R-дерево
R-дерево (англ. R-trees) — деревоподібна структура даних, яка використовується для організації доступу до просторових даних, тобто для індексації багатовимірної інформації, такої, наприклад, як географічні координати, прямокутники або многокутники. R-дерево було запропоноване в 1984 році Антоніном Гуттманном[1] і знайшло значне застосування як у теоретичному, так і у прикладному аспектах[2]. Типовим запитом з використанням R-дерев міг би бути такий: «Знайти всі музеї у радіусі 2 кілометрів від мого поточного місця розташування» або «знайти всі дороги в межах 2 кілометрів від мого поточного місця розташування» (для навігаційної системи). R-дерево також прискорює пошук найближчого сусіда[3] для різних метрик відстані, включаючи відстань по сфері.[4]
| R-tree | ||
|---|---|---|
| Тип | Дерево | |
| Винайдено | 1984 | |
| Винайшли | Антонін Гуттманн | |
| Обчислювальна складність у записі великого О | ||
| Середня | Найгірша | |
| Простір | ||
| Пошук | O(logMn) | |
| Вставляння | O(n) | |
| Видалення | ||
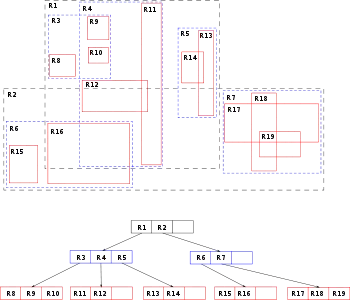
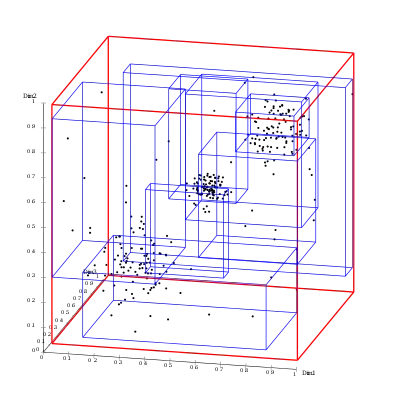
У випадку двовимірного простору, ця структура даних розбиває простір на множину ієрархічно вкладених прямокутників, які можуть перетинатись. У разі тривимірного або багатовимірного простору це будуть прямокутні паралелепіпеди.
Алгоритми вставки і видалення використовують ці обмежуючі прямокутники для забезпечення того, щоб «близько розташовані» об'єкти були поміщені в одну листову вершину. Зокрема, новий об'єкт потрапить у ту листову вершину, для якої потрібно найменше розширення її прямокутника. Кожен елемент листової вершини зберігає два поля даних: спосіб ідентифікації даних, що описують об'єкт, (або самі ці дані) і прямокутник, який обмежує цей об'єкт.
Аналогічно, алгоритми пошуку (наприклад, перетин, включення, окіл) використовують обмежуючі прямокутники для прийняття рішення про необхідність пошуку в дочірній вершині. Таким чином, більшість вершин ніколи не використовуються при пошуку. Як і у випадку з B-деревами, ця властивість R-дерев обумовлює їх придатність для баз даних, де вершини можуть вивантажуватися на накопичувач в міру необхідності.
Для розділення переповнених вершин можуть застосовуватися різні алгоритми, що породжує поділ R-дерев на підтипи: квадратичні та лінійні.
Спочатку R-дерева не гарантували гарних характеристик для найгіршого випадку, хоча добре працювали на реальних даних. Однак, в 2004-му році був опублікований новий алгоритм, що визначає пріоритетні R-дерева. Стверджується, що цей алгоритм ефективний, як і найбільш ефективні сучасні методи, і в той же час є оптимальним для найгіршого випадку.[5]
Структура R-дерева
Кожна вершина R-дерева має змінну кількість елементів (не більше деякого заздалегідь заданого максимуму). Кожен елемент не листової вершини зберігає два поля даних: спосіб ідентифікації дочірньої вершини і обмежує прямокутник (кубоїд), що охоплює всі елементи цієї дочірньої вершини. Всі збережені кортежі зберігаються на одному рівні глибини, таким чином, дерево ідеально збалансовано. При проектуванні R-дерева потрібно задати деякі константи:
- maxNumOfEntries — максимальне число дітей у вершини
- minNumOfEntries — мінімальне число дітей у вершини, за винятком кореня.
Для коректної роботи алгоритмів необхідно, щоб minNumOfEntries <= maxNumOfEntries / 2. У кореневій вершині може бути від 2 до maxNumOfEntries нащадків. Часто вибирають minNumOfEntries = 2, тоді для кореня виконуються ті ж умови, що і для інших вершин. Також іноді розумно виділяти окремі константи для кількості точок в листових вершинах, так як їх часто можна робити більше.
