Кеш процесора
Кеш процесора — кеш, який використовується центральним процесором (англ. CPU) для скорочення середнього часу доступу до пам'яті комп'ютера. Кеш — це швидша і менша за розміром пам'ять, яка зберігає копії даних, що часто використовуються, з головної пам'яті.
Коли процесору потрібно звернутися в пам'ять для читання або запису даних, він спочатку перевіряє, чи є їхні копії в кеші. У разі успіху перевірки процесор виконує операцію використовуючи кеш, що працює швидше ніж при використанні більш повільної основної пам'яті. Детальніше про затримки пам'яті див. затримки (англ. SDRAM latency) SDRAM: tCAS, tRCD, tRP, tRAS
Більшість сучасних мікропроцесорів для настільних комп'ютерів і серверів мають щонайменше три незалежних кеші: кеш інструкцій для прискорення завантаження машинного коду, кеш даних для прискорення читання і запису даних і буфер асоціативної трансляції (TLB) для прискорення трансляції віртуальних (логічних) адрес у фізичні, як для інструкцій, так і для даних. Кеш даних часто реалізується у вигляді багаторівневого кешу (L1, L2, L3)..
Збільшення розміру кеш-пам'яті може позитивно впливати на продуктивність майже всіх застосунків, хоча в деяких випадках ефект незначний. Робота кеш-пам'яті зазвичай прозора для програміста, проте для її ефективного використання у деяких випадках застосовуються спеціальні алгоритмічні прийоми, які змінюють порядок обходу даних в ОЗП або підвищують їх локальність (наприклад, при блочному множенні матриць).
Принцип роботи
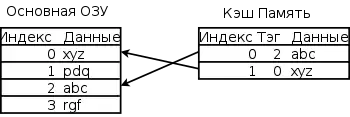
Даний розділ описує типовий кеш даних і деякі види кешу інструкцій; TLB може бути влаштований складніше, а кеш інструкцій — простіше. На діаграмі праворуч зображені основна і кеш-пам'ять. Кожен рядок — група комірок пам'яті, що містить дані, організовані в кеш-лінії. Розмір кожної кеш-лінії може розрізнятися у різних процесорах, але для більшості x86-процесорів він становить 64 байта. Розмір кеш-лінії зазвичай більше розміру даних, до якого є можливим доступ з однієї машинної команди (типові розміри від 1 до 16 байт). Кожна група даних в пам'яті розміром у 1 кеш-лінію має порядковий номер. Для основної пам'яті цей номер є адресою пам'яті з відкинутими молодшими бітами. У кеші кожної кеш-лінії додатково ставиться у відповідність тег, який є адресою продубльованих в цій кеш-лінії даних в основній пам'яті.
При звертанні процесора в пам'ять спочатку проводиться перевірка, чи зберігає кеш запитувані з пам'яті дані. Для цього проводиться порівняння адреси запиту з значеннями всіх тегів кешу, в яких ці дані можуть зберігатися. Випадок збігу з тегом якої-небудь кеш-лінії називається попаданням в кеш (англ. cache hit), зворотний випадок називається кеш-промахом (англ. cache miss). Попадання в кеш дозволяє процесору негайно провести читання або запис даних у кеш-лінії з збіглася тегом. Відношення кількості попадань в кеш до загальної кількості запитів до пам'яті називають рейтингом влучень (англ. hit rate), воно є мірою ефективності кешу для обраного алгоритму або програми.
У разі промаху в кеші виділяється новий запис, у тег якого записується адреса поточного запиту, а в саму кеш-лінію — дані з пам'яті після їх прочитання або дані для запису в пам'ять. Промахи з читання затримують виконання, оскільки вони вимагають запиту даних в більш повільної основної пам'яті. Промахи по запису можуть не давати затримку, оскільки потрібні дані можуть бути збережені в кеші, а запис їх в основну пам'ять можна зробити у фоновому режимі. Робота кешу інструкцій багато в чому схожа на вищенаведений алгоритм роботи кешу даних, але для інструкцій виконуються тільки запити на читання. Кеш інструкцій і даних можуть бути розділені для збільшення продуктивності (принцип, використовуваний в Гарвардській архітектурі) або об'єднані для спрощення апаратної реалізації.
Для додавання даних в кеш після кеш-промаху може знадобитися витіснення (англ. evict) раніше записаних даних. Для вибору заміщаючого рядка кешу використовується евристика, звана політика заміщення (англ. replacement policy). Основною проблемою алгоритму є передбачення, яка рядок найімовірніше не буде потрібно для подальших операцій. Якісні передбачення складні, і апаратні кеші використовують прості правила, такі, як LRU. Відмітка деяких областей пам'яті як тих, що не кешуються (англ. non cacheable) покращує продуктивність за рахунок заборони кешування рідко використовуваних даних. Промахи для такої пам'яті не створюють копію даних в кеші.
