміжних файлів показників можна легко встановлювати зв’язки між сегментами текстів, мемо, кодами. Так, програма NUD'IST дозволяє будувати ієрархічні та мережні структури категорій, програма Atlas.ti формує різноманітні неієрархічні мережі [23].
Внесок
Зміни відбулися на всіх етапах технології досліджень. Насамперед вони стосувались кодування. Інтеграція ручного і автоматичного кодування стало новою технологією багатьох програм, наприклад, PLCA (Program for Linguistic Content Analysis), MECA (Map Extraction, Comparison and Analysis).
Змінилася така функція, як використання конкорденсу. Відтепер, маючи на екрані слова (категорії) і їхню частоту, дослідник оперативно з допомогою KWIC-таблиці переглядав, у якому контексті з'являлося відібране ним слово. Це підсилило переконливість висновків. Такий режим реалізується через систему взаємозв'язаних вікон у багатьох програмах, зокрема навіть під MS DOS у програмі TACT [24].
Збільшилося число нових функцій, які реалізують програми. З'явилася можливість перевіряти гіпотези, розширились інтерпретаційні можливості за рахунок методів пошуку спільного входження кодів (слів), побудови концептуальних моделей, які зв'язують поняття в семантичні мережі, матричного, логічного та картографічного аналізу. Чимало програм приділяють увагу підрахункам показників надійності, наприклад, програми AGREE, Krippendorf’s alpha 3.12a, PRAM (Program for Reliability Assessment of Multiple Coders), або окремі модулі статистичних пакетів програм, зокрема SPSS і Simstat [25].
Такі можливості послужили основою створення цілого ряду програмних систем, які дозволяли вирішувати найрізноманітніші специфічні проблеми в процесі аналізу. Так, побудована на концепції "concept mapping", програма the VBPro дозволяє шляхом картографічного представлення ідентифікувати домінуючі теми і взаємозв’язки між темами для великих масивів даних. Цей різновид текстового аналізу використовується для аналізу медійних повідомлень.
Інший різновид аналізу представляє програма Minnesota Contextual Content analysis (MCCA), яка дозволяє вимірювати соціальну різницю (відстань) між статусом людей в організації, наприклад, лікарями і пацієнтами в лікарні, менеджерами та іншими працівниками фірми, враховуючи стилістичні особливості мови в процесі бесіди, а також контекстуальну інформацію. Дана методологія враховує чотири контекстуальних виміри: традиційний, практичний, емоційний і аналітичний. Здійснюючи кластерний аналіз, система дозволяє кількісно оцінити ступінь близькості між представниками різних соціальних груп [26].
З’явилися системи контент-аналізу для ефективної роботи в окремих сферах. До більш сучасних систем можна віднести програми для дослідження медіа, наприклад, CARMA® (Computer Aided Research & Media Analysis), PrecisTM, Echo®Research, IMPACTTM, Metrica, the Delahaye Medialink system. Окрім здійснення самого контент-аналізу, ці програми включають такі модулі, як убудовані медіабази даних, що забезпечують уведення, доступ і підрахунок відповідних статистичних даних, які стосуються різних параметрів медіа-засобів [27].
Критика
Основне спрямування критики:
- програма дистанціює людину від самих даних, людина практично не відчуває самого алгоритму;
- використання програм призведе до того, що якісні дані будуть аналізуватися кількісно;
- використання програм призведе до зростання однорідності (одноманітності) в методах аналізу, що особливо негативно позначиться на якісних дослідженнях [28].
До цього додається: комп’ютер лише ідентифікує слова, а від ідентифікації слів до ідентифікації ідей, які ці слова представляють, дуже далеко[29].
Особливої ваги набули проблеми забезпечення валідності і надійності результатів:
- труднощі врахування контексту;
- нездатність програми розпізнати комунікативні інтенції слів;
- нездатність дослідника забезпечити вичерпне внесення в список ключових слів для певних категорій;
- нездатність розв’язати проблеми посилань перед або після слів, які з'являються в довільному місці тексту, зокрема проблема займенників;
- нездатність програм визначати межі одиниць аналізу, насамперед при якісному аналізі;
- за чисельними характеристиками, які вираховуються програмами, може втрачатися сутність категорій [30].
