Геш-таблиця
Геш-таблиця[1] — структура даних, що реалізує інтерфейс асоціативного масиву, а саме, вона дозволяє зберігати пари (ключ, значення) і здійснювати три операції: операцію додавання нової пари, операцію пошуку і операцію видалення за ключем.
Вступ
Існує два основних варіанта геш-таблиць: з ланцюжками і з відкритою адресацією. Геш-таблиця містить в собі деякий масив H, елементами якого є пари (геш-таблиця з відкритою адресацією) або списки пар (геш-таблиця з ланцюжками).
Виконання операцій в геш-таблиці починається з обчислення геш-функції від ключа. Отримане геш-значення i = hash(key) відіграє роль індексу в масиві H. Після цього операція (додавання, видалення, пошук) перенаправляється об'єктові, який зберігається у відповідній комірці масиву H[i].
Ситуація, коли для різних ключів отримується одне й те саме геш-значення, називається колізією. Такі події непоодинокі — наприклад, при додаванні в геш-таблицю розміром 365 комірок усього лише 23-х елементів ймовірність колізії вже перевищує 50 відсотків (якщо кожний елемент може з однаковою ймовірністю потрапити в будь-яку комірку) — див. парадокс днів народження. Через це механізм розв'язання колізій — важлива складова будь-якої геш-таблиці.
В деяких особливих випадках вдається взагалі уникнути колізій. Наприклад, якщо всі ключі елементів відомі заздалегідь (або дуже рідко змінюються), тоді для них можна знайти деяку досконалу геш-функцію, яка розподілить їх за комірками геш-таблиці без колізій. Геш-таблиці, які використовують подібні геш-функції, не потребують механізму розв'язання колізій, і називаються геш-таблицями з прямою адресацією.
Властивості геш-таблиці
Важлива властивість геш-таблиць полягає в тому, що, при деяких розумних припущеннях, всі три операції (пошук, вставлення і видалення елементів) зазвичай виконується за час O(1). Але при цьому не гарантується, що час виконання окремої операції малий, з певною імовірністю час може бути сумірним із пошуком у списку. З ростом коефіцієнта заповнення таблиці ця імовірність, і, відповідно, середній час виконання операцій, ростуть. Тому при досягненні деякого значення коефіцієнта заповнення необхідно здійснювати перебудову індексу геш-таблиці: збільшити розміри масиву H і заново додати в порожню геш-таблицю всі пари.
Розв'язання колізій
Існує декілька способів розв'язання колізій.
Метод ланцюжків
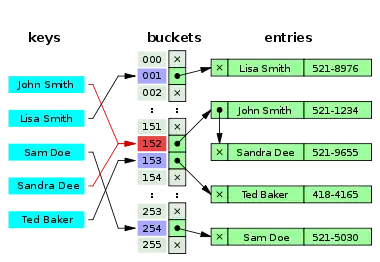
Кожна комірка масиву H є вказівником на зв'язаний список (ланцюжок) пар ключ-значення, відповідних одному і тому самому геш-значенню ключа. Колізії просто призводять до того, що з'являються ланцюжки довжиною більше одного елемента.
Операції пошуку або видалення елемента вимагають перегляду всіх елементів відповідного ланцюжка, щоб знайти в ньому елемент з заданим ключем. Для додавання нового елемента необхідно додати елемент в кінець або початок відповідного списку, і, у випадку якщо коефіцієнт заповнення стане занадто великим, збільшити розмір масиву H і перебудувати таблицю.
При припущенні, що кожний елемент може потрапити в будь-яку позицію таблиці H з однаковою ймовірністю і незалежно від того, куди потрапив будь-який елемент, пересічний час роботи операції пошуку елемента складає Θ(1 + α), де α — коефіцієнт заповнення таблиці.
