Двійкове дерево пошуку
Двійкове (або Бінарне) дéрево пóшуку[1] (англ. binary search tree, BST) в інформатиці — двійкове дерево, в якому кожній вершині x зіставлене певне значення val[x]. При цьому такі значення повинні задовольняти умові впорядкованості[1]:
- нехай x — довільна вершина двійкового дерева пошуку. Якщо вершина y знаходиться в лівому піддереві вершини x, то val[y] ≤ val[x].
- Якщо у знаходиться у правому піддереві x, то val[y] ≥ val[x].
| Двійкове дерево пошуку | ||
|---|---|---|
| Тип | Дерево | |
| Винайдено | 1960 | |
| Обчислювальна складність у записі великого О | ||
| Середня | Найгірша | |
| Простір | O(n) | O(n) |
| Пошук | O(log n) | O(n) |
| Вставляння | O(log n) | O(n) |
| Видалення | O(log n) | O(n) |
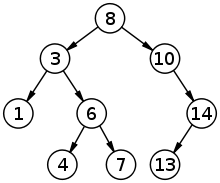
Таке структурування дозволяє надрукувати усі значення у зростаючому порядку за допомогою простого алгоритму центрованого обходу дерева[1].
Представляється таке дерево вузлами наступного вигляду:
*Node = (element, key, left, right, parent). Доступ до дерева T здійснюється за допомогою посилання root.
Бінарні дерева пошуку набагато ефективніші в операціях пошуку, аніж лінійні структури, в яких витрати часу на пошук пропорційні O(n), де n — розмір масиву даних, тоді як в повному бінарному дереві цей час пропорційний в середньому O(log2n) або O(h), де h — висота дерева (хоча гарантувати, що h не перевищує log2n можна лише для збалансованих дерев, які є ефективнішими в алгоритмах пошуку, аніж прості бінарні дерева пошуку).[джерело?]
Операції з двійковим деревом пошуку
Найпоширенішою операцією, яка виконується з бінарним деревом пошуку, є пошук в ньому певного ключа. Крім того, бінарні дерева пошуку підтримують такі запити, як пошук мінімального і максимального елемента, а також попереднього і наступного.
Пошук
Для пошуку вузла із заданим ключем в бінарному дереві пошуку використовується наступна процедура Tree_Search, яка отримує як параметри покажчик на корінь бінарного дерева і ключ k, а повертає покажчик на вузол з цим ключем (якщо такий існує; в іншому випадку повертається значення NIL).
| Tree_Search (x, k) |
|---|
1. if х = nil або k = key [x] 2. then return х 3. if k < key [x] 4. then return Tree_Search (left [x], k) 5. else return Tree_Search (right [x], k) |
Процедура пошуку починається з кореня дерева і проходить вниз по дереву. Для кожного вузла х на шляху вниз його ключ key[x] порівнюється з переданим як параметр ключем k. Якщо ключі однакові, пошук завершується. Якщо k менше key[х], пошук триває в лівому піддереві х; якщо більше — то пошук переходить в праве піддерево. Ту ж процедуру можна записати ітеративно, «розгортаючи» рекурсію в цикл while.
Ітеративна версія процедури Пошук
| Iterative_Tree_Search(x, k) |
|---|
1. while x ≠ NIL и k ≠ key[х] 2. do if k ← key[х] 3. then х ← left[x] 4. else х ← right[x] 5. return x |
Пошук мінімального (максимального) елемента
Алгоритм пошуку мінімального елемента. Елемент з мінімальним значенням ключа легко знайти, слідуючи за вказівниками left від кореневого вузла до тих пір, поки не зустрінеться значення NIL. Процедура TREE_MINIMUM(x) повертає покажчик на знайдений елемент піддерева з коренем x.
| TREE_MINIMUM(X) |
|---|
1. while left[x] ≠ NIL 2. do x ← left[x] 3. return x |
Алгоритм пошуку максимального елемента симетричний:
| TREE_MAXIMUM(X) |
|---|
1. while right[x] ≠ NIL 2. do x ← right[x] 3. return x |
Обидва алгоритми вимагають часу O(h), де h — висота дерева.
