Порядок байтів
Порядок байтів (англ. Endianness, byte order) — метод запису байтів багатобайтових чисел в інформатиці. У програмуванні, інформація в пам'яті зазвичай зберігається у двійкових даних, розділена на 8 біт (один байт).
У загальному випадку, для представлення числа M, більшого 255 ( — максимальне ціле число, що записується одним октетом), доводиться використовувати декілька байтів-октетів. При цьому число M записується в позиційній системі числення за основою 256:


Набір цілих чисел кожне з яких лежить в інтервалі від 0 до 255, є послідовністю байтів, складових числа M. при цьому називається молодшим байтом, а — старшим байтом числа M.



Походження назви
Терміни big-endian і little-endian запозичено у Джонатана Свіфта з його сатиричного твору «Мандри Гуллівера», де описуються держави Ліліпутія і Блефуску, що вели між собою протягом багатьох років війни через розбіжності з приводу того, з якого кінця слід розбивати варені яйця («гострого» чи «тупого» кінця («little-» and «big-endians»)).
Варіанти запису
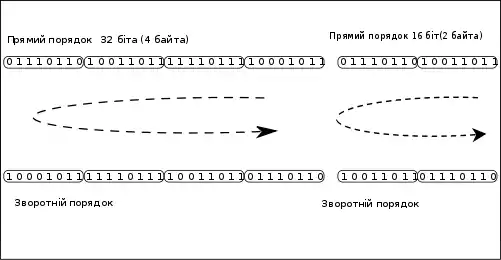
Порядок від старшого до молодшого
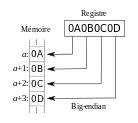
Порядок від старшого до молодшого або (англ. big-endian, дослівно: «тупокінцевий»): , Запис починається зі старшого і закінчується молодшим. Цей порядок є стандартним для протоколів TCP/IP, він використовується в заголовках пакетів даних і в багатьох протоколах більш високого рівня, розроблених для використання поверх TCP/IP. Тому, порядок байтів від старшого до молодшого часто називають мережевим порядком байтів (англ. network byte order). Цей порядок байтів використовується процесорами IBM 360/370/390, Motorola 68000, SPARC (звідси третя назва — порядок байтів Motorola, Motorola byte order).

Порядок від молодшого до старшого
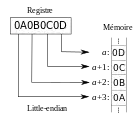
Порядок від молодшого до старшого або (англ. little-endian, дослівно: «гострокінцевий», про походження терміна нижче): , запис починається з молодшого і закінчується старшим. Цей порядок запису прийнятий в пам'яті персональних комп'ютерів з x86 — процесорами, у зв'язку з чим іноді його називають «інтелівський» порядок байтів (за назвою фірми-творця архітектури x86) . У деяких колах використовується назва англ. VAX order, наприклад, в документації Perl[1].
На противагу «тупокінцевому» порядку, менше крос-платформних протоколів і форматів даних із «загостреним» порядком байтів; помітні винятки: USB, конфігурація PCI, таблиця розділів GUID, рекомендації FidoNet .
Змінюваний порядок
Різні процесори можуть працювати і в порядку від молодшого до старшого, і в зворотному, наприклад, ARM, PowerPC (але не PowerPC 970), DEC Alpha, MIPS, PA-RISC і IA-64. Зазвичай порядок байтів вибирається програмно під час ініціалізації операційної системи, але може бути вибраний і апаратними перемичками на материнській платі. У цьому випадку правильніше говорити про порядок байтів операційної системи. Змінюваний порядок байтів іноді називають англ. bi-endian.
Змішаний порядок
Змішаний порядок байтів (англ. middle-endian) іноді використовується при роботі з числами, довжина яких перевищує машинне слово. Число представляється послідовністю машинних слів, які записуються у форматі, природному для даної архітектури, але самі слова слідують у зворотному порядку.
Класичний приклад middle-endian — представлення 4-байтних цілих чисел на 16-бітних процесорах сімейства PDP- 11 (відомий як PDP-endian) . Для представлення двохбайтних значень (слів) використовувався порядок little-endian , але 4-х байтне подвійне слово записувалося від старшого слова до молодшого.
У процесорах VAX і ARM використовується змішане уявлення для довгих дійсних чисел .
Приклад
Далі наведено приклад, в якому описується розміщення 4-байтового числа в ОЗП ЕОМ, доступ до якого може проводитися і як до 32-розрядного слова, і побайтно.
Всі числа записані в 16-ковій системі числення.
| Представлення | D4*0x01 + C3*0x100 + B2*0x10000 + A1*0x1000000 | |
| Порядок від молодшого до старшого | (little-endian) | 0xD4, 0xC3, 0xB2, 0xA1 |
| Порядок від старшого до молодшого | (big-endian) | 0xA1, 0xB2, 0xC3, 0xD4 |
| Порядок, прийнятний в PDP-11 | (PDP-endian) | 0xB2, 0xA1, 0xD4, 0xC3 |
Порівняння

