Код Гаффмана
Алгоритм Гаффмана (або коди Гафмена[1]) — адаптивний жадібний алгоритм оптимального префіксного кодування алфавіту з мінімальною надмірністю. Був розроблений аспірантом Массачусетського технологічного інституту Девідом Гаффманом при написанні ним курсової роботи та надрукований в статті 1952 року «A Method for the Construction of Minimum-Redundancy Codes».[2] В даний час[коли?] використовується в багатьох програмах стиснення даних без втрат.
На відміну від алгоритму Шеннона — Фано, алгоритм Гаффмана залишається завжди оптимальним і для вторинних алфавітів m2 з більш ніж двома символами.
Цей метод кодування складається з двох основних етапів:
- Побудова оптимального кодового дерева
- Побудова відображення код-символ на основі побудованого дерева
Кодування Гаффмана
Один з перших алгоритмів ефективного кодування інформації був запропонований 1952-го року Девідом Гаффманом. Ідея алгоритму така: знаючи ймовірності появи символів у повідомленні, можна описати процедуру побудови кодів змінної довжини, що складаються з цілої кількості бітів. Символам з більшою ймовірністю ставляться у відповідність коротші коди. Коди Гаффмана володіють властивістю префіксності (тобто жодне кодове слово не є префіксом іншого), що дозволяє однозначно їх декодувати.
Класичний алгоритм Гаффмана на вході отримує таблицю частот з якими зустрічаються символи у повідомленні. Далі на підставі цієї таблиці будується дерево кодування Гаффмана (Н-дерево).
- Символи вхідного алфавіту утворюють список вільних вузлів. Кожен лист має вагу, яка може бути рівною або ймовірності, або кількості входжень символу у стиснене повідомлення.
- Вибираються два вільних вузли дерева з найменшими вагами.
- Створюється їхній батьківський вузол з вагою, рівною їх сумарній вазі.
- Вузол-батько додається в список вільних вузлів, а два його нащадки видаляються з цього списку.
- Одній дузі, котра виходить з вузла батька, ставиться у відповідність біт 1, інший — біт 0.
- Кроки, починаючи з другого, повторюються доти, поки в списку вільних вузлів не залишиться тільки один вільний вузол. Він і буде вважатися коренем дерева.
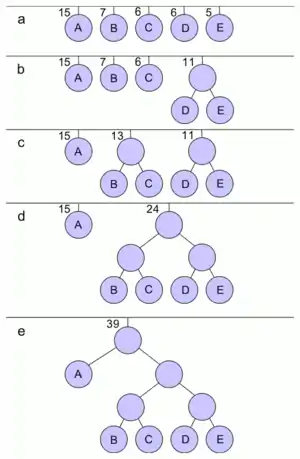
Припустимо, у нас є наступна таблиця частот:
| 15 | 7 | 6 | 6 | 5 |
|---|---|---|---|---|
| A | B | C | D | E |
Цей процес можна подати як побудову дерева, корінь якого — символ з сумою ймовірностей об'єднаних символів, отриманий при об'єднанні символів з останнього кроку, його n0 нащадків — символи з попереднього кроку і т. д.
Щоб визначити код для кожного із символів, що входять у повідомлення, потрібно пройти шлях від листка дерева, який відповідає поточному символу, до його кореня, накопичуючи біти при переміщенні по гілках дерева (перша гілка в шляху відповідає молодшому біту). Отримана таким чином послідовність бітів є кодом даного символу, записаним у зворотному порядку.
Для даної таблиці символів коди Гаффмана будуть виглядати так:
| A | B | C | D | E |
|---|---|---|---|---|
| 0 | 100 | 101 | 110 | 111 |
Оскільки жоден з отриманих кодів не є префіксом іншого, вони можуть бути однозначно декодовані при читанні їх з потоку. Крім того, найбільш частий символ повідомлення А закодований найменшою кількістю біт, а найбільш рідкісний символ E — найбільшою.
