Машинне навчання
Машинне навчання (англ. machine learning) — це підгалузь штучного інтелекту в галузі інформатики, яка часто застосовує статистичні прийоми для надання комп'ютерам здатності «навчатися» (тобто, поступово покращувати продуктивність у певній задачі) з даних, без того, щоби бути програмованими явно.[1]
Назву «машинне навчання» (англ. machine learning) було започатковано 1959 року Артуром Семюелем.[2] Еволюціонувавши з досліджень розпізнавання образів та теорії обчислювального навчання в галузі штучного інтелекту,[3] машинне навчання досліджує вивчення та побудову алгоритмів, які можуть навчатися й робити передбачення з даних,[4] — такі алгоритми долають слідування строго статичним програмним інструкціям, здійснюючи керовані даними прогнози або ухвалювання рішень[5] шляхом побудови моделі з вибіркових входів. Машинне навчання застосовують в ряді обчислювальних задач, в яких розробка та програмування явних алгоритмів з доброю продуктивністю є складною або нездійсненною; до прикладів застосувань належать фільтрування електронної пошти, виявляння мережних вторгників або зловмисних інсайдерів, що добуваються витоку даних,[6] оптичне розпізнавання символів (ОРС),[7] навчання ранжуванню та комп'ютерний зір.
Машинне навчання тісно пов'язане (та часто перетинається) з обчислювальною статистикою, яка також зосереджується на прогнозуванні шляхом застосування комп'ютерів. Воно має тісні зв'язки з математичною оптимізацією, яка забезпечує цю галузь методами, теорією та прикладними областями. Машинне навчання іноді об'єднують з добуванням даних,[8] де друга підгалузь фокусується більше на розвідувальному аналізі даних, і є відомою як навчання без учителя.[5][9] Машинне навчання також може бути спонтанним,[10] і застосовуваним для навчання та встановлення базових характерів поведінки різних суб'єктів,[11] а потім застосовуваним для пошуку виразних аномалій.
В межах галузі аналізу даних машинне навчання є методом, який застосовують для винаходження складних моделей та алгоритмів, які слугують прогнозуванню — в комерційному застосуванні це відоме як передбачувальна аналітика. Ці аналітичні моделі дозволяють дослідникам, науковцям з даних, інженерам та аналітикам «виробляти надійні, повторювані рішення та результати» та розкривати «приховані розуміння» шляхом навчання з історичних співвідношень та тенденцій в даних.[12]
Огляд
Том Мітчелл запровадив широко цитоване формальніше визначення алгоритмів, що їх досліджують у галузі машинного навчання: «Кажуть, що комп'ютерна програма вчиться з досвіду E по відношенню до якогось класу задач T та міри продуктивності P, якщо її продуктивність у задачах з T, вимірювана за допомогою P, покращується з досвідом E.»[13] Це визначення задач, якими займається машинне навчання, пропонує фундаментально операційне визначення, замість визначати цю галузь в когнітивних термінах. Це слідує пропозиції Алана Тюрінга в його праці «Обчислювальні машини та розум», у якій питання «Чи можуть машини думати?» замінюється питанням «Чи можуть машини робити те, що можемо робити ми (як істоти, які думають)?».[14] У пропозиції Тюрінга викладено різні характеристики, які може демонструвати «машина, що думає», та різні наслідки для побудові такої.
Задачі машинного навчання
Задачі машинного навчання, як правило, поділяють на дві широкі категорії, залежно від того, чи доступний системі, що навчається, навчальний «сигнал», або «зворотний зв'язок»:
- Навчання з учителем (кероване навчання, англ. supervised learning): Комп'ютерові представляють приклади входів та їхніх бажаних виходів, задані «вчителем», і метою є навчання загального правила, яке відображає входи на виходи. В окремих випадках вхідний сигнал може бути доступним лише частково, або бути обмеженим особливим зворотним зв'язком:
- Напівавтоматичне навчання (англ. semi-supervised learning): комп'ютерові дають лише неповний тренувальний сигнал: тренувальний набір, в якому відсутні деякі (часто численні) цільові виходи.