Привертається увага і до обмежень, одним з яких є так звана "ціна" комп’ютеризації, під якою Р.Морріс розуміє час і зусилля, витрачені на роботу [30].
Результат
Прихильники же зазначають, що завдяки комп’ютеру контент-аналіз став для дослідників набагато доступнішим, ніж будь-коли, а можливості аналітика значно зросли. Також стверджується, що тепер програми контент-аналізу виступають не лише в ролі одного з інструментів аналізу, а стають повноцінним експертом, завдяки новим інтерпретаційним, графічним та статичним можливостям, здатності формувати гіпотези і готувати варіанти висновків тощо. Особливо ці можливості важливі при роботі з дуже великими масивами текстів.
Наслідком цього періоду розвитку контент-аналізу було створення в різних країнах цілого ряду науково-дослідних центрів, які спеціалізуються на комп’ютерному аналізі текстів, наприклад Centre for Computer Assisted Qualitative Data Analysis Software (м.Суррей, Велика Британія), Centre for Social Anthropology and Computers (м.Кент, Велика Британія), добре відомі центри ZUMA – Zentrum für Umfragen Methoden und Analysen (м.Мангейм, Німеччина), Qualitative Solutions and Research (м.Ла Троуб, Австралія) [31].
Сучасні технології контент-аналізу і особливості Text Mining
Перші програми кількісного контент-аналізу зосереджували увагу в основному на підрахунку частот певних характеристик тексту. Більшість сучасних програм контент-аналізу також обмежені обробкою тексту, проте їхні можливості набагато ширші:
- зберігання даних та управління ними
Дозволяє зберігати у формі текстових першоджерел або в спеціальному форматі, а також зберігати різноманітний аудіовізуальний матеріал: фотографії, діаграми, відео- та аудіозаписи, зв’язки з Web- сторінками; додатково аналітик має змогу анотувати, редагувати тексти, автоматично індексувати й записувати власну супроводжувальну інформацію.
- пошук даних
Програми дозволяють шукати текстові дані за вказаними словами чи фразами, підраховувати частоту відповідних слів, шукати інформацію за заданим контекстом, а також різноманітними додатковими даними на зразок дати, хто брав інтерв’ю, звідки з'явилися дані тощо.
- кодування
Процес кодування робиться відносно простим; є можливість робити окремі дані більш істотними та відносити їх до певної категорії, називати, об'єднувати і розділяти категорії, формувати концептуальну схему для розвитку теорії.
- розвиток і перевірка теорії
Дозволяє застосовувати різноманітні теоретичні моделі для побудови теорій і представлення результатів.
- написання звітів
Дозволяє готувати звіти для різноманітних категорій або відтворювати відповідні фрагменти документів у формі цитат, таблиць, графічних зображень тощо; є змога формувати в програмі "журнал", у який можна записувати пояснення, ідеї, що виникають, та виводити його на друк або у файл [32].
Логіка технології
Комп’ютерний контент-аналіз має власну логіку розвитку – технологічну. Саме ця логіка розвинулася в програмах четвертого покоління. До програм четвертого покоління будемо відносити програми, які, будучи втіленням контент-аналізу, "убудовують" його в інші технології.
Прикладом технології цього покоління є технологія "видобування" даних або Text Mining (більш повна назва – Text Analysis and Knowledge Mining System). Text Mining – це алгоритмічне виявлення на основі статистичного і лінгвістичного аналізу, а також штучного інтелекту раніше невідомих зв'язків і кореляцій у вже існуючих неструктурованих текстових даних для проведення значеннєвого аналізу, забезпечення навігації і пошуку в неструктурованих текстах з кінцевою метою одержання нової цінної інформації – знань. Text Mining являє собою логічне продовження і поєднання цілого ряду методик і методів, зокрема технології Data Mining, контент-аналізу, статистичного аналізу тощо [33].
Чимало науковців вважають, що такі програми беруть свій початок від програм видобування інформації і близьких до них (FRUMP)[34].