Наступний і попередній елементи
Якщо x — покажчик на деякий вузол дерева, то процедура TREE_SUCCESSOR(X) повертає покажчик на вузол з наступним за x елементом або nil, якщо зазначений елемент — останній в дереві:
| TREE_SUCCESSOR(X) |
|---|
1. if right[x] ≠ NIL 2. then return TREE_MINIMUM(right[x]) 3. у ← p[x] 4. while y ≠ NIL та x = right[y] 5. do x ← у 6. у ← p[y] 7. return у |
Наведена процедура окремо розглядає два випадки. Якщо праве піддерево вершини не пусте, то наступний за x елемент є крайнім лівим вузлом у правому піддереві, який виявляється процедурою TREE_MlNlMUM(right[x]). З іншого боку, якщо праве піддерево вузла x пусте, та у x існує наступний за ним елемент y, то y є найменшим предком x, чий лівий вузол також є предком x. Для того щоб знайти y, ми просто піднімаємося вгору по дереву до тих пір, поки не зустрінемо вузол, який є лівим дочірнім вузлом свого батька. Ця дія виконується в рядках 3-7 алгоритму.
Час роботи алгоритму TREE_SUCCESSOR в дереві заввишки h складає O(h), оскільки ми або рухаємося по шляху вниз від вихідного вузла, або по шляху нагору. Процедура пошуку подальшого вузла в дереві TREE_PREDECESSOR симетрична процедурі TREE_SUCCESSOR і також має час роботи O(h).
Якщо в дереві є вузли з однаковими ключами, ми можемо просто визначити наступний і попередній вузли як ті, що повертаються процедурами TREE_SUCCESSOR та TREE_PREDECESSOR відповідно.
Додавання елемента
Для вставки нового значення v в бінарне дерево пошуку Т ми скористаємося процедурою TREE_INSERT. Процедура отримує як параметр вузол z, у якого key[z] = v, left[z] = NIL і right[z] = NIL, після чого вона таким чином змінює Т і деякі поля z, що z виявляється вставленим в відповідну позицію в дереві.
| TREE_INSERT (T, Z) |
|---|
1. у ← NIL 2. х ← root[T] 3. while x ≠ NIL 4. do у ← x 5. if key[z] < key [x] 6. then x ← left[x] 7. else x ← right[x] 8. p [z] ← у 9. if у = NIL 10. then root[T] ← z // Дерево T - пусте 11. else if key[z] <key[y] 12. then left[y] ← z 13. else right[у] ← z |
Видалення елемента
Процедура видалення даного вузла z з бінарного дерева пошуку отримує як аргумент покажчик на z. Процедура розглядає три можливі ситуації:
- Якщо у вузла z немає дочірніх вузлів, то ми просто змінюємо його батьківський вузол р[z], замінюючи в ньому покажчик на z значенням NIL.
- Якщо у вузла z лише один дочірній вузол, то ми видаляємо вузол z, створюючи новий зв'язок між батьківським і дочірнім вузлом вузла z.
- Якщо у вузла z два дочірніх вузла, то ми знаходимо наступний за ним вузол у, у якого немає лівого дочірнього вузла, прибираємо його з позиції, де він перебував раніше, шляхом створення нового зв'язку між його батьком і нащадком, і замінюємо ним вузол Z.
DELETE (T, z)
1 if left[z] = NULL or right[z]=NULL
2 then y:=z
3 else y:=SUCCESSOR(z)
4 if left[y] <> NULL
5 then x:=left[y]
6 else x:= right[y]
7 if x <> NULL
8 then p[x]:=p[y]
9 if p[y]:=NULL
10 then root[T]:=x
11 else if y=left[p[y] ]
12 then left[p[y] ] :=x
13 else right[p[y] ]:=x
14 if y <> z
15 then val[z]:=val[y]
16 //копіювання додаткових даних з y
17 return y
Час на виконання цієї процедури є також O(h)
Див. також
Примітки
- Кормен, Томас; Лейзерсон, Чарльз; Рівест, Рональд; Стайн, Кліфорд (2019). Розділ 12: Двійкові дерева пошуку. Вступ до алгоритмів (вид. 3). К.І.С. с. 301–322. ISBN 978-617-684-239-2.
Джерела
- Томас Кормен; Чарльз Лейзерсон, Рональд Рівест. Вступ до алгоритмів. MIT Press і McGraw-Hill.
- «Искусство программирование. Сортировка и поиск». Дональд Кнут. (рос.)