При запису даних у кеш повинен існувати певний момент часу, коли вони будуть записані в основну пам'ять. Це час контролюється політикою запису (англ. write policy). Для кешу зі наскрізним записом (англ. write-through) будь-який запис у кеш приводить до негайної запису в пам'ять. Інший тип кешей, зворотна запис англ. write-back (іноді також званий copy-back), відкладає запис на більш пізній час. У таких кешах відстежується стан кеш-лінійок ще не скинутих в пам'ять (відмітка бітом «брудний» англ. dirty). Запис в пам'ять проводиться при витісненні подібної рядка кешу. Таким чином, промах в кеші, що використовує політику зворотного запису, може вимагати двох операцій доступу в пам'ять, один для скидання стану старої рядки і інший — для читання нових даних.
Існують також змішані політики. Кеш може бути зі наскрізним записом (англ. write-through), але для зменшення кількості транзакцій на шині записи можуть тимчасово міститися в чергу і об'єднуватися один з одним.
Дані в основній пам'яті можуть змінюватися не тільки процесор, але і периферією, що використовує прямий доступ до пам'яті, або іншими процесорами багатопроцесорні системи. Зміна даних призводить до застарівання їх копії в кеші (стан stale). В іншої реалізації, коли один процесор змінює дані в кеші, копії цих даних в кешах інших процесорів будуть помічені як stale. Для підтримки вмісту декількох кешей в актуальному стані використовується спеціальний протокол кеш когерентності.
Структура запису в кеші
Типова структура запису в кеші
| Блок даних | тег | біт актуальності |
Блок даних (кеш-лінія) містить безпосередню копію даних з основної пам'яті. Біт актуальності означає, що дана запис містить актуальну (найсвіжішу) копію.
Структура адреси
| тег | індекс | зміщення |
Адреса пам'яті, що розділяється (від старших біт до молодших) на Тег, індекс і зміщення. Довжина поля індексу дорівнює біт і відповідає ряду (рядку) кешу, використовуваної для запису. Довжина зсуву дорівнює .


Асоціативність
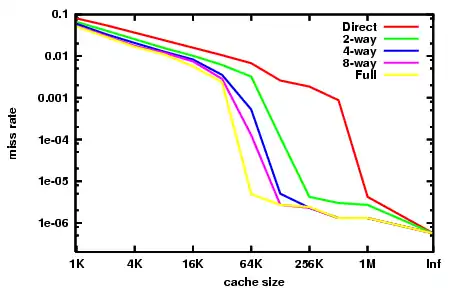
Асоціативність є компромісом. Перевірка більшого числа записів вимагає більше енергії, площі чипу, і, потенційно, часу. Якщо б існувало 10 місць, які алгоритм витіснення міг би відобразити місце в пам'яті, тоді перевірка наявності цього місця в кеші зажадала б переглянути 10 записів в кеші. З іншого боку, кеші з високою асоціативністю піддаються меншому кількості промахів (див. нижче «конфліктуючі промахи») і процесор витрачає менше часу на читання з повільної основної пам'яті. Існує емпіричне спостереження, що подвоєння асоціативності (від прямого відображення до 2-канальної або від 2- до 4-канальної) має приблизно такий же вплив на інтенсивність влучень (hit rate), що і подвоєння розміру кешу. Збільшення асоціативності понад 4 каналів приносить менший ефект для зменшення кількості промахів (miss rate) і зазвичай виробляється з інших причин, наприклад, через перетин віртуальних адрес.
В порядку погіршення (збільшення тривалості перевірки на потрапляння) та поліпшення (зменшення кількості промахів):
- кеш прямого відображення (англ. direct mapped cache) — найкращий час попадання і, відповідно, найкращий варіант для великих кешів;
- 2-канальний множинно-асоціативний кеш англ. 2-way set associative cache;
- 2-канальний skewed асоціативний кеш (англ. «the best for tradeoff …. caches whose sizes are in the range 4K-8K bytes» — André Seznec);
- 4-канальний множинно-асоціативний кеш (англ. 4-way set associative cache);
- повністю асоціативний кеш, (англ. fully associative cache) — найкращий (найнижчий) відсоток промахів (miss rate) і найкращий варіант при надзвичайно високих витратах при промаху (miss penalty).
 Кеш прямого відображення
Кеш прямого відображення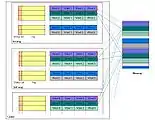 n-канальний множинно-асоціативний кеш
n-канальний множинно-асоціативний кеш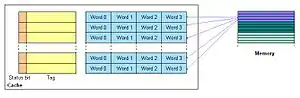 Повністю асоціативний кеш
Повністю асоціативний кеш
Види промахів
Промах з читання з кешу інструкцій. Зазвичай дає дуже велику затримку, оскільки процесор не може продовжувати виконання програми (принаймні, виконання поточного потоку) і змушений простоювати в очікуванні завантаження інструкції з пам'яті.
Промах з читання з кешу даних. Зазвичай дає меншу затримку, оскільки інструкції, які не залежать від запитаних даних, можуть продовжувати виконуватися, поки запит обробляється в основній пам'яті. Після отримання даних з пам'яті можна продовжувати виконання залежних інструкцій.
Категорії промахів (Three Cs)
- Compulsory misses — промахи, викликані першою згадкою потрібної адреси. Розміри кешей і їх асоціативність не впливають на кількість даних промахів. Попередня вибірка (prefetching), як програмну, так і апаратну, може допомогти, так само, як і збільшення розміру кеш-лінії (як виду апаратного вибору). Такі промахи іноді називають «холодними».