Ідея R-дерева
Основна ідея структури даних полягає в групі прилеглих об'єктів і представляти їх з їх мінімальним обмежувальним прямокутником в наступному вищому рівні дерева; звідси ця буква «R» (англ. rectangle) у назві R-дерева. Так як всі об'єкти знаходяться в межах цього контурного прямокутника, запит, який не перетинає прямокутник також не може перетинати будь-який з об'єктів прямокутника. На рівні листка, кожен прямокутник описує один об'єкт; на більш високих рівнях агрегації все більше об'єктів. Це також можна розглядати як збільшення грубої апроксимації набору даних.
За аналогією з В-деревом, R-дерево також збалансоване дерево пошуку (так що всі вузли листя знаходяться на однаковій висоті), організовує дані в сторінках, і призначене для зберігання на диску (як воно використовується в базах даних). Кожна сторінка може містити максимальну кількість записів, які часто позначаються як . Це також гарантує мінімальні заповнення (для кореневого вузла, як виняток), проте краще виконання було представлено з мінімальним заповненням 30 %-40 % від максимальної кількості входів (B-дерева гарантують 50 % заповнення сторінки, а В*-дерева навіть 66 %). Причиною цього є необхідність більш складного балансування для просторових даних, на відміну від лінійних даних, що зберігаються в B-деревах.

Як і з більшістю дерев, алгоритми пошукових (наприклад, перетин, локалізації, пошук найближчого сусіда) досить прості. Ключова ідея полягає в тому, щоб використати обмежуючі рамки, для прийняття рішення, чи варто шукати всередині піддерева. Таким чином, більшість вузлів в дереві ніколи не читали під час пошуку. На відміну від B-дерев, це робить R-дерева, придатними для великих наборів даних і баз даних, де вузли можуть бути вивантажені в пам'яті, коли це необхідно, і все дерево не може зберігатися в оперативній пам'яті.
Основні труднощі R-дерев є створення ефективного дерева, яке, з одного боку, збалансоване (так що вузли листа знаходяться на тій же висоті) з іншого боку прямокутниками не покривають занадто багато порожнього простору і не перекривають один одного занадто (так що під час пошуку, менше піддерева повинні бути оброблені). Наприклад, початкова ідея для вставки різних елементів, щоб отримати ефективне дерево — вставляти в піддерево, яке вимагає найменшого розширення його обмежувальної рамки. Після того, як сторінка заповнилась, дані розбиваються на дві групи, які повинні охоплювати мінімальну площу кожного. Більшість досліджень і удосконалень для R-дерев спрямована на поліпшення шляху побудови дерева і можуть бути згруповані в два об'єкти: побудова ефективного дерева з нуля (відомий як насипний завантаженням) і виконання змін в існуючому дереві (вставка і видалення).
R-дерева не гарантують гарну продуктивність в поганому випадку, але в цілому добре працюють з реальними даними.[6] У той час як більш теоретичний інтерес, (насипна завантаженим) Пріоритетне R-дерево — це найбільш оптимальний варіант R-дерева в найгіршому випадку,[5] але через підвищену складність, йому не приділялося багато уваги в практичних додатках до цих пір.
Коли дані організовані в R-дереві, найближчі К-сусіди (для будь-якого Lp-Norm) всіх точок ефективно можна обчислити за допомогою просторового об'єднання.[7] Це вигідно для багатьох алгоритмів, заснованих на найближчих К сусідах, наприклад Local Outlier Factor. DeLi-Clu,[8] Density-Link-Clustering є алгоритмом кластерного аналізу, який використовує структуру R-дерева для подібного роду просторового приєднання ефективно обчислювати кластеризацію OPTICS.
Різновиди
- R*-дерево
- R+ дерево
- Гільбертове R-дерево
- X-дерево
Алгоритми
Вставка
Побудова R-дерева відбувається, як правило, за допомогою багаторазового виклику операції вставки елемента в дерево. Ідея вставки схожа на вставку в B-дерево: пробуємо додати крапку в підходящу листову вершину, якщо вона переповнюється, поділяємо її і, поки вимагається, ділимо її предків. Наведемо нижче класичний алгоритм вставки, описаний Антоніном Гуттманном.