- Активне навчання (англ. active learning): комп'ютер може отримувати тренувальні мітки лише для обмеженого набору екземплярів (залежно від бюджету), а також має оптимізувати свій вибір об'єктів для отримування міток. За інтерактивного застосування, вони можуть надаватися для мічення користувачеві.
- Навчання з підкріпленням (англ. reinforcement learning): тренувальні дані (у вигляді винагород та покарань) надаються лише як зворотний зв'язок на дії програми в динамічному середовищі, як при керуванні автомобілем, або грі в гру з опонентом.[5]
- Навчання без учителя (спонтанне навчання, англ. unsupervised learning): Алгоритмові навчання не дається міток, залишаючи його самому знаходити структуру в своєму вході. Навчання без учителя може бути метою саме по собі (виявлення прихованих закономірностей у даних), або засобом досягнення мети (навчання ознак).
Застосування машинного навчання
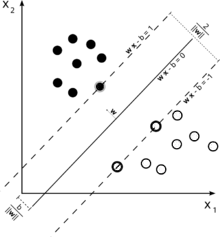
Інша класифікація завдань машинного навчання виникає при розгляді бажаного виходу системи з машинним навчанням:[5]
- У класифікації (англ. classification) входи поділяються на два або більше класів, і система-учень мусить породити модель, яка відносить небачені входи до одного або більше (багатоміткова класифікація) з цих класів. Це, як правило, намагаються розв'язувати керованим чином. Прикладом класифікації є фільтри спаму, в яких входами є повідомлення електронної пошти (або чогось іншого), а класами є «спам» та «не спам».
- У регресії (англ. regression), також керованій задачі, виходи є безперервними, а не дискретними.
- У кластеруванні (англ. clustering) набір входів повинно бути поділено на групи. На відміну від класифікації, групи не відомі заздалегідь, що зазвичай робить це завданням для спонтанного навчання.
- Оцінка густини знаходить розподіл входів у деякому просторі.
- Зниження розмірності спрощує входи шляхом відображення їх на простір меншої розмірності. Пов'язаною задачею є тематичне моделювання, в якому програмі надають перелік документів людською мовою, і ставлять задачу з'ясувати, які документи охоплюють подібні теми.
Серед інших задач машинного навчання навчання навчатися навчається свого власного індуктивного упередження на основі попереднього досвіду. Еволюційне навчання (англ. developmental learning), розроблене для навчання роботів, породжує свої власні послідовності навчальних ситуацій (також звані навчальним планом, англ. curriculum), щоби накопичувально отримувати репертуари нових навичок шляхом автономного само-дослідження та соціальної взаємодії з вчителями-людьми, і застосування провідних механізмів, таких як активне навчання, дозрівання, рухова синергія та імітація.
Історія та відношення до інших областей
Детальніші відомості з цієї теми ви можете знайти в статті Хронологія розвитку машинного навчання.
Артур Семюель, американський піонер у галузі комп'ютерних ігор та штучного інтелекту, започаткував термін «машинне навчання» 1959 року, будучи в IBM.[15] Як наукове прагнення, машинне навчання виросло з розшуків штучного інтелекту. Вже ранніми днями ШІ як академічної дисципліни деякі дослідники зацікавилися тим, щоби машини вчилися з даних. Вони намагалися наблизитися до розв'язання цієї задачі різними символьними методами, а також тим, що згодом було названо «нейронними мережами»; це були здебільшого перцептрони та інші моделі, які згодом виявилися повторними винаходами узагальнених лінійних моделей статистики.[16] Застосовувалося також і ймовірнісне міркування, особливо в автоматизованій медичній діагностиці.[17]
Проте зростання акценту на логічному, основаному на знаннях підході викликало розрив між ШІ та машинним навчанням. Ймовірнісні системи страждали на теоретичні та практичні проблеми збирання та представлення даних.[17] Близько 1980 року прийшли експертні системи, щоби домінувати над ШІ, а статистика була в немилості.[18] Робота над навчанням на основі символів/знань дійсно продовжувалася в межах ШІ, ведучи до індуктивного логічного програмування, але більш статистична лінія досліджень була тепер поза межами області справжнього ШІ, в розпізнаванні образів та інформаційному пошуку.[17] Приблизно в цей же час ШІ та інформатикою було облишено дослідження нейронних мереж. Цю лінію також було продовжено за межами області ШІ/інформатики, як «конекціонізм», дослідниками з інших дисциплін, включно з Хопфілдом, Румельхартом та Хінтоном. Їхній головний успіх прийшов у середині 1980-х років із повторним винайденням зворотного поширення.[17]
Машинне навчання, реорганізоване як окрема область, почало бурхливо розвиватися в 1990-х роках. Ця область змінила свої цілі з досягання штучного інтелекту на розв'язання розв'язних задач практичного характеру. Вона змістила фокус із символьних підходів, успадкованих нею від ШІ, в бік методів та моделей, позичених зі статистики та теорії ймовірності.[18] Вона також виграла від збільшуваної доступності оцифрованої інформації та можливості розповсюджування її через Інтернет.
