Метааналіз
Метааналіз — статистичний аналіз, який поєднує результати багатьох наукових досліджень. Метааналіз може бути виконаний, коли існує кілька наукових досліджень, що стосуються одного і того ж питання у кожному окремому дослідженні, і описані результати дослідження, які, як очікується, мають певний ступінь помилки. Метою цього є використання статистичних підходів для отримання об'єднаної оцінки, найближчої до невідомої загальної істини, заснованої на тому, як сприймається ця помилка.
Існуючі методи метааналізу дають середньозважену оцінку від результатів окремих досліджень, і відрізняються способом розподілу цих ваг, а також способом, яким обчислюється невизначеність навколо створеної таким чином оцінки. На додаток до оцінки невідомої загальної істини, метааналіз має здатність протиставляти результати різних досліджень та визначати закономірності між результатами дослідження, джерела розбіжностей між цими результатами чи інші цікаві взаємозв'язки, які можуть з'явитися у контексті кількох досліджень.[1]
Ключовою перевагою такого підходу є агрегування інформації, що призводить до вищої статистичної потужності та більш надійної оцінку, ніж це можливо за результатами будь-якого окремого дослідження. Однак, виконуючи метааналіз, дослідник вимушений робити вибір, який може вплинути на результати, включаючи рішення про пошук досліджень, підбір досліджень на основі набору об'єктивних критеріїв, розгляд неповних даних, аналіз даних та врахування або неврахування упередженності публікації.[2] Судження, зроблені при виконанні мета-аналізу, можуть вплинути на результати. Наприклад, Ванус та його колеги вивчили чотири пари метааналізів на чотири теми (а) взаємозв'язок між виконанням роботи та задоволенням, (б) реалістичні попередні перегляди роботи, (в) співвідношення конфлікту ролей та неоднозначності та (г) завдання взаємозв'язку задоволення та прогулів, і проілюструвало, як різні виклики суджень, зроблені дослідниками, давали різні результати.[3]
Метааналізи часто, але не завжди, є важливими складовими процедури систематичного огляду. Наприклад, метааналіз може бути проведений на кількох клінічних випробуваннях медикаментозного лікування, щоб досягти кращого розуміння того, наскільки добре працює лікування. Тут зручно дотримуватися термінології, що використовується Кокранівською співпрацею,[4] і використовувати «метааналіз» для позначення статистичних методів поєднання доказів, залишаючи інші аспекти «синтезу дослідження» або «синтезу доказів», таких як поєднання інформації з якісних досліджень, для більш загального контексту систематичних оглядів . Метааналіз — це вторинне джерело.[5][6]
Історія
Історичні корені метааналізу можна простежити до досліджень астрономії 17 століття,[7] в той час як стаття, опублікована в 1904 р. у «Британському медичному журналі» статистиком Карлом Пірсоном[8] який зібрав дані декількох досліджень тифозного щеплення, розглядається як перший раз, коли мета-аналітичний підхід був використаний для узагальнення результатів багатьох клінічних досліджень.[9][10] Перший метааналіз всіх концептуально однакових експериментів, що стосуються певного дослідження, і проведений незалежними дослідниками, був визначений як книжка, що випускається в 1940 році, «Екстрасенсорне сприйняття після шістдесяти років» ", авторами є психологи університету Дюка Дж. Г. Пратт, Джозеф . Б. Рейн та ін.[11] Це охопило огляд 145 доповідей про експериментів з екстрасенсорне сприйняття, опублікованих з 1882 по 1939 рік, і включило оцінку впливу неопублікованих праць на загальний ефект (роблема вилучених файлів). Хоча метааналіз широко застосовується в епідеміології та доказовій медицині, метааналіз медикаментозного лікування не був опублікований до 1955 року. У 1970-х більш складні аналітичні методи вмкористовувались у освітніх дослідженнях починаючи з робіт Гена В. Гласса, Франка Л. Шмідта та Дж. Е. Хантера.
Термін «метааналіз» був введений у 1976 році статистиком Гене В. Глассом,[12] хто заявив «моє головне зацікавлення в даний час полягає в тому, що ми почали називати … метааналіз досліджень. Термін трохи грандіозний, але він точний і вдалий … Мета-аналіз відноситься до аналізу аналізів». Хоча це призвело до того, що він був визнаний сучасним засновником методу, методологія, яку він назвав «метааналізом», передувала його роботі протягом кількох десятиліть.[13][14] Статистична теорія, що стосується мета-аналізу, була сильно просунута роботами Намбері С. Раджу, Ларрі В. Хеджесом, Харрісом Купером, Інграм Олкін, Джон Е. Хантер, Jacob Cohen, Thomas C. Chalmers, Robert Rosenthal, Frank L. Schmidt та Дугласом Г. Бонеттом.
