Інформаційна ентропія
Інформаці́йна ентропі́я (англ. information entropy) — це усереднена швидкість, із якою продукує інформацію стохастичне джерело даних.
| Теорія інформації |
|---|
 |
|
|
|
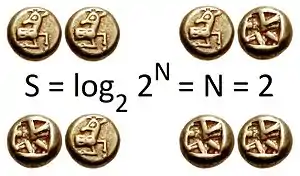
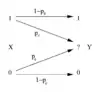
Мірою інформаційної ентропії, пов'язаною з кожним можливим значенням даних, є від'ємний логарифм функції маси ймовірності для цього значення: [1]. Таким чином, коли джерело даних має менш імовірне значення (наприклад, коли стається низькоймовірна подія), то ця подія несе більше «інформації» («неочікуваності»), ніж коли джерело даних має більш імовірне значення. Визначена таким чином кількість інформації, що передається кожною подією, стає випадковою змінною, чиє математичне сподівання є інформаційною ентропією. Взагалі, ентропію позначають безлад або невизначеність, і визначення ентропії, що застосовують в теорії інформації, є прямим аналогом визначення, що застосовують у статистичній термодинаміці. Поняття інформаційної ентропії було введено Клодом Шенноном у його праці 1948 року «Математична теорія зв'язку».[2]

Базова модель системи передавання даних складається з трьох елементів: джерела даних, каналу зв'язку та приймача, і, за виразом Шеннона, «фундаментальною задачею зв'язку» є те, щоби отримувач був здатен встановлювати, які дані було породжено джерелом, на основі сигналу, що він отримує каналом.[3] Ентропія забезпечує абсолютну межу найкоротшої можливої усередненої довжини безвтратного стиснювального кодування даних, продукованих джерелом, і якщо ентропія джерела є меншою за пропускну спроможність каналу зв'язку, то дані, породжувані цим джерелом, можливо надійно передавати приймачеві (принаймні теоретично, можливо, нехтуючи деякими практичними міркуваннями, такими як складність системи, потрібної для передавання даних, або кількості часу, що це передавання цих даних може забирати).
Інформаційну ентропію зазвичай вимірюють в бітах (що також називають «шеннонами», англ. bit, shannon), або іноді в «натуральних одиницях» (натах, англ. nat), або в десяткових цифрах (що називають «дитами», «банами» або «гартлі»). Одиниця вимірювання залежить від основи логарифму, що використовують для визначення ентропії.
Логарифм розподілу ймовірності є корисним як міра ентропії тому, що для незалежних джерел він є адитивним. Наприклад, ентропія підкидання справедливої монети складає 1 біт, а ентропією m підкидань є m біт. У простому поданні, для представлення величини, що може набувати одного з n значень, потрібно log2(n) бітів, якщо n є степенем числа 2. Якщо ці значення є однаково ймовірними, то ентропія (в бітах) дорівнює цьому числу. Якщо ж трапляння одного з цих значень є ймовірнішим за інші, то спостереження трапляння цього значення є менш інформативним, ніж якби трапився не такий звичайний результат. І навпаки, рідкісніші події при їхньому спостереженні надають більше інформації. Оскільки спостереження менш імовірних подій трапляється рідше, в підсумку виходить, що ентропія (при розгляданні її як усередненої інформації), отримувана від нерівномірно розподілених даних, є завжди меншою або рівною до log2(n). Якщо вихід є незмінним, то ентропія дорівнює нулеві. Коли розподіл імовірності джерела даних є відомим, ентропія виражає ці міркування кількісно. Зміст спостережуваних подій (зміст повідомлень) у визначенні ентропії значення не має. Ентропія враховує лише ймовірність спостереження певної події, тому інформація, яку вона включає, є інформацією про розподіл ймовірності, що лежить в основі, а не про зміст самих подій.
Введення
Основною ідеєю теорії інформації є те, що чим більше хтось знає про предмет, то менше нової інформації про нього вони здатні отримати. Якщо подія є дуже ймовірною, то коли вона трапляється, в цьому немає нічого неочікуваного, і відтак вона привносить мало нової інформації. І навпаки, якщо подія була малоймовірною, то її трапляння є набагато інформативнішим. Таким чином, інформаційний вміст є висхідною функцією оберненої ймовірності події (1/p, де p є ймовірністю події). Тепер, якщо може трапитися більше подій, ентропія вимірює усереднений інформаційний вміст, який ви можете очікувати отримати, якщо дійсно трапляється одна з цих подій. З цього випливає, що викидання грального кубика має більше ентропії, ніж підкидання монети, оскільки кожен з результатів грального кубика має меншу ймовірність, ніж кожен з результатів монети.
Отже, ентропія — це міра непередбачуваності (англ. unpredictability) стану, або, рівнозначно, його усередненого інформаційного вмісту (англ. average information content). Щоби отримати інтуїтивне розуміння цих термінів, розгляньмо приклад політичного опитування. Як правило, такі опитування відбуваються тому, що їхні результати не є заздалегідь відомими. Іншими словами, результати опитування є відносно непередбачуваними, і фактичне здійснення опитування та з'ясовування результатів дає деяку нову інформацію; це просто різні способи сказати, що апріорна ентропія результатів опитування є високою. Тепер розгляньмо випадок, коли таке ж опитування проводиться вдруге незабаром після першого опитування. Оскільки результати першого опитування вже є відомими, підсумки другого опитування можна передбачити добре, і ці результати не повинні містити багато нової інформації; в цьому випадку апріорна ентропія результатів другого опитування є низькою по відношенню до апріорної ентропії першого.
Тепер розгляньмо приклад з підкиданням монети. Якщо ймовірність випадання аверсу така ж, як і ймовірність випадання реверсу, то ентропія підкидання монети є настільки високою, наскільки це можливо. Причиною цього є те, що немає жодного способу передбачити результат підкидання монети заздалегідь — якщо нам треба було би обирати, то найкраще, що ми могли би зробити, це передбачити, що монета випаде аверсом догори, і цей прогноз був би правильним з імовірністю 1/2. Таке підкидання монети має один біт ентропії, оскільки є два можливі результати, які трапляються з однаковою ймовірністю, і з'ясування фактичного результату містить один біт інформації. На противагу до цього, підкидання монети, яка має два аверси й жодного реверсу, має нульову ентропію, оскільки монета завжди випадатиме аверсом, і результат може бути передбачено цілком. Аналогічно, бінарна подія з рівноймовірними результатами має ентропію Шеннона біт. Подібно до цього, один трит із рівноймовірними значеннями містить (близько 1.58496) бітів інформації, оскільки він може мати одне з трьох значень.


