Система нечіткого виведення
Система нечіткого виведення (англ. fuzzy inference system) – система логічного виведення, яка базується на алгоритмі отримання нечітких висновків на основі нечітких передумов з використанням понять нечіткої логіки[1]. Процес нечіткого виведення поєднує в собі всі основні концепції теорії нечітких множин: функції належності, лінгвістичні змінні, нечіткі логічні операції, методи нечіткої імплікації і нечітку композиції. Системи нечіткого виведення дозволяють вирішувати завдання автоматичного керування, класифікації даних, розпізнавання образів, прийняття рішень, машинного навчання та багато інших.
Основні етапи нечіткого виведення
Системи нечіткого виводу призначені для перетворення значень вхідних змінних процесу у вихідні змінні на основі використання нечітких продукційних правил. Для цього системи нечіткого виведення повинні містити базу правил нечітких продукцій і реалізовувати нечітке виведення на основі посилок або умов, поданих у формі нечітких лінгвістичних висловлювань.
Основні етапи нечіткого виводу зображені на рисунку 1.
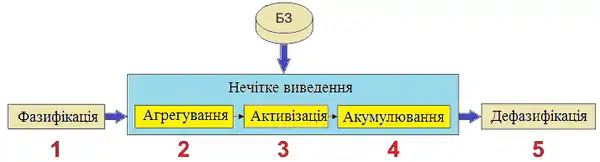
Формування бази знань у вигляді продукційних правил
База правил систем нечіткого виводу призначена для формального зображення емпіричних знань або знань експертів в тій чи іншій проблемній області. У системах нечіткого виведення використовуються правила нечітких продукцій, в яких умови і висновки сформульовані в термінах нечітких лінгвістичних висловлювань.
Сукупність таких правил будемо далі називати базою правил нечітких продукцій. База правил нечітких продукцій є кінцевою множиною правил нечітких продукцій, узгоджених щодо використовуваних в них лінгвістичних змінних. Найбільш часто база правил представляється в формі структурованого тексту:

ПРАВИЛО_2: ЯКЩО «умова_2, ТО висновок_2» (),

…
ПРАВИЛО_n: ЯКЩО «умова_n, ТО висновок_n» (),
де – вагові коефіцієнти відповідних правил. Ці коефіцієнти можуть приймати значення з інтервалу [0, 1]. У разі, якщо ці вагові коефіцієнти відсутні, зручно прийняти, що їх значення дорівнює 1.

У системах нечіткого виведення лінгвістичні змінні, які використовуються в нечітких висловлюваннях передумови правил нечітких продукцій, часто називають вхідними лінгвістичними змінними, а змінні, які використовуються в нечітких висловлюваннях висновків правил нечітких продукцій, називають вихідними лінгвістичними змінними.
Фазифікація вхідних змінних
В контексті нечіткої логіки під фазифікацією розуміють не тільки окремий етап виконання нечіткого виведення, а й власне процес або процедуру знаходження значень функцій належності нечітких множин (термів) на основі звичайних (НЕ нечітких) вихідних даних. Фазифікацію ще називають введенням нечіткості.
Метою етапу фазифікації є встановлення відповідності між конкретним (зазвичай чисельним) значенням окремої вхідної змінної системи нечіткого виведення і значенням функції належності відповідного їй терма вхідної лінгвістичної змінної. Після завершення цього етапу для всіх вхідних змінних повинні бути визначені конкретні значення функцій належності по кожному з лінгвістичних термів, використаних в передумовах бази правил системи нечіткого виведення.
Агрегування передумов в нечітких продукційних правилах.
Агрегування (англ. aggregation) являє собою процедуру визначення ступеня істинності умов по кожному з правил системи нечіткого виведення. Формально процедура агрегування виконується наступним чином.
До початку цього етапу передбачаються відомими значення істинності всіх передумов системи нечіткого виведення, тобто множина значень . Далі розглядають кожну з умов правил системи нечіткого виведення. Якщо умова складається з декількох передумов, то визначається ступінь істинності складного висловлювання на основі відомих значень істинності передумов.

