XXTEA
XXTEA — криптографічний алгоритм, що реалізує блочне симетричне шифрування і представляє собою мережу Фейстеля. Є розширенням алгоритму Block TEA. Розроблений і опублікований Девідом Уілером і Роджером Нідгемом в 1998 році. Виконаний на простих і швидких операціях: XOR, підстановка, додавання.[1][2]
| Алгоритм блокового шифрування | |
|---|---|
| Назва: | XXTEA |
| Розробник: | Девід Уілер і Роджер Нідгем |
| Створений: | 1998 р |
| Опублікований: | 1998 р |
| Розмір ключа: | 128 біт |
| Розмір блоку: | біт, де - кількість слів, не менше 2 |
| Число раундів: | , де - кількість слів |
| Тип: | Мережа Фейстеля |



Історія
На симпозіумі Fast Software Encryption в грудні 1994 року Девід Уілер і Роджер Нідгем, професори Комп'ютерної Лабораторії Кембриджського Університету (Computer Laboratory, University of Cambridge), представили новий криптографічний алгоритм TEA. Даний алгоритм проектувався як альтернатива DES, який до того моменту вже вважався застарілим.[3][4]
Пізніше в 1996 році в ході особистого листування Девіда Уїлера з Девідом Вагнером була виявлена уразливість до атаки на пов'язаних ключах, яка була офіційно представлена в 1997 році на Першій Міжнародній Конференції ICIS групою вчених, що складалася з Брюса Шнайера, Джона Келсі і Девіда Вагнера.[5][6] Ця атака стала підставою для покращення алгоритму TEA, і в жовтні 1996 року Уілер і Нідгем опублікували внутрішній звіт лабораторії, в якій наводилося два нових алгоритми: XTEA і Block TEA.[7]
10 жовтня 1998 року група новин sci.crypt.research опублікувала статтю Маркку-Юхані Саарінена, в якій була знайдена уразливість Block TEA на стадії дешифрування[4]. У тому ж місяці Девід Уілер і Роджер Нідгем опублікували внутрішній звіт лабораторії, в якій наводилося поліпшення алгоритму Block TEA — XXTEA.[1]
Особливості
XXTEA, як і інші шифри колекції TEA, має ряд відмінних особливостей у порівнянні з аналогічними шифрами:
Опис роботи алгоритму
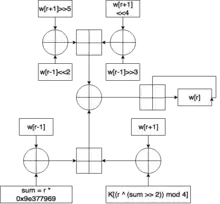
Вихідний текст розбивається на слова по 32 біта кожне, з отриманих слів формується блок. Ключ також розбивають на 4 частини, що складаються зі слів по 32 біта кожен, і формують масив ключів. В ході одного раунду роботи алгоритму шифрується одне слово з блоку. Після того, як були зашифровані слова, закінчується цикл і починається новий. Кількість циклів залежить від кількості слів і дорівнює , де — кількість слів. Шифрування одного слова полягає в наступному:

- Над лівим сусідом виконується операція бітового зсуву вліво на два, а над правим операція бітового зсуву вправо на п'ять. Над отриманими значеннями виконують операцію побітового додавання за модулем 2.
- Над лівим сусідом виконується операція бітового зсуву вправо на три, а над правим операція бітового зсуву вліво на 4. Над отриманими значеннями виконують операцію побітового додавання за модулем 2
- Отримані числа складають по модулю 232.
- Константа δ, виведена із Золотого перетину (δ = ( — 1) * 231 = 2654435769 = 9E3779B9h)[3] множиться на номер циклу (це було зроблено для запобігання простим атакам, заснованим на симетрії раундів).
- Отримане в попередньому пункті число складають побітово по модулю 2 з правим сусідом.
- Отримане в пункті 4 число зсувають побітово направо на 2, складають побітово по модулю два з номером раунду, і знаходять залишок від ділення на 4. З допомогою отриманого числа вибирають ключ з масиву ключів.
- Обраний в попередньому раунді ключ складають побітово по модулю 2 з лівим сусідом.
- Числа, отримані у попередньому та 4 пунктах складають по модулю 232.
- Числа, отримані в попередньому і 3 пунктах складають побітово по модулю 2, цю суму складають з шифрованим словом по модулю 232.

Криптоаналіз
На даний момент існує атака на основі адаптивно підібраного відкритого тексту, опублікована Еліасом Яаррковом в 2010 році. Існує два підходи, в яких використовується зменшення кількості циклів за рахунок збільшення кількості слів.
Перший підхід

Нехай у нас є якийсь відкритий текст. Візьмемо з нього 5 певних слів, починаючи з , які ми шифруємо з . Додамо яке-небудь число до і отримаємо новий відкритий текст. Тепер виконаємо перший цикл шифрування для цих текстів. Якщо після шифрування різниця залишилася тільки в даному слові, то продовжуємо шифрування. Якщо почали з'являтися різниці в інших словах, то починаємо пошук заново або змінюючи вихідний, або намагаючись підібрати іншу різницю. Збереження різниці тільки в одному слові можливо, так як функція шифрування не бієктивна для кожного сусіда. Еліас Яаррков провів ряд експериментів і з'ясував, що ймовірність проходження різниці 5 повних циклів давала ймовірність між і для більшості ключів, тобто якщо пара текстів пройшла 5 з 6 повних циклів, то її можна вважати вірною, так як якщо помістити різницю в кінець блоку, будуть виникати різниці в більшості слів. Дана атака була проведена і був відновлений ключ для алгоритму з кількістю циклів зменшеною до трьох.