Англомовний текст, якщо розглядати його як стрічку символів, має досить низький рівень ентропії, тобто, він є доволі передбачуваним. Навіть якщо ми не знаємо точно, що буде далі, ми можемо бути доволі впевненими, що, наприклад, «e» там буде набагато поширенішою за «z», що поєднання «qu» зустрічатиметься набагато частіше за будь-які інші поєднання, які містять «q», і що поєднання «th» буде набагато поширенішим за «z», «q» або «qu». Після перших кількох літер часто можна вгадати решту слова. Англійський текст має між 0.6 та 1.3 біта ентропії на символ повідомлення.[4]
Якщо схема стиснення є вільною від втрат, — тобто, завжди можна відтворити повне первинне повідомлення шляхом розтискання, — то стиснене повідомлення має такий самий обсяг інформації, як і первинне, але переданий меншою кількістю символів. Тобто, воно має більше інформації, або вищу ентропію, на один символ. Це означає, що стиснене повідомлення має меншу надмірність. Грубо кажучи, теорема Шеннона про кодування джерела стверджує, що схема стиснення без втрат в середньому не може стиснути повідомлення так, щоби воно мало більше одного біту інформації на біт повідомлення, але що будь-яке значення менше одного біту інформації на біт повідомлення може бути досягнуто шляхом застосування відповідної схеми кодування. Ентропія повідомлення на біт, помножена на довжину цього повідомлення, є мірою того, наскільки багато інформації в цілому містить повідомлення.
Для наочності уявіть, що ми хочемо передати послідовність, до складу якої входять 4 символи, «А», «Б», «В» і «Г». Таким чином, повідомленням для передавання може бути «АБАГГВАБ». Теорія інформації пропонує спосіб обчислення найменшої можливої кількості інформації, яка передасть це. Якщо всі 4 літери є рівноймовірними (25 %), ми не можемо зробити нічого кращого (над двійковим каналом), аніж кодувати кожну літеру 2 бітами (у двійковому вигляді): «А» може бути кодовано як «00», «Б» — як «01», «В» — як «10», а «Г» — як «11». Тепер припустімо, що «А» трапляється з імовірністю 70 %, «Б» — 26 %, а «В» та «Г» — по 2 % кожна. Ми могли би призначити коди змінної довжини, так, що отримання «1» казало би нам дивитися ще один біт, якщо тільки ми не отримали вже перед цим 2 послідовні біти одиниць. В цьому випадку «А» було би кодовано як «0» (один біт), «Б» — як «10», а «В» і «Г» як «110» і «111». Легко побачити, що протягом 70 % часу потрібно надсилати лише один біт, 26 % часу — два біти, і лише протягом 4 % від часу — 3 біти. Тоді в середньому необхідно менше за 2 біти, оскільки ентропія є нижчою (через високу поширеність «А» з наступною за нею «Б» — разом 96 % символів). Обчислення суми зважених за ймовірностями логарифмічних імовірностей вимірює та схоплює цей ефект.
Теорема Шеннона також означає, що жодна схема стиснення без втрат не може скорочувати всі повідомлення. Якщо якісь повідомлення виходять коротшими, хоча б одне повинне вийти довшим в силу принципу Діріхле. В практичному застосуванні це зазвичай не є проблемою, оскільки нас, як правило, цікавить стиснення лише певних типів повідомлень, наприклад, документів англійською мовою на противагу до тексту тарабарщиною, або цифрових фотографій, а не шуму, і не важливо, якщо алгоритм стиснення робить довшими малоймовірні або нецікаві послідовності.
Означення
Назвавши її на честь Η-теореми Больцмана, Шеннон означив ентропію Η (грецька літера ета) дискретної випадкової величини з можливими значеннями та функцією маси ймовірності як




Тут є оператором математичного сподівання (англ. expectation), а I є кількістю інформації X.[5][6] I(X) і сама є випадковою величиною.

Ентропію може бути записано в явному вигляді як

де b є основою логарифму, який застосовується. Звичними значеннями b є 2, число Ейлера е, та 10, а відповідними одиницями ентропії є біти для b = 2, нати для b = e, та бани для b = 10.[7]
У випадку P(xi) = 0 для деякого i значення відповідного доданку 0 logb(0) приймають рівним 0, що відповідає границі

Можна також визначити умовну ентропію двох подій X та Y, які набувають значень xi та yj відповідно, як

де p(xi, yj) є ймовірністю того, що X = xi та Y = yj. Цю величину слід розуміти як ступінь довільності випадкової величини X при заданій події Y.
Приклад
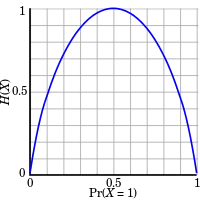
Тут ентропія складає щонайбільше 1 біт, і для повідомлення результатів підкидання монети (2 можливі значення) потрібно в середньому не більше 1 біту (в точності 1 біт для справедливої монети). Результат справедливого грального кубика (6 можливих значень) потребуватиме в середньому log26 бітів.
Детальніші відомості з цієї теми ви можете знайти в статті Функція двійкової ентропії та Процес Бернуллі.
Розгляньмо підкидання монети з відомими, але не обов'язково справедливими ймовірностями випадання аверсу чи реверсу; це можна змоделювати як процес Бернуллі.
Ентропія невідомого результату наступного підкидання монети є найбільшою, якщо монета є справедливою (тобто, якщо як аверси, так і реверси мають однакову ймовірність 1/2). Це є ситуацією максимальної невизначеності, оскільки в ній найскладніше передбачити результат наступного підкидання; результат кожного підкидання монети подає один повний біт інформації. Це є тому, що

