Пошук зображень за вмістом
Пошук зображень за змістом (англ. Content-based image retrieval (CBIR)), також відомий як запит за вмістом зображення (англ. Query by image content (QBIC)) та Отримання візуальної інформації за змістом (англ. Content-based visual information retrieval (CBVIR)) — це одна із технік машинного зору, що вирішує проблему отримання зображень, що є проблемою пошуку цифрових зображень у великих базах даних. Пошук зображень за змістом є протилежним підходом відносно пошуку зображень за описом.
"На основі вмісту" означає, що пошук повинен аналізувати фактичний вміст зображення, а не метадані, такі як ключові слова, теги та/або опис пов'язаний із зображенням. Термін «вміст» в даному контексті міг би послатися на кольори, форми, текстури, або будь-яка іншу інформацію, яка може бути отримана з самого зображення.
Загальна інформація
Традиційно, для пошуку зображень використовують їх текстові характеристики: ім’я файлу, заголовок, ключові слова тощо. Однак такий підхід має ряд недоліків. Перш за все необхідне втручання людини для опису вмісту зображень відповідно до обраного набору підписів та ключових слів. У більшості випадків зображення містить декілька об’єктів, кожен з яких має свій набір атрибутів. Крім цього, потрібно описати просторові відношення між цими об’єктами, щоб зрозуміти його зміст. Оскільки розміри баз даних зображень зростають, використання ключових слів стає не тільки складним але і недостатнім для представлення зображення. Інша проблема даного підходу полягає у неадекватності єдиного текстового опису зображення. Як результат є необхідність для автоматизованого отримання примітивних властивостей зображень і пошук зображень на основі цих властивостей. Для великої бази даних із понад десятками тисяч образів ефективна індексація є важливим інструментом в CBIR-системах. Успішна класифікація зображень зменшує час опрацювання зображень фільтруванням зайвих класів образів під час пошуку подібних до них [1].
Історія
Термін «Content-based image retrieval» вперше був запропонований 1992 році Т. Като (T. Kato) при описі експериментів з автоматичним пошуком зображень за критеріями присутності квітів і геометричних форм. З того моменту його застосовують як узагальнення процесу вибірки зображень з бази за будь-якими синтаксичним характеристикам об'єктів. Використовувані алгоритми, методи і програмні інструменти беруть початок в областях, пов'язаних з обробкою сигналів, машинного зору та статистикою.
Розвиток
До області пошуку зображень за характерними особливостями в наш час[коли?] зростає інтерес, пов'язаний з обмеженістю методів, заснованих виключно на категоризації метаданих, а також зростаючим потенціалом її застосування. Зараз алгоритми категоризації та пошуку в текстових даних дозволяють досить ефективно справляти із зображеннями, що описані за допомогою метаданих, проте такий підхід вимагає ручного опису кожного зображення в базі людиною. Це абсолютно непрактично, особливо в застосуванні до великих баз даних або зображень, що створюються автоматично (наприклад, камерами відеоспостереження). Крім того існує велика ймовірність упустити деякі результати пошуку через багатозначності чи синоніми.
Принцип роботи CBIR-системи
Сучасні CBIR-системи працюють у два етапи: Індексування та Пошук. На етапі індексування кожний образ у базі даних представляється вектором властивостей. Існуючі універсальні системи CBIR відносять до однієї із трьох категорій залежно від підходу отримання властивостей образу: гістограма, кольорове розташування і пошук за регіонами. Такими властивостями, зокрема, є: колір, форма, структура і розташування. Отримані властивості зберігаються в окремій базі даних візуальних властивостей. На етапі пошуку обчислюються властивості із образу-запиту користувача. Використовуючи критерії подібності, отриманий вектор властивостей порівнюється з векторами у базі даних візуальних властивостей. Користувач у відповідь отримує образи, які максимально відповідають запиту. Системи пошуку за регіонами використовують локальні властивості регіонів (ідеальних об’єктів) у протилежність глобальним властивостям повного зображення. Якщо об’єкти в межах зображення сегментовані і кожна властивість об’єкта отримана автоматично, то такі особливості роблять можливу систему пошуку зображень за регіонами [2]. Представлення візуального образу адекватним числом кластерів (об’єкти у зображенні) може краще відобразити його вміст, однак цей підхід є часозалежним.