Етапи мета-аналізу
Метааналізу зазвичай передує систематичний огляд, оскільки це дозволяє ідентифікувати та критично оцінити всі відповідні докази (тим самим обмежуючи ризик упередженості у підсумкових оцінках). Загальні кроки наступні:
- Формулювання дослідницького питання, напр. з використанням моделі PICO (Population, Intervention, Comparison, Outcome — Популяція, Вплив, Порівняння, Результати).
- Пошук літератури
- Вибір досліджень («критерії включення»)
- На основі критеріїв якості, наприклад вимога рандомізації та осліплення в клінічному випробуванні
- Вибір конкретних досліджень на щодо визначеного предмету, напр. лікування раку молочної залози.
- Рішення, чи включати неопубліковані дослідження, щоб уникнути упередженості публікацій (проблема з вилученням файлів)
- Вирішити, які залежні змінні чи підсумкові заходи дозволені. Наприклад, при розгляді мета-аналізу опублікованих (агрегованих) даних:
- Відмінності (дискретні дані)
- Засоби (безперервні дані)
- Хеджи g — популярна підсумкова величина для безперервних даних, яка стандартизується з метою усунення різниць масштабу, але він включає індекс зміни між групами:
- у якій є середнім значенням для лікуванням, — середнє значення контрольної групи, об'єднана дисперсія.
- Вибір моделі метааналізу, напр. метааналіз з фіксованим ефектом або випадковими ефектами.
- Вивчіть джерела гетерогенності між дослідженнями, наприклад за допомогою аналізу підгруп або метарегресії. Формальні вказівки щодо проведення та звітування про метааналізи надаються Посібником з Кокрана.




Методи та припущення
Підходи
Загалом при проведенні метааналізу можна виділити два типи доказів: індивідуальні дані учасника (ІДЧ) та агреговані дані (АД). Агреговані дані можуть бути прямими або непрямими.
АД частіше доступні (наприклад, з літератури) і, як правило, представляють зведені оцінки, такі як відношення переваги або відносний ризик. Це можна безпосередньо синтезувати в рамках концептуально подібних досліджень, використовуючи декілька підходів (див. нижче). З іншого боку, непрямі агреговані дані вимірюють дію двох методів лікування, які порівнювались проти аналогічної контрольної групи в метааналізі. Наприклад, якщо лікування A і лікування B безпосередньо порівнювались з плацебо в окремих мета-аналізах, ми можемо використовувати ці два об'єднані результати, щоб отримати оцінку ефектів від A проти B у непрямому порівнянні як ефект A проти плацебо мінус ефект B проти плацебо.
Докази ІДЧ представляють необроблені дані, зібрані дослідними центрами. Ця відмінність викликала потребу в різних метааналітичних методах, коли потрібен синтез доказів, і призвела до розробки одноетапних та двоступеневих методів.[15] Одноетапними методами ІДЧ усіх досліджень моделюються одночасно, враховуючи групування учасників в рамках досліджень. Двоетапні методи спочатку обчислюють підсумкову статистику для АД з кожного дослідження, а потім обчислюють загальну статистику як середньозважену статистику дослідження. За рахунок зведення ІДЧ до АД, двоступеневі методи також можуть застосовуватися, коли доступний ІДЧ; це робить їх привабливим вибором при виконанні метааналізу. Хоча загальноприйнято вважати, що одноетапні та двоступеневі методи дають подібні результати, останні дослідження показали, що вони можуть іноді призводити до різних висновків.[16][17]
Модель з фіксованими ефектами
Модель з фіксованими ефектами забезпечує середньозважене значення з серії оцініваних досліджень. Зворотна дисперсія оцінок зазвичай використовується як вага дослідження, так що більші дослідження мають тенденцію до більшого внеску до середньозваженого ніж менші дослідження. Отже, коли в дослідженнях мета-аналізу переважає дуже велике дослідження, результати менших досліджень практично ігноруються.[18] Найголовніше, що модель фіксованих ефектів передбачає, що всі включені дослідження досліджують одну і ту ж сукупність, використовують однакові визначення змінних та результатів тощо. Це припущення, як правило, нереальне, оскільки дослідження часто схильні до декількох джерел неоднорідності; напр. ефекти лікування можуть відрізнятися залежно від місцевості, рівнів дозування, умов дослідження, …
Модель випадкових ефектів
Загальна модель, яка використовується для синтезу гетерогенних досліджень, — це метааналіз випадкових ефектів. Це просто середньозважена середня величина ефекту групи досліджень. Вага, що застосовується в цьому процесі зваженого усереднення з метааналізом випадкових ефектів, досягається в два етапи:[19]
- Крок 1: Зважування зворотної дисперсії
- Крок 2: Розважування цього зважування на основі зворотної дисперсії шляхом застосування компонента дисперсії випадкових ефектів (КДВП), який просто виводиться зі ступеня мінливості розмірів ефекту в базових дослідженнях.
