UWN project
Проє́кт UWN (англ. UWN project) — науково-дослідний проєкт, присвячений створенню лексико-семантичної онтологічної бази знань української та, в перспективі, російської мови. Як основу для побудови онтології проєкт використовує характерні для сімейства WordNet структурні елементи: синсети (набори синонімів, що описують єдине поняття) та набори семантичних (22 типи) і лексичних (12 типів) зв'язків. Не зважаючи на схожість логічних структур, архітектурно створювана в проєкті онтологія суттєво відрізняється як від онтологій типу WordNet, так і від інших проєктів, що можуть розглядатися як бази загальних знань доступних для автоматичного використання (ConceptNet, Cyc, Wikipedia). З точки зору архітектури UWN відноситься до онтологій створених на базі СУБД, що дозволило об'єднати в одному місці дані про зовнішній світ та логіку їх обробки. Базова архітектура UWN описана в статті [1]
Історія
Перша версія онтологічної бази знань була розроблена в 2009, тоді ж на основі даних WordNet в рамках державної цільової науково-технічної програми "Образний комп'ютер" на базі UWN було створено та апробовано семантичну метапошукову систему для пошуку на англійській мові в мережі Інтернет. Офіційною датою народження UWN вважається 1 липня 2010, коли до розвитку проєкту підключився колектив фахівців факультету кібернетики КНУ ім. Т. Шевченка. На даний момент в проєкті взяло участь уже понад 100 студентів, аспірантів та викладачів факультету. Керівництво проєктом здійснює декан факультету Анісімов Анатолій Васильович.
Найбільший внесок в розбудову проєкту зробили фахівці з комп'ютерної лінгвістики кафедри МІ. Даною групою було розроблено методики асоціативно-семантичного контекстного аналізу з використанням онтологій, що базуються на обчисленні семантичних відстаней між ключовими елементами тексту. Дані методики було використано при розробці алгоритмів для вирішення прикладних задач з автоматичної інтелектуальної обробки природномовних текстів (таких як визначення тематик текстів, семантична фільтрація потоків даних за змістом, смислове покращення якості машинного перекладу, семантичний пошук в Інтернет, аналіз настрою тексту та багато інших). Ключові ідеї групи описано в роботах [2], [3], [4], [5]. Саме ці практично апробовані алгоритми та моделі було покладено в основу програмного комплексу призначеного для обробки природномовних текстів в середині UWN.
Основні завдання проєкту
Проєкт має вирішити наступні завдання [6]:
- створення англомовної, україномовної та російськомовної лексикографічних баз знань універсального характеру
- забезпечення міжмовних зв'язків між концептами онтологій
- створення гнучкої архітектури системи, що дозволяє вносити значні зміни в структуру даних без впливу на стандартний процес роботи UWN
- реалізація принципу "логіка та дані в одному місці"
- забезпечення онлайн доступу до онтологічної бази
- забезпечення сумісної та одночасної роботи користувачів та автоматизованих систем
- вичерпність бази (обсяг даних понад 120000 концептів)
Архітектура
Базова архітектура UWN описана в статті [1]. Проте, з моменту свого створення система зазнала ряду значних змін пов'язаних з розбудовою бази знань, розширенням наявного лінгвістичного функціоналу, змінами в механізмах безпеки і логування та забезпеченням одночасної роботи великої кількості користувачів. Основні принципи що мали виконуватися при створенні архітектури [7]:
- заснована на СУБД
- онтології кожної мови реалізовано у вигляді окремих логічних одиниць
- серверну логіку згруповано за функціональним призначенням у програмні одиниці - пакети
- відсутність прямого доступу до даних
- наявність спеціальних інтерфейсів (API) для забезпечення роботи з даними та логікою онтології
- розділення рівня доступу за системами та користувацькими профілями
- наявність централізованого контролю за доступом до даних та систем
- гнучкість системи, здатність до розширення новими функціями, системами та даними без втрати наявної функціональності
- забезпечення сумісної роботи великої кількості користувачів в т.ч. через різні системи
- можливість включення до системи нових підсистем для збору, аналізу та показу аналітичних даних
Використання СУБД як платформи дозволяє широко застосовувати дворівневу (клієнт-серверну) архітектуру, де СУБД виконує роль сервера та БД, а web- або десктоп- додаток роль клієнта. Основними елементами бази даних є наступні блоки(схеми) [8]:
- ua_guest – схема, що використовується для підключення до БД всіма клієнтами.
- ua_security – схема, що відповідає за розрізнення профілів доступу систем-додатків, інтерфейси доступу до серверної логіки, механізми логування і т.д.
- ua_ontology – схема, що зберігає інформацію про наповнення україномовної онтології та серверну логіку, що застосовується програмами-додатками для доступу до неї.