Проте, якщо ми знаємо, що монета не є справедливою, а випадає аверсом чи реверсом з імовірностями p та q, де p ≠ q, то тоді невизначеності є менше. Кожного разу, як її підкидають, випадання однієї зі сторін є ймовірнішим, ніж випадання іншої. Зниження невизначеності отримує кількісну оцінку в вигляді меншої ентропії: в середньому кожне підкидання монети подає менше ніж один повний біт інформації. Наприклад, якщо p=0.7, то

Крайнім випадком є двоаверсова монета, яка ніколи не випадає реверсом, або двореверсова монета, яка ніколи не дає в результаті аверс. Тут немає ніякої невизначеності. Ентропія дорівнює нулеві: кожне підкидання монети не подає жодної нової інформації, оскільки результати кожного підкидання монети завжди визначені.
Ентропію може бути нормалізовано шляхом ділення її на довжину інформації. Це співвідношення називається метричною ентропією, воно є мірою хаотичності інформації.
Обґрунтування
Щоби зрозуміти сенс ∑ pi log(1/pi), спершу спробуймо визначити функцію інформації I з точки зору події i з імовірністю pi. Кількість інформації, отримувана через спостереження події i, випливає з шеннонового розв'язку фундаментальних властивостей інформації:[8]
- I(p) є монотонно спадною в p — збільшення ймовірності події зменшує інформацію зі спостереження події, і навпаки.
- I(p) ≥ 0 — інформація є невід'ємною величиною.
- I(1) = 0 — події, які відбуваються завжди, не несуть інформації.
- I(p1 p2) = I(p1) + I(p2) — інформація від незалежних подій є адитивною.
Остання властивість є ключовою. Вона стверджує, що спільна ймовірність незалежних джерел інформації несе стільки ж інформації, скільки й ці дві окремі події по одній. Зокрема, якщо перша подія може видавати один з n рівноймовірних результатів, а інша має один із m рівноймовірних результатів, то існує mn можливих результатів спільної події. Це означає, що якщо для кодування першого значення потрібно log2(n) біт, а для кодування другого — log2(m), то для кодування обох потрібно log2(mn) = log2(m) + log2(n). Шеннон виявив, що правильним вибором функції для кількісної оцінки інформації, яка зберігала би цю адитивність, є логарифмічна, тобто

нехай є інформаційною функцією, що є двічі неперервно диференційовною, тоді


Це диференціальне рівняння веде до розв'язку для будь-якого . Умова 2 веде до , а надто, може обиратися з вигляду , де , що рівнозначне обиранню конкретної основи логарифму. Різні одиниці інформації (біти для двійкового логарифму log2, нати для натурального логарифму ln, бани для десяткового логарифму log10 і так далі) є лише сталим домноженням одна одної. Наприклад, у випадку підкидання справедливої монети аверс дає log2(2) = 1 біт інформації, що становить приблизно 0.693 нат, або 0.301 десяткових цифр. В силу адитивності, n підкидань дають n біт інформації, що становить приблизно 0.693n нат, або 0.301n десяткових цифр.






Якщо існує розподіл, в якому подія i може траплятися з імовірністю pi, з нього було взято N проб, і результат i трапився ni = N pi разів, то загальною кількістю інформації, яку ми отримали, є
- .

Отже, усередненою кількістю інформації, яку ми отримуємо на подію, є

Аспекти
Відношення до термодинамічної ентропії
Детальніші відомості з цієї теми ви можете знайти в статті Ентропія в термодинаміці та теорії інформації.
Натхнення прийняти слово ентропія в теорії інформації виникло від близької подібності між формулою Шеннона, і дуже схожими відомими формулами зі статистичної механіки.
У статистичній термодинаміці найзагальнішою формулою для термодинамічної ентропії S термодинамічної системи є ентропія Ґіббза,

де kB є сталою Больцмана, а pi є ймовірністю мікростану. Ентропію Ґіббза було визначено Віллардом Ґіббзом 1878 року після ранішої праці Больцмана (1872 року).[9]
Ентропія Ґіббза переноситься майже беззмінною до світу квантової фізики, даючи ентропію фон Неймана, введену Джоном фон Нейманом 1927 року,

де ρ є матрицею густини квантової механічної системи, а Tr є слідом.
На побутовому практичному рівні зв'язок між інформаційною та термодинамічною ентропією очевидним не є. Фізики та хіміки схильні більше цікавитися змінами ентропії при спонтанному розвитку системи від її первісних умов, у відповідності з другим законом термодинаміки, ніж незмінним розподілом імовірності. І, як вказує малість сталої Больцмана kB, зміни в S / kB навіть для невеликих кількостей речовин у хімічних та фізичних процесах являють собою обсяги ентропії, які є надзвичайно великими порівняно з чим завгодно в стисненні даних та обробці сигналів. Крім того, в класичній термодинаміці ентропія визначається в термінах макроскопічних вимірювань, і не робить жодних посилань на будь-який розподіл імовірності, що є головним у визначенні ентропії інформаційної.
Зв'язок між термодинамікою і тим, що зараз відомо як теорія інформації, було вперше зроблено Людвігом Больцманом, і виражено його знаменитим рівнянням:

де S є термодинамічною ентропією окремого макростану (визначену термодинамічними параметрами, такими як температура, об'єм, енергія тощо), W є числом мікростанів (різних комбінацій частинок у різних енергетичних станах), які можуть дати даний макростан, а kB є сталою Больцмана. Передбачається, що кожен мікростан є однаково правдоподібним, так що ймовірністю заданого мікростану є pi = 1/W. При підставленні цих імовірностей до наведеного вище виразу для ентропії Ґіббза (або, рівнозначно, ентропії Шеннона, помноженої на kB) в результаті виходить рівняння Больцмана. В термінах теорії інформації інформаційна ентропія системи є кількістю інформації, якої «бракує» для визначення мікростану при відомому макростані.
На думку Джейнса (1957 року), термодинамічну ентропію, як пояснюється статистичною механікою, слід розглядати як застосування теорії інформації Шеннона: термодинамічна ентропія інтерпретується як така, що є пропорційною до кількості додаткової інформації Шеннона, необхідної для визначення детального мікроскопічного стану системи, яка залишається не повідомленою описом виключно в термінах макроскопічних величин класичної термодинаміки, з коефіцієнтом пропорційності, який є просто сталою Больцмана. Наприклад, додавання теплоти до системи підвищує її термодинамічну ентропію, оскільки це збільшує число можливих мікроскопічних станів системи, які узгоджуються з вимірюваними значеннями його макроскопічних величин, роблячи таким чином будь-який повний опис стану довшим. (Див. статтю термодинаміка максимальної ентропії). Демон Максвелла може (гіпотетично) знижувати термодинамічну ентропію системи з використанням інформації про стан окремих молекул, але, як показали Ландауер (з 1961 року) з колегами, щоби діяти, цей демон мусить сам підвищувати термодинамічну ентропію в цьому процесі, принаймні на кількість інформації Шеннона, яку він пропонує спочатку отримати й зберегти; і, таким чином, загальна термодинамічна ентропія не знижується (що розв'язує парадокс). Принцип Ландауера встановлює нижню межу кількості тепла, яке комп'ютер повинен генерувати для обробки заданого обсягу інформації, хоча сучасні комп'ютери є набагато менш ефективними.
Ентропія як кількість інфромації
Детальніші відомості з цієї теми ви можете знайти в статті Теорема Шеннона про кодування джерела.
Ентропія визначається в контексті ймовірнісної моделі. Незалежні підкидання справедливої монети мають ентропію по 1 біту на підкидання. Джерело, яке завжди породжує довгий рядок «Б», має ентропію 0, оскільки наступним символом завжди буде «Б».
Ентропійна швидкість джерела даних означає усереднене число бітів на символ, потрібне для його кодування. Експерименти Шеннона з передбаченням людьми показують швидкість інформації на символ англійською мовою між 0.6 і 1.3 біта;[10] Алгоритм стиснення PPM може досягати рівня стиснення в 1.5 біти на символ англомовного тексту.
Зверніть увагу на наступні моменти з попереднього прикладу:
- Кількість ентропії не завжди є цілим числом бітів.
- Багато бітів даних можуть не нести інформації. Наприклад, структури даних часто зберігають інформацію надмірно, або мають ідентичні розділи, незалежно від інформації в структурі даних.
Шеннонівське визначення ентропії, при застосуванні до джерела інформації, може визначати мінімальну пропускну здатність каналу, необхідну для надійного передавання джерела у вигляді закодованих двійкових цифр (див. застереження нижче курсивом). Цю формулу може бути виведено шляхом обчислення математичного сподівання кількості інформації, яка міститься в одній цифрі з джерела інформації. Див. також теорему Шеннона — Гартлі.
Ентропія Шеннона вимірює інформацію, яка міститься в повідомленні, на противагу до тієї частини повідомлення, яка є визначеною (або передбачуваною). Приклади останнього включають надмірність у структурі мови та статистичні властивості, які стосуються частот трапляння пар, трійок тощо літер або слів. Див. ланцюги Маркова.
Ентропія як міра різноманітності
Ентропія є одним з декількох способів вимірювання різноманітності. Зокрема, ентропія Шеннона є логарифмом 1D, індексу істинної різноманітності з параметром, який дорівнює 1.
Стиснення даних
Ентропія ефективно обмежує продуктивність найсильнішого можливого стиснення без втрат, яке може бути реалізовано теоретично з допомогою типового набору, або практично із застосуванням кодування Хаффмана, Лемпеля — Зіва, або арифметичного кодування. Див. також колмогоровську складність. На практиці для захисту від помилок алгоритми стиснення навмисно включають деяку розумну надмірність у вигляді контрольних сум.
Світовий технологічний потенціал для зберігання та передавання інформації
Дослідження 2011 року в журналі «Science» оцінює світовий технологічний потенціал для зберігання та передавання оптимально стисненої інформації, нормалізований за найефективнішими алгоритмами стиснення, доступними в 2007 році, оцінюючи таким чином ентропію технологічно доступних джерел.[11]
| Тип інформації | 1986 | 2007 |
|---|---|---|
| Зберігання | 2.6 | 295 |
| Широкомовлення | 432 | 1900 |
| Телекомунікації | 0.281 | 65 |
Автори оцінюють технологічний потенціал людства у зберіганні інформації (повністю ентропійно стисненої) 1986 року, і знову 2007 року. Вони ділять інформацію на три категорії — зберігання інформації на носії, отримування інформації через мережі однобічного широкомовлення, та обмін інформацією через двобічні телекомунікаційні мережі.[11]
Обмеження ентропії як кількості інформації
Існує ряд пов'язаних з ентропією понять, які певним чином здійснюють математичну кількісну оцінку обсягу інформації:
- власна інформація окремого повідомлення або символу, взятого із заданого розподілу ймовірності,
- ентропія заданого розподілу ймовірності повідомлень або символів, та
- ентропійна швидкість стохастичного процесу.
(Для конкретної послідовності повідомлень або символів, породженої заданим стохастичним процесом, також може бути визначено «швидкість власної інформації»: у випадку стаціонарного процесу вона завжди дорівнюватиме швидкості ентропії.) Для порівняння різних джерел інформації, або встановлення зв'язку між ними, використовуються й інші Кількості інформації.
Важливо не плутати наведені вище поняття. Яке з них мається на увазі, часто може бути зрозумілим лише з контексту. Наприклад, коли хтось говорить, що «ентропія» англійської мови становить близько 1 біта на символ, вони насправді моделюють англійську мову як стохастичний процес, і говорять про швидкість її ентропії. Шеннон і сам використовував цей термін таким чином.
Проте, якщо ми використовуємо дуже великі блоки, то оцінка посимвольної ентропійної швидкості може стати штучно заниженою. Це відбувається тому, що насправді розподіл ймовірності послідовності не є пізнаваним точно; це лише оцінка. Наприклад, припустімо, що розглядаються тексти всіх будь-коли опублікованих книг як послідовність, у якій кожен символ є текстом цілої книги. Якщо існує N опублікованих книг, і кожну книгу опубліковано лише одного разу, то оцінкою ймовірності кожної книги є 1/N, а ентропією (в бітах) є −log2(1/N) = log2(N). Як практичний код, це відповідає призначенню кожній книзі унікального ідентифікатора і використання його замість тексту книги будь-коли, коли потрібно послатися на цю книгу. Це надзвичайно корисно для розмов про книги, але не дуже корисно для характеризування кількості інформації окремих книг або мови в цілому: неможливо відтворити книгу з її ідентифікатора, не знаючи розподілу ймовірності, тобто повного тексту всіх книг. Ключова ідея полягає в тому, що повинна братися до уваги складність імовірнісної моделі. Колмогоровська складність являє собою теоретичне узагальнення цієї ідеї, яке дозволяє розглядати кількість інформації послідовності незалежно від конкретної ймовірнісної моделі; воно розглядає найкоротшу програму для універсального комп'ютера, яка виводить цю послідовність. Такою програмою є код, який досягає ентропійної швидкості послідовності для заданої моделі, плюс кодовий словник (тобто, ймовірнісна модель), але вона не може бути найкоротшою.
Наприклад, послідовністю Фібоначчі є 1, 1, 2, 3, 5, 8, 13, …. При розгляді цієї послідовності як повідомлення, а кожного числа як символу, існує майже стільки ж символів, скільки є символів у повідомленні, даючи ентропію близько log2(n). Таким чином, перші 128 символів послідовності Фібоначчі мають ентропію приблизно 7 біт/символ. Проте цю послідовність може бути виражено за допомогою формули [F(n) = F(n−1) + F(n−2) для n = 3, 4, 5, …, F(1) =1, F(2) = 1], і ця формула має значно нижчу ентропію, і застосовується до послідовності Фібоначчі будь-якої довжини.
Обмеження ентропії в криптографії
В криптоаналізі ентропію часто грубо використовують як міру непередбачуваності криптографічного ключа, хоча її справжня невизначеність є незмірною. Наприклад, 128-бітовий ключ, який породжено рівномірно випадково, має 128 біт ентропії. Він також вимагає (усереднено) спроб для зламу грубою силою. Проте, ентропія не відображає число потрібних спроб, якщо можливі ключі вибирають не рівномірно.[12][13] Натомість, для вимірювання зусиль, необхідних для атаки грубою силою, можна використовувати міру, що називають здогадом (англ. guesswork).[14]