При цьому загальна довжина повідомлення, що складається з наведених у таблиці символів, складе 87 біт (в середньому 2,2308 біта на символ). При використанні рівномірного кодування загальна довжина повідомлення склала б 117 біт (рівно 3 біти на символ). Зауважимо, що ентропія джерела, яке незалежним чином породжує символи із зазначеними частотами, складає ~ 2,1858 біта на символ, тобто надмірність побудованого для такого джерела коду Гаффмана, що розуміється, як відмінність середнього числа біт на символ від ентропії, становить менше 0,05 біта на символ.
Класичний алгоритм Гаффмана має ряд істотних недоліків. По-перше, для відновлення вмісту стиснутого повідомлення декодер повинен знати таблицю частот, якою користувався кодер. Отже, довжина стиснутого повідомлення збільшується на довжину таблиці частот, яка повинна надсилатися попереду даних, що може звести нанівець всі зусилля щодо стиснення повідомлення. Крім того, необхідність наявності повної частотної статистики перед початком власне кодування вимагає двох проходів по повідомленню: одного для побудови моделі повідомлення (таблиці частот і Н-дерева), іншого для власне кодування. По-друге, надмірність кодування обертається на нуль лише в тих випадках, коли ймовірності кодованих символів є оберненими степеням числа 2. По-третє, для джерела з ентропією, що не перевищує 1 (наприклад, для двійкового джерела), безпосереднє застосування коду Гаффмана позбавлене сенсу.
Адаптивне стиснення
Адаптивне стиснення дозволяє не передавати модель повідомлення разом з ним самим і обмежитися одним проходом по повідомленню як при кодуванні, так і при декодуванні.
У створенні алгоритму адаптивного кодування Гаффмана найбільші складнощі виникають при розробці процедури поновлення моделі чергових символів. Теоретично можна було би просто вставити всередину цієї процедури повну побудову дерева кодування Гаффмана, однак, такий алгоритм стиснення мав би неприйнятно низьку швидкодію, оскільки побудова Н-дерева — це занадто велика робота і виконувати її при обробці кожного символу нерозумно. На щастя, існує спосіб модифікувати вже наявне Н-дерево так, щоб відобразити обробку нового символу.
Оновлення дерева при зчитуванні чергового символу повідомлення складається з двох операцій.
Перша — збільшення ваги вузлів дерева. Спочатку збільшуємо вагу листка, який відповідає прочитаному символу, на одиницю. Потім збільшуємо вагу батька, щоб привести її у відповідність з новими значеннями ваг нащадків. Цей процес продовжується до тих пір, поки ми не дістанемося кореня дерева. Середнє число операцій збільшення ваги дорівнює середній кількістю бітів, необхідних для того, щоб закодувати символ.
Друга операція — перестановка вузлів дерева — потрібна тоді, коли збільшення ваги вузла призводить до порушення властивості впорядкованості, тобто тоді, коли збільшена вага вузла стає більшою, ніж вага наступного за порядком вузла. Якщо і далі продовжувати обробляти збільшення ваги, рухаючись до кореня дерева, то дерево перестане бути деревом Гаффмана.
Щоб зберегти упорядкованість дерева кодування, алгоритм працює в такий спосіб. Нехай нова збільшена вага вузла дорівнює W+1. Тоді починаємо рухатися по списку у бік збільшення ваги, поки не знайдемо останній вузол з вагою W. Переставимо поточний і знайдений вузли між собою в списку, відновлюючи таким чином порядок у дереві (при цьому батьки кожного з вузлів теж зміняться). На цьому операція перестановки закінчується.
Після перестановки операція збільшення ваги вузлів продовжується далі. Наступний вузол, вага якого буде збільшена алгоритмом, — це новий батько вузла, збільшення ваги якого викликало перестановку.