- Capacity misses — промахи, викликані виключно кінцевим розміром кешу, що відбуваються незалежно від ступеня асоціативності або розміру кеш-лінії. Графік таких промахів щодо розміру кешу може дати деяку міру тимчасової локальності (temporal locality) деякого набору запитів в пам'ять. Варто зауважити, що не існує поняття повного кешу, порожнього кешу або майже повного кешу, так як кеші процесора майже весь час мають кеш-лінії в зайнятому стані, і, отже, практично кожен заклад нової лінії зажадає гасіння вже зайнята.
- Conflict misses — промахи, викликані конфліктом. Їх можна уникнути, якщо б кеш не витіснив запис раніше. Можна додатково розділити на промахи, викликані відображенням (конкретним значенням асоціативності) і промахи заміщення, які викликані конкретним алгоритмом вибору записів для заміщення.
Трансляція адрес
Більша частина процесорів загального призначення реалізує якийсь варіант віртуальної пам'яті. Коротко кажучи, кожна програма, що виконується на машині, бачить власне спрощене адресний простір, що містить код і дані тільки цієї програми. Будь-яка програма використовує своє віртуальне адресний простір незалежно від його місцезнаходження фізичної пам'яті.
Наявність віртуальної пам'яті вимагає від процесора проведення трансляції віртуальних (математичних) адрес, використовуваних програмою, у фізичні адреси, відповідні реальному розташуванню в ОЗП. Частина процесора, провідна це перетворення, називається пристрій управління пам'яттю (MMU). Для прискорення трансляцій в MMU доданий кеш нещодавно використаних відображень (відповідностей віртуальних і фізичних адрес), званий Translation Lookaside Buffer (TLB).
Для подальшого опису важливі три особливості процесу трансляції адрес:
- Затримка: Фізичний адресу буде отримано від MMU тільки через деякий час, аж до декількох тактів, після подачі на вхід MMU віртуального адреси з генератора адрес.
- Ефект накладення: Кілька віртуальних адрес, які можуть відповідати одному фізичному. У більшості процесорів гарантується, що всі записи по фізичній адресою будуть здійснені в порядку, заданому програмою. Для виконання цієї властивості потрібна перевірка, що тільки один екземпляр копії даних з фізичної адреси знаходиться в даний момент в кеші.
- Одиниця відображення: Віртуальне адресний простір розбито на сторінки — блоки пам'яті фіксованого розміру, що починаються з адреси, кратних їх розміром. Наприклад, 4 ГБ адресного простору можна розділити на 1048576 сторінки по 4 КБ, для кожної з яких можливо незалежне відповідність фізичним сторінкам. У сучасних процесорах часто підтримується використання одночасно декількох розмірів сторінки, наприклад, 4 КБ і 2 МБ для x86-64, а в деяких сучасних AMD-процесорах ще і 1 ГБ.
Важливо також зауважити, що перші системи віртуальної пам'яті були дуже повільними, тому що вони вимагали перевірки таблиці сторінок (зберігається в основній ПАМ'ЯТІ) перед будь-яким програмним зверненням в пам'ять. Без використання кешування для відображень такі системи зменшують швидкість роботи з пам'яттю приблизно в 2 рази. Тому використання TLB дуже важливо і іноді його додавання в процесори передувало появі звичайних кешу даних та інструкцій.
По відношенню до віртуальної адресації кеші даних та інструкцій можуть бути поділені на 4 типи. Адреси в кешах використовуються для двох різних цілей: індексування і тегів.
- Physically indexed, physically tagged (PIPT) — фізично індексовані і фізично тегируемые. Такі кеші прості і уникають проблем з накладенням (aliasing), але вони повільні, так як перед зверненням в кеш потрібен запит фізичної адреси в TLB. Цей запит може викликати промах в TLB і додаткове звернення в основну пам'ять перед тим, як наявність даних буде перевірено в кеші.
- Virtually indexed, virtually tagged (VIVT) — віртуально індексовані і віртуально тегируемые. І для тегів, і для індексу використовується віртуальний адресу. Завдяки цьому перевірки наявності даних в кеші відбуваються швидше, не вимагаючи звернення до MMU. Однак виникає проблема накладання, коли кілька віртуальних адрес відповідають одному й тому ж фізичному. У цьому випадку дані будуть закешовані двічі, що сильно ускладнює підтримку когерентності. Іншою проблемою є омоніми, ситуації, коли один і той же віртуальний адресу (наприклад, у різних процесах) відображається різні фізичні адреси. Стає неможливим розрізнити такі відображення виключно по віртуальному індексу. Можливі рішення: скидання кешу при перемиканні між завданнями (context switch), вимога непересечения адресних просторів процесів, тегування віртуальних адрес ідентифікатором адресного простору (address space ID, ASID) або використання фізичних тегів. Також виникає проблема при зміні відображення віртуальних адрес у фізичні, що вимагає скидання кеш-ліній, для яких змінилося відображення.