Через нерівномірність розподілів, що застосовують в криптографії, можуть виникати й інші проблеми. Наприклад, розгляньмо 1 000 000-цифровий двійковий шифр Вернама із застосуванням виключного «або». Якщо цей шифр має 1 000 000 біт ентропії, це чудово. Якщо цей шифр має 999 999 біт ентропії, які розподілено рівномірно (коли кожен окремий біт шифру має 0.999999 біт ентропії), то він може пропонувати добру безпеку. Але якщо якщо цей шифр має 999 999 біт ентропії, так, що перший біт є незмінним, а решта 999 999 бітів вибирають випадково, то перший біт шифрованого тексту не буде шифровано взагалі.
Дані як марковський процес
Звичний спосіб визначення ентропії для тексту ґрунтується на марковській моделі тексту. Для джерела нульового порядку (кожен символ обирається незалежно від останніх символів) двійковою ентропією є

де pi є ймовірністю i. Для марковського джерела першого порядку (такого, в якому ймовірність вибору символу залежить лише від безпосередньо попереднього символу) ентропійною швидкістю є
- [джерело?]

де i є станом (деякими попередніми символами), а є ймовірністю j за заданого попереднього символу i.

Для марковського джерела другого порядку ентропійною швидкістю є

b-арна ентропія
В загальному випадку b-арна ентропія джерела = (S, P) з первинною абеткою S = {a1, …, an} і дискретним розподілом ймовірності P = {p1, …, pn}, де pi є імовірністю ai (скажімо, pi = p(ai)), визначається як


Зауваження: b у «b-арній ентропії» є числом різних символів ідеальної абетки, яка використовується як стандартне мірило для вимірювання первинних абеток. В теорії інформації для абетки для кодування інформації є необхідними і достатніми два символи. Тому стандартним є брати b = 2 («двійкова ентропія»). Таким чином, ентропія первинної абетки, з її заданим емпіричним розподілом імовірності, — це число, яке дорівнює числу (можливо дробовому) символів «ідеальної абетки», з оптимальним розподілом імовірності, необхідних для кодування кожного символу первинної абетки. Також зверніть увагу, що «оптимальний розподіл імовірності» тут означає рівномірний розподіл: первинна абетка з n символів має найвищу можливу ентропію (для абетки з n символів), коли розподіл імовірності абетки є рівномірним. Цією оптимальною ентропією виявляється logb(n).
Ефективність
Первинна абетка з нерівномірним розподілом матиме меншу ентропію, ніж якби ці символи мали рівномірний розподіл (тобто, були «оптимальною абеткою»). Цю дефективність ентропії може бути виражено відношенням, яке називається ефективністю:
- [прояснити]

Ефективність є корисною для кількісної оцінки ефективності використання каналу зв'язку. Це формулювання також називають нормалізованою ентропією, оскільки ентропія ділиться на максимальну ентропію . Крім того, ефективності байдужий вибір (додатної) бази b, про що свідчить нечутливість до неї в кінцевому логарифмі.

Характеризування
Ентропія Шеннона характеризується невеликим числом критеріїв, перерахованих нижче. Будь-яке визначення ентропії, яке задовольняє ці припущення, має вигляд

де K є сталою, яка відповідає виборові одиниць вимірювання.
Далі pi = Pr(X = xi), а Ηn(p1, …, pn) = Η(X).
Неперервність
Ця міра повинна бути неперервною, так що зміна значень ймовірностей на дуже незначну величину повинна змінювати ентропію лише на незначну величину.
Симетричність
При перевпорядкуванні виходів xi ця міра повинна залишатися незмінною.
- тощо

Максимум
Ця міра повинна бути максимальною тоді, коли всі виходи є однаково правдоподібними (невизначеність є найвищою, коли всі можливі події є рівноймовірними).

