Синтаксичний аналіз
Синтакси́чний ана́ліз (па́рсинг) (англ. parsing) — в інформатиці це процес аналізу вхідної послідовності символів, з метою розбору граматичної структури згідно із заданою формальною граматикою. Синтаксичний аналізатор (англ. parser) — це програма або частина програми, яка виконує синтаксичний аналіз.
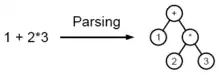
Під час синтаксичного аналізу текст оформлюється у структуру даних, зазвичай — в дерево, яке відповідає синтаксичній структурі вхідної послідовності і добре підходить для подальшої обробки. Зазвичай синтаксичні аналізатори працюють в два етапи: на першому ідентифікуються осмислені токени (виконується лексичний аналіз), на другому створюється дерево розбору.
Мови програмування
Синтаксичний аналізатор
Синтаксичний аналізатор — це програмний компонент, який приймає вхідні дані (часто текст) і створює структуру даних — часто дерево розбору, абстрактне дерево синтаксису або іншу ієрархічну структуру — забезпечує структурне представлення вводу, перевіряє правильність синтаксису в процесі. Аналізу можуть передувати або слідувати інші кроки, або їх можна об'єднати в один крок. Аналізатору часто передує окремий лексичний аналізатор, який створює токени з послідовності введених символів; Крім того, їх можна об'єднати у парсінг без сканування. Аналізатори можуть бути запрограмовані вручну або автоматично, або напів автоматично генератором парсерів.[1] Розбір допомагає шаблону, який виробляє відформатований вихід. Вони можуть використовуватись у різних ділянках, але часто з'являються разом, наприклад, пара scanf/printf, або як вхідний (аналіз вхідних даних) та вихідний етапи (створення кінцевого коду) компілятора.
Вхідними даними для синтаксичного аналізатора часто є текст деякою комп'ютерною мовою, але також може бути текстом природною мовою або менш структурованими текстовими даними, в цьому випадку, як правило, витягуються лише окремі частини тексту, а не дерево розбору. Параметри відрізняються від дуже простих функцій, таких як scanf, до складних програм, таких як інтерфейс компілятора C++ або HTML-аналізатор веб-браузера. Важливий клас простий синтаксичний аналіз виконується за допомогою регулярних виразів, в яких група регулярних виразів визначає регулярну мову та двигун регулярного виразу, автоматично генеруючи аналізатор для цієї мови, що дозволяє узгодити шаблон та вилучення тексту. В інших контекстах регулярні вирази замість цього використовуються перед розбором, як етап лексизації, вихід якого потім використовується аналізатором.
Використання аналізаторів залежить від вхідних даних. У випадку з мовами даних часто використовується синтаксичний аналізатор як функція читання файлів у програмі, наприклад, читання в HTML або XML-тексті; ці приклади є мовами розмітки даних. У випадку мов програмування є компонентом компілятора або інтерпретатора, який аналізує початковий код мови комп'ютерного програмування для створення певної форми внутрішнього представлення; аналізатор є ключовим кроком в інтерфейсі компілятора. Мови програмування, як правило, вказуються в термінах детерміністичної контекстно-вільної граматики, оскільки для них можуть бути написані швидкі та ефективні аналізатори. Для компіляторів сам аналіз може бути виконаний за один прохід або кілька проходів — див. одно-прохідний компілятор і багатопрохідний компілятор.
Майбутні недоліки компілятора з одним прохідним процесом у значній мірі можуть бути вирішені шляхом додавання виправлень, коли передбачається виправлення впродовж прямого переходу, а виправлення застосовуються в зворотньому напрямку, коли поточний сегмент програми є таким, що має бути завершений. Прикладом, коли такий механізм виправлення може бути корисним, є формальне твердженням GOTO, де вказівник GOTO невідомий, доки не буде пройдено сегмент програми. У такому випадку застосування виправлення буде відкладено, доки не буде визначено куди вказує GOTO. Очевидно, що відсталий GOTO не вимагає виправлення.
Контекстні граматики обмежені тією мірою, в якій вони можуть виразити всі вимоги до мови. Неформально причиною є те, що пам'ять в такій мові обмежена. Граматика не запам'ятовує існування конструкції над довільним введенням; це необхідно для мови, в якій, наприклад, ім'я повинно бути оголошено, перш ніж може бути посилання на нього. Однак більш потужні граматики, які можуть обійти це обмеження, не можуть бути ефективно розібрані. Таким чином, загальною стратегією є створення аналізатора для контекстно-вільної граматики, який приймає потрібні конструкції мови (тобто він приймає деякі недійсні конструкції); пізніше, небажані конструкції можуть бути відфільтровані на етапі семантичного аналізу (контекстного аналізу).
Наприклад, в Python такий синтаксичний код:
x = 1
print(x)
Такий код, однак, є синтаксично правильним з точки зору контекстної граматики, яка дає дерево синтаксису з тією ж структурою, що і попередня, але є синтаксично недійсною з точки зору контекстно-залежної граматики, яка вимагає, щоб змінні були ініціалізовані раніше використання:
x = 1
print(y)
Замість того, щоб аналізувати на етапі парсинга, це відбувається шляхом перевірки значень в дереві синтаксису, отже, як частина семантичного аналізу: контекстно-залежний синтаксис на практиці часто більш легко аналізується, ніж семантика.