- Virtually indexed, physically tagged (VIPT) — віртуально індексовані і фізично тегируемые. Для індексу використовується віртуальний адреса, а для тегу — фізичний. Перевагою над першим типом є менша затримка, оскільки можна шукати кеш-лінію одночасно з трансляцією адрес в TLB, однак порівняння тегу затримується до одержання фізичної адреси. Перевагою над другим типом є виявлення омонімів (homonyms), так як тег містить фізична адреса. Для даного типу потрібно більше біт для тегу, оскільки індексні біти використовують інший тип адресації.
- Physically indexed, virtually tagged — фізично індексовані і віртуально теговані кеші вважаються непотрібними і маргінальними і представляють виключно академічний інтерес.
Швидкість цих дій (затримка завантаження з пам'яті) критично важлива для продуктивності процесорів, і тому більшість сучасних L1-кешей є віртуально індексованими, що як мінімум дозволяє блоку MMU робити запит в TLB одночасно з запитом даних їх кеш-пам'яті.
Віртуальне тегування і механізм vhints
Але віртуальна індексація не є найкращим вибором для інших рівнів кешу. Вартість виявлення перетину віртуальних адрес (aliasing) зростає із збільшенням розміру кешу і, в результаті, більшість реалізацій L2 і більш далеких від процесора рівнів кешу використовують індексування за фізичними адресами
Досить тривалий час кеші використовували для тегів як фізичні, так і віртуальні адреси, хоча віртуальне тегування в даний час зустрічається дуже рідко. Якщо TLB-запит закінчується раніше запиту в кеш-пам'ять, фізичний адресу буде доступний для порівняння з тегом до моменту, коли це буде необхідно, і, отже, віртуальне тегування не потрібно. Великі кеші частіше тегируются фізичними адресами, і лише невеликі швидкодіючі кеші використовують для тегів віртуальні адреси. У сучасних процесорах загального призначення, віртуальне тегування замінено на механізм vhints, описаний далі.
Ієрархія кешей в сучасних мікропроцесорах
Більшість сучасних процесорів містять у собі кілька взаємодіючих кешей.
Спеціалізовані кеші
Суперскалярні процесори здійснюють доступ до пам'яті з декількох етапів конвеєра: читання інструкцій (instruction fetch), трансляція віртуальних адрес у фізичні, читання даних (data fetch). Очевидним рішенням є використання різних фізичних кешей для кожного з цих випадків, щоб не було боротьби за доступ до одного з фізичних ресурсів з різних стадій конвеєра. Таким чином, наявність конвеєра зазвичай призводить до наявності, принаймні, трьох роздільних кешей: кеш інструкцій, кеш трансляцій TLB і кеш даних, кожен з яких спеціалізується на своєму завданні.
Конвеєрні процесори, що використовують роздільні кеші для даних і інструкцій (такі процесори зараз повсюдні), називаються процесорами з Гарвардською архітектурою. Спочатку даний термін застосовувався для комп'ютерів, у яких інструкції і дані розділені повністю і зберігаються в різних пристроях пам'яті. Однак таке повне розділення не виявилося популярним, і більшість сучасних комп'ютерів мають один пристрій основної пам'яті, тому можуть вважатися машинами з архітектурою фон Неймана.
Багаторівневі кеші
Однією з проблем є фундаментальна проблема балансу між затримками кешу і інтенсивністю влучень. Великі кеші мають більш високий відсоток влучень але, разом з тим, і велику затримку. Щоб послабити протиріччя між цими двома параметрами, більшість комп'ютерів використовує кілька рівнів кешу, коли після маленьких і швидких кешей знаходяться більш повільні великі кеші (зараз — сумарно до 3 рівнів в ієрархії кешу).
У поодиноких випадках реалізують 4 рівні кеш-пам'яті.
Багаторівневі кеші зазвичай працюють в послідовності від менших кешей до великих. Спочатку відбувається перевірка найменшого і заразом — найшвидшого кешу першого рівня (L1), у разі попадання процесор продовжує роботу на високій швидкості. Якщо менший кеш дав промах, перевіряється наступний, трохи більший і більш повільне кеш другого рівня (L2), і так далі, поки не буде запиту до основного ОЗП.
По мірі того, як різниця затримок між ОЗП і найшвидшим кешем збільшується, в деяких процесорах збільшують кількість рівнів кешу (у деяких — до 3х рівнів на кристалі). Наприклад, процесор Alpha 21164 в 1995 році мав накристалльный кеш 3го рівня в 96 КБ; IBM POWER4 у 2001 році мав до чотирьох кешу L3 32 МБ на окремих кристалах, що використовуються спільно декількома ядрами; Itanium 2 у 2003 році мав 6 МБ кеш L3 на кристалі; Xeon MP під кодом «Tulsa» у 2006 році — 16 МБ кешу L3 на кристалі, спільний на 2 ядра; Phenom II в 2008 році — до 6 МБ універсального кешу L3; Intel Core i7 у 2008 році — 8 МБ накристалльного кешу L3, який є інклюзивним та поділяється між усіма ядрами. Користь від кешу L3 залежить від характеру звернень програми в пам'ять.