При цьому, для визначення результату нечіткої кон'юнкції або зв'язки «І» може бути використана одна з формул:
логічна кон'юнкція:
алгебраїчний добуток:
граничний добуток:
драстичний добуток:




де – функції належності нечітких висловлювань А та В відповідно.

Для визначення результату нечіткої диз'юнкції або зв'язки «АБО» може бути використана одна з формул:
логічна диз'юнкція:
алгебраїчна сума:
гранична сума:
драстична сума:




де – функції належності нечітких висловлювань А та В відповідно.
При цьому значення використано як аргументи відповідних логічних операцій. Тим самим знаходяться кількісні значення істинності всіх умов правил системи нечіткого виведення.

Етап агрегування вважається закінченим, коли будуть знайдені всі значення для кожного з правил, що входять в базу правил системи нечіткого виведення.
Для ілюстрації виконання цього етапу розглянемо приклад процесу агрегування двох нечітких висловлювань:
«швидкість автомобіля середня» І «кава гаряча» та
«швидкість автомобіля середня» АБО «кава гаряча»
для вхідної лінгвістичної змінної "швидкість руху автомобіля" та "температура кави".
Припустимо, що поточна швидкість автомобіля дорівнює 55 км/год, тобто , а температура кави дорівнює 70°, тобто . Тоді агрегування першого нечіткого висловлювання з використанням операції нечіткої кон'юнкції дає в результаті число (наближене значення), яке означає його ступінь істинності та визначається як мінімальне зі значень 0.67 та 0.8 (рис. 2, а). Агрегування другого нечіткого висловлювання з використанням операції нечіткої диз'юнкції дає в результаті число , яке означає його ступінь істинності та визначається як максимальне зі значень 0.67 та 0.8 (рис. 2, б).




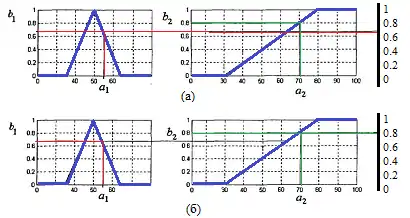
Активізація або композиція висновків в нечітких продукційних правилах
Активізація (англ. activation) в системах нечіткого виведення являє собою процедуру або процес знаходження ступеня істинності кожного з висновків правил нечітких продукцій. Формально процедура активізації виконується наступним чином.
До початку цього етапу передбачено відомими значення істинності всіх передумов системи нечіткого виведення, тобто множина значень та значення вагових коефіцієнтів для кожного правила. Далі розглядається кожне з висновків правил системи нечіткого виведення. Якщо висновком правила є нечітке висловлювання, то ступінь його істинності дорівнює алгебраїчному добутку відповідного значення на ваговий коефіцієнт.
Таким чином, знаходяться всі значення ступенів істинності висновків для кожного з правил, що входять в дану базу правил системи нечіткого виведення. Цю множину значень позначимо через , де – загальна кількість висновків в базі правил.


Після знаходження множини визначаються функції належності кожного з висновків для розглянутих вихідних лінгвістичних змінних.
Для цієї мети можна використовувати один з методів, які є модифікацією того чи іншого методу нечіткої композиції:
min-активізація:
prod-активізація:
average-активізація:



де – функція належності терму, який є значенням деякої вихідної змінної, заданої на універсумі .


Етап активізації вважається закінченим, коли для кожної з вихідних лінгвістичних змінних, що входять в окремі висновки правил нечітких продукцій, будуть визначені функції належності нечітких множин їх значень, тобто сукупність нечітких множин: , де – загальна кількість висновків в базі правил системи нечіткого виведення.

