Перетворення даних (статистика)
В статистиці перетворення даних зводиться до застосування детермінованої математичної функції до кожного елементу в наборі даних, тобто, кожна точка z в наборі даних замінюється на трансформоване значення , де f – це якась функція. Перетворення зазвичай застосовуються для того, щоб дані точніше відповідали припущенням процедури статистичного зведення, а також для покращення інтерпретації або вигляду графіків. Майже завжди функція, застосована для трансформації даних, має обернену та єнеперервною. Трансформацію зазвичай застосовують до набору порівняних вимірювань. Наприклад, якщо ми маємо набір даних про доходи населення в якійсь валюті, трансформацію зазвичай виконують за допомогою логарифмічної функції.

Причини трансформації даних
Напрямки перетворення даних (або обґрунтування необхідності застосування трансформації) мають бути наслідком застосованого статистичного аналізу. Наприклад, для визначення 95% довірчого інтервалу середнього значення для генеральної сукупності слід взяти середнє значення вибірки плюс-мінус два стандартних відхилення. Проте, використання саме числа два обумовлюється властивостями нормального розподілу і тому можливе тільки в тому випадку, коли середнє значення вибірки має розподіл близький до нормального. Центральна гранична теорема стверджує, що в багатьох випадках середнє значення вибірки розподілене нормально, якщо розмір вибірки доволі великий. Проте, якщо генеральна сукупність є асиметричною та розмір вибірки є невеликим, апроксимація, запропонована центральною граничною теоремою, є некоректною, а тому отриманий в результаті довірчий інтервал може мати довірчу ймовірність, що відрізняється від заданої. Тому асиметричні дані зазвичай трансформують в симетричний розподіл перш ніж обчислювати довірчі інтервали. Якщо необхідно, отриманий довірчий інтервал трансформують в оригінальну шкалу використовуючи функцію, обернену до функції перетворення.
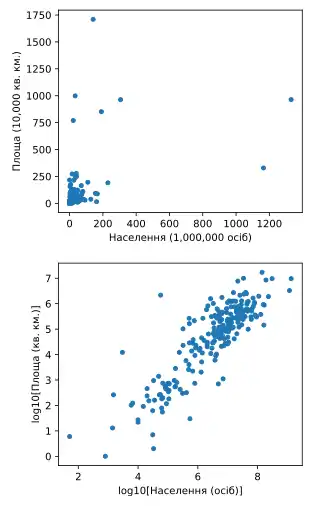
Також дані трансформують для спрощення візуалізації. Наприклад, візьмемо графік, на якому кожна точка відповідає одній зі світових країн, а осі х та у зображають відповідно кількість населення та розмір території. Якщо зображати такий графік, використовуючи не перетворені дані (тобто, для площі використовувати квадратні кілометри, а для населення – кількість осіб), то більшість країн опиниться в нижньому лівому кутку у вигляді кластеру з крапок. Декілька країн з найбільшою площею та/або кількістю населення будуть розподілені по координатній площині. Якщо використати інші одиниці вимірювання, наприклад, площу виразити в тисячах квадратних кілометрів, а населення – в мільйонах осіб, то графік майже не зміниться. Проте, якщо використати логарифмічну трансформацію даних по обох осях, точки будуть більш рівномірно розподілені по графіку.
Нарешті, дані трансформують для спрощення інтерпретації, навіть якщо статистичний аналіз або візуалізація не використовуються. Припустимо, що нам потрібно порівняти автомобілі за параметром економії пального. Подібні дані зазвичай подаються в таких одиницях вимірювання як «кілометрів на літр пального». Проте, якщо потрібно оцінити кількість додаткового пального що буде необхідна у випадку використання однієї машини або іншої протягом року, дані можна перетворити за допомогою оберненої функції, щоб отримати значення, виражені в літрах на кілометр.
Перетворення даних в регресійному аналізі
Лінійна регресія – статистичний метод, що використовується для визначення відношення залежної змінної від однієї або більше незалежних змінних. Найпростіші регресійні моделі відображають лінійну залежність між математичним сподіванням залежної змінної та окремими незалежними змінними (при фіксованих значеннях інших незалежних змінних). Якщо навіть приблизної лінійної залежності немає, інколи можливо трансформувати або залежну або незалежні змінні в регресійній моделі для виявлення лінійної залежності. Іншим припущенням лінійної регресії є рівність дисперсії для кожного очікуваного значення залежної змінної (гомоскедастичність). Для отримання значущих коефіцієнтів регресії за використання методу найменших квадратів необов’язково, щоб це припущення виконувалось. Проте обчислені довірчі інтервали та тести гіпотез матимуть кращі статистичні властивості, якщо воно виконується. Через це для уникнення проблем пов’язаних з гетероскедастичністю найчастіше використовують один з наступних підходів:
- Використання логарифмічних перетворень даних;
- Зміна специфікації моделі (наприклад, застосування лінійної трансформації незалежної змінної);
- Використання методу зважених найменших квадратів (використання МНК для зважених або трансформованих значень залежної та незалежних змінних);
- Обчислення стандартної похибки, що є робастною до гетероскедастичності.
Приклади трансформацій
Рівняння:

Значення: Зростання X на одиницю викликає зростання Y в середньому на b одиниць.
Рівняння: (Шляхом застосування експоненційної функції до обох сторін рівняння отримаємо: )


Значення: Зростання X на одиницю призводить до зростання Y в середньому на 100b%.
Рівняння:

Значення:Зростання Х на 1% призводить до зростання Y в середньому на b/100.
Рівняння: (Шляхом логарифмування обох сторін рівняння )


Значення:Зростання Х на 1% призводить до зростання Y в середньому на b%.
Типові трансформації
Для позитивних значень даних зазвичай застосовують логарифмічну функцію або квадратний корінь. Обернену трансформацію використовують для ненульових значень даних. Степенева трансформація являє собою групу функцій, що застосовуються в статистиці для трансформації даних зі збереженням рангу. Ці функції параметризуються за допомогою невід’ємного параметру λ, різні значення якого відповідають логарифмічній функції, квадратному кореню, або оберненій функції. Цей параметр можливо статистично оцінити для визначення типу трансформації, яка буде найбільш ефективною. За допомогою такою оцінки можливо також визначити, чи потрібно використовувати трансформацію взагалі. Використання оберненої функції та степеневих трансформацій можливо для даних, які мають позитивні та негативні значення (степенева трансформація буде коректною якщо λ є цілим та непарним). Проте зазвичай в такому випадку до всіх значень даних додають константу щоб отримати набір невід’ємних даних, до якого вже потім застосовують трансформацію.
Типово застосовувати трансформацію у випадках, коли дані мають змінний діапазон (дані з різними очікуваними значеннями мають різну дисперсію). Це властиво для даних по багатьох фізичних та соціальних явищах. Для додання симетричності таким даним використовують степеневі трансформації або логарифмічне перетворення. Прикладами таких трансформацій є трансформація Фішера, трансформація Анскомба, та трансформація Бокса-Кокса.
Використання логарифмічного перетворення також корисно у випадку визначення відношень. Наприклад, потрібно порівняти дві позитивні величини X та Y використовуючи відношення . Тоді, якщо X < Y, відношення лежить в інтервалі (0,1), а коли X > Y, відношення попадає в інтервал (1,∞). Якщо ж застосувати логарифмічне перетворення даних, то відношення у випадку рівності двох величин; а у випадку якщо Х та У не є рівними, логарифмічні відношення та будуть рівновіддаленими від нуля. Якщо значення даних коливаються в межах від 0 до 1, тоді для трансформації можна використати логістичну функцію: вона має діапазон значень (−∞,∞).



Трансформація до нормального розподілу
Багато методів статистичного висновування вимагають використовування нормально розподілених даних.
Нормальність даних можна досягти через степеневу трансформацію. Для оцінки відповідності даних параметрам нормального розподілу зазвичай використовують графічний метод. Одним із методів перевірки нормальності даних є граф - Гістограма. Нормально розподілені данні матимуть вигляд симетричної Гаусової кривої.
Якщо ж Гістограма виявила несиметричність - дані можна спробувати трансформувати одним із наступних методів:
- Логарифмічна трансформація
- Взяти корінь із числа


Якщо стандартне відхилення пропорційно середньому арифметичному, або ж Гістограма показує що данні позитивно асиметричні, може допомогти логарифмічна трансформація. Якщо ж дисперсія пропорційна середньому арифметичному, то підійне коренева трансформація.[1]
Трансформація до рівномірного розподілу
Для набору з n різних значень можна застосувати рангову трансформацію (, де k – порядковий номер Xi у ряді, ранжованому за зростанням), яка приводить дані до рівномірного розподілу. Так само якщо Х – випадкова величина, а F – функція розподілу ймовірностей для Х, то, якщо F має обернену, випадкова величина є рівномірно розподіленою на одиничному інтервалі [0,1]. З рівномірного розподілу можна здійснити трансформацію до будь-якого розподілу за допомогою оберненої функції розподілу ймовірностей. Так, якщо G – обернена функція розподілу ймовірностей, а U - випадкова рівномірно розподілена величина, то для випадкової величини G−1(U) функція G буде функцією розподілу ймовірностей.



Примітки
- Manikandan, S. (1 липня 2010). Data transformation. Journal of Pharmacology and Pharmacotherapeutics (англ.) 1 (2). с. 126. ISSN 0976-500X. PMID 21350629. doi:10.4103/0976-500X.72373. Процитовано 19 травня 2021.