Нарешті, з іншого боку ієрархії пам'яті знаходиться регістровий файл самого мікропроцесора, який можна розглядати як невеликий і найшвидший кеш в системі зі спеціальними властивостями (наприклад, статичне планування компілятором при розподілі регістрів). Детальніше див. loop nest optimization. Регістрові файли також можуть мати ієрархію: Cray-1 (у 1976 році) мав 8 адресних «A»-регістрів і 8 скалярних «S»-регістрів загального призначення. Також машина містила набір з 64 адресних «B» і 64 скалярних «T» регістрів, звернення до яких було довше, але все ж значно швидше основний ОЗП. Ці регістри були введені через відсутність в машині кешу даних (хоча кеш команд в машині був)
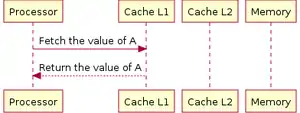 Витребувані дані зчитуються з кешу першого (англ. L1) рівня.
Витребувані дані зчитуються з кешу першого (англ. L1) рівня.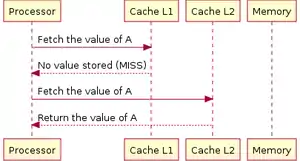 Витребувані дані зчитуються з кешу другого (англ. L2) рівня.
Витребувані дані зчитуються з кешу другого (англ. L2) рівня.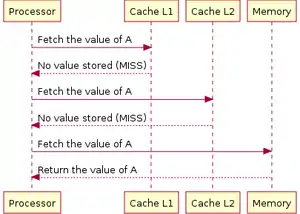 У разі відсутності потрібних даних в кешах, проводиться читання з ОЗП.
У разі відсутності потрібних даних в кешах, проводиться читання з ОЗП.
Ексклюзивність (винятковість) і інклюзивність
Для багаторівневих кешей потрібно робити нові архітектурні рішення.
Наприклад, в деякому процесорі можуть вимагати, щоб всі дані, що зберігаються в кеші L1, зберігалися також і в кеш-пам'яті L2. Такі пари кешей називають строго інклюзівними (англ. inclusive). Інші процесори (наприклад, AMD Athlon) можуть не мати такого вимоги, тоді кеші називаються ексклюзивні (виняткові) — дані можуть бути або в L1 або L2 кеш, але ніколи не можуть бути одночасно в обох.
Досі іншим процесорам (таким, як Pentium II, Pentium III і Pentium 4) не потрібні, щоб дані в кеші першого рівня також розміщувалися в кеші другого рівня, тим не менш, вони продовжують робити. Немає ніякого універсального загальноприйнятого імені для цієї проміжної політики, хоча часто використовується термін головним чином інклюзівно (англ. mainly inclusive).
Перевага виняткових кешей в тому, що вони зберігають більше даних. Це перевага більше, коли винятковий кеш L1 порівнянний за розміром з кешем L2, і менше, якщо кеш L2 у багато разів більше, ніж кеш L1. Коли L1 пропускає і L2 отримує доступ у разі попадання, рядок кешу попадання в L2 обмінюється з рядком в L1.
Victim cache
Victim cache або Victim buffer (дослівно «Кеш жертв») — це невеликий спеціалізований кеш, зберігає ті кеш-лінії, які нещодавно були витіснені з основного кешу мікропроцесора при їх заміщення. Цей кеш розташовується між основним кешем і його англ. refill path. Зазвичай кеш жертв є повністю асоціативним і служить для зменшення кількості конфліктних промахів (conflict miss). Багато часто використовувані програми не вимагають повного асоціативного відображення для всіх спроб доступу до пам'яті. За статистикою лише невелика частка звернень до пам'яті вимагає високого ступеня асоціативності. Саме для таких звернень є кеш жертв, що надає високу асоціативність для таких рідкісних запитів. Був запропонований Norman Jouppi (DEC) в 1990. Розмір такого кешу може становити від 4 до 16 кеш-ліній.
Кеш трас
Одним з найбільш екстремальних випадків спеціалізації кешей можна вважати кеш трас (англ. trace cache), використовуваний в процесорах Intel Pentium 4. Кеш трас — це механізм для збільшення пропускної здатності завантаження інструкцій і для зменшення тепловиділення (у разі Pentium 4) за рахунок зберігання декодованих трас інструкцій. Таким чином цей кеш виключав роботу декодера при повторному виконанні коду, що нещодавно виконувався
Однією з ранніх публікацією про кеші трас була стаття колективу авторів (Eric Rotenberg, Steve Bennett і Jim Smith), що вийшла в 1996 році під назвою «Trace Cache: a Low Latency Approach to High Bandwidth Instruction Fetching.» (Кеш трас: низколатентный підхід для забезпечення високої пропускної спроможності завантаження інструкцій).
Кеш трас зберігає декодированные інструкції або після їх декодування, або після закінчення їх виконання. Узагальнюючи, інструкції додаються в кеш трас в групах, що представляють собою або базові блоки, або динамічні траси. Динамічна траса (шлях виконання) складається тільки з інструкцій, результати яких були значимі (використовувалися згодом), і видаляє інструкції, які знаходяться в не які працюють гілках, крім того, динамічна траса може бути об'єднанням декількох базових блоків. Така особливість дозволяє пристрою підвантаження інструкцій у процесорі завантажувати відразу декілька базових блоків без необхідності піклуватися про наявність розгалужень у потоці виконання.
