Векторна модель
Векторна модель (англ. vector space model) — в інформаційному пошуку алгебраїчне представлення колекції документів векторами одного спільного для всієї колекції векторного простору.
Векторна модель є основою для вирішення багатьох завдань інформаційного пошуку, таких як: пошук документа за запитом, класифікація документів, кластеризація документів.
Визначення
Документ у векторній моделі розглядається як невпорядкована множина термів. Термами в інформаційному пошуку називають слова, з яких складається текст, а також такі елементи тексту, як, наприклад, 2010, II-5 або Тянь-Шань.
Різними способами можна визначити вагу терма в документі — «важливість» слова для ідентифікації цього тексту. Наприклад, можна просто підрахувати кількість вживань терма в документі, так звану частоту терма, — чим частіше слово зустрічається в документі, тим більша у нього буде вага. Якщо терм не зустрічається в документі, то його вага в цьому документі дорівнює нулю.
Всі терми, які трапляються в документах оброблюваної колекції, можна впорядкувати. Якщо тепер для деякого документа виписати по порядку ваги всіх термів, включаючи ті, яких немає в цьому документі, вийде вектор, який і буде представленням цього документа у векторному просторі. Розмірність цього вектора, як і розмірність простору, дорівнює кількості різних термів у всій колекції, і є однаковою для всіх документів.
Більш формально


де dj — векторне уявлення j-го документа, wij — вага i-го терма в j-му документі, n — загальна кількість різних термів у всіх документах колекції.
Маючи таке подання для всіх документів, можна, наприклад, знаходити відстань між точками простору і тим самим вирішувати задачу подоби документів — чим ближче розташовані точки, тим більше схожі відповідні документи. У разі пошуку документа за запитом, запит теж представляється як вектор того ж простору — і можна обчислювати відповідність документів запиту.
Застосування
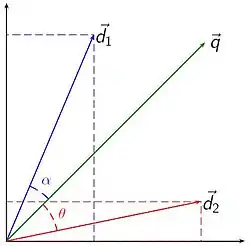
Рейтинг релевантності документів у пошуку за ключовими словами можна обчислити, використовуючи припущення про теорію спільних рис документа, порівнявши відхилення кутів між кожним вектором документу та оригінальним вектором запиту, де запит представлений як той же самий вид вектора як документа. На практиці легше обчислити косинус кута між векторами замість самого кута:

Де — перетин (тобто скалярний добуток) документу та вектори запиту, — нормаль вектора d2, к — нормаль вектора q. Нормаль вектора обчислюється наступною формулою:



Оскільки всі вектори, що розглядуються цією моделлю поелементно невід'ємні, нульовий косинус означає, що запит і вектор документа ортогональні і не збігаються (тобто в документі, що розглядають, не існує терму запит). Подивіться статтю косинусний коефіцієнт для отримання додаткової інформації.
Міра TF-IDF
У класичній векторній моделі, запропонованій Салтоном, Вонгом та Янгом[1], певні для слова міри в векторах документа — це продукти локальних та глобальних параметрів. Модель, відома як tf-idf модель. Маса вектора для документу d:
, де


та
- це частота терміну терму t у документі d (локальний параметр)
- це зворотна частота документу(глобальний параметр). — це загальна кількість документів у наборі документів; — це кількість документів, що містять терм t.




З використанням косинусу, подібність між документом dj та запитом q можна обчислити так:

Переваги
Векторна модель має наступні переваги над моделлю Standard Boolean:
- Проста модель, заснована на лінійній алгебрі
- Міра терміну не двійкова(бінарна)
- Дозволяє обчислювати нескінчену кількість подібностей між запитами та документами
- Дозволяє оцінювати документи згідно з їхньою можливою релевантністю
- Дозволяє часткові збіги
Обмеження
Векторна модель має наступні обмеження:
- Великі документи погано представлені, тому що вони мають недостатньо змінних подібності(маленький скалярний добуток та велика розмірність)
- Ключові слова у пошуку повинні точно відповідати термінам документа; підрядки терма можуть привести до «похибки першого роду»
- Семантична чутливість; документи зі схожим контекстом, але різним словником термів не пов'язані, видаючи у результаті «похибку другого роду»
- Порядок, у якому терми з'являються у документі, втрачається у векторному зображенні
- Теоретично передбачається, що терми статистично незалежні
- Вимірювання інтуїтивне, та не дуже формальне
Хоча багато з цих складностей можна подолати за допомогою інтеграції різних інструментів, включаючи математичні методи, такі як сингулярний розклад матриці та лексичні бази даних, такі як WordNet.
Моделі, засновані на векторній моделі та доповнюють її
Моделі, що засновані на векторній моделі та ті, що її доповнюють:
- Узагальнена векторна модель
- Латентно-семантичний аналіз
- Дискримінація термів
- Класифікація Роше
- Випадкове індексування
Програми, що реалізовують векторну модель
Наступні пакети програм можуть зацікавити бажаючих поекспериментувати з векторною моделлю та реалізувати пошукові служби, засновані на них.
Безкоштовні загальнодоступні програми
- Apache Lucene. Apache Lucene — високо-продуктивна бібліотека для повнотекстного пошуку, повністю написана на Java.
- Gensim — платформа Python+NumPy для векторного моделювання. Вона містить поетапні алгоритми для Tf-idf, латентно-семантичного індексування, рандомних проектувань та латентного розміщення Дирихле.
- Weka. Weka — популярний пакет збору даних для Java, що включає моделі WordVectors та Bag of words.
Примітки
- G. Salton, A. Wong, C. S. Yang, A vector space model for automatic indexing, Communications of the ACM, v.18 n.11, p.613-620, Nov. 1975
Література
- Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze An Introduction to Information Retrieval Draft. Online edition. Cambridge University Press. — 2009. — 544 pp.
- Daniel Jurafsky, James H. MartinSpeech and Language Processing. An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Second Edition. Pearson Education International. — 2009. — 1024 pp.
- G. Salton, A. Wong, and C. S. Yang (1975), "A Vector Space Model for Automatic Indexing, " Communications of the ACM, vol. 18, nr. 11, pages 613—620. (Article in which a vector space model was presented)
- David Dubin (2004), The Most Influential Paper Gerard Salton Never Wrote (Explains the history of the Vector Space Model and the non-existence of a frequently cited publication)
- Description of the vector space model
- Description of the classic vector space model by Dr E. Garcia
- Relationship of vector space search to the «k-Nearest Neighbor» search
Посилання
- Apache Lucene — програмна реалізація інформаційного пошуку, заснована на векторній моделі.