Це означає, що чим більша ця мінливість розмірів ефектів (інакше відома як неоднорідність), тим більше розважування, і можна досягти точки, коли результат метааналізу випадкових ефектів стає просто незваженим середнім розміром ефекту в ході досліджень. З іншого боку, коли всі розміри ефектів схожі (або мінливість не перевищує помилку вибірки), не застосовується КДВП, а метааналіз випадкових ефектів зводиться до метааналізу з фіксованими ефектами (лише зі зважуванням зворотньої дисперсії).
Ступінь цього зведення залежить виключно від двох факторів:[20]
- Неоднорідність точності
- Неоднорідність розміру ефекту
Оскільки жоден із цих факторів автоматично не вказує на помилкове масштабне дослідження або більш надійні менші дослідження, перерозподіл ваг за цією моделлю не матиме відношення до того, що ці дослідження можуть запропонувати насправді. Дійсно, було продемонстровано, що перерозподіл ваг є просто в одному напрямку від більших до менших досліджень, оскільки гетерогенність збільшується, поки в кінцевому підсумку всі дослідження не мають однакової ваги і подальший перерозподіл неможливий.[20] Інша проблема моделі випадкових ефектів полягає в тому, що найчастіше використовувані довірчі інтервали, як правило, не зберігають ймовірності їх покриття вище зазначеного номінального рівня і, таким чином, істотно занижують статистичну помилку і, можливо, завищують переконаність у своїх висновках.[21][22] Запропоновано кілька виправлень[23][24] але дебати тривають далі.[22][25] Наступне занепокоєння полягає в тому, що середній ефект лікування іноді може бути навіть менш консервативним порівняно з моделлю з фіксованим ефектом[26] і тому вводить в оману на практиці. Одне з запропонованих інтерпретаційних виправлень полягає у створенні інтервалу прогнозування навколо оцінки випадкових ефектів для відображення діапазону можливих ефектів на практиці.[27] Однак припущення при обчисленні такого інтервалу прогнозування полягає в тому, що випробування вважаються більш-менш однорідними суб'єктами, що включають популяції пацієнтів та порівняльне лікування, слід вважати взаємозамінними[28] і це, як правило, недосяжно на практиці.
Найбільш широко застосовуваний метод для оцінки між дисперсією досліджень (КДВП) — це підхід DerSimonian-Laird (DL).[29] Існує кілька вдосконалених ітеративних (і обчислювально дорогих) методів обчислення різниці між дослідженнями (такі як максимальна ймовірність, імовірність профілю та обмежена максимальна ймовірність методів) та моделями випадкових ефектів за допомогою цих методів можна запустити в Stata за допомогою команди metaan.[30] Команду metaan слід відрізняти від класичної команди metan (одиночна «a») в Stata, яка використовує оцінювач DL. Ці вдосконалені методи також були реалізовані у вільному та простому у використанні додатку Microsoft Excel, MetaEasy.[31][32] Однак порівняння між цими передовими методами та методом DL для обчислення дисперсії між дослідженнями показало, що виграш малий, а DL у більшості сценаріїв цілком адекватний.[33][34]
Однак більшість мета-аналізів включає в себе від 2 до 4 досліджень, і такий зразок частіше за все є недостатнім для точної оцінки гетерогенності. Таким чином, виявляється, що в невеликих метааналізах виходить некоректний нуль між оцінкою дисперсії дослідження, що призводить до помилкового припущення про однорідність. В цілому, виявляється, що гетерогенність постійно недооцінюється в мета-аналізах та аналізах чутливості, в яких передбачається, що високі рівні гетерогенності можуть бути інформативними.[35] Ці зразки випадкових ефектів та програмні пакети, згадані вище, стосуються мета-аналізів, що сукупні з дослідженнями, і дослідникам, які бажають проводити індивідуальні метааналізи даних про пацієнтів (ІПД), необхідно враховувати підходи моделювання змішаних ефектів.[36]
Модель зворотньої дисперсії неоднорідності (IVhet)