Лінії трас зберігаються в кеші трас за адресами, відповідним лічильника інструкцій першої машинної команди з траси, до яких доданий набір ознак передбачення розгалужень. Така адресація дозволяє зберігати різні траси виконання, що починаються з однієї адреси, але представляють різні ситуації по результату передбачення розгалужень. На стадії підвантаження інструкції (instruction fetch) конвеєра інструкцій для перевірки попадання в кеш трас використовується як поточний лічильник інструкцій (program counter), так і стан провісника розгалужень. Якщо попадання сталося, лінія траси безпосередньо подається на конвеєр без необхідності опитувати звичайний кеш (L2) або основне ОЗП. Кеш трас подає машинні команди на вхід конвеєра, поки не скінчиться лінія траси, або поки не станеться помилка передбачення в конвеєрі. У разі промаху кеш трас починає будувати таку лінію траси, завантажуючи машинний код з кешу або з пам'яті.
Схожі кеші трас використовувалися в Pentium 4 для зберігання декодованих мікрооперацій і мікрокоду, що реалізує складні x86-інструкції. Smith, Rotenberg and Bennett's paper См повний текст роботи в Citeseer.
Реалізації
Історія
У ранні роки мікропроцесорних технологій доступу в пам'ять був лише трохи повільніше доступу до процесорним регістрів. Але з 1980х розрив у продуктивності між процесорами і пам'яттю став наростати. Мікропроцесори удосконалювалися швидше, ніж пам'ять, особливо в плані частоти функціонування, таким чином, пам'ять ставала вузьким місцем при досягненні повної продуктивності від системи. Хоча було технічно можливим мати основну пам'ять настільки ж швидко, як і процесор, був обраний більш економічний шлях: використовувати надмірну кількість низькошвидкісний пам'яті, але ввести в систему невелику, але швидку кеш-пам'ять, для пом'якшення розриву в продуктивності. В результаті отримали на порядок великі обсяги пам'яті, приблизно за ту ж ціну і з невеликими втратами загальної продуктивності.
Читання даних з кешу для сучасних процесорів зазвичай займає більш одного такту. Час виконання програм є чутливим до затримок читання з кешу даних першого рівня. Багато зусиль розробників, а також потужності і площі кристала при створенні процесора відводиться для прискорення роботи кешей.
Найпростішим кешем є віртуально індексований кеш прямого відображення. Віртуальний адресу підраховується за допомогою суматора, відповідна частина адреси виділяється і використовується для індексування SRAM, який поверне завантажуються дані. Дані можуть бути вирівняні по байтовим кордонів байтовому сдвигателе і потім передані наступної операції. При такому читанні не потрібна якась перевірка тегів, фактично немає навіть необхідності зчитувати тег. На більш пізніх стадіях конвейєра, перед закінченням виконання інструкції читання потрібно читання тегу і його порівняння з віртуальним адресою, щоб упевнитися, що сталося попадання в кеш. Якщо ж був промах, потрібно читання з пам'яті або більш повільного кешу з подальшим оновленням розглянутого кешу і перезапуском конвеєра.
Асоціативний кеш більш складний, тому що певний варіант тегу потрібно вважати для визначення, яку частину кешу вибрати. Кеш N-way set-associative першого рівня зазвичай зчитує одночасно всі N можливих тегів і N даних паралельно, потім проводить порівняння тегів з адресою і вибір даних, асоційованих з збіглася тегом. Кеш 2-го рівня в цілях економії енерговиділення іноді виконують спочатку читання тегів, і тільки потім читання одного елемента даних SRAM-даних.
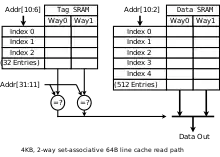
Діаграма справа повинна показати, як відбувається використання різних частин адреси. Біт 31 адреси є найбільш значущим бітом (старшим), біт 0 — найменш значущим бітом (молодшим). На діаграмі показані дві SRAM, індексація і мультиплексування для 4 КБ, 2-way set-associative, віртуально індексованого і віртуально тегированного кешу з 64байтними блоками, 32бітною шириною читання і 32битным віртуальним адресою.
Оскільки кеш має розмір 4 КБ і лінії розміром 64 байта, у ньому зберігається 64 лінії, і ми можемо вважати за два рази з тегу SRAM, який містить 32 стовпця, кожен з яких містить кілька 21-бітних тегів. Хоча може бути використана будь-яка функція віртуальної адресації бітів 31 6, щоб індексувати тег і дані SRAM, найпростіше скористатися молодшими розрядами. Так само, тому що об'єм кешу складає 4 кБ і має четырехбайтный шлях для читання і читання проводиться за двома шляхами для кожного доступу, дані SRAM складають 512 рядів шириною 8 байтів.