Машинне навчання та добування даних часто використовують одні й ті ж методи, і значно перекриваються, але в той час як машинне навчання фокусується на передбаченні на основі відомих властивостей, вивчених з тренувальних даних, добування даних фокусується на відкритті невідомих (раніше) властивостей даних (це є кроком аналізу з відкривання знань у базах даних). Добування даних використовує багато методів машинного навчання, але з іншими цілями; з іншого боку, машинне навчання також застосовує методи добування даних як «навчання без учителя», або як крок попередньої обробки для покращення точності механізму навчання. Велика частина плутанини між цими двома дослідницькими спільнотами (які часто мають окремі конференції та окремі журнали, з ECML PKDD як основним винятком) виходить з основних припущень, з якими вони працюють: у машинному навчанні продуктивність зазвичай оцінюється по відношенню до здатності відтворювати відоме знання, тоді як у відкриванні знань та добуванні даних (англ. knowledge discovery and data mining, KDD) ключовою задачею є відкривання не відомого раніше знання. При оцінці по відношенню до відомих знань неінформований (некерований) метод легко програватиме іншим керованим методам, тоді як у типовій задачі KDD керовані методи застосовуватися не можуть в силу відсутності тренувальних даних.
Машинне навчання також має тісні зв'язки з оптимізацією: багато задач навчання формулюються як мінімізація деякої функції втрат на тренувальному наборі прикладів. Функції втрат виражають розбіжність між передбаченнями тренованої моделі та дійсними зразками задачі (наприклад, у класифікації потрібно призначати мітки зразкам, і моделі тренуються правильно передбачати попередньо призначені мітки набору прикладів). Різниця між цими двома областями виникає з мети узагальнення: в той час як алгоритми оптимізації можуть мінімізувати втрати на тренувальному наборі, машинне навчення зосереджене на мінімізації втрат на небачених зразках.[19]
Відношення до статистики
Машинне навчання та статистика є тісно пов'язаними областями. Згідно Майкла І. Джордана, ідеї машинного навчання, від методологічних принципів до теоретичних інструментів, мали довгу передісторію в статистиці.[20] Він також запропонував термін «наука про дані» для позначення загальної області.[20]
Лео Брейман виділив дві парадигми статистичного моделювання: модель даних, та алгоритмічну модель,[21] де «алгоритмічна модель» означає більш-менш алгоритми машинного навчання, такі як випадковий ліс.
Деякі фахівці зі статистики запозичили методи з машинного навчання, ведучи до об'єднаної області, яку вони називають статистичним навчанням (англ. statistical learning).[22]
Теорія
Детальніші відомості з цієї теми ви можете знайти в статті Теорія обчислювального навчання.
Основна мета системи, яка навчається, — це робити узагальнення зі свого досвіду.[5][23] Узагальнення в цьому контексті є здатністю машини, яка вчиться, працювати точно на нових, не бачених прикладах/задачах після отримання досвіду навчального набору даних. Тренувальні приклади походять з якогось загалом невідомого розподілу ймовірності (який вважається представницьким для простору випадків), і система, яка вчиться, має будувати загальну модель цього простору, яка дозволяє їй виробляти достатньо точні передбачення в нових випадках.