Doi & Barendregt, працюючи у співпраці з Ханом, Талібом та Вільямсом (з Університету Квінсленда, Університету Південного Квінсленду та Кувейтського університету), створили для моделі випадкових ефектів (RE) альтернативу, засновано на квазиімовірності на основі зворотньої дисперсії, подробиці для якої доступні в Інтернеті.[37] Вона була включена до MetaXL версії 2.0,[38] безкоштовну надбудову Microsoft excel для мета-аналізу, вироблену Epigear International Pty Ltd, і доступну з 5 квітня 2014 року. Автори заявляють, що очевидною перевагою цієї моделі є те, що вона вирішує дві основні проблеми моделі випадкових ефектів. Перша перевага моделі IVhet полягає в тому, що покриття залишається на номінальному (зазвичай 95 %) рівні довірчого інтервалу на відміну від моделі випадкових ефектів, що падає на покриття зі збільшенням неоднорідності.[21][22] Друга перевага полягає в тому, що модель IVhet підтримує зворотні дисперсійні ваги окремих досліджень, на відміну від моделі випадкових ефектів, яка надає невеликим дослідженням більше ваги (а отже, і більших досліджень) зі збільшенням гетерогенності. Коли гетерогенність стає великою, окремі ваги дослідження за моделлю RE стають рівними, і, таким чином, модель RE повертає середнє арифметичне, а не зважене середнє. Цей побічний ефект моделі RE не виникає з моделлю IVhet, яка, таким чином, відрізняється від оцінки моделі RE у двох перспективах:[37] Об'єднані оцінки сприятимуть більшій кількості випробувань (на відміну від пенімання масштабних випробувань у моделі RE) та матимуть довірчий інтервал, який залишатиметься в межах номінального покриття при невизначеності (неоднорідності). Doi & Barendregt припускають, що, хоча модель RE пропонує альтернативний метод об'єднання даних дослідження, результати їх моделювання[39] продемонструють, що використання більш визначеної моделі ймовірності з непереборними припущеннями, як і для моделі RE, не обов'язково дає кращі результати. Останнє дослідження також повідомляє, що модель IVhet вирішує проблеми, пов'язані з недооцінкою статистичної помилки, поганим покриттям довірчого інтервалу та збільшенням MSE, що спостерігається з моделлю випадкових ефектів, і автори роблять висновок, що дослідникам слід відмовитися від використання моделі випадкових ефектів в мета-аналізі. Незважаючи на те, що їх дані є переконливими, наслідки (з точки зору масштабів хибно позитивних результатів у базі даних Кокрана) величезні, і тому прийняття цього висновку вимагає ретельного незалежного підтвердження. Наявність вільного програмного забезпечення (MetaXL)[38] що керує моделлю IVhet (і всі інші моделі для порівняння) сприяє цьому для дослідницької спільноти.
Модель ефектів якості
Дой і Таліб представили модель ефектів якості.[40] Вони[41] запровадили новий підхід до коригування відмінності між дослідженнями, включивши внесок дисперсії за рахунок відповідного компонента (якості) на додаток до внеску дисперсії через випадкову помилку, яка використовується в будь-якій моделі метааналізу з фіксованими ефектами для генерації ваг для кожного дослідження. Сила метааналізу ефектів якості полягає в тому, що він дозволяє використовувати наявні методологічні докази над суб'єктивними випадковими ефектами, і тим самим, допомагає усунути згубний розрив, який відкрився між методологією та статистикою в клінічних дослідженнях. Для цього розраховується дисперсія синтетичного зміщення на основі інформації про якість для коригування зворотних дисперсійних ваг і вводиться вага, скоригована якістю i-го дослідження.[40] Ці скориговані ваги потім використовуються в метааналізі. Іншими словами, якщо i-те дослідження має хорошу якість, а інші дослідження мають низьку якість, частка їх коригованої ваги якості математично перерозподіляється на i-те дослідження, надаючи йому більшу вагу у загальній величині ефекту. Коли дослідження стають все більш схожими за якістю, перерозподіл стає відповідно меншим і припиняється, коли всі дослідження мають однакову якість (у випадку однакової якості модель ефектів якості за замовчуванням відповідає моделі IVhet — див. Попередній розділ). Недавня оцінка моделі ефектів якості (з деякими оновленнями) демонструє, що незважаючи на суб'єктивність оцінки якості, продуктивність (MSE та справжня дисперсія при моделюванні) перевершує показники, які можна досягти за допомогою моделі випадкових ефектів.[42][43] Ця модель, таким чином, замінює непереборні інтерпретації, які широко розповсюджені в літературі, і доступне програмне забезпечення для подальшого вивчення цього методу.[38]