Функція insert
- викликає chooseLeaf, щоб вибрати лист, куди ми хочемо вставити крапку. Якщо вставка здійснена, то дерево могло бути поділено, і розкол міг дійти до вершини. У цьому випадку chooseLeaf повертає дві розколоті вершини splittedNodes для вставки в корінь
- викликається функція adjustBounds, яка розширює обмежує прямокутник кореня на вставляється точку
- перевіряє, якщо chooseLeaf повернула ненульові splittedNodes, то дерево росте на рівень вгору: з цього моменту коренем оголошується вершина, діти якої ті самі splittedNodes
Функція chooseLeaf
- якщо на вході лист (база рекурсії), то:
- викликає функцію doInsert, яка здійснює безпосередню вставку елемента в дерево і повертає два листи, якщо відбулося розділення
- змінює обмежуючий прямокутник вершини з урахуванням вставленої точки
- повертає splittedNodes, які нам повернув doInsert
- якщо на вході не листова вершина:
- з усіх нащадків вибирається той, чиї кордони вимагають мінімального збільшення для вставки даної точки
- рекурсивно викликається chooseLeaf для обраного нащадка
- поправляються обмежуючі прямокутники
- якщо splittedNodes від рекурсивного виклику нульові, то покидаємо функцію, інакше:
- якщо numOfEntries <maxNumOfEntries, то додаємо нову вершину до дітей, чистимо splittedNodes
- інакше (коли немає місць для вставки), ми конкатенуємо масив дітей з новою вершиною і передаємо отримане функції linearSplitNodes або іншої функції поділу вершин, і повернемо з chooseLeaf ті splittedNodes, які нам повернула використовувана функція поділу.
Функція linearSplit
Для поділу вершин можуть використовуватися різні алгоритми, це один з них. Він має всього лінійну складність і просто реалізується, правда видає не саме оптимальне розділення. Однак практика показує, що такої складності зазвичай достатньо.
- по кожній координаті для всього набору поділюваних вершин обчислюється різниця між максимальною нижньою межею прямокутника з цієї координаті та мінімальної верхньої, потім ця величина нормалізується на різницю між максимальною і мінімальною координатою точок вихідного набору для побудови всього дерева
- знаходиться максимум цього нормалізованого розкиду по всіх координатах
- встановлюємо як перших дітей для повертаних вершин node1 і node2 ті вершини з вхідного списку, на яких досягався максимум, видаляємо їх з вхідного списку, коригуємо bounds для node1 і node2
- далі, виконується вставка для решти вершин:
- якщо в списку залишилося настільки мало вершин, що якщо їх все додати в одну з вихідних вершин, то в ній виявиться minNumOfEntries вершин, то в неї додається залишок, повернення з функції
- якщо в якійсь з вершин вже набраний максимум нащадків, то залишок додається в протилежну, повернення
- для чергової вершини зі списку порівнюється, на скільки треба збільшити обмежує прямокутник при вставці в кожну з двох майбутніх вершин, де менше — туди її і вставляється
Функція фізичної вставки doInsert
- якщо в вершині є вільні місця, то точка вставляється туди
- якщо ж місць немає, то діти вершини конкатенуються з точкою, яка додається, і викликається функція linearSplit або іншу функцію поділу, що повертає дві розділені вершини, які ми повертаємо з doInsert
Розбиття за допомогою алгоритмів кластеризації
Іноді замість R-дерева використовують так зване cR-дерево (c означає clustered). Основна ідея в тому, що для розділення вершин або точок використовуються алгоритми кластеризації, такі як k-means. Складність k-means теж лінійна, але він в більшості випадків дає кращий результат, ніж лінійний алгоритм поділу Гуттмана, на відміну від якого він не тільки мінімізує сумарну площу огинаючих паралелепіпедів, але і відстань між ними і площа перекриття. Для кластеризації точок використовується обрана метрика початкового простору, для кластеризації вершин можна використовувати відстань між центрами їх огинаючих паралелепіпедів або максимальною відстанню між ними.
Алгоритми кластеризації не враховують те, що число нащадків вершини обмежено зверху і знизу константами алгоритму. Якщо кластеризація видає неприйнятний результат, можна використовувати для цього набору класичний алгоритм, так як на практиці таке відбувається не часто.
Цікава ідея використовувати кластеризацію на кілька кластерів, де кілька може бути більше двох. Однак треба враховувати, що це накладає певні обмеження на параметри структури R-дерева.
Відзначимо, що крім cR-дерева існує його варіація clR-дерево, засноване на методі кластеризації, де як центр використаний ітераційний алгоритм розв'язання «задачі розміщення». Алгоритм має квадратичну обчислювальну складність, але забезпечує побудову більш компактних огинаючих паралелепіпедів у записах вершин структури.
