Моделювання даних
Моделюва́ння да́них (англ. data modeling) у програмній інженерії — процес створення моделі даних для інформаційної системи шляхом застосування певних формальних підходів.
Огляд
Моделювання даних — процес, що використовується для визначення й аналізу вимог до даних, необхідних для підтримки бізнес-процесів у межах відповідних інформаційних систем в організаціях. Таким чином, процес моделювання даних залучає професійних моделістів даних, які тісно працюють із зацікавленими сторонами бізнесу, а також із потенційними користувачами інформаційної системи.
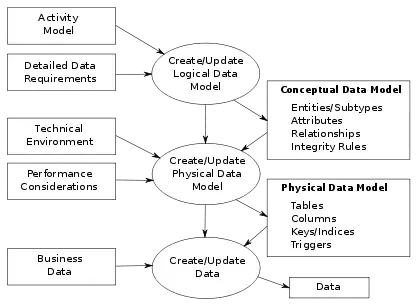
Існують три різних типи моделей даних, що виробляються протягом переходу від вимог до дійсної бази даних для використання в інформаційній системі[2]. Вимоги до даних спочатку записуються як концептуальна модель даних, яка по суті є набором технологічно залежних специфікацій про дані та використовується для обговорення початкових вимог із зацікавленими сторонами бізнесу. Концептуальна модель потім перетворюється на логічну модель даних, яка документує структури даних, що можуть реалізовуватися в базах даних. Реалізація однієї концептуальної моделі даних може вимагати багатьох логічних моделей даних. Останнім кроком у моделюванні даних є перетворення логічної моделі даних на фізичну модель даних, яка організує дані в таблиці та пояснює деталі доступу, продуктивності та зберігання. Моделювання даних визначає не тільки елементи даних, а й також їх структури та відношення між ними[3].
Техніки та методології моделювання даних використовуються для моделювання даних у стандартний, послідовний і передбачуваний спосіб задля керування ним як ресурсом. Використання стандартів моделювання даних настійно рекомендується для всіх проектів, що вимагають стандартні засоби визначення й аналізу даних у межах організації, наприклад, моделювання даних використовується для:
- допомоги бізнес-аналітикам, програмістам, тестувальникам, авторам керівництв, вибірникам пакетів ІТ, інженерам, менеджерам, пов'язаним організаціям і клієнтам зрозуміти та використати погоджену напівформальну модель концепції організації та як вони стосуються один одного;
- керування даними як ресурсом;
- інтеграції інформаційної системи;
- проектування баз і сховищ даних (також відомі як репозитарії даних).
Моделювання даних може здійснюватися під час різних типів проектів і на багатьох фазах проектів. Моделі даних прогресивні: немає такого поняття, як кінцева модель даних для бізнесу чи застосунку. Натомість модель даних повинна розглядатися як живий документ, який змінюватиметься у відповідь на зміну бізнесу. Моделі даних в ідеалі слід зберігати в репозитарії так, щоб їх можна було отримати, розширити та редагувати за деякий час. Віттен та інші (2004) визначили два типи моделювання даних[4]:
- Стратегічне моделювання даних — є частиною створення стратегії інформаційних систем, що визначає загальне бачення й архітектуру інформаційних систем. Інформаційна інженерія є методологією, що охоплює цей підхід.
- Моделювання даних протягом системного аналізу: В системному аналізі логічні моделі даних створюються як частина розробки нових баз даних.
Моделювання даних також використовується як техніка деталізації бізнес-вимог для конкретних баз даних. Воно іноді називається «моделюванням даних», оскільки модель даних із часом реалізується в базу даних[4].