Для рівноймовірних подій ентропія повинна зростати зі збільшенням числа виходів.

Для безперервних випадкових змінних розподілом із максимальною диференціальною ентропією є багатовимірний нормальний розподіл.
Адитивність
Величина ентропії повинна не залежати від того, який поділ процесу на частини розглядається.
Ця остання функційна залежність характеризує ентропію системи з підсистемами. Вона вимагає, щоби ентропію системи можливо було обчислити з ентропій її підсистем, якщо взаємодії між цими підсистемами є відомими.
При заданому ансамблі n рівномірно розподілених елементів, які поділяються на k блоків (підсистем) з b1, ..., bk елементами в кожному, ентропія всього ансамблю повинна дорівнювати сумі ентропії системи блоків і окремих ентропій блоків, кожна з яких є зваженою на ймовірність знаходження в цьому відповідному блоці.
Для додатних цілих чисел bi, де b1 + … + bk = n,

При обранні k = n, b1 = … = bn = 1 це означає, що ентропія незмінного виходу дорівнює нулеві: Η1(1) = 0. Це означає, що ефективність первинної абетки з n символами може бути визначено просто як таку, що дорівнює її n-арній ентропії. Див. також надмірність інформації.
Додаткові властивості
Ентропія Шеннона задовольняє наступні властивості, для деяких з яких корисно інтерпретувати ентропію як кількість пізнаної інформації (або усуненої невизначеності) при розкритті значення випадкової величини X:
- Додавання або усування подій з нульовою ймовірністю не впливає на ентропію:
- .

- Ентропія дискретної випадкової змінної є невід'ємним числом:
- .[15]

- За допомогою нерівності Єнсена може бути підтверджено, що
- .[15]

- Ця максимальна ентропія logb(n) ефективно досягається первинною абеткою, яка має рівномірний розподіл ймовірності: невизначеність є максимальною, коли всі можливі події є однаково ймовірними.
- Ентропія, або обсяг інформації, розкритої шляхом визначення (X,Y) (тобто визначення X та Y одночасно) дорівнює інформації, розкритої шляхом проведення двох послідовних експериментів: спершу виявлення значення Y, а потім виявлення значення X, за умови, що ви знаєте значення Y. Це може бути записано як

- Якщо , де є функцією, то . Застосування попередньої формули до дає





- отже, , таким чином, ентропія величини може тільки зменшуватися, коли остання проходить через функцію.

- Якщо X та Y в є двома незалежними випадковими змінними, то знання значення Y не впливає на наше знання про значення X (оскільки ці двоє не впливають одне на одне в силу незалежності):

- Ентропія двох одночасних подій є не більшою за суму ентропій кожної з окремих подій, і дорівнює їй, якщо ці дві події є незалежними. Точніше, якщо X та Y є двома випадковими величинами на одному й тому ж імовірнісному просторі, а (X, Y) позначає їхній декартів добуток, то

- Ентропія є угнутою за функцією маси ймовірності , тобто,



- для всіх функцій маси ймовірності та .[15]


Розширення дискретної ентропії до неперервного випадку
Диференціальна ентропія
Ентропію Шеннона обмежено випадковими величинами, які набувають дискретних значень. Відповідна формула для неперервної випадкової величини з функцією густини ймовірності f(x) зі скінченною або нескінченною областю визначення на дійсній осі визначається аналогічно, з допомогою наведеного вище вираження ентропії як математичного сподівання:


Цю формулу зазвичай називають непере́рвною ентропі́єю (англ. continuous entropy), або диференціальною ентропією. Попередником неперервної ентропії h[f] є вираз функціоналу Η в Η-теоремі Больцмана.
Хоча аналогія між обома функціями й наводить на роздуми, мусить бути поставлено наступне питання: чи є диференціальна ентропія обґрунтованим розширенням дискретної ентропії Шеннона? Диференціальній ентропії бракує ряду властивостей, якими володіє дискретна ентропія Шеннона, — вона навіть може бути від'ємною, — і відтак було запропоновано поправки, зокрема, взяття границі щільності дискретних точок.
Щоби відповісти на це питання, ми мусимо встановити зв'язок між цими двома функціями:
Ми хочемо отримати загальну скінченну міру при прямуванні розміру засіків до нуля. В дискретному випадку розмір засіків є (неявною) шириною кожного з n (скінченних або нескінченних) засіків, чиї ймовірності позначаються через pn. Оскільки ми робимо узагальнення до неперервної області визначення, ми мусимо зробити цю ширину явною.
Щоби зробити це, почнімо з неперервної функції f, дискретизованої засіками розміру . Згідно теореми про середнє значення, в кожному засіку існує таке значення xi, що


і відтак інтеграл функції f може бути наближено (в рімановому сенсі) за допомогою

де ця границя і «розмір засіку прямує до нуля» є рівноцінними.
Позначмо

і, розкриваючи цього логарифма, ми маємо

При Δ → 0 ми маємо

Але зауважте, що log(Δ) → −∞ при Δ → 0, отже, нам потрібне особливе визначення диференціалу або неперервної ентропії:

що, як було сказано раніше, називають диференціа́льною ентропі́єю (англ. differential entropy). Це означає, що диференціальна ентропія не є границею ентропії Шеннона при n → ∞. Вона радше відрізняється від границі ентропії Шеннона нескінченним зсувом (див. також статтю про інформаційну розмірність).
Взяття границі щільності дискретних точок
Детальніші відомості з цієї теми ви можете знайти в статті Взяття границі щільності дискретних точок.
В результаті виходить, що, на відміну від ентропії Шеннона, диференціальна ентропія не є в цілому доброю мірою невизначеності або інформації. Наприклад, диференціальна ентропія може бути від'ємною; крім того, вона не є інваріантною відносно неперервних перетворень координат. Цю проблему може бути проілюстровано зміною одиниць вимірювання, коли x є розмірною величиною. f(x) тоді матиме одиниці 1/x. Аргумент логарифму мусить бути безрозмірним, інакше він є неправильним, бо така диференціальна ентропія, як наведено вище, буде неправильною. Якщо є деяким «стандартним» значенням x (тобто, «розміром засіку»), і відтак має такі ж одиниці вимірювання, то видозмінену диференціальну ентропію може бути записано в належному вигляді як