Типова архітектура CBIR-системи
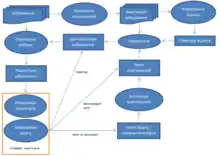
Інтерфейс користувача (UI, User Interface), як правило, складається з двох частин: формування запиту і візуалізація результатів виконання запиту. Більшість CBIR-систем є результатами досліджень, і підкреслюють один з аспектів пошуку на основі вмісту. Іноді це можливість представлення результатів у вигляді ескізів у користувацькому інтерфейсі, іноді це використання нової структури даних для індексування. Деякі системи існують у дослідницьких, комерційних версіях та версіях для виробництва. Комерційні версії, як правило, володіють більш стандартними пошуковими можливостями. Деякі системи надають користувачеві інтерфейс, який дозволяє більш гнучко формулювати запити. Чим простіше властивість може бути отримана із зображення, тим легше її впровадити в систему, і тим легше використовувати цю властивість. Наприклад, властивості кольору для пошуку образів здебільшого ефективні, оскільки їх не важко отримати і впровадити в систему. Однак, властивості форми, які є стійкіші до шуму, беруть активнішу участь у CBIR-системах. Як результат, використовуються дуже прості функції, які часто є малоефективними. Більшість систем використовують ознаки кольору і текстури, меншість – ознаки форми та розташування. Результатом пошуку за кольором зазвичай є зображення зі схожими кольорами. Результатом пошуку за текстурою не завжди є зображення із подібною текстурою, якщо база даних містить багато зображень із домінуючими текстурами. Результати пошуку за формою часто є несподіваними. Тому вони не є найбільш ефективними властивостями.
Програмні системи та алгоритми
Попри те, що існує безліч програмних комплексів з пошуку зображень в базах даних, проблема пошуку на основі піксельного змісту в більшості ситуацій поки не має ефективного реалізованого рішення. Із списком існуючих пошукових систем за зображенням можна ознайомитися тут.
Способи побудови запитів
Різні реалізації систем пошуку зображень за змістом працюють з наступними типами користувацьких запитів:
Запит за шаблоном
Передбачається, що система робить пошук на основі вхідного зображення, поданого користувачем. Алгоритми, що лежать в основі системи, можуть мати різні способи опису та роботи з вхідним зображенням, але всі результати пошуку повинні мати спільні характеристики із вхідним зображенням, що подавалося користувачем.
Користувач може подати на вхід як існуюче зображення, так і грубий начерк необхідного результату (розмітку на кольорові області або прості геометричні форми).[3]
При даному способі побудови запитів не виникає труднощів, пов'язаних з описом зображення за допомогою слів.
Розпізнавання семантики запиту
В ідеалі система пошуку повинна вміти обробляти запити користувача, сформульовані у вільній формі, наприклад «знайти фотографії собак» або навіть «знайти портрети Леоніда Ілліча Брежнєва». Запити такого типу дуже складні для обробки комп'ютером, адже фотографії лабрадора і карликового пуделя сильно різняться, а Леонід Ілліч не завжди дивиться в камеру в однаковій позі. У цей час багато систем використовують для класифікації характеристики нижчого рівня, такі як колір, текстура і форма об'єкта, хоча існують і системи, в основному засновані на диференціації критеріїв високого рівня (див. Теорія розпізнавання образів). Більшість систем не є широко орієнтованими. Наприклад, системи пошуку зображень, згенерованих на комп'ютері, з успіхом обходяться характеристиками, основаними на поєднанні форм та градієнтів.
Інші способи
Ця категорія включає в себе такі форми запитів, як визначення категорії в запропонованій ієрархії, запит у вигляді частини зображення, очікуваного як результат, розширення запиту додатковими зображеннями, задання графічного шаблону, що складається зі складних форм, а також комбінацію методів.
Також можливе поступове уточнення запиту, коли користувач в процесі роботи системи пошуку позначає проміжні результати як «підходящі» або «незадовільні», і система продовжує працювати з уточненим запитом.
Методи опису характеристик
Тут представлені найбільш загальні методи опису характеристик зображень, що використовуються для подальшого порівняння їх між собою. Всі вони є потенційно широко застосовними, тобто не специфічними для будь-якого особливого підкласу систем.
Колір
Пошук зображень за допомогою порівняння колірних складових проводиться за допомогою побудови Гістограми кольору їх розподілу. У цей час ведуться дослідження з побудови опису, в якому зображення ділиться на регіони за схожими колірним характеристикам, і далі враховується їх взаємне розташування. Опис зображень за допомогою кольорів, з яких воно складається, є найбільш поширеним, оскільки воно не залежить від розміру або орієнтації зображення. Побудова гістограм з наступним їх порівнянням використовується найбільш часто, але не є єдиним способом опису колірних характеристик.
Текстура
Методи такого опису працюють з порівнянням текстурних зразків, присутніх на зображенні, і їх взаємного розташування. Для визначення текстури використовують текселі, які об'єднують в множини. Вони містять не тільки інформацію, що описує текстуру, а й її місце розташування на описуваному зображенні. Текстуру як сутність складно формалізовано описати, і зазвичай її представляють у вигляді двомірного масиву зміни яскравості. Також в опис іноді включають міру контрастності, спрямованості градієнту та регулярності. Існує проблема порівняння коваріації пікселів з метою віднесення текстури до певного класу (наприклад, «гладка» або «груба»).