Теми моделювання даних
Моделі даних
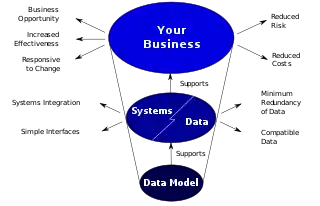
Моделі даних надають фреймворк для даних, які використовуватимуться в інформаційних системах шляхом надання конкретного визначення та формату. Якщо модель даних використовується послідовно в усіх системах, то сумісність даних є досяжною. Якщо ті самі структури даних використовуються для зберігання та доступу до даних, тоді різні застосунки можуть безшовно ділитися даними. Результати цього показано на діаграмі. Проте, системи й інтерфейси часто дорого будувати, оперувати та підтримувати. Вони також можуть радше обмежувати бізнес, аніж підтримувати його. Це може статися, коли якість моделей даних, реалізованих у системах та інтерфейсах, є низькою[1]
- Бізнес-правила, специфічні до того, як усе робиться в певному місці, часто фіксуються у структурі моделі даних. Це означає, що малі зміни у способі ведення бізнесу призводять до великих змін у комп'ютерних системах та інтерфейсах. Тому бізнес-правила повинні реалізовуватися у гнучкий спосіб, що не спричинює складні залежності, а модель даних повинна бути достатньо гнучкою, щоби такі зміни в бізнесі могли реалізовуватися в межах моделі даних у відносно швидкий та ефективний спосіб.
- Типи сутностей часто невизначені чи визначені некоректно. Це може призвести до реплікації даних, їх структур і функційності, разом із супутньою вартістю такого дублювання в розробці та підтримці. Таким чином, визначення даних повинні бути зроблені настільки чіткими та легкими для розуміння, наскільки можливо для мінімізації хибного тлумачення та дублювання.
- Моделі даних для різних систем довільно різні. Наслідком цього є необхідність складних інтерфейсів між системами, що спільно використовують дані. Ці інтерфейси можуть становити 25—70 % вартості поточних систем. Необхідні інтерфейси повинні розглядатися по суті під час проектування моделі даних, сама по собі модель даних не використовуватиметься без інтерфейсів у різних системах.
- Даними не можна ділитися в електронному вигляді між клієнтами та постачальниками, оскільки структура та значення даних не були стандартизовані. Для отримання оптимального значення від реалізованої моделі даних дуже важливо визначити стандарти, які забезпечать, що моделі даних і відповідатимуть потребам бізнесу, і будуть послідовними[1].
Концептуальні, логічні та фізичні схеми
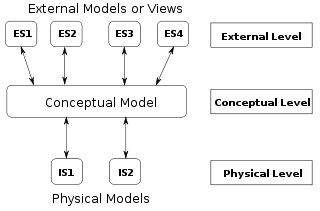
1975 року ANSI описав три види «екземплярів» моделей даних[5]:
- Концептуальна схема: описує семантику предметної області (межі[уточнити] моделі). Наприклад, це може бути модель площі інтересів організації чи індустрії. Вона складається з класів сутностей, які подають види важливих речей у предметній області, та відношень тверджень про асоціації між парами класів сутностей. Концептуальна схема визначає види фактів або пропозицій, які можна виразити за допомогою моделі. У цьому сенсі вона визначає дозволені вирази штучною «мовою» в межах, обмежених межами моделі. Простіше кажучи, концептуальна схема є першим кроком в організації вимог до даних.
- Логічна схема: описує структуру певної предметної області інформації. Вона складається з описів (наприклад) таблиць, колонок, об'єктно-орієнтованих класів і тегів XML. Логічна та концептуальна схеми іноді реалізуються як одне й те саме[2].
- Фізична схема: описує фізичні засоби, що використовуються для зберігання даних. Вона стосується розділів, ЦП, табличних просторів тощо.
Згідно з ANSI, цей підхід дозволяє трьом перспективам бути відносно незалежними одна від одної. Технології зберігання можуть змінюватися без упливу на логічну чи концептуальну схему. Структура таблиць або колонок може змінюватися без (обов'язкового) впливу на концептуальну схему. У цьому випадку, звичайно, структури повинні залишатися послідовними в усіх схемах тієї самої моделі даних.
Процес моделювання даних
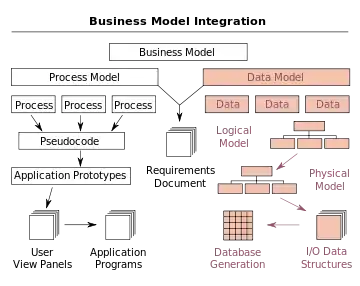
У контексті інтеграції бізнес-процесів (див. малюнок) моделювання даних доповнює моделювання бізнес-процесів і зрештою має наслідком генерацію бази даних[6].