До важливих піонерських досліджень з Text Mining М.Діксон відносить два:
- роботи дослідницької групи з Гельсінського університету [35], яка намагалася використати технологію Data Mining до неструктурованих попередньо необроблених текстових масивів.
- роботи Р.Фельдмана [36], в основу яких покладено встановлення значущих для тексту понять (концептів) і визначення взаємозв’язку між документами і цими поняттями, тобто фактично здійснення класифікації тексту [37].
Система Document Explorer, запропонована Р.Фельдманом, спочатку будує базу даних на основі сукупності досліджуваних документів різних видів, у тому числі з Інтернет, а потім аналізує їх, використовуючи техніку видобування знань і графічний підхід.
Технологія Text Mining працює зі структурованими базами даних фактів, видобуває зразки (шаблони) зі звичайних текстів, призначених для читання людьми, а не комп’ютерами. Водночас, як і більшість когнітивних технологій, Text Mining – це не просто пошук серед великих масивів готової, кимсь іншим уже створеної інформації, а насамперед виявлення раніше невідомої і ніде не записаної інформації, а точніше, алгоритмічне виявлення раніше непомічених зв’язків як в самих текстах, так і внаслідок їх спільного читання. Крім того, часто на початку досліджень аналітик сам достеменно не знає, яка конкретно інформація йому потрібна та де її шукати.
Починаючи із середини 1990-х років, як напрям аналізу неструктурованих даних технологія Text Mining взяла за основу не лише методи класичного видобування знань, але й останні досягнення контент-аналізу: класифікацію, кластеризацію, виділення понять, фактів, шаблонів тощо [38].
Технологічними компонентами Text Mining є:
- інформаційний пошук (відбір релевантних записів або текстових баз даних для наступного опрацювання);
- інформаційна переробка (виділення зразків на основі відібраних даних);
- інформаційна інтеграція (поєднання комп’ютерного виведення інформації з пізнавальним можливостями людини)[39].
Саме при реалізації другої компоненти Text Mining здійснює такі види аналізу, як:
- виявлення або видобування інформації;
- відслідковування категорій або тем;
- резюмування або реферування документів;
- класифікація або категоризація тексту;
- кластеризація або групування;
- прогнозування;
- знаходження винятків;
- пошук пов'язаних ознак, полів, понять окремих документів;
- візуалізація даних;
- відповіді на запитання або Q&A [40].
Приклад моделі [41] "видобування" даних представлено на рисунку[42]:
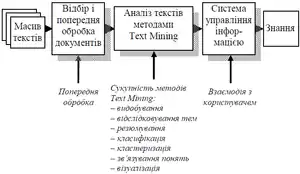
Наведені в таблицях дані показують, які методи Text Mining використовуються різними комерційними програмами та в різних сферах людської діяльності (за версією Б. М. Юськіва) [43].
| Сфери людської діяльності | Методи Text Mining | |||||||
| Видобування інформації | Відслідковування тем | Підсумовування (узагальнення) | Виділення понять | Зв'язування ознак | Кластеризація | Візуалізація інформації | Відповіді на запитання | |
| Медицина | ||||||||
| Питання, які найчастіше ставляться (FAQ's) | + | + | + | + | ||||
| Наркотичні проекти | + | + | + | |||||
| Нові способи лікування | + | + | ||||||
| Бізнес | ||||||||
| Конкурентний аналіз | + | + | ||||||
| Аналіз медіа впливів | + | |||||||
| Поточне інформування | + | |||||||
| Порушення прав приватної власності | + | + | + | |||||
| Підтримка питань клієнтів, які найчастіше ставляться (FAQ's) | + | + | + | + | ||||
| Дослідження соціальних мереж | + | |||||||
На сьогодні системи Text Mining, як правило, реалізуються у вигляді масштабних систем зі складними математичними і лінгвістичними алгоритмами аналізу, для яких характерним є розвинений графічний інтерфейс, багаті можливості візуалізації та маніпулювання даними, доступ до різних джерел даних, функціонування в архітектурі клієнт-сервер [44]. За даними Центру технологічної політики і оцінювання (Technology Policy and Assessment Center – TPAC) Джорджіанського інституту технологій, станом на кінець 2000р. в Інтернеті було представлено понад 70 інструментальних систем Text Mining [45].