Форма
Опис форми передбачає опис геометричної форми окремих фрагментів зображення. Для її визначення до фрагмент спочатку застосовують сегментацію або Виділення контурів зображення. Існують і інші способи, наприклад фільтрація форм (Tushabe and Wilkinson, 2008). Часто визначення форми вимагає втручання людини, тому що методи типу сегментації складно повністю автоматизувати для широкого класу задач.
Застосування
Існують компанії, що представляють програмні продукти, в яких алгоритми пошуку зображень за змістом застосовуються для фільтрації вмісту веб-сторінок і державного моніторингу мережевого трафіку з метою відстеження зображень порнографічного змісту. Потенційні області застосування алгоритмів пошуку за змістом:
- Пошук зображень в мережі інтернет
- Каталогізація зображень творів мистецтва
- Організація роботи з архівами фотографічних знімків
- Організація каталогів роздрібного продажу товарів
- Медична діагностика захворювань
- Запобігання злочинів і заворушень
- Застосування у військових цілях
- Питання контролю за поширенням інтелектуальної власності
- Отримання інформації про місце знаходження віддалених зондів і географічне позиціювання
- Контроль за вмістом масивів зображень
Див. також
- Кластеризація зображення за фрагментами інтенсивності
- Навчання за набором зразків
- Query by Image and Video Content: The QBIC System, (Flickner, 1995)
- Finding Naked People (Fleck et al., 1996)
- Virage Video Engine[недоступне посилання з квітня 2019], (Hampapur, 1997)
- Library-based Coding: a Representation for Efficient Video Compression and Retrieval, (Vasconcelos & Lippman, 1997)
- System for Screening Objectionable Images (Wang et al., 1998)
- Content-based Image Retrieval (JISC Technology Applications Programme Report 39) (Eakins & Graham 1999)
- Windsurf: Region-Based Image Retrieval Using Wavelets (Ardizzoni, Bartolini, and Patella, 1999)
- A Probabilistic Architecture for Content-based Image Retrieval, (Vasconcelos & Lippman, 2000)
- A Unifying View of Image Similarity, (Vasconcelos & Lippman, 2000)
- Next Generation Web Searches for Visual Content, (Lew, 2000)
- Image Indexing with Mixture Hierarchies, (Vasconcelos, 2001)
- SIMPLIcity: Semantics-Sensitive Integrated Matching for Picture Libraries (Wang, Li, and Wiederhold, 2001)
- A Conceptual Approach to Web Image Retrieval (Popescu and Grefenstette, 2008)
- FACERET: An Interactive Face Retrieval System Based on Self-Organizing Maps (Ruiz-del-Solar et al., 2002)
- Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach (Li and Wang, 2003)
- Video google: A text retrieval approach to object matching in videos (Sivic & Zisserman, 2003)
- Minimum Probability of Error Image Retrieval (Vasconcelos, 2004)
- On the Efficient Evaluation of Probabilistic Similarity Functions for Image Retrieval (Vasconcelos, 2004)
- Names and Faces in the News (Berg et al., 2004)
- Cortina: a system for large-scale, content-based web image retrieval (Quack et al., 2004)
- A new perspective on Visual Information Retrieval (Eidenberger 2004)
- Language-based Querying of Image Collections on the basis of an Extensible Ontology (Town and Sinclair, 2004)
- Automatic Face Recognition for Film Character Retrieval in Feature-Length Films (Arandjelovic & Zisserman, 2005)
- Algorithm on which Retrievr (Flickr search) and imgSeek is based on (Jacobs, Finkelstein, Salesin)
- From Pixels to Semantic Spaces: Advances in Content-Based Image Retrieval (Vasconcelos, 2007)
- Content-based Image Retrieval by Indexing Random Subwindows with Randomized Trees (Maree et al., 2007)
- Image Retrieval: Ideas, Influences, and Trends of the New Age (Datta et al., 2008)
- Real-Time Computerized Annotation of Pictures (Li and Wang, 2008)
- Query Processing Issues in Region-based Image Databases (Bartolini, Ciaccia, and Patella, 2010)
- The Windsurf Library for the Efficient Retrieval of Multimedia Hierarchical Data (Bartolini, Patella, and Stromei, 2011)
Примітки
- Vailaya, A; A.K. Jain, H.J. Zhang (1998). On image classification: city vs. landscape.
- Yoo, H.W.; S.H. Jung, D.H. Jang, Y.K. Na (2002). Extraction of major object features using VQ clustering for content-based image retrieval.
- Shapiro, Linda; George Stockman (2001). Computer Vision. Upper Saddle River, NJ: Prentice Hall. ISBN 0-13-030796-3.