Непрямі докази: мережеві методи метааналізу
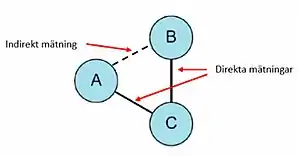
Методи непрямого порівняння метааналізу (їх також називають мережевими метааналізами, зокрема, коли багаторазове лікування оцінюється одночасно), як правило, використовують дві основні методології. По-перше, це метод Бюхера[44] що являє собою одиничне або повторне порівняння замкнутого циклу трьох обробок таким чином, що одна з них є спільною для двох досліджень і утворює вузол, де починається і закінчується цикл. Тому для порівняння декількох методів лікування потрібні декілька порівнянь двічі на два (3-х петлі обробки). Ця методологія вимагає, щоб у випробуваннях з більш ніж двома руками було вибрано лише дві руки, оскільки необхідні незалежні паралельні порівняння. Альтернативна методологія використовує складне статистичне моделювання для включення декількох випробувань та порівнянь одночасно між усіма конкуруючими методами лікування. Вони були виконані за допомогою байєсівських методів, змішаних лінійних моделей та методів регресії.
Байєсівська модель
Зазначення байєсівської моделі метааналізу мережі передбачає написання моделі спрямованого ациклічного графа (САГ) для програмного забезпечення марківського ланцюга Монте-Карло (МЛМК), такого як WinBUGS.[45] Крім того, для ряду параметрів повинні бути вказані попередні розподіли, а дані повинні надаватися у певному форматі.[45] Разом САГ, пріори та дані утворюють баєсову ієрархічну модель. Для подальшого ускладнення, через характер оцінки МЛМК, для декількох незалежних ланцюгів необхідно вибирати передисперсні вихідні значення, щоб можна було оцінити конвергенцію.[46] Наразі не існує програмного забезпечення, яке б автоматично генерувало подібні моделі, хоча є деякі інструменти, які допоможуть у цьому процесі. Складність байєсівського підходу обмежує використання цієї методології. Запропоновано методику автоматизації цього методу[47]але потрібно, щоб були дані про результати, отримані руками, і вони зазвичай недоступні. Іноді висуваються великі претензії на властиву байєсівській структурі обробку мережевого метааналізу та її більшу гнучкість. Однак цей вибір реалізації моделі для висновку, байєсівської або частотної, може бути менш важливим, ніж інші варіанти щодо моделювання ефектів[48] (див. обговорення на моделях вище).
Частотна модель з багатьма змінними
З іншого боку, частотні методи з багатьма змінними передбачають наближення та припущення, які не вказані прямо або перевірені під час застосування методів (див. Обговорення на моделях метааналізу вище). Наприклад, пакет mvmeta для Stata дозволяє здійснювати мережевий метааналіз частотними методами.[49] Однак, якщо в мережі немає загального значення для порівняння, то потрібно вирішити цю проблему доповнивши набір даних фіктивними згначеннями з великою дисперсією, що не дуже об'єктивно і вимагає прийняття рішення щодо того, що є досить великою дисперсією.[50] Іншим питанням є використання моделі випадкових ефектів як у цій частотній моделі, так і в байєсівській. Сенн радить аналітикам бути обережними щодо тлумачення аналізу «випадкових ефектів», оскільки можливий лише один випадковий ефект, але можна передбачити багато.[48]
Сенн продовжує говорити, що це досить наївно, навіть у випадку, коли порівнюють лише два методи лікування, припускаючи, що аналіз випадкових ефектів враховує всю невизначеність у тому, як ефекти можуть змінюватись від спроби до спроби. Новіші моделі метааналізу, такі, як обговорені вище, безумовно, допоможуть полегшити цю ситуацію і будуть впроваджені в наступній моделі.