Сфери застосування
Одним із найперспективніших напрямів узагальнення інформаційних потоків є контент-моніторинг. Його ідею можна сформулювати як постійно здійснюваний в часі контент-аналіз неперервних інформаційних потоків. Серед принципів побудови системи моніторингу виділяють системність, адресність і предметну спрямованість. У ній текстовий потік досліджується на підставі заданих конфігураційних характеристик (наборів кількісних параметрів або слів, що супроводжують визначені теми і поняття). Він опрацьовується багаторазово, з додаванням характеристик, отриманих із самого потоку. Методологічну основу дослідження складає контент-аналіз. У результаті генерується, а потім наочно відображається узагальнена інформація. З появою систем Text Mining контент-моніторинг отримав реальну і потужну програмну основу [46].
До сучасних і перспективних напрямів використання Text Mining також відносяться:
- пошук всеохопної і релевантної інформації на основі текстових баз даних;
- визначення інфраструктури заданих технологічних і наукових дисциплін і напрямів;
- здійснення тематичної структуризації певних сфер діяльності та взаємозв’язку між темами;
- виявлення нових напрямів досліджень, появи нових ідей у рамках певних дисциплін і на стику дисциплін;
- прогнозування технологічного розвитку [47].
Особливої уваги заслуговує інноваційне прогнозування [48]. Один із різновидів прогнозів базується на бібліометриці: підраховуючи число публікацій,патентів, відповідних згадувань у виступах науковців, можна виміряти та інтерпретувати напрями технологічного розвитку. Ці вимірювання узагальнюються у формі інноваційних індикаторів технологій, які можуть свідчити про стадію життєвого циклу технологій, інноваційний контекстуальний вплив даної технології на інші, розвиток ринкового потенціалу тощо. Ще один метод прогнозування базується на картографії новинних повідомлень, що дозволяє ідентифікувати споріднені групи технологій і ресурсів, взаємовпливи різних груп технологій, локалізувати дослідницькі домени та встановлювати коло їхніх інтересів [49].
Надзвичайно перспективним напрямом Text Mining є технологічна конкурентна розвідка (Competitive Technological Intelligence). Її значення і використання особливо зросло в 1990-х роках, коли посилилася технологічна конкуренція, і компанії, університети та урядові організації відчули особливу потребу в знаннях про нові і перспективні технології. Значна частина результатів технологічною розвідкою отримується на основі пошуків з використанням технологій Text Mining. Актуальність розробок Text Mining добре засвідчує застосування їх Федеральними службами і агентствами США [50]. Так, дослідження GAO від травня 2004 р.[51] засвідчило, що з 128 служб, які вивчалися, 52 використовували або планували використовувати технології Data Mining і Text Mining. Цілі їх використання надзвичайно різноманітні: починаючи від поліпшення обслуговування населення і завершуючи аналізом і виявленням терористичної і злочинної діяльності. Аналітиками GAO виявлено 199 випадків застосувань технології видобування знань, з яких 68 пов'язані з плануванням роботи і 131 – з оперативною діяльністю [50].
У березні 2001 р. в ряді російських і українських інтернет-видань [52] з'явилися повідомлення про використання Управлінням розвитку інформаційних технологій, яке є частиною директорату науки і технології ЦРУ США, Text Mining для роботи з відкритими джерелами інформації. Окремі вітчизняні публікації відсилають до першоджерела – матеріалу на сайті "Вашингтон пост". Мова йшла про застосування розвідувальним відомством трьох комп’ютерних систем – Oasis, FLUENT, Text Data Mining.
Oasis пов'язаний із медіа-моніторингом як систематичних, так і випадкових джерел, які охоплюють друковані видання, цифрові матеріали, графічні зображення, аудіоінформацію 35 мовами світу.