Огляд процесу
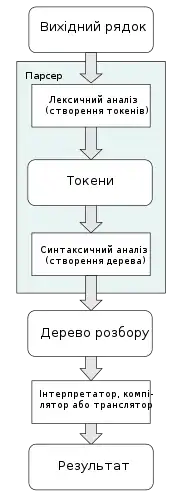
Наведений нижче приклад демонструє загальний випадок розбору комп'ютерної мови з двома рівнями граматики: лексичної та синтаксичної.
Перший етап — генерація токенів або лексичний аналіз, за допомогою яких потік вхідних символів поділяється на значущі символи, визначені граматикою регулярні вирази. Наприклад, програма калькулятора буде отримувати на вхід, такий рядок "12 * (3 + 4)^2" і розділити його на токени 12, *, (, 3, +, 4, ), ^, 2, кожен з яких є значущим символом в контексті арифметичного виразу. Лексери міститимуть правила, які вказують на те, що символи *, +, ^, ( і ) позначають початок нового токену, так що незначні токени типу"12*" або "(3" не будуть створені).
Наступним етапом є парсинг чи синтаксичний аналіз, який перевіряє, чи токени утворюють допустимий вираз. Це, як правило, робиться з посиланням на контекстну граматику, яка рекурсивно визначає компоненти, які можуть скласти вираз та порядок їх появи. Проте не всі правила, що визначають мови програмування, можуть бути виражені контекстно-вільними граматиками, наприклад, дійсність типу та правильне декларування ідентифікаторів. Ці правила можуть бути формально виражені атрибутивними граматики.
Заключна фаза - це семантичний аналіз або парсинг, який розробляє наслідки тільки що підтвердженого вираження та вживання відповідних заходів. У випадку калькулятора чи інтерпретатора дія полягає в оцінці виразу або програми, а компілятор, з іншого боку, генерує якийсь код. Атриматичні граматики також можуть бути використані для визначення цих дій.
Типи аналізаторів
Завдання аналізатора по суті полягає в тому, щоб визначити, як вхід можна отримати з початкового символу граматики. Це можна зробити по суті двома способами:
- Низхідний синтаксичний аналіз — аналіз згори донизу можна розглядати як спробу знайти найбільший початок z слова x, що може бути початком слова, що виводиться, шляхом пошуку в синтаксичному дереві за допомогою розгорнення згори донизу заданих формальних правил граматики. Токени читаються зліва направо. Інклюзивний вибір використовується для задоволення багатозначності шляхом розширення всіх альтернативних правих правил граматики.[2]
- Синтаксичний аналіз знизу — Синтаксичний аналізатор може початися з введення та спробувати переписати символ на його початку. Інтуїтивно, синтаксичний аналізатор намагається знайти найдовші основні елементи, потім елементи, що містять їх, і так далі. Аналізатор LR є прикладами аналізаторів знизу вгору. Іншим терміном, що використовують для цього типу аналізатора, є Shift-Reduce, синтаксичний аналіз.
LL-аналізатор та рекурсивний спуск є прикладами аналізаторами згори-вниз, які не можуть враховувати ліву рекурсію. Хоча вважалося, що прості реалізації синтаксичного аналізу зверху вниз не можуть враховувати пряму та непряму ліву рекурсію і можуть вимагати експоненціального часу та просторово складності під час аналізу неоднозначних контекстно-вільних граматик, складніші алгоритми для розбору зверху вниз створюються Frost, Hafiz, і Callaghan[3][4], які враховують багатозначність і ліва рекурсія в поліноміальному часі і які генерують поліноміальне представлення потенційно експоненціального числа дерев розбору. Їхній алгоритм здатний виготовити як ліві, так і правомірні похідні вхідних даних щодо цієї контекстно-вільної граматики.
Примітки
- Example Domain. www.example.com. Процитовано 24 листопада 2017.
- Aho, A.V., Sethi, R. and Ullman, J.D. (1986) « Compilers: principles, techniques, and tools.» Addison-Wesley Longman Publishing Co., Inc. Boston, MA, USA.
- Frost, R., Hafiz, R. and Callaghan, P. (2007) « Modular and Efficient Top-Down Parsing for Ambiguous Left-Recursive Grammars .» 10th International Workshop on Parsing Technologies (IWPT), ACL-SIGPARSE , Pages: 109—120, June 2007, Prague.
- Frost, R., Hafiz, R. and Callaghan, P. (2008) « Parser Combinators for Ambiguous Left-Recursive Grammars.» 10th International Symposium on Practical Aspects of Declarative Languages (PADL), ACM-SIGPLAN , Volume 4902/2008, Pages: 167—181, January 2008, San Francisco.
Див. також
- Формальні граматики
- Алгоритм Ерлі
- Алгоритм сортувальної станції
- Синтаксичний аналіз «зверху-вниз»
- LR-граматики
- Рекурсивний спуск
- Синтаксичний розбір «знизу-вверх»
- Граматики передування
- Парсери мови Java
- Поверхнево-синтаксичний аналіз