Узагальнена система парного моделювання
Підхід, який випробовували з кінця 1990-х років, полягає у впровадженні багаторазового аналізу із замкнутим циклом із трьох обробок. Це не було популярно, оскільки процес швидко стає таким, який неможливо виконати,, оскільки складність мережі зростає. Тоді від розвитку у цій галузі відмовились на користь байєсівських та багатофакторних частотних методів, які з'явились як альтернативи. Зовсім недавно деякими дослідниками була розроблена автоматизація методу із замкнутим циклом із трьох обробок для складних мереж[37] як спосіб зробити цю методологію доступною для основних дослідницьких кіл. Ця пропозиція дійсно обмежує кожне випробування двома втручаннями, але також вводить обхідний шлях для багатократних випробувань: різний фіксований контрольний вузол може бути обраний в різних прогонах. Він також використовує надійні методи метааналізу, щоб уникнути багатьох проблем, висвітлених вище. Подальші дослідження цієї системи необхідні, щоб визначити, чи справді це перевершує байєсівські чи багатовимірні частотні схеми. Дослідники, які бажають спробувати це, мають доступ до цієї основи за допомогою вільного програмного забезпечення.[38]
Примітки
- Greenland S, O' Rourke K: Meta-Analysis. Page 652 in Modern Epidemiology, 3rd ed. Edited by Rothman KJ, Greenland S, Lash T. Lippincott Williams and Wilkins; 2008.
- Meta-analysis: Its strengths and limitations. Cleve Clin J Med 75 (6): 431–9. 2008. PMID 18595551. doi:10.3949/ccjm.75.6.431. Проігноровано невідомий параметр
|vauthors=(довідка) - Wanous, John P.; Sullivan, Sherry E.; Malinak, Joyce (1989). The role of judgment calls in meta-analysis.. Journal of Applied Psychology 74 (2): 259–264. ISSN 0021-9010. doi:10.1037/0021-9010.74.2.259.
- Glossary at Cochrane Collaboration. cochrane.org.
- Gravetter, Frederick J.; Forzano, Lori-Ann B. (1 січня 2018). Research Methods for the Behavioral Sciences (англ.). Cengage Learning. с. 36. ISBN 9781337613316. «Some examples of secondary sources are (1) books and textbooks in which the author describes and summarizes past research, (2) review articles or meta-analyses...»
- Adams, Kathrynn A.; Lawrence, Eva K. (2 лютого 2018). Research Methods, Statistics, and Applications (англ.). SAGE Publications. ISBN 9781506350462. «The most common types of secondary sources found in academic journals are literature reviews and meta-analyses.»
- PLACKETT, R. L. (1958). Studies in the History of Probability and Statistics: Vii. The Principle of the Arithmetic Mean. Biometrika 45 (1–2): 133. doi:10.1093/biomet/45.1-2.130. Процитовано 29 травня 2016.
- Pearson K (1904). Report on certain enteric fever inoculation statistics. BMJ 2 (2288): 1243–1246. PMC 2355479. PMID 20761760. doi:10.1136/bmj.2.2288.1243.
- Meta-analyses: what they can and cannot do. Swiss Medical Weekly 142: w13518. 9 березня 2012. PMID 22407741. doi:10.4414/smw.2012.13518. Проігноровано невідомий параметр
|vauthors=(довідка); Проігноровано невідомий параметр|doi-access=(довідка) - O'Rourke K (1 грудня 2007). An historical perspective on meta-analysis: dealing quantitatively with varying study results. J R Soc Med 100 (12): 579–582. PMC 2121629. PMID 18065712. doi:10.1258/jrsm.100.12.579.
- Pratt JG, Rhine JB, Smith BM, Stuart CE, Greenwood JA. Extra-Sensory Perception after Sixty Years: A Critical Appraisal of the Research in Extra-Sensory Perception. New York: Henry Holt, 1940
- Glass G. V (1976). Primary, secondary, and meta-analysis of research. Educational Researcher 5 (10): 3–8. doi:10.3102/0013189X005010003.
- Cochran WG (1937). Problems Arising in the Analysis of a Series of Similar Experiments. Journal of the Royal Statistical Society 4 (1): 102–118. JSTOR 2984123. doi:10.2307/2984123.
- A Sampling Investigation of the Efficiency of Weighting Inversely as the Estimated Variance. Biometrics 9 (4): 447–459. 1953. JSTOR 3001436. doi:10.2307/3001436. Проігноровано невідомий параметр
|vauthors=(довідка) - Debray, Thomas P. A.; Moons, Karel G. M.; van Valkenhoef, Gert; Efthimiou, Orestis; Hummel, Noemi; Groenwold, Rolf H. H.; Reitsma, Johannes B.; on behalf of the GetReal methods review group (1 грудня 2015). Get real in individual participant data (IPD) meta-analysis: a review of the methodology. Research Synthesis Methods (англ.) 6 (4): 293–309. ISSN 1759-2887. PMC 5042043. PMID 26287812. doi:10.1002/jrsm.1160.