Обчислювальний аналіз алгоритмів машинного навчання та їхньої продуктивності є галуззю теоретичної інформатики, відомої як теорія обчислювального навчання (англ. computational learning theory). Оскільки тренувальні набори є скінченними, а майбутнє є непевним, теорія навчання зазвичай не дає гарантій продуктивності алгоритмів. Натомість доволі поширеними є ймовірнісні рамки продуктивності. Одним зі шляхів кількісної оцінки похибки узагальнення є компроміс зсуву та дисперсії.
Для найкращої продуктивності в контексті узагальнення складність гіпотези повинна відповідати складності функції, яка лежить в основі даних. Якщо гіпотеза є менш складною за цю функцію, то модель недопристосувалася до даних. Якщо у відповідь складність моделі підвищувати, то похибка тренування знижуватиметься. Але якщо гіпотеза є занадто складною, то модель піддається перенавчанню, й узагальнення буде гіршим.[24]
На додачу до рамок продуктивності, теоретики обчислювального навчання досліджують часову складність та здійсненність навчання. В теорії обчислювального навчання обчислення вважається здійсненним, якщо його може бути виконано за поліноміальний час. Є два види результатів часової складності. Позитивні результати показують, що певного класу функцій може бути навчено за поліноміальний час. Негативні результати показують, що певних класів не може бути навчено за поліноміальний час.
Підходи
Детальніші відомості з цієї теми ви можете знайти в статті Перелік алгоритмів машинного навчання.
Навчання дерев рішень
Навчання дерев рішень (англ. decision tree learning) використовує як передбачувальну модель дерево рішень, яке відображує спостереження про предмет на висновки про цільове значення предмету.
Навчання асоціативних правил
Навчання асоціативних правил (англ. association rule learning) є методом відкривання цікавих зв'язків між величинами у великих базах даних.
Штучні нейронні мережі
Алгоритм навчання штучної нейронної мережі (ШНМ, англ. artificial neural network, ANN), зазвичай званої «нейронною мережею» (НМ), є алгоритмом навчання, віддалено натхненим біологічними нейронними мережами. Обчислення структуруються в термінах взаємозв'язаних груп штучних нейронів, які обробляють інформацію із застосуванням конективістського підходу до обчислень. Сучасні нейронні мережі є нелінійними статистичними інструментами моделювання даних. Їх зазвичай застосовують для моделювання складних взаємозв'язків між входами та виходами, для пошуку закономірностей в даних, або для виявлення статистичної структури в невідомому спільному розподілі ймовірності спостережуваних величин.
Глибинне навчання
Падіння цін на апаратне забезпечення та розвиток графічних процесорів для особистого використання протягом останніх кількох років зробили свій внесок у розвиток поняття глибинного навчання (англ. deep learning), яке складається з кількох прихованих шарів штучної нейронної мережі. Цей підхід намагається моделювати спосіб, яким людський мозок обробляє світло та звук для зору та слуху. Деякими з успішних застосувань глибинного навчання є комп'ютерний зір та розпізнавання мовлення.[25]
Індуктивне логічне програмування
Детальніші відомості з цієї теми ви можете знайти в статті Індуктивне логічне програмування.
Індуктивне логічне програмування (ІЛП, англ. Inductive logic programming, ILP) є підходом до навчання правил із застосуванням логічного програмування як універсального представлення вхідних прикладів, зворотного поширення, та гіпотез. Маючи кодування відомого основного знання та набір прикладів, представлені як логічна база даних фактів, система ІЛП виводитиме гіпотетичну логічну програму, яка має наслідками всі позитивні й жодні з негативних прикладів. Пов'язаною областю є індуктивне програмування, яке для представлення гіпотез розглядає будь-які види мов програмування (а не лише логічне програмування), такі як функційні програми.
