Суперскалярність
Суперскалярність — архітектура обчислювального ядра, що використовує кілька декодерів команд, які можуть навантажувати роботою декілька виконавчих блоків. Планування виконання потоку команд є динамічним і здійснюється самим обчислювальним ядром.
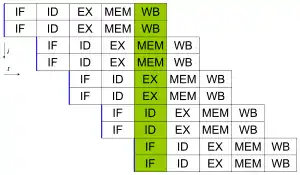
Якщо в процесі роботи команди, що обробляються конвеєром, не суперечать одна одній, і одна не залежить від результату іншої, то такий пристрій може здійснити паралельне виконання команд. У суперскалярних системах рішення про запуск інструкції на виконання приймає сам обчислювальний модуль, що вимагає багато ресурсів. У пізніших системах, таких як Ельбрус і Itanium, використовується статпланування, тобто паралельні інструкції об'єднуються компілятором в довгу команду, в якій наперед відомо, що всі інструкції паралельні (архітектура VLIW).
Суперскалярна архітектура ЦП втілює форму паралелізму відому як паралелізм рівня інструкцій на одному процесорі.
Історія
Існує суперечка щодо того, яку ЕОМ можна вважати першою з використанням суперскалярної архітектури. У західній літературі найчастіше вказується CDC 6600 (1964) розроблена Сеймуром Креєм. У СРСР першою суперскалярною ЕОМ вважався «Ельбрус», розробка якого велася в 1973—1979 роках в ИТМиВТ. Основною структурною відзнакою Ельбруса від CDC 6600 (крім, природно, абсолютно іншої видимої програмісту системи команд — стекового типу) було те, що всі модулі виконання в ньому були конвеєризовані, як у сучасних суперскалярних мікропроцесорах. На підставі цього факту Б. А. Бабаян заявляв про пріоритет радянських ЕОМ у питанні побудови суперскалярних обчислювальних машин, однак його думка позбавлена достатніх підстав, бо вже наступна за CDC 6600 машина фірми Control Data, CDC 7600 1969 року мала конвеєризацію виконавчих пристроїв. Крім того, дещо раніше (1967) фірмою IBM була випущена машина IBM 360/91, що використовує позачергове виконання, перейменування регістрів і конвеєризацію виконавчих пристроїв. Першим же комерційно широкодоступним суперскалярним мікропроцесором став Intel i960, що вийшов в 1988 році. У 1990-х роках основним виробником суперскалярних мікропроцесорів стала фірма Intel.
Реалізації
Процесори, що підтримують суперскалярність:
| Архітектура | Перша реалізація | Рік | Розробник | Примітка |
|---|---|---|---|---|
| CDC 6600 | CDC 6600 | 1964 | Control Data Corporation | Конвеєр виконання команд, кілька виконуючих пристроїв (але не конвеєризованих) |
| IBM System/360 Model 91 | 1967 | IBM | Повна конвеєризація з динамічним перейменуванням регістрів та динамічним, під час виконання, визначенням порядку команд | |
| CDC 7600 | CDC 7600 | 1969 | Control Data Corporation | Повна конвеєризація — і виконання команд, і самих виконуючих пристроїв |
| Ельбрус | Ельбрус-1 | 1979 | ИТМиВТ | Повна конвеєризація з динамічним перейменуванням регістрів та динамічним, під час виконання, визначенням порядку команд |
| Intel i960 | I960 | 1988 | Intel | |
| SPARC | SuperSPARC | 1992 | Sun Microsystems | |
| x86 | Pentium | 1993 | Intel | |
| MIPS | R8000 | 1994 | MIPS Technologies | |
| ARM | Cortex A8 | 2005 | ARM |
Прискорення обчислень
У суперскалярних обчислювальних машинах використовується ряд методів для прискорення обчислень, характерних насамперед для них, однак такі методи можуть використовуватися і в інших типах архітектур:
- Позачергове виконання (англ. Out-of-order execution) — метод, застосовуваний при розробці обчислювальних пристроїв, з метою підвищення продуктивності. Його особливість полягає у тому, що інструкції надходять у виконавчі модулі не в порядку їх слідування, як було в концепції виконання інструкцій по порядку (англ. In-Order execution), а по готовності до виконання. Серед широко відомих машин вперше цей метод була в істотній мірі реалізований в машинах CDC6600 фірми Control Data і IBM 360/91 фірми IBM.
- Перейменування регістрів (англ. Register Renaming) — метод ослаблення взаємозалежностей інструкцій, застосовуваний в процесорах, що здійснюють їх позачергове виконання (англ. Out-of-order execution). У тому випадку, якщо відповідно для двох або більше інструкцій необхідно здійснити запис даних в один регістр, їх коректне позачергове виконання стає неможливим (новіша інструкція не може бути оброблена до завершення більш ранньої) навіть у тому випадку, якщо при цьому немає залежності за даними. Такі взаємозалежності часто називають хибними (у разі істинної залежності існує залежність і за даними). Так як кількість архітектурних регістрів зазвичай обмежена (наприклад, стандартно архітектура х86 передбачає тільки вісім регістрів загального призначення), ймовірність виникнення помилкових взаємозалежностей досить велика, що може призвести до зниження продуктивності процесора. Перейменування регістрів являє собою перетворення програмних посилань на архітектурні регістри в посилання на фізичні регістри і дозволяє послабити вплив помилкових взаємозалежностей за рахунок використання великої кількості фізичних регістрів замість обмеженої кількості архітектурних (так, наприклад, x86-сумісні процесори архітектури Intel P6 містять 40 фізичних регістрів). При цьому процесор відстежує, стан яких фізичних регістрів відповідає стану архітектурних, а видача результатів здійснюється в порядку, який передбачений програмою.
- Об'єднання кількох команд в одну — метод розпаралелювання обчислень на рівні компіляції, що дозволяє одночасно виконувати декілька інструкцій на обладнанні, яке дозволяє паралельну незалежну роботу.
Методики збільшення продуктивності
- Модуль передбачення умовних переходів (англ. Branch Prediction Unit) — пристрій, що входить до складу мікропроцесорів, що мають конвеєрну архітектуру, визначальний напрямок розгалужень (передбачають, чи буде виконаний умовний перехід) в виконуваній програмі. Передбачення розгалужень дозволяє здійснювати попередню вибірку інструкцій і даних з пам'яті, а також виконувати інструкції, що розташовані після умовного переходу, до того, як він буде виконаний. Передбачення переходів є невід'ємною частиною всіх сучасних суперскалярних мікропроцесорів, тому що в більшості випадків (точність передбачення переходів в сучасних процесорах перевищує 90 %) дозволяє оптимально використовувати обчислювальні ресурси процесора.
- Кеш — пристрій, що знаходиться між процесором та оперативною пам'яттю і являє собою швидкодійну програмно недоступну пам'ять, яка забезпечує тимчасове збереження даних з можливістю їх читання та запису без звернення до менш швидкодійної оперативної пам'яті.
- Конвеєр команд — пристрій, що одночасно декодує декілька команд та узгоджує їх можливе одночасне виконання, застосовується в сучасних суперскалярних процесорах.
Література
- Э.Таненбаум Архитектура компьютера = Structured Computer Organization. — 5-е изд.. — СПб.: Питер, 2007. — С. 81-83. — 848 с. — (Классика Computer Science). — ISBN 5-469-01274-3
Див. також
- Структура суперскалярного процесора