- Individual participant data meta-analysis for a binary outcome: one-stage or two-stage?. PLoS ONE 8 (4): e60650. 2013. Bibcode:2013PLoSO...860650D. PMC 3621872. PMID 23585842. doi:10.1371/journal.pone.0060650. Проігноровано невідомий параметр
|vauthors=(довідка) - Burke, Danielle L.; Ensor, Joie; Riley, Richard D. (28 лютого 2017). Meta-analysis using individual participant data: one-stage and two-stage approaches, and why they may differ. Statistics in Medicine (англ.) 36 (5): 855–875. ISSN 1097-0258. PMC 5297998. PMID 27747915. doi:10.1002/sim.7141.
- Helfenstein U (2002). Data and models determine treatment proposals--an illustration from meta-analysis. Postgrad Med J 78 (917): 131–4. PMC 1742301. PMID 11884693. doi:10.1136/pmj.78.917.131.
- Senn S (2007). Trying to be precise about vagueness. Stat Med 26 (7): 1417–30. PMID 16906552. doi:10.1002/sim.2639.
- Combining heterogenous studies using the random-effects model is a mistake and leads to inconclusive meta-analyses (PDF). Journal of Clinical Epidemiology 64 (2): 119–23. 2011. PMID 20409685. doi:10.1016/j.jclinepi.2010.01.009. Проігноровано невідомий параметр
|vauthors=(довідка) - Brockwell S.E.; Gordon I.R. (2001). A comparison of statistical methods for meta-analysis. Statistics in Medicine 20 (6): 825–840. PMID 11252006. doi:10.1002/sim.650.
- Noma H (Dec 2011). Confidence intervals for a random-effects meta-analysis based on Bartlett-type corrections. Stat Med 30 (28): 3304–12. PMID 21964669. doi:10.1002/sim.4350. Проігноровано невідомий параметр
|hdl=(довідка); Проігноровано невідомий параметр|hdl-access=(довідка) - A simple method for inference on an overall effect in meta-analysis. Statistics in Medicine 26 (25): 4531–4543. 2007. PMID 17397112. doi:10.1002/sim.2883. Проігноровано невідомий параметр
|vauthors=(довідка) - A simple confidence interval for meta-analysis. Statistics in Medicine 21 (21): 3153–3159. 2002. PMID 12375296. doi:10.1002/sim.1262. Проігноровано невідомий параметр
|vauthors=(довідка) - A re-evaluation of the 'quantile approximation method' for random effects meta-analysis. Stat Med 28 (2): 338–48. 2009. PMC 2991773. PMID 19016302. doi:10.1002/sim.3487. Проігноровано невідомий параметр
|vauthors=(довідка) - Random-effects meta-analyses are not always conservative. Am J Epidemiol 150 (5): 469–75. Sep 1999. PMID 10472946. doi:10.1093/oxfordjournals.aje.a010035. Проігноровано невідомий параметр
|vauthors=(довідка); Проігноровано невідомий параметр|doi-access=(довідка) - Interpretation of random effects meta-analyses. British Medical Journal 342: d549. 2011. PMID 21310794. doi:10.1136/bmj.d549. Проігноровано невідомий параметр
|vauthors=(довідка) - Kriston L (2013). Dealing with clinical heterogeneity in meta-analysis. Assumptions, methods, interpretation. Int J Methods Psychiatr Res 22 (1): 1–15. PMC 6878481. PMID 23494781. doi:10.1002/mpr.1377.
- Meta-analysis in clinical trials. Control Clin Trials 7 (3): 177–88. 1986. PMID 3802833. doi:10.1016/0197-2456(86)90046-2. Проігноровано невідомий параметр
|vauthors=(довідка) - Kontopantelis, Evangelos; Reeves, David (1 серпня 2010). Metaan: Random-effects meta-analysis. Stata Journal 10 (3): 395–407. doi:10.1177/1536867X1001000307 — через ResearchGate. Проігноровано невідомий параметр
|doi-access=(довідка) - Kontopantelis, Evangelos; Reeves, David (2009). MetaEasy:A Meta-Analysis Add-In for Microsoft Excel, Journal of Statistical Software 2009. Journal of Statistical Software 30 (7). doi:10.18637/jss.v030.i07. Проігноровано невідомий параметр
|doi-access=(довідка) - Developer's website. Statanalysis.co.uk. Процитовано 18 вересня 2018.