Для ілюстрації виконання цього етапу розглянемо приклад процесу активізації укладення в наступному правилі нечіткої продукції:
ЯКЩО «швидкість автомобіля середня», ТО «кава гаряча».
Вхідною лінгвістичною змінною в цьому правилі є "швидкість руху автомобіля", а вихідною змінної є "температура кави". Припустимо, що поточна швидкість автомобіля дорівнює 55 км/год, тобто .
Оскільки агрегування умови цього правила дає в результаті , а ваговий коефіцієнт дорівнює 1 (за замовчуванням), то значення 0.67 буде використовуватися як для отримання результату активізації.

На рис. 3 (а) зеленим кольором зображено результат, отриманий методом min-активізації, а на рис. 3 (б) – результат, отриманий методом pгod-активізації. Слід пам'ятати, що в цьому прикладі на відміну від попереднього «температура кави» – вихідна лінгвістична змінна.

Акумулювання висновків нечітких продукційних правил
Акумуляція або акумулювання (англ. accumulation) в системах нечіткого виведення являє собою процедуру або процес знаходження функції належності для кожної з вихідних лінгвістичних змінних множини.
Мета акумуляції полягає в тому, щоб об'єднати або акумулювати всі ступені істинності висновків для отримання функції належності кожної з вихідних змінних. Причина необхідності виконання цього етапу полягає в тому, що висновки, які відносяться до однієї і тієї ж вихідної лінгвістичної змінної, належать різним правилам системи нечіткого виведення. Формально процедура акумуляції виконується наступним чином.
До початку цього етапу передбачаються відомими значення істинності всіх висновків для кожного з правил, що входять в дану базу правил системи нечіткого виведення, в формі сукупності нечітких множин: , де – загальна кількість висновків в базі правил. Далі послідовно розглядається кожна з вихідних лінгвістичних змінних і пов'язані з нею нечіткі множини. Результат акумуляції для вихідної лінгвістичної змінної визначається як об'єднання нечітких множин за однією з формул:

логічна диз'юнкція:
алгебраїчна сума:
гранична сума:
де – функції належності нечітких висловлюваннь А та В відповідно.
Етап акумуляції вважається закінченим, коли для кожної з вихідних лінгвістичних змінних будуть визначені підсумкові функції належності нечітких множин їх значень, тобто сукупність нечітких множин: , де – загальна кількість вихідних лінгвістичних змінних в базі правил системи нечіткого виведення.


Для ілюстрації виконання цього етапу розглянемо приклад процесу акумуляції висновків для трьох нечітких множин, отриманих в результаті виконання процедури активізації для вихідної лінгвістичної змінної «швидкість руху автомобіля» в деякій системі нечіткого виведення. Припустимо, що функції належності цих нечітких множин зображені на рис. 4 (а), (б) та (в) відповідно.
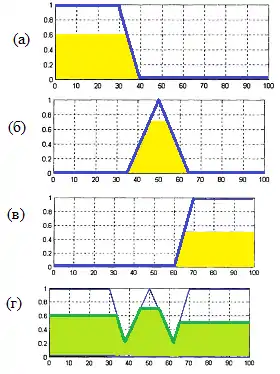
Акумуляція цих функцій належності шляхом max-об'єднання нечітких множин дозволяє отримати в результаті функцію належності вихідної лінгвістичної змінної «швидкість руху автомобіля», яка представлена на рис. 4 (г).
Дефазифікація вихідної змінної
Дефазифікація в системах нечіткого виведення являє собою процедуру або процес знаходження звичайного (НЕ нечіткого) значення для кожної з вихідних лінгвістичних змінних. Мета дефазифікації полягає в тому, щоб, використовуючи результати акумуляції всіх вихідних лінгвістичних змінних, отримати звичайне кількісне значення (crisp value) кожної з вихідних змінних, яке може бути використане спеціальними пристроями, що не належать до системи нечіткого виведення.
Основні алгоритми нечіткого виведення
Розглянуті вище етапи нечіткого виводу можуть бути реалізовані неоднозначним чином, оскільки включають в себе окремі параметри, які повинні бути фіксовані або специфіковані. Тим самим вибір конкретних варіантів параметрів кожного з етапів визначає алгоритм, який в повному обсязі реалізує нечіткий висновок в системах правил нечітких продукцій. До теперішнього часу запропоновано кілька алгоритмів нечіткого виведення[2]. Ті з них, які отримали найбільше застосування в системах нечіткого виведення, розглядаються нижче.
Алгоритм Мамдані (Mamdani)
Алгоритм Мамдані є одним з перших, який знайшов застосування в системах нечіткого виведення. Він був запропонований у 1975 році англійським математиком Е. Мамдані (Ebrahim Mamdani) як метод для управління паровим двигуном[3]. За своєю суттю цей алгоритм породжує розглянуті вище етапи, оскільки найбільшою мірою відповідає їх параметрам.
У моделі Мамдані математично взаємозв'язок між входами та виходом визначається нечіткою базою правил наступного формату:



де – лінгвістичний терм, яким оцінюється змінна в рядку з номером ;



– кількість рядків-кон'юнкція, в яких вихід оцінюється лінгвістичним термом ;


– кількість термів, що використовуються для оцінки вихідної лінгвістичної змінної.

За допомогою операцій ᑌ (АБО) та ᑎ (І) нечітку базу правил можна переписати в більш компактному вигляді:

Логічний висновок, згідно з алгоритмом Мамдані, здійснюється за такі шість етапів:
1. Формування бази правил систем нечіткого виводу у наступному вигляді:
ПРАВИЛО <1>: ЯКЩО ( є І є ), ТО, ,




ПРАВИЛО <2>: ЯКЩО ( є І є ), ТО, ,



де ౼ вхідні лінгвістичні змінні;

౼ вихідна лінгвістична змінна;

౼ функції належності, визначені відповідно на .


2. Введення нечіткості (фазифікація). Функції належності, що визначенні на вхідних змінних , застосовуються до їх фактичних значень для визначення функції належності для кожного правила.


3. Агрегування передумов в нечітких правилах продукцій. Для знаходження ступеня істинності умов кожного з правил нечітких продукцій використовуються парні нечіткі логічні операції:
, .


Ті правила, ступінь істинності умов яких відмінна від нуля, вважаються активними і використовуються для подальших розрахунків.
4. Активізація висновків нечітких правилах продукцій. Здійснюється за формулою , коли функція належності виведення «відсікається» по висоті відповідно обчисленої функції належності передумови правила (нечітка логіка «І»):

, .


При цьому для скорочення часу виведення враховуються тільки активні правила нечітких продукцій.
5. Акумуляція висновків нечітких правил продукцій. Всі нечіткі підмножини, отримані для кожної вихідної змінної (у всіх правилах), об'єднуються разом, щоб сформувати одну нечітку підмножину для кожної вихідної змінної. При подібному об'єднанні використовуються операції:
max: або
sum: .


6. Приведення до чіткості (дефазифікації). Дана процедура використовується, коли необхідно перетворити нечітку вихідну множину в чітке число. Найчастіше для моделі Мамдані використовується дефазифікація центроїдним методом, коли чітке значення вихідної змінної визначається як центр ваги для кривої .