Процес проектування бази даних включає створення попередньо описаних трьох типів схем — концептуальної, логічної та фізичної. Проект бази даних, документований у трьох схемах, перетворюється через мову визначення даних, яка потім може використовуватися для генерації бази даних. Повністю приписана модель даних містить докладні атрибути (описи) для кожнї сутності в ній. Термін «проект бази даних» може описувати багато різних частин проекту всієї системи баз даних. Принципово та найкоректніше, це може вважатися логічним проектом базових структур даних, що використовуються для зберігання даних. У реляційній моделі це таблиці та розрізи. В об'єктних базах даних сутності та відношення відображаються безпосередньо в об'єктні класи й іменовані відношення. Проте, термін «проект бази даних» може також застосовуватися до всього процесу проектування, а лише базових структур даних, але також форм і запитів, що використовуються як частина всього застосунку баз даних у системі керування базами даних, або СКБД.
У процесі системні інтерфейси становлять від 25 % до 70 % вартості розробки та підтримки поточних систем. Основною причиною цієї вартості є те, що ці системи не поділяють спільну модель даних. Якщо моделі даних розроблені на засадах система за системою, тоді не лише той самий аналіз повторюється в пересічних областях, а й подальший аналіз повинен здійснюватися дл ястворення інтерфейсів між ними. Більшість систем в організації містять ті самі базові дані, перероблені для конкретної мети. Таким чином, ефективно спроектована базова модель даних може мінімізувати переробку з мінімальними модифікаціями для цілей різних систем в організації[1].
Методології моделювання
Моделі даних подають інформаційні сфери інтересів. Тоді як існує багато способів створення моделі даних, за словами Лена Сілверстона (1997)[7], виділяються лише дві методології моделювання, згори донизу та знизу догори:
- Моделі знизу догори, чи моделі інтеграції розрізів англ. View Integration, часто є наслідком зусиль реінжинірингу. Вони зазвичай починаються з існування форм структур даних, полів на екранах застосунків або звітів. Ці моделі зазвичай фізичні, специфічні до застосунку та незавершені з погляду підприємства. Вони можуть не сприяти обміну даними, особливо якщо вони побудовані без посилань на інші частини організації[7].
- Логічні моделі даних згори донизу, з іншого боку, створені в абстрактний спосіб отриманням інформації від людей, які знають предметну область. Система може не реалізувати всі сутності в логічній моделі, але модель слугує орієнтиром або шаблоном[7].
Іноді моделі створено в суміші двох методів: розглядаючи необхідні дані та структури застосунку, та послідовно посилаючись на модель предметної області. На жаль, у багатьох середовищах відмінності між логічною та фізичною моделями даних розмиті. На додачу, деякі CASE-засоби не розрізняють логічні та фізичні моделі даних[7].
Діаграми «сутність — зв'язок»
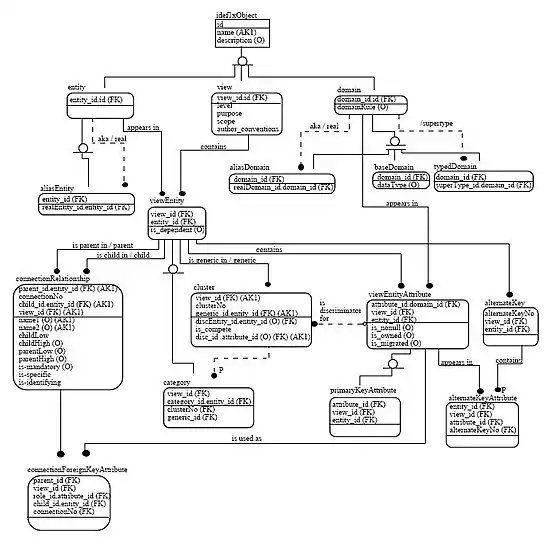
Існують декілька нотацій моделювання даних. Дійсна модель часто називається «модель „сутність — зв'язок“», оскільки вона зображає дані в термінах сутностей і відношень, описаних у даних[4]. Модель «сутність — зв'язок» (англ. entity-relationship model, ERM) є абстрактним концептуальним поданням структурованих даних. Моделювання «сутність — зв'язок» є реляційною схемою методу моделювання баз даних, що використовується у програмній інженерії для створення типу концептуальної моделі даних (або семантичної моделі даних) системи, часто реляційної бази даних, та її вимог згори донизу.