Переповнення
У процесі роботи алгоритму стиснення ваги вузлів у дереві кодування Гаффмана неухильно зростають. Перша проблема виникає тоді, коли вага кореня дерева починає перевищувати місткість комірки, в якій він зберігається. Як правило, це 16-бітове значення і, отже, не може бути більшим, ніж 65535. Друга проблема, яка заслуговує ще більшої уваги, може виникнути значно раніше, коли розмір найдовшого коду Гаффмана перевищує місткість комірки, яка використовується для того, щоб передати його у вихідний потік. Декодеру все одно, якої довжини код він декодує, оскільки він рухається зверху вниз по дереву кодування, вибираючи з вхідного потоку по одному біту. А кодер повинен починати від листа дерева і рухатися вгору до кореня, збираючи біти, які потрібно передати. Зазвичай для цього використовують змінну цілого типу і, коли довжина коду Гаффмана перевершує розмір цілого типу в бітах, настає переповнення.
Можна довести, що максимальну довжину код Гаффмана для повідомлень з одним і тим самим вхідним алфавітом матиме, якщо частоти символів утворюють послідовність Фібоначчі. Повідомлення з частотами символів, рівними числам Фібоначчі до Fib(18), — це відмінний спосіб випробувати роботу програми стиснення за Гаффманом.
Масштабування ваг вузлів дерева Гаффмана
Беручи до уваги сказане вище, алгоритм поновлення дерева Гаффмана повинен бути змінений таким чином: при збільшенні ваги потрібно перевіряти її на досягнення допустимого максимуму. Якщо ми досягли максимуму, то необхідно «масштабувати» вагу, зазвичай поділивши вагу листка на ціле число, наприклад, 2, а потім перерахувавши ваги всіх інших вузлів.
Однак при діленні ваги навпіл виникає проблема, пов'язана з тим, що після виконання цієї операції дерево може змінити свою форму. Пояснюється це тим, що ми ділимо цілі числа і при діленні відкидаємо дробову частину.
Правильно організоване дерево Гаффмана після масштабування може мати форму, яка значно відрізняється від початкової. Це відбувається тому, що масштабування призводить до втрати точності нашої статистики. Але зі збором нової статистики наслідки цих «помилок» практично сходять нанівець. Масштабування ваги — досить дорога операція, оскільки вона призводить до необхідності заново будувати все дерево кодування. Але оскільки необхідність у ній виникає відносно рідко, то з цим можна змиритися.
Виграш від масштабування
Масштабування ваги вузлів дерева через певні інтервали дає несподіваний результат. Незважаючи на те, що при масштабуванні відбувається втрата точності статистики, тести показують, що воно призводить до кращих показників стиснення, ніж якщо б масштабування відкладалося. Це можна пояснити тим, що поточні символи стисненого потоку більше «схожі» на своїх близьких попередників, ніж на тих, які зустрічалися набагато раніше. Масштабування призводить до зменшення впливу «давніх» символів на статистику і до збільшення впливу на неї «недавніх» символів. Це дуже складно виміряти кількісно, але, в принципі, масштабування позитивно впливає на ступінь стиснення інформації. Експерименти з масштабуванням в різних точках процесу стиснення показують, що ступінь стиснення сильно залежить від моменту масштабування ваги, але не існує правила вибору оптимального моменту масштабування для програми, орієнтованої на стиск будь-яких типів інформації.
Застосування
Стиснення даних Гаффмана застосовується під час стиснення фото- і відеозображень (JPEG, стандарти стиснення MPEG), в архіваторах (PKZIP, LZH та інших), в протоколах передачі даних MNP5 і MNP7.
Примітки
- Кормен, Томас; Лейзерсон, Чарльз; Рівест, Рональд; Стайн, Кліфорд (2019). 16.3: Коди Гафмена. Вступ до алгоритмів (вид. 3). К.І.С. с. 443–451. ISBN 978-617-684-239-2.
- Huffman, D. (1952). A Method for the Construction of Minimum-Redundancy Codes. Proceedings of the IRE 40 (9): 1098–1101. doi:10.1109/JRPROC.1952.273898.
Посилання
- Код Гаффмана (WebArchive)
- Візуалізатор побудови дерева для m2=2
- Стиск по алгоритму Гаффмана на algolist.manual.ru