Процедура отримання логічного висновку показана на рис. 5.
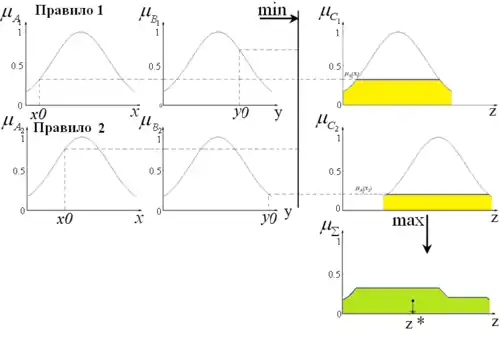
Алгоритм Цукамото (Tsukamoto)
Формально алгоритм Цукамото може бути визначений таким чином.
- Формування бази правил системи нечіткого виводу. Особливості формування бази правил збігаються з розглянутими вище при описі даного етапу.
- Фазифікація вхідних змінних. Особливості фазифікації збігаються з розглянутими вище при описі даного етапу.
- Агрегування передумов в нечітких правилах продукцій. Для знаходження ступеня істинності умов всіх правил нечітких продукцій використовуються парні нечіткі логічні операції. Ті правила, ступінь істинності умов яких відмінна від нуля, вважаються активними і використовуються для подальших розрахунків.
- Активізація висновків в нечітких правилах продукцій. Здійснюється аналогічно алгоритму Мамдані за формулою , після чого знаходяться звичайні (НЕ нечіткі) значення всіх вихідних лінгвістичних змінних в кожному з висновків активних правил нечітких продукцій. У цьому випадку значення вихідної лінгвістичної змінної у кожному з висновків знаходиться як розв'язок рівняння:де – загальна кількість висновків в базі правил.
- Акумуляція висновків нечітких правил продукцій. Фактично відсутня, оскільки розрахунки здійснюються із звичайними дійсними числами.
- Дефазифікація вихідних змінних. Використовується модифікований варіант у формі метода центру тяжіння для одноточкових множин:де – загальна кількість активних правил нечітких продукцій, в висновках яких присутня вихідна лінгвістична змінна .





Приклад алгоритму Цукамото для функцій належності та результатів активізації:






Розглянемо результат нечіткого виведення для та : на рисунку 6.





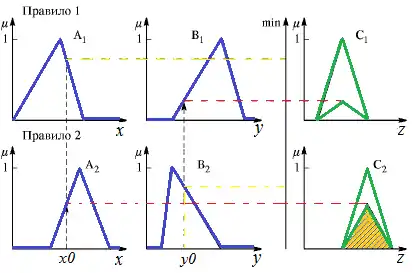
Алгоритм Ларсена (Larsen)
Формально алгоритм Ларсена може бути визначений таким чином.
- Формування бази правил систем нечіткого виводу. Особливості формування бази правил збігаються з розглянутими вище при описі даного етапу.
- Фазифікація вхідних змінних. Особливості фазифікації також збігаються з розглянутими вище при описі даного етапу.
- Агрегування передумов в нечітких правилах продукцій. Використовуються парні нечіткі логічні операції для знаходження ступеня істинності умов всіх правил нечітких продукцій (як правило, mах-диз'юнкція і min-кон'юнкція ). Ті правила, ступінь істинності умов яких відмінна від нуля, вважаються активними і використовуються для подальших розрахунків.
- Активізація висновків в нечітких правилах продукцій. Здійснюється використанням формули , за допомогою чого знаходиться сукупність нечітких множин: , де – загальна кількість висновків в базі правил.
- Акумуляція висновків нечітких правил продукцій. Здійснюється за формулою для об'єднання нечітких множин, що відповідають термам висновків, які відносяться до одних і тих самих вихідних лінгвістичних змінних.
- Дефазифікація вихідних змінних. Може використовуватися будь-який з методів дефазифікації.


На рисунку 7 наведено приклад алгоритму Ларсена.
Алгоритм Сугено (Sugeno)
Формально алгоритм Сугено, запропонований Сугено і Такагі, може бути визначений таким чином.
1. Формування бази правил систем нечіткого виводу. У базі правил використовуються тільки правила нечітких продукцій в формі:
ПРАВИЛО <1>: ЯКЩО ( є І є ), ТО, , ПРАВИЛО <2>: ЯКЩО ( є І є ), ТО, ,


де ౼вхідні змінні;

౼ чисельні значення вхідних параметрів;