і результат буде однаковим при будь-якому виборі одиниць вимірювання для x. Насправді границя дискретної ентропії при N → 0 включала би також і член log(N), який в загальному випадку був би нескінченним. Це є очікуваним, неперервні величини при дискретизації зазвичай матимуть нескінченну ентропію. Взяття границі щільності дискретних точок в дійсності є мірою того, наскільки розподіл є простішим для опису за розподіл, який є рівномірним над своєю схемою квантування.
Відносна ентропія
Детальніші відомості з цієї теми ви можете знайти в статті Узагальнена відносна ентропія.
Іншою корисною мірою ентропії, яка однаково добре працює в дискретному та неперервному випадках, є відно́сна ентропі́я (англ. relative entropy) розподілу. Вона визначається як відстань Кульбака — Лейблера від розподілу до еталонної міри m наступним чином. Припустімо, що розподіл імовірності p є абсолютно неперервним відносно міри m, тобто має вигляд p(dx) = f(x)m(dx) для деякої невід'ємної m-інтегрованої функції f з m-інтегралом 1, тоді відносну ентропію може бути визначено як

В такому вигляді відносна ентропія узагальнює (з точністю до зміни знака) як дискретну ентропію, коли міра m є лічильною мірою, так і диференціальну ентропію, коли міра m є мірою Лебега. Якщо міра m і сама є розподілом ймовірності, то відносна ентропія є невід'ємною, і нульовою, якщо p = m як міри. Вона визначається для будь-якого простору мір, отже, не залежить від координат, і є інваріантною відносно перепараметризації координат, якщо перетворення міри m береться до уваги правильно. Відносна ентропія, і неявно ентропія та диференціальна ентропія, залежать від «базової» міри m.
Застосування в комбінаториці
Ентропія стала корисною величиною в комбінаториці.
Нерівність Люміса — Уїтні
Простим прикладом цього є альтернативне доведення нерівності Люміса — Вітні: для будь-якої підмножини A ⊆ Zd ми маємо

де Pi є ортогональною проекцією в i-й координаті:

Це доведеня випливає як простий наслідок нерівності Ширера: якщо X1, …, Xd є випадковими величинами, а S1, …, Sn є підмножинами {1, …, d}, такими, що кожне ціле число між 1 і d лежить точно в r з цих підмножин, то

де є декартовим добутком випадкових величин Xj з індексами j в Si (тому розмірність цього вектора дорівнює розмірові Si).

Ми зробимо нарис, як з цього випливає Люміс — Уїтні: справді, нехай X є рівномірно розподіленою випадковою величиною зі значеннями в A, і такою, що кожна точка з A трапляється з однаковою ймовірністю. Тоді (згідно додаткових властивостей ентропії, згадуваних вище) Η(X) = log|A|, де |A| позначає потужність A. Нехай Si = {1, 2, …, i−1, i+1, …, d}. Діапазон міститься в Pi(A) і, отже, . Тепер застосуймо це, щоби обмежити праву частину нерівності Ширера, і піднести до степеня протилежні частини нерівності, яку ви отримали в результаті.

Наближення до біноміального коефіцієнту
Для цілих чисел 0 < k < n покладімо q = k/n. Тоді

де

Нижче наведено схематичне доведення. Зауважте, що є одним із членів суми


Відповідно, з нерівності після логарифмування отримується верхня межа.

Для отримання нижньої межі спочатку шляхом певних перетворень показується, що доданок є найбільшим членом у наведеній сумі. Але тоді

оскільки біном містить n + 1 членів. Звідси випливає нижня межа.
Наведені результати інтерпретуються, наприклад, таким чином: число двійкових стрічок довжини n, які містять рівно k одиниць, можна оцінити як .[17]