Більш сучасний кеш, можливо, був би 16-кілобайтним, чотирьохшляховим, набір-асоціативним, віртуально індексовані, віртуально влучаємим і фізично відмічаємим (тегом), з 32-бітовими рядками, 32-бітної шириною шини читання і 36-бітним фізичним адресуванням. Рекурентне співвідношення шляху читання для такого кешу виглядає дуже схоже з розглянутими вище. Замість тегів читаються віртуальні потрапляння (англ. vhits), і знову проводиться відповідність підмножини віртуального адресою. Пізніше, в конвеєрі, віртуальна адреса переводиться у фізичну адресу TLB, і проводиться читання фізичного тегу (тільки одне, так як віртуальне потрапляння поставляє шлях для читання кешу). В кінці фізична адреса порівнюється з фізичним тегом, щоб визначити, чи відбулося попадання.
Деякі процесори SPARC мали прискорені на кілька затримок затвора (англ. gate delay) L1 кеш за рахунок використання SRAM-декодерів замість суматора віртуальних адрес. Детальніше див. Sum addressed decoder.
В X86

Коли x86 мікропроцесори досягли частот у 20 і більше мегагерц (починаючи з Intel 80386), для збільшення продуктивності в них було додано невелику кількість швидкої кеш-пам'яті. Це було необхідно через те, що використовується як системна ОПЕРАТИВНОЇ пам'яті DRAM мала значні затримки (до 120 нс), і вимагала такти для оновлення. Кеш був побудований на базі дорожчий, але значно більш швидкої SRAM, яка в ті часи мала затримки близько 10 нс. Ранні кеші були зовнішніми по відношенню до процесора і часто розташовувалися на материнській платі як 8 або 9 мікросхем в корпусах DIP, розташовані в сокети для можливості збільшення або зменшення розміру кешу. Деякі версії процесора I386 підтримували від 16 до 64 КБ зовнішнього кешу.
З виходом процесора Intel 80486 8 КБ кешу було інтегровано безпосередньо на кристал мікропроцесора. Цей кеш був названий L1 (першого рівня, англ. level 1), щоб відрізняти його від більш повільного кешу на материнській платі, названого L2 (другого рівня, англ. level 2). Останні були значно більше, аж до 256 КБ.
В подальшому випадки відділення кешу проводилися, виходячи лише з міркувань маркетингової політики, наприклад, у мікропроцесорі Celeron, побудованому на ядрі Pentium II.
У мікропроцесорі Pentium використовується роздільний кеш команд і даних. Буфер трансляції адрес (TLB) перетворює адреса в ОЗП відповідний адресу в кеші. Кеш даних Pentium використовує метод зворотного запису (англ. write-back), який дозволяє модифікувати дані в кеші без додаткового звернення до оперативної пам'яті (дані записуються в ОЗП тільки при видаленні з кешу) і протокол MESI (Modified, Exclusive, Shared, Invalid), який забезпечує когерентність даних в кешах процесорів і в ОЗП при роботі в мультипроцесорної системи.
Кожен з окремих кешей, даних і команд мікропроцесора Pentium MMX має об'ємом 16 кБ і містить два порти, по одному для кожного виконавчого конвеєра. Кеш даних має буфер трансляції адрес (TLB).
Наступний варіант реалізації кешей у x86 з'явився в Pentium Pro, в якому кеш другого рівня (об'єднаний для даних і команд, розміром 8 кБ) розміщений в одному корпусі з процесором і кешем першого рівня, розміром 8 кБ, роздільним для даних і команд, і підняв його частоту до частоти ядра. Пізніше кеш другого рівня став розміщуватися на тому ж кристалі, що і процесор. Подвійна незалежна шина (TLB)англ. DIB), нова архітектура кеш-пам'яті, використовує різні шини для підключення процесорного ядра з основною оперативною пам'яттю. Кеш першого рівня двухпортовий, неблокуючий, підтримує одну операцію завантаження і одну операцію запису за такт. Працює на тактовій частоті процесора. За такт передається 64 біта.
У мікропроцесорі Pentium II кеш першого рівня збільшено — 16 кбайт для даних і 16 кбайт для команд. Для кешу другого рівня використовується BSRAM, розташована на одній з процесором платі у картриджі S. E. C. для установки в Slot 1.
З зростанням популярності багатоядерних процесорів на кристал стали додавати кеш третього рівня, названі L3. Цей рівень кешу може бути загальним для декількох ядер і реалізовувати ефективну взаємодію між ядрами. Його обсяг зазвичай більше сумарного обсягу кешу всіх підключених до нього ядер і може досягати 16 МБ.
Популярним кеш на материнській платі залишався до ери виходу Pentium MMX і вийшов з ужитку з введенням SDRAM і зростанням різниці між частотою шини процесора і частотою ядра процесора: кеш на материнській платі став лише трохи швидше основний ОЗП.
Приклад кешу (процесорне ядро К8)
Наведена схема кешей ядра мікропроцесорів AMD K8, на якій видно як спеціалізовані кеші, так і їх багаторівневість.
Ядро використовує чотири різних спеціалізованих кешу: кеш інструкцій, TLB інструкцій, TLB даних і кеш даних:
- Кеш інструкцій складається з 64-байтних блоків, які є копією основної пам'яті, і може завантажувати до 16 байтів за такт. Кожен байт у цьому кеші зберігається в 10 бітах, а не у 8, причому в додаткових бітах відзначені кордону інструкцій (т. о. кеш проводить часткове преддекодирование). Для перевірки цілісності даних використовується лише контроль парності, а не ECC, так як біт парності займає менше місця, а в разі збою пошкоджені дані можна оновити правильною версією з пам'яті.