Ці моделі використовуються на першій стадії проектування інформаційної системи протягом аналізу вимог для опису потреб інформації чи типу інформації, що зберігатиметься в базі даних. Техніка моделювання даних може використовуватися для опису будь-якої онтології (тобто огляду та класифікацій використовуваних термінів і їх відношень) для певного універсуму дискурсу, тобто сфери інтересів.
Декілька технік було розроблено для проектування моделей даних. Поки ці методології керує моделістами даних у їхній роботі, використання однієї методології двома різними людьми часто призведе до дуже різних результатів. Найпомітнішими є:
- Діаграма Бакмана
- Нотація Баркера
- Нотація Чена
- Моделювання сховищ даних
- Розширена нотація Бекуса — Наура
- IDEF1X
- Об'єктно-реляційне відображення
- Об'єктно-рольове моделювання
- Реляційна модель даних
- Реляційна модель/Тасманія
Загальне моделювання даних
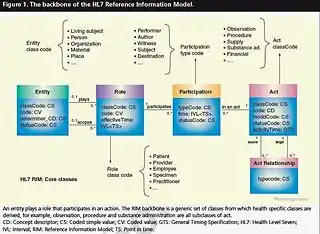
Загальні моделі даних є узагальненнями звичайних моделей даних. Вони визначають стандартизовані загальні типи відношень, разом із видами речей, що можуть бути пов'язані такими типами відношень.
Визначення загальної моделі даних подібне до визначення природної мови. Наприклад, загальна модель даних може визначати типи відношень, як-от «відношення класифікації», що є бінарним відношенням між окремими речами та їх видами (класами), та «відношення „частина-ціле“», що є бінарним відношенням між двома речами, одним із роллю частини, іншим із роллю цілого, незалежно від видів речей, що пов'язані.
Враховуючи розширюваний список класів, це дозволяє класифікувати будь-яку окрему річ і визначити відношення «частина—ціле» для будь-якого окремого об'єкта. Стандартизацією розширюваного списку типів відношень загальна модель даних дозволяє виражати необмежену кількість видів фактів і наближатиметься до можливостей природних мов. Звичайні моделі даних, з іншого боку, мають фіксовані й обмежені межі галузі, оскільки екземпляри (використання) такої моделі дозволяє виражати лише види фактів, які заздалегідь визначені в моделі.
Семантичне моделювання даних
Логічні структури даних СУБД, чи то ієрархічних, мережевих або реляційних, не можуть повністю задовольнити вимоги концептуального визначення даних, оскільки вони обмежені в межах та упереджені до стратегії реалізації, що використовується СКБД. Це так, якщо семантична модель даних не реалізована в базі даних за призначенням, вибір, який може дещо вплинути на виконання, але загалом значно поліпшує продуктивність.
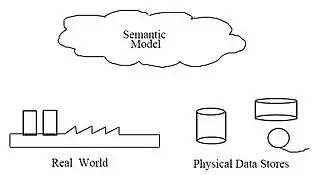
Таким чином, потреба визначення даних із концептуального розрізу призводить до розробки техніки семантичного моделювання даних. Тобто техніки для визначення суті даних у контексті їх взаємовідношень із іншими даними. Як показано на малюнку, реальний світ, у термінах ресурсів, ідей, подій та ін., символічно визначений у фізичних сховищах даних. Семантична модель даних є абстракцією, що визначає те, як збережені символи відносяться до реального світу. Тому модель повинна бути істинним поданням реального світу[8].