Див. також
- Взаємна інформація
- Випадковість
- Відстань Геммінга
- Відстань Левенштейна
- Геометрія інформації
- Ентропійна швидкість
- Ентропійне кодування — схема кодування, яка призначає коди символам таким чином, щоби довжини кодів відповідали ймовірностям символів
- Ентропія (вісь часу)
- Ентропія графа
- Ентропія Колмогорова — Синая в динамічних системах
- Ентропія Реньї — узагальнення ентропії Шеннона; вона є однією з сімейства функціоналів для кількісної оцінки різноманіття, невизначеності або випадковості системи.
- Ентропія Цалліса
- Індекс різноманітності — альтернативні підходи до кількісної оцінки різноманітності в розподілі ймовірності
- Індекс Тейла
- Індекс Шеннона
- Інформація за Фішером
- Історія ентропії
- Історія теорії інформації
- Квантова відносна ентропія — міра розрізнюваності між двома квантовими станами
- Множник Лагранжа
- Негентропія
- Нерівність ентропійної потужності
- Типоглікемія
- Оцінка ентропії
- Перехресна ентропія — є мірою усередненого числа бітів, необхідних для ідентифікації події з набору можливостей між двома розподілами ймовірності
- Перплексивність
- Спільна ентропія — це міра того, як багато ентропії міститься в спільній системі з двох випадкових величин.
- Умовна ентропія
- Якісна варіативність — інші міри статистичної дисперсії для номінальних розподілів
Примітки
- Pathria, R. K.; Beale, Paul (2011). Statistical Mechanics (Third Edition). Academic Press. с. 51. ISBN 978-0123821881. (англ.)
- Shannon, Claude E. (July–October 1948). A Mathematical Theory of Communication. Bell System Technical Journal 27 (3): 379–423. doi:10.1002/j.1538-7305.1948.tb01338.x. (PDF, заархівовано звідси) (англ.)
- Shannon, Claude E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal 27., July and October (англ.)
- Schneier, B: Applied Cryptography, Second edition, John Wiley and Sons. (англ.)
- Borda, Monica (2011). Fundamentals in Information Theory and Coding. Springer. ISBN 978-3-642-20346-6. (англ.)
- Han, Te Sun & Kobayashi, Kingo (2002). Mathematics of Information and Coding. American Mathematical Society. ISBN 978-0-8218-4256-0. (англ.)
- Schneider, T.D, Information theory primer with an appendix on logarithms, National Cancer Institute, 14 April 2007. (англ.)
- Carter, Tom (March 2014). An introduction to information theory and entropy. Santa Fe. Процитовано 4 серпня 2017. (англ.)
- Compare: Boltzmann, Ludwig (1896, 1898). Vorlesungen über Gastheorie : 2 Volumes – Leipzig 1895/98 UB: O 5262-6. English version: Lectures on gas theory. Translated by Stephen G. Brush (1964) Berkeley: University of California Press; (1995) New York: Dover ISBN 0-486-68455-5 (англ.)
- Mark Nelson (24 серпня 2006). The Hutter Prize. Процитовано 27 листопада 2008. (англ.)
- "The World's Technological Capacity to Store, Communicate, and Compute Information", Martin Hilbert and Priscila López (2011), Science, 332(6025); free access to the article through here: martinhilbert.net/WorldInfoCapacity.html (англ.)
- Massey, James (1994). Guessing and Entropy. Proc. IEEE International Symposium on Information Theory. Процитовано 31 грудня 2013. (англ.)
- Malone, David; Sullivan, Wayne (2005). Guesswork is not a Substitute for Entropy. Proceedings of the Information Technology & Telecommunications Conference. Процитовано 31 грудня 2013. (англ.)
- Pliam, John (1999). Guesswork and variation distance as measures of cipher security. International Workshop on Selected Areas in Cryptography. doi:10.1007/3-540-46513-8_5. (англ.)
- Thomas M. Cover; Joy A. Thomas (18 липня 2006). Elements of Information Theory. Hoboken, New Jersey: Wiley. ISBN 978-0-471-24195-9. (англ.)
- Aoki, New Approaches to Macroeconomic Modeling. (англ.)
- Probability and Computing, M. Mitzenmacher and E. Upfal, Cambridge University Press (англ.)
Література
Підручники з теорії інформації
- Теорія інформації і кодування: навч. посіб. / А. Я. Кулик, С. Г. Кривогубченко; Вінниц. нац. техн. ун-т. — Вінниця, 2008. — 145 c.
- Теорія інформації: навч. посіб. / Н. О. Тулякова; Сум. держ. ун-т. — Суми, 2008. — 212 c.
- Теорія інформації: навч. посіб. / В. В. Дядичев, Б. М. Локотош, А. В. Колєсніков; Східноукр. нац. ун-т ім. В. Даля. — Луганськ, 2009. — 249 c.
- Теорія інформації та кодування / В. С. Василенко, О. Я. Матов; НАН України, Ін-т пробл. реєстрації інформації. — Київ : ІПРІ НАН України, 2014. — 439 c.
- Теорія інформації та кодування: підручник / В. І. Барсов, В. А. Краснобаєв, З. В. Барсова, О. І. Тиртишніков, І. В. Авдєєв; ред.: В. І. Барсов; МОНМС України, Укр. інж.-пед. акад., Полтав. нац. техн. ун-т ім. Ю. Кондратюка. — Полтава, 2011. — 321 c.
- Теорія інформації та кодування: Підруч. для студ. вищ. техн. навч. закл. / Ю. П. Жураковський, В. П. Полторак. — К. : «Вища шк.», 2001. — 255 c.
- Arndt, C. (2004), Information Measures: Information and its Description in Science and Engineering, Springer, ISBN 978-3-540-40855-0 (англ.)
- Cover, T. M., Thomas, J. A. (2006), Elements of information theory, 2nd Edition. Wiley-Interscience. ISBN 0-471-24195-4. (англ.)
- Gray, R. M. (2011), Entropy and Information Theory, Springer. (англ.)
- MacKay, David J. C.. Information Theory, Inference, and Learning Algorithms Cambridge: Cambridge University Press, 2003. ISBN 0-521-64298-1 (англ.)
- Martin, Nathaniel F.G. & England, James W. (2011). Mathematical Theory of Entropy. Cambridge University Press. ISBN 978-0-521-17738-2. (англ.)
- Мартин Н., Ингленд Дж. Математическая теория энтропии. — М. : Мир, 1988. — 350 с. (рос.)
- Shannon, C.E., Weaver, W. (1949) The Mathematical Theory of Communication, Univ of Illinois Press. ISBN 0-252-72548-4 (англ.)
- Stone, J. V. (2014), Chapter 1 of Information Theory: A Tutorial Introduction, University of Sheffield, England. ISBN 978-0956372857. (англ.)
- Хэмминг Р. В. (1983). Теория информации и теория кодирования. Москва: Радио и Связь. (рос.)
Посилання
- Hazewinkel, Michiel, ред. (2001). Entropy. Encyclopedia of Mathematics. Springer. ISBN 978-1-55608-010-4. (англ.)
- Введення в ентропію та інформацію на Principia Cybernetica Web (англ.)
- Entropy, міждисциплінарний журнал про всі аспекти поняття ентропії. Відкритий доступ. (англ.)
- Опис інформаційної ентропії з «Tools for Thought» Говарда Райнгольда (англ.)
- Аплет Java, який представляє експеримент Шеннона з обчислення ентропії англійської мови
- Слайди про приріст інформації та ентропію (англ.)
- An Intuitive Guide to the Concept of Entropy Arising in Various Sectors of Science — вікікнига про інтерпретацію поняття ентропії. (англ.)
- Network Event Detection With Entropy Measures, Dr. Raimund Eimann, University of Auckland, PDF; 5993 kB — докторська праця, яка демонструє, як вимірювання ентропії можуть застосовуватися для виявлення мережевих аномалій. (англ.)
- Entropy — репозитарій Rosetta Code реалізацій ентропії Шеннона різними мовами програмування.
- "Information Theory for Intelligent People". Коротке введення до аксіом теорії інформації, ентропії, взаємної інформації, відстані Кульбака — Лейблера та відстані Єнсена — Шеннона. (англ.)
- Інтерактивний інструмент для обчислення ентропії (простого тексту ASCII)
- Інтерактивний інструмент для обчислення ентропії (двійкового входу)