Істотною перевагою little-endian в порівнянні з big-endian є те, що порядком запису вважається можливість «неявної типізації» цілих чисел при читанні меншого обсягу байт (за умови, що прочитане число поміщається в діапазон). Так, якщо в комірці пам'яті міститься число 0x00000022, то прочитавши його як int16 (два байти) ми отримаємо число 0x0022 , прочитавши один байт — число 0x22 . Однак, це ж може вважатися одночасно недоліком, тому що це може спричинити помилки втрати даних.
Навпаки, вважається що у little-endian, в порівнянні з big-endian є «неочевидність» значення байтів пам'яті відлагодженні (послідовність байтів (A1, B2, C3, D4) насправді це означає 0xD4C3B2A1, для big-endian ця послідовність (A1, B2, C3, D4) читалася б «природним» для арабського запису чисел чином: 0xA1B2C3D4). Найменш зручним у роботі вважається middle-endian формат запису. Він зберігся тільки на старих платформах. Для запису довгих чисел (чисел, довжина яких істотно перевищує розрядність машини) зазвичай переважає порядок слів у числі little-endian (оскільки арифметичні операції над довгими числами здійснюються від молодших розрядів до старших) Порядок байтів в слові — звичайний для даної архітектури.
Проблеми сумісності
Запис багатобайтового числа з пам'яті комп'ютера в файл або передача по мережі потребує дотримання відповідностей про те, який з байтів є старшим, а який молодшим. Прямий запис комірок пам'яті призводить до можливих проблем при перенесенні додатку з платформи на платформу.
Визначення порядку байтів
Порядок байтів в конкретній машині можна визначити за допомогою програми на мові Сі (testendian.c):
#include <stdio.h>
unsigned short x = 1; /* 0x0001 */
int main(void)
{
printf("%s\n", *((unsigned char *) &x) == 0 ? "big-endian" : "little-endian");
return 0;
}
Вивід даної програми має сенс тільки на платформах, де розмір типу unsigned short більший, ніж розмір типу unsigned char. Це правильно на переважній більшості комп'ютерів, оскільки вони мають 8-розрядний байт. Однак існують і апаратні платформи, в яких розмір байта рівний розміру слова (або, в термінах мови C: sizeof (char) == sizeof (int)). Наприклад, в суперкомп'ютерах Cray.
Результати запуску на big-endian машині (SPARC):
$ uname -m
sparc64
$ gcc -o testendian testendian.c
$ ./testendian
big-endian
Результати запуску на little-endian машині (x86):
$ uname -m
i386
$ gcc -o testendian testendian.c
$ ./testendian
little-endian
Дійсні числа
Зберігання дійсних чисел може залежати від порядку байт; так, на x86 використовуються формати IEEE 754 зі знаком і порядком числа в старших байтах.
Юнікод
Якщо Юнікод записаний у вигляді UTF-16 або UTF-32, то порядок байтів є суттєвим. Одним із способів позначення порядку байтів в юнікодових текстах є встановлення на початку спеціального символу BOM (byte-order mark), маркер послідовності байтів, U + FEFF) — «перевернутий» варіант цього символу (U + FFFE) не існує і не допускається в текстах.
Символ U + FEFF зображується в UTF-16 послідовністю байтів 0xFE 0xFF (big-endian) або 0xFF 0xFE (little-endian), а в UTF-32 — послідовністю 0x00 0x00 0xFE 0xFF (big-endian) або 0xFF 0xFE 0x00 0x00 (little -endian).
Конвертація
Для перетворення між мережним порядком байтів (англ. network byte order), який завжди у форматі big-endian, і порядком байтів, що використовується на машині (англ. host byte order), стандарт POSIX передбачає функції htonl (), htons (), ntohl (), ntohs ():
uint32_t htonl (uint32_t hostlong);- конвертує 32-бітну беззнакову величину з локального порядку байтів в мережевій;uint16_t htons (uint16_t hostshort);- конвертує 16-бітну беззнакову величину з локального порядку байтів в мережевій;
uint32_t ntohl (uint32_t netlong);- конвертує 32-бітну беззнакову величину з мережевого порядку байтів в локальний;uint16_t ntohs (uint16_t netshort);- конвертує 16-бітну беззнакову величину з мережевого порядку байтів в локальний.
У разі збігу поточного порядку байтів і мережевого, функції можуть бути «порожніми» (тобто, не змінювати порядку байтів). Стандарт також допускає, щоб ці функції були реалізовані макросами.
Існує багато мов і бібліотек із засобами конвертації в обидва основні порядку байт і навпаки.
Ядро Linux: le16_to_cpu (), cpu_to_be32 (), cpu_to_le16p (), і так далі;
Ядро FreeBSD: htobe16 (), le32toh (), і так далі;
<<Count:32/big-unsigned-integer, Average:64/big-float>> = Chunk
Message = <<Length:32/little-unsigned-integer,
MType:16/little-unsigned-integer, MessageBody>>
import struct
Count, Average = struct.unpack(">Ld", Chunk)
Message = struct.pack("<LH", Length, MType) + MessageBody
Perl:
($Count, $Average) = unpack('L>d>', $Chunk);
$Message = pack('(LS)<', $Length, $MType) . $MessageBody;
(або те ж саме: $Message = pack('Vv', $Length, $MType) . $MessageBody;)
дані приклади для Erlang, Python, Perl містять ідентичну функціональність.