౼ довільна чітка функція.
Приклад алгоритму Сугено 1-порядку наведено на рисунку 8.
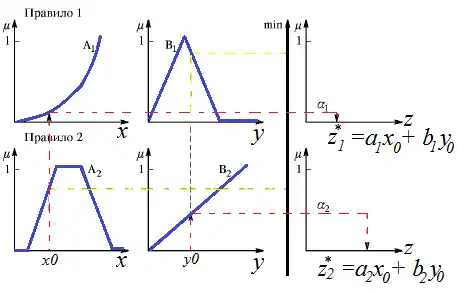
На рисунку 8 видно, що виходами правил є функції: та . Таким чином, результат дефазифікації обчислюється наступним чином:



Якщо як опція використовується поліном , то говорять про алгоритм Сугено 0-порядку. Тоді правила будуть мати такий вигляд:


ПРАВИЛО <1>: ЯКЩО ( є І є ), ТО, , ПРАВИЛО <2>: ЯКЩО ( є І є ), ТО, ,


де ౼ звичайні (чіткі) числа.

2. Фазифікація вхідних змінних. На цьому етапі усім відомим конкретним значенням вхідних змінних системи нечіткого виведення ставлять у відповідність нечітку множину, тобто множину значень .

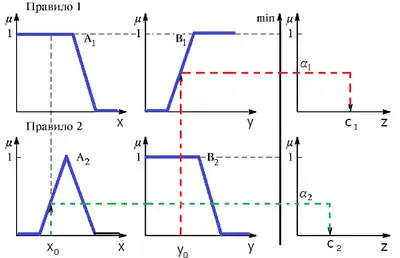
3. Агрегування передумов в нечітких правилах продукцій. Для знаходження міри істинності умов всіх правил нечітких продукцій, як правило, використовують логічну операція min-кон'юнкції. Ті правила, ступінь істинності умов яких відмінна від нуля, вважають активними й використовують для подальших розрахунків.
4. Активізація висновків в нечітких правилах продукцій. Для заданого (чіткого) значення аргументу знаходяться ступені істинності для передумов кожного правила. Далі знаходяться значення ступенів істинності всіх висновків правил нечітких продукцій з використанням методу min-активізації:


5. Акумуляція висновків нечітких правил продукцій. Фактично відсутня, оскільки розрахунки здійснюються зі звичайними дійсними числами . 6. Дефазифікація вихідних змінних. Використовується модифікований варіант у формі метода центру тяжіння для одноточкових множин:


де – загальна кількість активних правил нечітких продукцій.
Ілюстрація алгоритму Сугено 0-порядку представлена на рисунку 9.
Порівняння систем нечіткого виведення
Алгоритми нечіткого виведення розрізняються видом використовуваних правил логічних операцій і способом дефазифікації, а вибір моделі визначається, як правило, характером вирішуваних завдань. При цьому необхідно враховувати таке:
- якщо значення всіх вхідних змінних знаходяться в одному діапазоні і не вимагають масштабування, то немає потреби застосовувати модель Ларсена;
- якщо всі функції належності однорідні, то немає потреби застосовувати модель Цукамото;
- якщо результатом обчислення нечітких правил є проста нечітка множина, елементи якої не обчислені за допомогою спеціального функціоналу, то немає потреби застосовувати модель Сугено.
Див. також
Джерела інформації
- Желдак Т.А.; Коряшкіна Л.С.; Ус С.А. (2020). Нечіткі множини в системах управління та прийняття рішень: Навчальний посібник. Дніпро: НТУ «Дніпровська політехніка».
Примітки
- Леоненков, А. В. Нечеткое моделирование в среде MATLAB и fuzzyTECH / А.В. Леоненков. – СПб.: БХВ-Петербург, 2005. – 736 с.
- Круглов, В. В. Нечеткая логика и искусственные нейронные сети / В. В. Круглов, М. И. Дли, Р. Ю. Голунов. – М.: ФИЗМАТЛИТ, 2001. – 201с.
- Mamdani, E. H., Application of fuzzy algorithms for the control of a simple dynamic plant. In Proc IEEE (1974), 121–159.