- en_ontology – схема, що зберігає інформацію про наповнення англомовної онтології та серверну логіку, що застосовується програмами-додатками для доступу до неї.
- ru_ontology – схема, що запланована для зберігання інформації російськомовної онтології.
- ua_alg – схема, що призначена для зберігання різноманітних семантичних алгоритмів та методів вимірювання ступеню семантичної зв’язності.
- ua_morphology – схема, що призначена для зберігання морфологічної інформації для української мови, також на базі даної схеми працюють алгоритми перевірки правопису та підбору варіантів правильного написання слова.
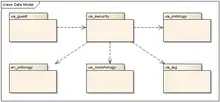
В цілому, внутрішня структура UWN є досить складною та сильно взаємозв’язаною, але назовні система пропонує ряд простих у використанні та добре задокументованих інтерфейсів (API). Наразі існує два типи інтерфейсів доступу до БД:
1) старий – інтерфейс типу get, який пропонує лише методи отримання інформації з онтології. Серед них: пошук синсетів, у які входить певне слово; побудова ієрархічних дерев за різними типами зв’язку; пошук синонімів і т.д. Цей інтерфейс використовується в ескізному проєкті семантичної пошукової системи та альфа-версіях клієнтів для перегляду наповнення онтології.
2) новий – інтерфейс типу get/set, призначений, в першу чергу, для внесення змін в БД. Використовується в клієнтських додатках типу онтокоректорів та онторедакторів.
Література
- Глибовець М.М., Марченко О.О., Никоненко А.О. «Побудова україномовної онтології засобами СУБД», Наукові записки. Національний університет "Києво-Могилянська академія". - Том 86 : Комп’ютерні науки (2008. стр. 46-50) http://biblio.ukma.kiev.ua/e-lib/NZ/NZV86_2008_computer/08_glybovets_mm.PDF%5Bнедоступне+посилання+з+червня+2019%5D
- Анісімов А.В., Марченко О.О., Никоненко А.О. «Алгоритмічна модель асоціативно-семантичного контекстного аналізу природномовних текстів», науковий журнал «Проблеми Програмування» (2008 №2-3, стр. 379-384) http://eprints.isofts.kiev.ua/401/1/%231_D50-c379.pdf Архівовано 2 травня 2018 у Wayback Machine.
- А.В. Анисимов, К.С. Лиман, А.А. Марченко «Методы вычисления мер семантической близости слов естественного языка» // Журнал «Искусственный Интеллект» (2009, №3 стр. 612-617) http://www.nbuv.gov.ua/portal/natural/ii/2010_3/AI_2010_3%5C3%5C00_AnisimovLiman_Marchenko.pdf%5Bнедоступне+посилання+з+червня+2019%5D
- Никоненко А.А. «Обзор баз знаний онтологического типа» // Журнал «Искусственный Интеллект» (2009, №4 стр. 208-219) http://www.nbuv.gov.ua/portal/natural/ii/2009_4/4%5C00_Nikonenko_AA.pdf%5Bнедоступне+посилання+з+червня+2019%5D
- Марченко А.А., Никоненко А.А. «Контекстный семантический анализ текста. Система текстового мониторинга и качественного оценивания фокусного объекта» // Журнал «Искусственный Интеллект» (2008, №3 стр. 808-813) http://www.nbuv.gov.ua/portal/natural/ii/2008_3/JournalAI_2008_3/Razdel9/02_Marchenko_Nikonenko.pdf
- Никоненко А.О. «Проект UWN: Методологія створення універсальної онтологічної бази знань української мови» // Слайди міжнародної наукової конференції MegaLing’2011 «Горизонти прикладної лінгвістики та лінгвістичних технологій» Партеніт, Крим, Україна http://lingvoworks.org.ua/index.php?option=com_jotloader&task=files.download&cid=1427%5Bнедоступне+посилання+з+червня+2019%5D
- Никоненко А.О. «Проект UWN: Методологія створення універсальної онтологічної бази знань української мови» // Тези міжнародної наукової конференції MegaLing’2011 «Горизонти прикладної лінгвістики та лінгвістичних технологій» Партеніт, Крим, Україна (2011 стр. 57-58) http://megaling.crimea.edu/publications/2011_Nikonenko.rtf Архівовано 22 вересня 2015 у Wayback Machine.
- Никоненко А.О. «Проект UWN: Досвід створення універсальної онлайн онтології української мови» // Тези міжнародної наукової конференції ISDMCI'2011 «Интеллектуальные системы принятия решений и проблемы вычислительного интеллекта», Євпаторія, Крим, Україна (2011 стр. 92-96) Посилання на збірник доповідей конференції Архівовано 5 березня 2016 у Wayback Machine.
