Значення форми
Значення форми (англ. shape context) — характеристика опису, що використовується в розпізнаванні об’єктів. Термін було запропоновано Сержем Белонгі та Джинтендра Маліком в їхній статті "Matching with Shape Contexts" (2000).[1]
Теорія
Характеристика призначена для опису форм з метою вимірювання їхньої подібності та відновлення точкових відповідностей.[1] Основною ідеєю є вибір n точок контуру форми. Для кожної точки pi форми розглядаються n − 1, векторів, отриманих шляхом з'єднання точки pi з усіма іншими точками. Множина усіх цих векторів є описом локалізованої форми локалізованої в цій точці, але цей опис є занадто деталізованим. Ключова ідея полягає в тому, що розподіл по відносній позиції є надійним, компактним і характерним ідентифікатором. Таким чином, для точки pi, груба гістограма відносних координат решти n − 1 точок,

визначається як форма контексту . Стовпчики гістограми (англ. – bins) зазвичай приймають рівномірними в полярних координатах. Підтвердження факту, що форма контексту є характерним ідентифікатором, можна побачити на малюнку нижче, де зображено форми контекстів двох різних варіантів написання літери «А».

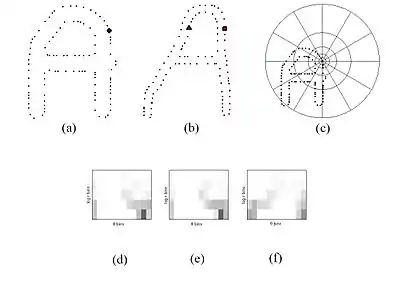
На мал. (a) і (b) зображено точки контурів двох форм. На мал. (c) є зображення в полярних координатах, призначене для розрахунку значення форми. На мал. (d) зображено значення форми для круга, на мал. (e) – значення форми ромба, на мал. (f) – значення форми трикутника. Як можна помітити з малюнків (d) та (e), значення форми для двох тісно пов'язаних точок, дуже схожі, в той час як значення форми на малюнку (f) істотно відрізняється.
Тепер для того, щоб ідентифікатор ознаки (характеристики) був корисний, він повинен мати інваріанти. Зокрема, він має бути інваріантним відносно перенесення, масштабування, наявності невеликих завад та залежати від повороту. Незмінність значення форми при перенесенні є зрозумілою. Незмінність при масштабуванні досягається за рахунок нормалізації всіх радіальних відстаней середнім значенням відстані між всіма парами точок форми.[2][3] Для нормалізації також може бути використана медіанна відстань.[1][4] Емпірично продемонстровано, що при використанні множини синтетичних точок для експериментів[5] , значення форми є стійким до деформації, шумів і відхилень.[4]

Можна забезпечити стійкість значення форми також і при повороті. Один зі способів – виміряти кути в кожній точці по відношенню до напрямку дотичної в цій точці (оскільки точки обираються на краях). В результаті буде отримано абсолютно стійкий до повороту ідентифікатор. Але це не завжди бажано, оскільки деякі локальні характеристики втрачають їхнє описове значення, якщо вимірюються не по відношенню до того ж базису. Багато додатків не використовують стійкість до повороту, щоб, наприклад відрізняти цифри «6» та «9».
Використання в зіставленні форм
Завершена система, що використовує значення форми для зіставлення, складається з таких кроків:
- Довільним чином обрати множину точок, що лежать на краях відомої форми та множину точок, що належать невідомій формі.
- Для кожної точки, знайденої на кроці 1, обрахувати значення форми.
- Зіставити кожну точку відомої форми з точкою невідомої форми. Для зменшення кількості співставлень, спершу потрібно обрати перетворення (наприклад, афінне), що перетворює межі відомої форми в межі невідомої форми. Потім обрати точку невідомої форми, що найбільш точно відповідає кожній перетвореній точці відомої форми.
- Обчислити відстань між значеннями форми для кожної пари точок цих двох форм. Варто використати зважену суму відстаней між значеннями форми, відстань обробки зображення та силу вигину (міра, що вказує наскільки сильні перетворення потрібні, щоб зрівняти дві форми).
- Для визначення невідомої формі, використовуйте Класифікатор найближчого сусіда, щоб порівняти його форму з формою відомих об'єктів.
Деталі реалізації
Крок 1: Визначення списку точок на краях форми
Цей підхід припускає, що форма об'єкта, по суті, визначається скінченною підмножиною точок, що належать внутрішнім або зовнішнім контурам об'єкта. Множина цих точок може бути отримана за допомогою детектора країв Канні (англ. – Canny edge detector) і вибору випадкового набору точок з цих країв. Зверніть увагу, що ці точки не повинні і в більшості випадків не відповідають ключовим точкам, таким як максимуми кривизни або точкам перегину (англ. – inflection points). Бажано обирати форми з приблизно рівномірним інтервалом, хоча це не критично.[2]
Крок 2: Обчислення значення форми
Цей крок докладно описаний у розділі Теорія.
Крок 3: Розрахунок матриці вартості
Розглянемо дві точки p і q, для яких маємо нормалізовані гістограми з K стовпцями – g(k) і h(k). Оскільки значення форми – розподіли представлені у вигляді гістограм, то закономірно використати статистичний χ2 тест як "вартість форми контексту" для двох точок:

Це значення змінюється в діапазоні від 0 до 1.[1] Окрім показника вартості значення форми, може бути використаний показник додаткової вартості, що ґрунтується на зовнішньому вигляді. Наприклад, це може бути міра несхожості тангенса кута (застосовується при розпізнаванні цифр):

Це половина довжини хорди одиничного кола між одиничними векторами з кутами і . Знайдене значення також змінюється від 0 до 1. Загальна вартість співставлення двох точок може бути розрахована як зважена сума двох вищезгаданих вартостей:



Тепер для кожної точки pi першої форми та точки qj другої форми, потрібно розрахувати загальну вартість, як описано вище, і позначити це значення Ci,j. Обраховані значення вартостей для всіх точок формують матрицю вартостей.
Крок 4: Знаходження такого зіставлення, яке мінімізує загальну вартість
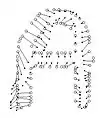
Тепер потрібно знайти таке попарне співставлення кожної точки pi першої форми, з точкою qj другої форми, що мінімізує загальну вартість зіставлення:

Це може бути виконано за час , використовуючи угорський метод (Hungarian method) , хоча існують більш ефективні алгоритми.[6] Щоб отримати надійну обробку відхилень, можна додати "штучні" вузли, які мають постійну, але досить велику вартість співставлення по відношенню до матриці вартостей. Це змусить алгоритм зіставляти точки, що є відхиленнями, з штучно введеними точками тільки у випадку, якщо немає реального зіставлення.

Крок 5: Моделювання перетворень
Враховуючи безліч відповідностей між скінченною множиною точок двох фігур перетворення може бути оцінене як співставлення будь-якої точки однієї фігури з точкою іншої фігури. Кілька варіантів такого перетворення описані нижче.

Афінне перетворення
Афінне перетворення є стандартним вибором: . Розв’язок методом найменших квадратів матриці і вектор зміщення o обчислюють наступним чином:



Де з аналогічним виразом для . є псевдо оберненою матрицею для .



Крок 6: Обчислення значення форми
Тепер знайдемо відстань між значеннями двох форм і . Ця відстань є зваженою сумою трьох значень:

Відстань значення форми: це симетрична сума вартості зіставлень значень форми для точок з найкращою відповідністю:

де T(•) – це розраховане перетворення, що перетворює точки форми Q в точки форми P.
Вартість входження: Після встановлення відповідностей та правильно перетворення одного зображення в інше, можна визначити вартість входження, як суму квадратів різниць інтенсивностей в вікні Гаусса навколо відповідних точок зображення:

де та зображення в градаціях сірого кольору ( зображення після перетворення) і Гауссівська функція.



Вартість перетворення: Остаточна вартість вимірює перетворення, що потрібні, щоб вирівняти два зображення.

Тепер маючи спосіб обчислення відстані між двома формами, можемо застосувати класифікатор (k-NN) найближчого сусіда з відстанню, яка визначається як відстань форми. Результати застосування наведені в наступному розділі.
Результати
Розпізнавання цифр
Автори Серж Белонгі та Джинтендра Малік випробували їхній підхід на базі даних рукописних цифр. Більше, ніж 50 алгоритмів було протестовано на цій базі даних. База містить 60,000 навчальних зразків і 10,000 тестових зразків. Коефіцієнт помилок для цього підходу становив 0.63% для використаних 20,000 навчальних зразків. На даний момент, найнижчий рівень помилок становить 0.35%.
Пошук торгових марок
Значення форми були використані для отримання найбільш подібних торгових знаків з бази даних за запитом (корисно при виявленні порушень, що стосуються товарних знаків). Жоден візуально схожий товарний знак не був пропущений алгоритмом (перевірено вручну авторами).
Див. також
Примітки
- S. Belongie and J. Malik (2000). Matching with Shape Contexts. IEEE Workshop on Contentbased Access of Image and Video Libraries (CBAIVL-2000).
- S. Belongie, J. Malik, and J. Puzicha (April 2002). Shape Matching and Object Recognition Using Shape Contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence 24 (24): 509–521. doi:10.1109/34.993558.
- S. Belongie, J. Malik, and J. Puzicha (July 2001). Matching Shapes. Eighth IEEE International Conference on Computer Vision (July 2001).
- S. Belongie, J. Malik, and J. Puzicha (2000). Shape Context: A new descriptor for shape matching and object recognition. NIPS 2000.
- H. Chui and A. Rangarajan (June 2000). A new algorithm for non-rigid point matching. CVPR 2. с. 44–51.
- R. Jonker and A. Volgenant (1987). A Shortest Augmenting Path Algorithm for Dense and Sparse Linear Assignment Problems. Computing 38 (4): 325–340. doi:10.1007/BF02278710.