Комп'ютерна технологія FLUENT призначена для пошуку інформації в текстових документах. Маючи на вході ключові слова англійською мовою, система тут же перекладає їх на ряд інших мов, шукає інформацію в текстових базах даних з документами на різних мовах і повертає аналітику результати пошуку після автоматичного перекладу. FLUENT дозволяє перекладати англійською мовою з китайської, корейської, португальської, російської, сербсько-хорватської, української та інших мов. Ще одна програма, Text Data Mining, дозволяє автоматично створювати візуальні образи текстових документів, а також отримувати дані про частоту використання тих або інших слів.
Перелічені технології ЦРУ використовує для відслідковування незаконних фінансових операцій і наркотрафіку.
Також Text Mining можна використовувати як інтегратори новин, які інтегрують інформаційні потоки, здійснюючи контент- моніторинг новин у Web-просторі як базу для своєї роботи. Наприклад, Northern Light Technology є клієнтом однієї з величезних служб збору новин COMTEX, що інтегрує ресурси солідних джерел, серед яких такі світові інформаційні агентства, як Associated Press, ИТАР-ТАСС, Синьхуа. Клієнтами COMTEX, у свою чергу, є десятки новинних служб: OneSource, Screaming Media, Vertical Net, CompuServe та інші. Технологія моніторингу і подальшої синдикації Інтернет-новин передбачає етапи: "навчання" програм збору інформації структурі відібраних джерел, сканування інформації, приведення її до внутрішньосистемного формату, класифікація, кластеризація, передача користувачам через різноманітні канали, у тому числі e-mail, WWW, Wap, SMS.
Відзначається, що технологія Text Mining знаходиться лише на початку своєї "кар’єри". Однак навіть зараз вона видаються дуже перспективною [53].
Підсумок
Контент-аналіз у своєму розвитку пройшов шлях від наукового методу формалізованого аналізу змісту мас-медіа до широко застосовуваної високотехнологічної методики.
Як було показано, у процесі становлення контент-аналізу можна виділити такі етапи:
- його зародження
До 1920-х років – характеризується описовою та інтуїтивною методологією, розвиваються різноманітні підходи до аналізу та порівняння текстів у інтерпретаційних контекстах, насамперед засобів масових комунікацій, ранній газетний аналіз, графологічний аналіз, аналіз мрій.
- формування основ "класичного" контент-аналізу
1920-ті – 1940-ві роки – розвиваються систематичні основи кількісного контент-аналізу, знову ж таки в рамках масових комунікацій, розвиток відбувається практично разом з теорією і практикою пропаганди.
- міждисциплінарне розширення і диференціація
1950-ті – 1960-ті роки – методологія не лише розвиває свої теоретичні основи, але й знаходить шлях до різноманітних дисциплін, насамперед лінгвістики, психології, соціології, історичних наук, мистецтва тощо.
- розвиток теоретичних основ та розширення практичного застосування
1970-ті – 1980-ті роки – удосконалення і застосування різноманітних моделей зв'язку, аналіз невербальних комунікацій, а також розвиток нових різновидностей, зокрема якісного контент-аналізу, удосконалення методики, насамперед за рахунок використання нових можливостей комп’ютерної техніки.
- період "глобального" розвитку
Від 1990-х років – період, пов’язаний із використанням контент-аналізу в практиці діяльності найрізноманітніших суб’єктів, починаючи від науковців, які ознайомлені з його методикою та свідомо її застосовують, і завершуючи пересічними користувачамиІнтернет, практична більшість з яких, мабуть, і не підозрюють, що пошук інформації для них здійснюють програми із убудованими елементами контент-аналізу.
Тепер не наука чи засоби масової інформації є найбільшими користувачами контент-аналізу, а державні та недержавні установи, політичні партії, аналітичні центри, комерційні структури, зацікавлені в здобутті нових знань. Нинішні контент-дослідження пов’язані з переробкою величезних текстових масивів на основі Інтернет-технологій та комп’ютерних технологій видобування знань на зразок Text mining і Web-mining, побудованих значною мірою на ідеях контент-аналізу. Із ними ж пов’язана перспектива розвитку контент-аналізу найближчих років [54].
Джерела
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід. — Рівне.: Перспектива, 2006. — 203 с.