- TLB інструкцій, що містять копії записів з таблиці сторінок. На кожен запит читання команд потрібно трансляція математичних адрес у фізичні. Записи про трансляції бувають 4 — і 8-байтними, і TLB розбитий на 2 частини, відповідно одна для 4 КБ відображень і інша для 2 і 4 МБ відображень (великі сторінки). Таке розбиття спрощує схеми повністю асоціативного пошуку в кожній з частин. ОС і додатки можуть використовувати відображення різного розміру для частин віртуального адресного простору.
- TLB даних є здвоєним, і обидва буфера містять однаковий набір записів. Їх здвоєння дозволяє виробляти кожен такт трансляцію для двох запитів до даних одночасно. Так само, як і TLB інструкцій, цей буфер розділений між записами двох видів.
- Кеш даних містить 64-байтні копії фрагментів пам'яті. Він розділений на 8 банків (банок), кожний з яких містить по 8 кілобайт даних. Кеш дозволяє проводити по два запити до 8-байтовим даними кожен такт, за умови, що запити будуть оброблені різними банками. Тегові структури в кеші продубльовані, так як кожен 64-байтний блок розподілений по всьому 8 банкам. Якщо відбувається 2 запиту в один такт, вони працюють з власною копією теговій інформації.
Також в цьому ядрі використовуються багаторівневі кеші: дворівневі TLB інструкцій і даних (на другому рівні зберігаються лише записи про 4-кб відображеня), і кеш другого рівня (L2), уніфікований для роботи як з кешами даних та інструкцій 1-го рівня, так і для різних TLB. Кеш L2 є ексклюзивним для даних L1 L1 і інструкцій, тобто кожен ваш 8-байтовий фрагмент може знаходитися або в L1 інструкцій, або в даних L1 або L2. Винятком можуть бути лише байти, складові запису PTE, які можуть перебувати одночасно в TLB і в кеші даних під час обробки віртуального відображення з боку ОС. В такому випадку ОС відповідає за своєчасний скидання TLB після оновлення записів трансляції.
DEC Alpha
У мікропроцесорі DEC Alpha 21164 (випущений в листопаді 1995 року з тактовою частотою 333 МГц) кеш першого рівня може підтримувати деяка кількість (до 21) необроблених промахів. Є шестиелементний файл адрес необроблених промахів (англ. miss address file, MAF), кожен елемент якого містить адресу та регістр для завантаження при промаху (якщо адреси промаху належать одним рядком кешу, то в MAF вони розглядаються як один елемент).
Крім роздільних кешу L1 зі наскрізним записом, на кристалі процесора розташовані частково-асоціативний кеш L2 зі зворотним записом і контролер кешу L3, який працює як у синхронному, так і в асинхронному режимі.
У випущеному в березні 1997 року DEC Alpha 21164PC зовнішній кеш другого рівня; обсяг кешу команд збільшено до 16 кБ.
У мікропроцесорі DEC Alpha 21264 немає кешу другого рівня (контролер якого, тим не менш, розміщується на кристалі), але кеш першого рівня збільшено до 128 кбайт (по 64 кбайт для кешу команд і кеш даних відповідно).
PA-RISC
Розробка Hewlett-Packard для наукових та інженерних обчислень PA-8000 містить буфер переупорядковування адрес (англ. ARB), що відслідковує всі команди завантаження/збереження, який дозволяє скоротити затримку адресування зовнішньої кеш-пам'яті даних і команд, яка в даному процесорі може мати обсяг до 4 МБ. Тим не менш, навіть ефективне управління зовнішнім кешем за допомогою високошвидкісних ліній управління і предвибірки даних і команд з основної пам'яті в кеш не скомпенсировало невисоку швидкість і високу вартість.
Усунути вказані недоліки вдалося PA-8500, в якому за рахунок техпроцесу 0,25 мкм вдалося додати на кристал 512 кБ кешу інструкцій і 1 МБ кешу даних.
PowerPC
Побудований на гарвардській архітектурі PowerPC 620 містить два вбудованих кешу, ємністю 32 кБ кожний, які мають власні блоки управління пам'яттю (англ. MMU) і функціонують незалежно один від одного. Команди і адреси переходів зберігається в кеші BTAC (англ. Branch Target Adress Cache).
Шинний інтерфейс процесора включає повну реалізацію підтримки кешу другого рівня (об'ємом до 128 МБ, працює на частоті процесора удвічі/вчетверо меншою), і для управління роботою зовнішнього кешу не вимагає додаткових тактів. Реалізована комбінація наскрізний і зворотного запису, а також підтримка протоколу MESI.
MIPS
Своя специфіка у кешу L1, застосовуваного в RA-10000, — кожна команда в кеші забезпечена додатковим четырехбитным тегом, який використовується в подальшому декодуванні та класифікації команди.
Див. також
Посилання
- Memory part 2: CPU caches Стаття на lwn.net (автор Ulrich Drepper) з детальним описом кешей
- 8-way set-associative кэш написаний на VHDL