Другий підхід
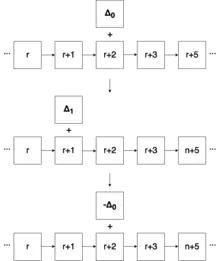
Другий підхід відрізняється від першого тим, що після першого раунду шифрування слова, різниця повинна перейти у нього самого з слова, при цьому різниця може зміниться, а після наступного раунду шифрування різниця повернеться в слово і стане дорівнювати початковому, але змінить знак. Після проведення оцінки даного методу, Еліас Яаррков отримав, що для успішного знаходження правильної пари досить 259 текстів, причому різниця повинна лежати в інтервалі , де , причому збільшення d не поліпшила результатів. Після була проведена успішна атака на XXTEA з кількістю циклом зменшеним до 4, і правильна пара була отримана за допомогою 235 пар текстів, а попередня оцінка дає необхідність у 234.7 пар текстів.


Зразок коду
Оригінальне формулювання виправленого блоку TEA алгоритму, опублікованого Девідом Вільцером та Роджером Нідгем, полягає в наступному[10]:
#define MX ((z>>5^y<<2) + (y>>3^z<<4) ^ (sum^y) + (k[p&3^e]^z))
long btea(long* v, long n, long* k) {
unsigned long z=v[n-1], y=v[0], sum=0, e, DELTA=0x9e3779b9;
long p, q ;
if (n > 1) { /* Coding Part */
q = 6 + 52/n;
while (q-- > 0) {
sum += DELTA;
e = (sum >> 2) & 3;
for (p=0; p<n-1; p++) y = v[p+1], z = v[p] += MX;
y = v[0];
z = v[n-1] += MX;
}
return 0 ;
} else if (n < -1) { /* Decoding Part */
n = -n;
q = 6 + 52/n;
sum = q*DELTA ;
while (sum != 0) {
e = (sum >> 2) & 3;
for (p=n-1; p>0; p--) z = v[p-1], y = v[p] -= MX;
z = v[n-1];
y = v[0] -= MX;
sum -= DELTA;
}
return 0;
}
return 1;
}
За словами Нідгема та Уілера:
BTEA буде кодувати або декодувати n слів як єдиний блок, де n> 1
- v - вектор n даних слова
- k - це ключ від 4 слів
- n - для декодування є негативним
- якщо n дорівнює нулю, то результат - 1, і ніякого кодування чи декодування не відбувається, інакше результат буде нульовим
- передбачає 32-бітове "довге" та аналогічне кодування та декодування
Зверніть увагу, що ініціалізація z є невизначеною поведінкою для n <1, що може спричинити помилку сегментації або іншу небажану поведінку, - це було б краще помістити в блок «Coding Part». Крім того, у визначенні MX деякі програмісти вважатимуть за краще використовувати брекетинг, щоб визначити перевагу оператора.
Уточнена версія, включаючи такі вдосконалення, полягає в наступному:
#include <stdint.h>
#define DELTA 0x9e3779b9
#define MX (((z>>5^y<<2) + (y>>3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z)))
void btea(uint32_t *v, int n, uint32_t const key[4]) {
uint32_t y, z, sum;
unsigned p, rounds, e;
if (n > 1) { /* Coding Part */
rounds = 6 + 52/n;
sum = 0;
z = v[n-1];
do {
sum += DELTA;
e = (sum >> 2) & 3;
for (p=0; p<n-1; p++) {
y = v[p+1];
z = v[p] += MX;
}
y = v[0];
z = v[n-1] += MX;
} while (--rounds);
} else if (n < -1) { /* Decoding Part */
n = -n;
rounds = 6 + 52/n;
sum = rounds*DELTA;
y = v[0];
do {
e = (sum >> 2) & 3;
for (p=n-1; p>0; p--) {
z = v[p-1];
y = v[p] -= MX;
}
z = v[n-1];
y = v[0] -= MX;
sum -= DELTA;
} while (--rounds);
}
}
Примітки
- Wheeler et al, 1998.
- Yarrkov, 2010.
- Wheeler et al, 1994.
- Saarinen, 1998.
- Kelsey et al, 1997.
- ICIS, 1997.
- Wheeler et al, 1996.
- Sima et al, 2012.
- Cenwei, 2008.
- David J. Wheeler and Roger M. Needham (October 1998). Correction to XTEA. Computer Laboratory, Cambridge University, England. Процитовано 4 липня 2008.
Література
- David J. Wheeler, Roger M. Needham. Correction to XTEA. — 1998. — Жовтень.
- E. Yarrkov. Cryptanalysis of XXTEA. — 2010. — Травень.
- Saarinen M.-J. Cryptanalysis of Block Tea. — 1998. — Жовтень.
- David J. Wheeler, Roger M. Needham. TEA, a tiny encryption algorithm. — 1994. — Грудень.
- David J. Wheeler, Roger M. Needham. TEA extensions. — 1996. — Жовтень.
- J. Kelsey, B. Schneier and D. Wagner. Related-key cryptanalysis of 3-WAY, Biham-DES,CAST, DES-X, NewDES, RC2, and TEA. — 1997. — Листопад.
- Mao Cenwei. Comparison of a Few Small Ciphers Applicable to RFID. — 2008. — Червень.
- I. Sima, D. Tarmurean и V. Greu. XXTEA, an alternative replacement of KASUMI cipher algorithm in A5/3 GSM and f8, f9 UMTS data security functions. — 2012. — Червень.
- First International Conference, ICIS'97, Beijing, China, November 11-14, 1997, Proceedings / Editors: Yongfei Han, Tatsuaki Okamoto, Sihan Quing. — 1. — Springer-Verlag Berlin Heidelberg, 1997. — ISBN 978-3-540-63696-0.