- Іванов О.В. Комп’ютерний контент-аналіз: проблеми та перспективи вирішення / О. В. Іванов // Вісник Харківського національного університету імені В.Н.Каразіна. Серія: Методологія, теорія та практика соціологічного аналізу сучасного суспільства. — Харків: Харківський національний університет ім. В.Н.Каразіна, 2009. — Випуск 15.
- Іванов О.В. Класичний контент-аналіз та аналіз тексту: термінологічні та методологічні відмінності / Іванов Олег Валерійович // Вісник Харківського національного університету імені В.Н. Каразіна, Харків: Видавничий центр ХНУ імені В. Н. Каразіна, 2013. – №1045. – С. 69-74.
Примітки
- Іванов О.В. Класичний контент-аналіз та аналіз тексту: термінологічні та методологічні відмінності / Іванов Олег Валерійович // Вісник Харківського національного університету імені В.Н. Каразіна, Харків: Видавничий центр ХНУ імені В. Н. Каразіна, 2013. – No1045. – С. 71
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.116
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 114-115
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 117
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 118
- Bernard H.R., Ryan G. Text Analysis: Qualitative and Quantitative Methods…– P.625.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 117-118
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 119-120
- Іванов О.В. Комп’ютерний контент-аналіз: проблеми та перспективи вирішення / О. В. Іванов // Вісник Харківського національного університету імені В.Н.Каразіна. Серія: Методологія, теорія та практика соціологічного аналізу сучасного суспільства. — Харків: Харківський національний університет ім. В.Н.Каразіна, 2009. — Випуск 15. — С. 336
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 120
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 121
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 122-123
- Iker H.P., Harway N.I. A Computer Systems Approach Toward the Recognition and Analysis of Content // The Analysis of Communication Content / Gerbner G.A. et al. (eds.).– Wiley & Sons, 1969.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 126
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 127
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 127-129
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С. 130-131
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.131
- Kelle U. Computer-Aided Qualitative Data Analysis: An Overview // Text Analysis and Computers / Cornelia Zuell, Janet Harkness, Juergen H.P. Hoffmeyer-Zlotnik (Eds.). Zentrum für UmfragenMethoden und Analysen (ZUMA).– Mannheim (Germany): ZUMA, 1996.–– P.36.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.131-132
- Alexa M., Zuell C. Commonalities, differences and limitations of text analysis Software: The results of a review / Zentrum für Umfragen Methoden und Analysen (ZUMA). ZUMA-Arbeitsbericht 99/06.– Mannheim (Germany): ZUMA, 1999.– Р.2.– http://www.gesis.org/Publikationen/Berichte/ZUMA_Arbeitsberichte/99/99_06.pdf Архівовано 10 червня 2007 у Wayback Machine.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.133
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.134
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.134-135
- Lombard M., Snyder-Duch J., Bracken C.C. Practical Resources for Assessing and Reporting Intercoder Reliability in Content Analysis Research Projects. – 2004.– http://www.temple.edu/mmc/reliability/ Архівовано 7 жовтня 2008 у Wayback Machine.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.136
- Macnamara J.R. Media Content Analysis: Its Uses, Benefits & Best Practice Methodology / CARMA International (Asia Pacific).– Chippendale (Australia): CARMA, 2003.– Р.8.– www.masscom.com.au/book/papers/media_content.html– Р.8.
- Barry C.A. Choosing Qualitative Data Analysis Software: Atlas/ti and Nudist Compared // Sociological Research Online.– 1998.– Vol. 3.– No.3.– http://www.socresonline.org.uk/socresonline/3/3/4.html%5Bнедоступне+посилання+з+липня+2019%5D (2004.05.14)
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.137
- Morris R.Computerized content analysis in management research: a demonstration of advantages & limitations // Journal of Management.– Winter.– 1994.–http://www.findarticles.com/p/articles/mi_m4256/is_n4_v20/ai_16549030.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.138-139
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.139-140; Lacey A., Luff D. Trent Focus for Research and Development in Primary Health Care: An Introduction to Qualitative Analysis.– Trent Focus, 2001.– http://www.trentfocus.org.uk/Resources/Qualitative%20Data%20Analysis.pdf Архівовано 15 травня 2005 у Wayback Machine.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.141
- Dixon M. An Overview of Document Mining Technology.– October 4, 1997.– https://web.archive.org/web/20011120163231/http://www.geocities.com/ResearchTriangle/Thinktank/1997/mark/writings/dm.html ; Wilks Y. Information extraction as a core language technology // Information Extraction: A Multidisciplinary Approach to an Emergine Information Technology.– Vol. 1299.– June 1997.– PP.1-9.