- Performance of statistical methods for meta-analysis when true study effects are non-normally distributed: A simulation study.. Statistical Methods in Medical Research 21 (4): 409–26. 2012. PMID 21148194. doi:10.1177/0962280210392008. Проігноровано невідомий параметр
|vauthors=(довідка) - Performance of statistical methods for meta-analysis when true study effects are non-normally distributed: a comparison between DerSimonian-Laird and restricted maximum likelihood. SMMR 21 (6): 657–9. 2012. PMID 23171971. doi:10.1177/0962280211413451. Проігноровано невідомий параметр
|vauthors=(довідка) - Friede, Tim, ред. (2013). A Re-Analysis of the Cochrane Library Data: The Dangers of Unobserved Heterogeneity in Meta-Analyses. PLoS ONE 8 (7): e69930. Bibcode:2013PLoSO...869930K. PMC 3724681. PMID 23922860. doi:10.1371/journal.pone.0069930. Проігноровано невідомий параметр
|vauthors=(довідка) - Kontopantelis, Evangelos; Reeves, David (27 вересня 2013). A short guide and a forest plot command (ipdforest) for one-stage meta-analysis. Stata Journal 13 (3): 574–587. doi:10.1177/1536867X1301300308 — через ResearchGate. Проігноровано невідомий параметр
|doi-access=(довідка) - MetaXL User Guide. Процитовано 18 вересня 2018.
- MetaXL software page. Epigear.com. 3 червня 2017. Процитовано 18 вересня 2018.
- Advances in the Meta-analysis of heterogeneous clinical trials I: The inverse variance heterogeneity model. Contemp Clin Trials 45 (Pt A): 130–8. 2015. PMID 26003435. doi:10.1016/j.cct.2015.05.009. Проігноровано невідомий параметр
|vauthors=(довідка) - A quality-effects model for meta-analysis. Epidemiology 19 (1): 94–100. 2008. PMID 18090860. doi:10.1097/EDE.0b013e31815c24e7. Проігноровано невідомий параметр
|vauthors=(довідка) - Meta-analysis of heterogeneous clinical trials: an empirical example. Contemp Clin Trials 32 (2): 288–98. 2011. PMID 21147265. doi:10.1016/j.cct.2010.12.006. Проігноровано невідомий параметр
|vauthors=(довідка) - Simulation Comparison of the Quality Effects and Random Effects Methods of Meta-analysis. Epidemiology 26 (4): e42–4. 2015. PMID 25872162. doi:10.1097/EDE.0000000000000289. Проігноровано невідомий параметр
|vauthors=(довідка) - Advances in the meta-analysis of heterogeneous clinical trials II: The quality effects model. Contemp Clin Trials 45 (Pt A): 123–9. 2015. PMID 26003432. doi:10.1016/j.cct.2015.05.010. Проігноровано невідомий параметр
|vauthors=(довідка) - Bucher H. C.; Guyatt G. H.; Griffith L. E.; Walter S. D. (1997). The results of direct and indirect treatment comparisons in meta-analysis of randomized controlled trials. J Clin Epidemiol 50 (6): 683–691. PMID 9250266. doi:10.1016/s0895-4356(97)00049-8.
- Valkenhoef G.; Lu G.; Brock B.; Hillege H.; Ades A. E.; Welton N. J. (2012). Automating network meta‐analysis. Research Synthesis Methods 3 (4): 285–299. PMID 26053422. doi:10.1002/jrsm.1054.
- General methods for monitoring convergence of iterative simulations. Journal of Computational and Graphical Statistics 7 (4): 434–455. 1998. doi:10.1080/10618600.1998.10474787. Проігноровано невідомий параметр
|vauthors=(довідка) - van Valkenhoef G, Lu G, de Brock B, Hillege H, Ades AE, Welton NJ. Automating network meta-analysis. Res Synth Methods. 2012 Dec;3(4):285-99.
- Issues in performing a network meta-analysis. Stat Methods Med Res 22 (2): 169–89. Apr 2013. PMID 22218368. doi:10.1177/0962280211432220. Проігноровано невідомий параметр
|vauthors=(довідка) - White IR (2011). Multivariate random-effects meta-regression: updates to mvmeta. The Stata Journal 11 (2): 255–270. doi:10.1177/1536867X1101100206. Проігноровано невідомий параметр
|doi-access=(довідка) - van Valkenhoef G, Lu G, de Brock B, Hillege H, Ades AE, Welton NJ. Automating network meta-analysis. Res Synth Methods. 2012 Dec;3(4):285-99