Відкрита адресація
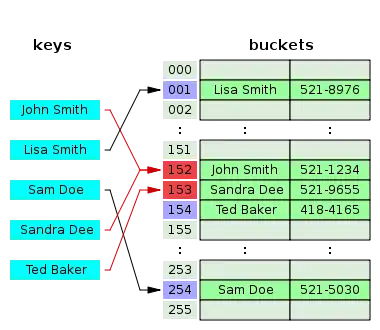
В стратегії, названій відкритою адресацією, всі записи зберігаються в самому масиві H. Коли додається новий запис, масив перевіряється в певному порядку, доки не буде знайдена вільна комірка, куди буде доданий елемент. У випадку пошуку елемента, масив сканується в тій самій послідовності, доки потрібний запис або порожня комірка не буде знайдена. Останнє — означає відсутність елемента.[2] Назва «відкрита адресація» показує, що положення («адреса») елемента не визначається його геш-значенням. Цей метод також називають закритим гешуванням.
Загалом, послідовність, у якій переглядаються комірки геш-таблиці, залежить лише від ключа елемента. Тобто це послідовність h0(x), h1(x), …, hn-1(x), де x — ключ елемента, а hi(x) — довільна функція, яка порівнює кожен ключ комірки з геш-таблицею. Перший елемент послідовності, зазвичай, дорівнює значенню деякої геш-функції від ключа, а наступні обчислюються одним з наведених нижче способів. Для успішної роботи алгоритму пошуку, послідовність перебору має бути такою, щоб всі комірки геш-таблиці виявились переглянутими рівно по одному разу.
Алгоритм пошуку переглядає всі комірку геш-таблиці в тому самому порядку, що і при вставці, доки не знайдеться або елемент з шуканим ключем, або вільна комірка (що означає відсутність елемента в геш-таблиці).
Видалення елементів у такій схемі складніше. Зазвичай воно здійснюється таким чином: заводять булевий прапорець для кожної комірки. Він має означати видалений цей елемент з таблиці чи ні. Тобто видалення елемента означає встановлення цього прапорця. При цьому доведеться модифікувати процедуру пошуку існуючого елемента так, щоб вона вважала видалені комірки зайнятими, а процедуру додавання — щоб вона їх вважала вільними і скидала прапорець при доданні елемента.
Нижче наведені деякі розповсюджені варіанти переборів. Одразу зауважимо, що нумерація елементів послідовності спроб і комірок геш-таблиці при переборі ведеться від нуля, а N — розмір геш-таблиці.
- Лінійне зондування: комірки геш-таблиці послідовно переглядаються з деяким фіксованим інтервалом k між комірками (зазвичай, ), тобто i-й елемент послідовності — це комірка з номером (hash(x) + ik) mod N. Для того, щоб всі комірки виявились перебраними по одному разу, необхідно, щоб k було взаємно-простим з розміром геш-таблиці.
- Квадратичне зондування: інтервал між комірками з кожним кроком збільшується на константу, що задається в загальному вигляді з допомогою деякого квадратичного поліному k1i+k2i2. У найпростішому випадку k1 = 0, k2 = 1 для і = 0,1,2,3,… отримаємо:
- h0 = hash(x) mod N, h1 = (hash(x) + 12) mod N, h2 = (hash(x) + 22) mod N, h3 = (hash(x) + 32) mod N, …
- Подвійне гешування: інтервал між комірками фіксований, як при лінійному переборі, але, на відміну від нього, розмір інтервалу обчислюється другою, допоміжною геш-функцією, тобто може бути різним для різним ключів. Значення цієї геш-функції мають бути ненульовими і взаємно простими з розміром геш-таблиці, що найпростіше всього зробити, якщо взяти просте число як розмір, і вимагати, щоб допоміжна геш-функція приймала значення від 1 до N − 1.
Недоліком усіх схем відкритої адресації є те, що кількість елементів, які можуть зберігатися в таблиці може досягти кількість комірок в масиві. Дійсно, навіть з хорошими геш-функціями, продуктивність серйозно падає при коефіцієнті завантаження більшому ніж 0,7 або біля того. Для багатьох застосувань, це обмеження викликає необхідність використання динамічної зміну розміру з відповідними затратами.
Схеми відкритої адресації також накладають суворіші вимоги до геш-функції: окрім рівномірного розподілу значень по всьому масиву, функція має також мінімізувати скупчення геш-значень, що слідують одна за одною в послідовності спроб.
Відкрита адресація зберігає пам'ять тільки у випадку якщо елементи малого розміру і коефіцієнт завантаження не дуже малий. Якщо коефіцієнт завантаження близький до нуля, відкрита адресація марнотратна навіть якщо кожен елемент займає лише два машинних слова.
