R*-дерево
R*-дере́ва (англ. R*-trees) — один з варіантів R-дерев, що застосовується для індексування просторової інформації. R*-дерева мають дещо вищу конструктивну витратність, ніж стандартні R-дерева, оскільки дані можуть потребувати повторного вставляння; але отримуване в результаті дерево зазвичай матиме кращу продуктивність запитів. Як і стандартне R-дерево, воно може зберігати як точкові, так і просторові дані. Його було запропоновано Норбертом Бекманом, Гансом-Петером Крігелем, Ральфом Шнайдером та Бернардом Сіґером 1990 року.[1]
Різниця між R*-деревами та R-деревами

Для продуктивності R-дерев вирішальне значення має мінімізація як покриття, так і перекриття. Перекриття означає, що при запиті або вставлянні даних розкриття потребує більш ніж одна гілка дерева (через те, що дані розщеплюються на області, які перекриваються). Мінімізоване покриття покращує продуктивність обрізання, дозволяючи частіше виключати з пошуку цілі блоки, зокрема для заперечних запитів за областями. R*-дерево намагається зменшувати і те, і те, застосовуючи поєднання переглянутого алгоритму розщеплення вузлів, та поняття примусового повторного вставляння при переповненні вузлів. Це ґрунтується на тому спостереженні, що структури R-дерев є дуже чутливими до порядку, в якому вставляються їхні записи, так що структура, побудована вставлянням (а не одночасним завантаженням) є ймовірно не зовсім оптимальною. Вилучення та повторне вставлення записів дозволяє їм «знаходити» місце в дереві, що може бути більш підхожим, ніж їхнє первинне місце.
При переповненні вузла частина записів вилучається з нього, і вставляється до дерева повторно. (Для того, щоби уникнути невизначеного каскаду повторних вставлень, спричиненого наступним переповненням вузла, процедура повторного вставлення може викликатися лише по одному разу на кожному рівні дерева при вставленні будь-якого одного нового запису.) Це дає ефект вироблення краще кластеризованих груп записів у вузлах, що зменшує покриття вузлів. Крім того, фактичні розщеплення вузлів часто відкладаються, в результаті чого середня заповненість вузла зростає. Повторне вставлення можна розглядати як метод поступової оптимізації дерева, що спрацьовує при переповненні вузла.
Продуктивність
- Покращена евристика розщеплення виробляє блоки, що є ближчими до квадратних, і відтак кращими для багатьох застосувань.
- Метод повторного вставляння оптимізує наявне дерево, але підвищує складність.
- Дієво підтримує як точкові, так і просторові дані одночасно.
| Дія різних евристик розщеплення на базі даних із поштовими округами Німеччини | ||||||
|---|---|---|---|---|---|---|
|
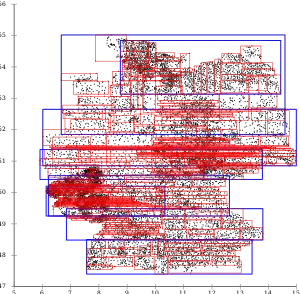
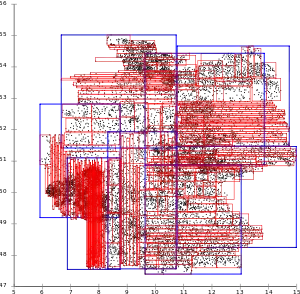

Алгоритм та складність
- Для операцій здійснення запитів та вилучення R*-дерево використовує той же самий алгоритм, що й звичайне R-дерево.
- При вставлянні R*-дерево застосовує комбіновану стратегію. Для листкових вузлів мінімізується перекриття, тоді як для внутрішніх вузлів мінімізуються поширення та площа.
- При розщепленні R*-дерево застосовує топологічне розщеплення, яке обирає вісь розщеплення на основі периметру, а потім мінімізує перекриття.
- На додачу до вдосконаленої стратегії розщеплення, R*-дерево також намагається уникати розщеплень, повторно вставляючи об'єкти та піддерева до дерева, під натхненням ідеї балансування B-дерева.
Таким чином, складність запиту та вилучення у найгіршому випадку є ідентичними до R-дерева. Стратегія вставляння до R*-дерева з є складнішою за стратегію лінійного розщеплення () R-дерева, але менш складною, ніж стратегія квадратичного розщеплення () для розміру блока в об'єктів, і має незначний вплив на загальну складність. Загальна складність вставляння залишається порівня́нною з R-деревом: повторне вставлення зачіпає щонайбільше одну з гілок дерева, і відтак повторних вставлень, порівня́нно до виконання розщеплення на звичайному R-дереві. Отже, в цілому складність R*-дерева є такою ж, як і в звичайного R-дерева.





Реалізація повного алгоритму мусить враховувати багато межових випадків та вузьких ситуацій, не обговорених тут.
Примітки
- Beckmann, N.; Kriegel, H. P.; Schneider, R.; Seeger, B. (1990). The R*-tree: an efficient and robust access method for points and rectangles. Proceedings of the 1990 ACM SIGMOD international conference on Management of data - SIGMOD '90. с. 322. ISBN 0897913655. doi:10.1145/93597.98741. Архів оригіналу за 17 квітня 2018. Процитовано 19 березня 2016. (англ.)
- Guttman, A. (1984). R-Trees: A Dynamic Index Structure for Spatial Searching. Proceedings of the 1984 ACM SIGMOD international conference on Management of data - SIGMOD '84. с. 47. ISBN 0897911288. doi:10.1145/602259.602266. (англ.)
- Ang, C. H.; Tan, T. C. (1997). New linear node splitting algorithm for R-trees. У Scholl, Michel; Voisard, Agnès. Proceedings of the 5th International Symposium on Advances in Spatial Databases (SSD '97), Berlin, Germany, July 15–18, 1997. Lecture Notes in Computer Science 1262. Springer. с. 337–349. doi:10.1007/3-540-63238-7_38. (англ.)
Посилання
Бібліотеки, що містять R*-дерева: