Нуклеотидна послідовність
Нуклеотидна або генетична послідовність — послідовність букв, що представляють первинну структуру реального або гіпотетичного ланцюжка нуклеїнової кислоти (зазвичай ДНК), що може нести генетичну інформацію.
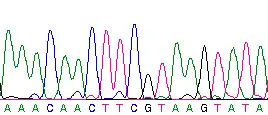
Можливими буквами є A, C, G і T, які являють собою чотири нуклеотиди, що входять до складу ДНК — аденін, цитозин, гуанін і тимін і ковалентно зв'язані із фосфатно-цукровим остовом молекули. Нуклеотидна послідовність йде без пробілів, хоча пробіли можуть додаватися для зручності сприйняття людиною. Послідовність, написана зліва направо, наприклад AAAGTCTGAC, означає послідовність, що йде в напрямку від 5' до 3' .
Біологічна функція послідовності залежить від закодованої в ній інформації. Послідовність може бути «змістовна» або «сенс» (що несе інформацію, яка зчитується в живій клітині) та «антизмістовна» чи «антисенс» (комплементарна їй послідовність, наприклад антисенсова РНК). Крім того, послідовність може бути кодуючою (що переводиться у амінокислотну послідовність білків у процесі біосинтезу білків за правилами генетичного коду) або некодуючою (некодуючі РНК).
Нуклеотидна послідовності ДНК біологічного зразку може бути отримана у процесі секвенування ДНК. У деяких випадках, особливо при порівнянні послідовностей, окрім букв A, T, C і G в послідовності використовуються інші. Ці букви представляють багатозначність, тобто в цьому положенні може бути присутнім більш ніж один тип нуклеотидів. За правилами Міжнародного союзу теоретичної і прикладної хімії (IUPAC) використовуються такі букви:
A = аденін
C = цитозин
G = гуанін
T = тимін
R = G A (пурин)
Y = T C (піримідин)
K = G T (кето)
M = A C (аміно)
S = G C (сильне зв'язування)
W = A T (слабке зв'язування)
B = G T C (всі крім A)
D = G A T (всі крім C)
H = A C T (всі крім G)
V = G C A (всі крім T)
N = A G C T (будь-який)