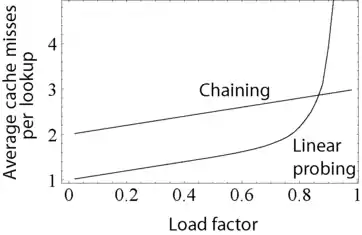
Відкрита адресація уникає витрат на розміщення кожного нового елемента, і може бути реалізована навіть у відсутності розподільника пам'яті. Вона також уникає додаткових посилань для доступу до набору елементів з певним однаковим значенням геш-функції. З малими розмірами елементів, цей фактор може додати продуктивності порівняно з таблицею організованою методом ланцюжків особливо при пошуку.
Геш-таблиця з лінійною адресацією також легше серіалізується, через відсутність вказівників.
З іншого боку, зазвичай відкрита адресація — поганий вибір для великих елементів, через те, що такі елементи заповнюють весь кеш процесора (нівелюючи переваги кешу), також значна кількість місця втрачається через велику кількість порожніх комірок. Якщо відкрита адресація зберігає тільки вказівники на елементи, вона використовує кількість пам'яті, яку можна порівняти з використанням пам'яті методом ланцюжків, але втрачає перевагу в швидкості.
Узагальнюючи, відкриту адресацію краще використовувати для геш-таблиць з малими елементами, які зберігаються в таблиці. Вони особливо підходять для елементів в одне слово або менших. У випадку коли очікується високий коефіцієнт завантаження, елементи великі за розміром, або можуть мати різні розміри, метод ланцюжків показує таку ж або кращу продуктивність.
Зрештою, при розумному використанні, будь-який алгоритм зазвичай достатньо швидкий; і відсоток обчислень в геш-таблицях малий. Використання пам'яті рідко вважається надмірним. Отже, в більшості випадків різниця між цими двома алгоритмами мінімальні, і, як правило, інші міркування виходять на арену.
Об'єднане гешування
Гібрид методу ланцюжків та відкритої адресації (англ. Coalesced hashing), що розв'язує колізії з допомогою додаткових ланок між вузлами зв'язаних списків всередині таблиці[2]. Як і метод ланцюжків, не має кластерних ефектів і геш-таблиця може бути ефективно заповнена.
Гешування зозулею
Ще одна альтернатива відкритої адресації — англ. Cuckoo hashing,— забезпечує постійний час пошуку і сталий амортизований час для вставок і вилучень. Цей метод використовує дві чи більше геш-функції, а це означає, що будь-яка пара ключ/значення може знаходитись в двох або більше місцях. Для пошуку використовується перша геш-функція; якщо ключ/значення не знайдено, то використовується друга геш-функція, і так далі. Якщо колізія відбувається під час вставки, то ключ повторно гешується другою геш-функцією, щоб відобразити його в інший бакет. Якщо всі функції гешування використані, а колізія не розв'язана, то старий ключ на місці колізії видаляється, щоб звільнити місце для нового ключа, і цей попередній старий ключ повторно гешується однією з наступних геш-функцій, які відображають його в інший бакет. Якщо це також призводить до колізії, то процес повторюється, поки колізія не зникне або процес пройде через всі бакети в таблиці. Таким шляхом оптимізується використання пам'яті.
Hopscotch гешування
Інший альтернативний метод, поєднує в собі гешування зозулею та лінійне зондування але таким чином, щоб обійти обмеження цих методів[3]. Зокрема, він добре працює навіть тоді, коли коефіцієнт завантаження таблиці зростає до 0,9.
Примітки
- геш-таблиця // Англійсько-український словник з математики та інформатики / уклад. Є. Мейнарович, М. Кратко. — 2010.
- Tenenbaum, Aaron M.; Langsam, Yedidyah; Augenstein, Moshe J. (1990). Data Structures Using C. Prentice Hall. с. 456–461, pp. 472. ISBN 0-13-199746-7.
- Herlihy, Maurice; Shavit, Nir; Tzafrir, Moran (2008). Hopscotch Hashing. DISC '08: Proceedings of the 22nd international symposium on Distributed Computing. Berlin, Heidelberg: Springer-Verlag. с. 350–364.