Пошук
Пошук в дереві досить тривіальний, треба лише враховувати той факт, що кожна точка простору може бути покрита декількома вершинами.
| Вплив різних розщеплень евристики на базі даних з американськими поштовими районами | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
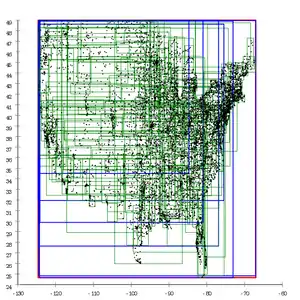
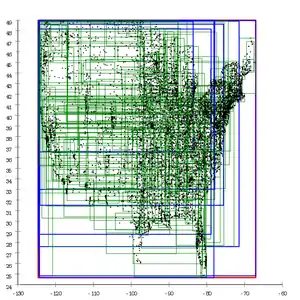

Обговорення R-дерев
Переваги
- ефективно зберігають локалізовані в просторі групи об'єктів
- збалансовані, значить, швидкий пошук в гіршому випадку
- вставка / видалення однієї точки не вимагає істотної перебудови дерева (динамічний індекс)
Недоліки
- чутливе до порядку додавання даних
- обмежують прямокутники вершин можуть перекриватися
Примітки
- Guttman, A. (1984). R-Trees: A Dynamic Index Structure for Spatial Searching. Proceedings of the 1984 ACM SIGMOD international conference on Management of data – SIGMOD '84. с. 47. ISBN 0897911288. doi:10.1145/602259.602266.
- Y. Manolopoulos; A. Nanopoulos; Y. Theodoridis (2006). R-Trees: Theory and Applications. Springer. ISBN 978-1-85233-977-7. Процитовано 8 жовтня 2011.
- Roussopoulos, N.; Kelley, S.; Vincent, F. D. R. (1995). Nearest neighbor queries. Proceedings of the 1995 ACM SIGMOD international conference on Management of data – SIGMOD '95. с. 71. ISBN 0897917316. doi:10.1145/223784.223794.
- Schubert, E.; Zimek, A.; Kriegel, H. P. (2013). Geodetic Distance Queries on R-Trees for Indexing Geographic Data. Advances in Spatial and Temporal Databases. Lecture Notes in Computer Science 8098. с. 146. ISBN 978-3-642-40234-0. doi:10.1007/978-3-642-40235-7_9.
- Arge, L.; De Berg, M.; Haverkort, H. J.; Yi, K. (2004). The Priority R-tree. Proceedings of the 2004 ACM SIGMOD international conference on Management of data – SIGMOD '04. с. 347. ISBN 1581138598. doi:10.1145/1007568.1007608.
- Hwang, S.; Kwon, K.; Cha, S. K.; Lee, B. S. (2003). Performance Evaluation of Main-Memory R-tree Variants. Advances in Spatial and Temporal Databases. Lecture Notes in Computer Science 2750. с. 10. ISBN 978-3-540-40535-1. doi:10.1007/978-3-540-45072-6_2.
- Brinkhoff, T.; Kriegel, H. P.; Seeger, B. (1993). Efficient processing of spatial joins using R-trees. ACM SIGMOD Record 22 (2): 237. doi:10.1145/170036.170075.
- Achtert, E.; Böhm, C.; Kröger, P. (2006). DeLi-Clu: Boosting Robustness, Completeness, Usability, and Efficiency of Hierarchical Clustering by a Closest Pair Ranking. LNCS: Advances in Knowledge Discovery and Data Mining. Lecture Notes in Computer Science 3918: 119–128. ISBN 978-3-540-33206-0. doi:10.1007/11731139_16.
- Greene, D. (1989). An implementation and performance analysis of spatial data access methods. [1989] Proceedings. Fifth International Conference on Data Engineering. с. 606–615. ISBN 0-8186-1915-5. doi:10.1109/ICDE.1989.47268.
- Ang, C. H.; Tan, T. C. (1997). New linear node splitting algorithm for R-trees. У Scholl, Michel; Voisard, Agnès. Proceedings of the 5th International Symposium on Advances in Spatial Databases (SSD '97), Berlin, Germany, July 15–18, 1997. Lecture Notes in Computer Science 1262. Springer. с. 337–349. doi:10.1007/3-540-63238-7_38.
- Beckmann, N.; Kriegel, H. P.; Schneider, R.; Seeger, B. (1990). The R*-tree: an efficient and robust access method for points and rectangles. Proceedings of the 1990 ACM SIGMOD international conference on Management of data – SIGMOD '90. с. 322. ISBN 0897913655. doi:10.1145/93597.98741. Архів оригіналу за 17 квітня 2018. Процитовано 23 січня 2017.
Посилання
- Spatial Index Library
- R-tree Portal
- R*-tree або індексація геопросторових даних
- Revisiting R-tree Construction Principles. Sotiris Brakatsoulas, Dieter Pfoser, and Yannis Theodoridis
- Гулаков В. К., Трубаков А. О. Багатовимірні структури даних. 2010. 387 стр. ISBN 978-5-89838-515-6