- Ahonen H., Heinonen O., Klemettinen M., Verkamo A.I. Mining in the phrasal frontier // Proceedings of PKDD'97 / 1st European Symposium on Principles of Data Mining and Knowledge Discovery.– Norway.– Trondheim.– June 1997.
- Feldman R., Klosgen W., Ben-Yehuda Y., Kedar G., Reznikov V. Pattern based browsing in document collections // Principles of data mining and knowledge discovery. – June 1997.– Vol. 1263.– PP.112-122.
- Dixon M. An Overview of Document Mining Technology.– October 4, 1997.–https://web.archive.org/web/20011120163231/http://www.geocities.com/ResearchTriangle/Thinktank/1997/mark/writings/dm.html
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.142-143
- Kostoff R. Text Mining for Global Technology Watch / Office of Naval Research (ONR) Science & Technology.– 2001.– http://www.onr.navy.mil/sci_tech/special/technowatch/default.htm Архівовано 5 квітня 2009 у Wayback Machine. ; Kostoff R. Information Extraction From Scientific Literature with Text Mining / Office of Naval Research (ONR) Science & Technology.– 2001.– http://www.onr.navy.mil/sci_tech/special/technowatch/default.htm Архівовано 5 квітня 2009 у Wayback Machine.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.143-146
- Fan W., Wallace L., Rich S., Zhang Z. Tapping into the Power of Text Mining // Communications of ACM.– February 16, 2005.– http://filebox.vt.edu/users/wfan/paper/text_mining_final_preprint.pdf Архівовано 24 серпня 2014 у Wayback Machine.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.147
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.148-149
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.150
- Text Mining: Review of TPAC Technologies for ONR // ASDL.– Aug. 2002.– http://www.asdl.gatech.edu/research_teams/pdf/2002/Text%20Mining%20Sum.doc Архівовано 11 вересня 2006 у Wayback Machine.
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.151
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.151; Text Mining: Review of TPAC Technologies for ONR // ASDL.– Aug. 2002.– http://www.asdl.gatech.edu/research_teams/pdf/2002/Text%20Mining%20Sum.doc Архівовано 11 вересня 2006 у Wayback Machine.
- Watts R.J., Porter A.L. Innovation Forecasting // Technology Policy and Assessment Center (TPAC) at Georgia Institute of Technology.– 2002.– http://www.tpac.gatech.edu/toa/inov.shtml%5Bнедоступне+посилання+з+липня+2019%5D
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.151-152
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.152
- Data Mining. Federal Efforts Cover a Wide Range of Uses: Report to the Ranking Minority Member, Subcommittee on Financial Management, the Budget, and International Security, Committee on Governmental Affairs, U.S. Senate / GAO (United States General Accounting Office).– GAO-04-548.– Washington, D.C. – May 2004.– 71 p.– http://www.epic.org/privacy/profiling/gao_dm_rpt.pdf
- Ландэ Д. Добыча знаний…; ЦРУ начинает просеивать информацию // Сетевой журнал. Лента новостей.– Вып. от 14.03.2001.– http://www.setevoi.ru/cgi-bin/srch.pl?id=579 Архівовано 9 жовтня 2016 у Wayback Machine. ; ЦРУ извлекает данные // Компьютер-информ.– 2001.– №6.– http://www.ci.ru/inform06_01/p245moz.htm ; Гордиенко И. Понять и заставить // Компьютерра. – 10.04.2001.– http://www.ibusiness.ru/offline/2001/158/8585/print.html%5Bнедоступне+посилання+з+липня+2019%5D
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.153-154
- Юськів Б. М. Контент-аналіз. Історія розвитку і світовий досвід: Монографія. / Б. М. Юськів — Рівне.: «Перспектива», 2006. — С.155-156