Семантична модель даних може використовуватися для багатьох цілей, як-от[8]:
- планування ресурсів даних;
- побудова поділюваних[уточнити] баз даних;
- оцінювання постачальників програмного забезпечення;
- інтеграція наявних баз даних.
Загальна мета семантичних моделей даних полягає в захоплення якомога більшого сенсу даних шляхом інтеграції реляційних концепції з потужнішими концепціями абстрагування, відомими з галузі штучного інтелекту. Ідея полягає в забезпечення високорівневих примітивів моделювання як цілої частини моделі даних задля сприяння поданню ситуацій реального світу[10].
Квантове моделювання
У жовтні 2017 з'явився фреймворк OpenFermion Cirq , перша платформа з відкритим кодом для перекладу проблем хімії та матеріалознавства в квантові схеми. OpenFermion - це бібліотека для моделювання систем взаємодіючих електронів (ферміонів), що породжують властивості речовини[11] [12]. До OpenFermion розробникам квантових алгоритмів потрібно було вивчити значну кількість хімії та написати велику кількість коду, щоб зламати інші коди, щоб скласти навіть найосновніші квантові симуляції.
Див. також
- Архітектурні шаблони програмного забезпечення
- Дані
- Інформативне моделювання
- Інформаційний менеджмент
- Мова моделювання
- Модель Закмана
- Моделювання документів
- Моделювання метаданих
- Порівняння засобів моделювання даних
- Словник даних
- Трисхемний підхід
Примітки
- Вест, Метью; Фоулер, Джуліан (1999). Developing High Quality Data Models (PDF). The European Process Industries STEP Technical Liaison Executive (EPISTLE).
- Грем Сімсіон, Грехем Вітт. Data Modeling Essentials. — 3-е. — Сан-Франциско : Morgan Kaufmann Publishers, 2005. — ISBN 0-12-644551-6.
- Data Integration Glossary (PDF). — Міністерство транспорту США, 2001. — Серпень. Архівовано з джерела 20 березня 2009.
- Віттен, Джеффрі Л.; Бентлі, Лонні Д.; Діттман, Кевін К. (2004). Systems Analysis and Design Methods (вид. 6-е). ISBN 0-256-19906-X.
- Американський національний інститут стандартів (1975). ANSI/X3/SPARC Study Group on Data Base Management Systems; Interim Report. FDT (Bulletin of ACM SIGMOD) 7:2.
- Сміт, Пол Р.; Сарфаті, Річард (1 травня 1993). Creating a strategic plan for configuration management using computer aided software engineering (CASE) tools (англійською). США: Paper For 1993 National DOE/Contractors and Facilities CAD/CAE User's Group.
- Сілверстон, Лен; Інмон, В. Г.; Граціано, Кент (2007) [1997]. The Data Model Resource Book. Wiley. ISBN 0-471-15364-8. Reviewed by Van Scott on tdan.com
- FIPS Publication 184 released of IDEF1X (DOC) (прес-реліз). Computer Systems Laboratory of the National Institute of Standards and Technology (NIST). 21 грудня 1993. Архівовано 3 грудня 2013 у Wayback Machine.
- Шабо, Амнон (2006). Clinical genomics data standards for pharmacogenetics and pharmacogenomics. Архів оригіналу за 22 липня 2009. Процитовано 23 серпня 2018.
- Semantic data modeling. Metaclasses and Their Application (Book Series Lecture Notes in Computer Science. Publisher Springer Berlin / Heidelberg) (943). 1995.
- https://ai.googleblog.com/2017/10/announcing-openfermion-open-source.html
- https://www.fightaging.org/archives/2017/12/the-sens-research-foundation-comments-on-calicos-research-into-apparent-rejuvenation-in-oocytes
Посилання
- Agile/Evolutionary Data Modeling
- Data modeling articles
- Database Modelling in UML
- Data Modeling 101
- Semantic data modeling
- System Development, Methodologies and Modeling Notes on by Tony Drewry
- Request For Proposal — Information Management Metamodel (IMM) of the Object Management Group
- Data Modeling is NOT just for DBMS's Part 1 Chris Bradley
- Data Modeling is NOT just for DBMS's Part 2 Chris Bradley