Метод опорних векторів
Метод опорних векторів (англ. support vector machines, SVMs) є набором пов'язаних методів навчання з учителем, які використовуються для класифікації та регресії. Маючи набір тренувальних прикладів, кожен з яких помічено як належний до однієї з двох категорій, алгоритм тренування методу опорних векторів будує модель, яка передбачує, чи новий приклад потрапляє до однієї категорії, чи до іншої.
Кластерування
Кластерний аналіз (англ. cluster analysis) є розподілом набору спостережень на підмножини (які називають кластерами), так, що спостереження в межах одного й того ж кластеру є подібними відповідно до деякого наперед встановленого критерію або критеріїв, в той час як спостереження, взяті з різних кластерів, є несхожими. Різні методики кластерування роблять різні припущення про структуру даних, часто визначені деякими мірами подібності, і оцінювані, наприклад, внутрішньою компактністю (подібністю членів одного й того ж кластеру) та відокремленістю між різними кластерами. Інші методи ґрунтуються на оцінюваній густині та зв'язності графу. Кластерування є методом навчання без учителя, і поширеною методикою статистичного аналізу даних.
Баєсові мережі
Баєсова мережа, мережа переконань, або спрямована ациклічна графова модель (англ. bayesian network, belief network, directed acyclic graphical model) — це ймовірнісна графова модель, яка представляє набір випадкових величин та їхніх умовних незалежностей через спрямований ациклічний граф. Наприклад, баєсова мережа може представляти ймовірнісні взаємозв'язки між хворобами та симптомами. Маючи в розпорядженні симптоми, таку мережу можна використовувати для обчислення ймовірностей наявності різних хвороб. Існують ефективні алгоритми для виконання висновування та навчання.
Навчання з підкріпленням
Навчання з підкріпленням (англ. reinforcement learning) переймається тим, як агент повинен вчиняти дії в середовищі таким чином, щоби максимізувати деяке уявлення про довготермінову винагороду. Алгоритми навчання з підкріпленням намагаються знайти політику, яка відображує стани світу на дії, які агент повинен вчиняти в цих станах. Навчання з підкріпленням відрізняється від навчання з учителем тим, що пари правильних входів/виходів йому ніколи не представляються, і не зовсім оптимальні дії ніколи явно не виправляються.
Навчання представлень
Декотрі алгоритми навчання, головно алгоритми навчання без учителя, мають на меті відкривання кращих представлень входів, наданих протягом тренування. Класичні приклади включають метод головних компонент та кластерний аналіз. Алгоритми навчання представлень (англ. representation learning) часто намагаються зберегти інформацію в своїх входах, але перетворити її таким чином, щоби зробити її зручною, часто як крок попередньої обробки перед виконанням класифікації або передбачень, уможливлюючи відбудову входів, які йдуть з невідомого розподілу, що породжує дані, й у той же час не будучи обов'язково точними для конфігурацій, які є малоймовірними за того розподілу.
Алгоритми навчання многовидів намагаються робити це за обмеження, щоби навчені представлення мали низьку розмірність. Алгоритми розрідженого кодування намагаються робити це за обмеження, щоби навчені представлення були розрідженими (мали багато нулів). Алгоритми навчання полілінійного підпростору мають на меті навчання представлень низької розмірності безпосередньо з тензорних представлень багатовимірних даних без перетворення їх на (багатовимірні) вектори.[26] Алгоритми глибинного навчання відкривають кілька рівнів представлення, або ієрархію ознак, в якій високорівневі, абстрактніші ознаки визначаються в термінах ознак нижчого рівня (або породжують їх). Було висловлено думку, що розумна машина — це така, яка навчається представлення, що розплутує чинники, які лежать в основі варіацій, що описують спостережувані дані.[27]
Навчання подібностей та мір
Детальніші відомості з цієї теми ви можете знайти в статті Навчання подібностей.
У цій задачі машині, яка навчається, надають пари прикладів, які розглядаються як подібні, і пари менш подібних об'єктів. Їй потрібно навчитися функції подібності (або функції міри відстані), яка може передбачувати, чи є нові об'єкти подібними. Це іноді використовується в рекомендаційних системах.
Навчання розріджених словників
Детальніші відомості з цієї теми ви можете знайти в статті Навчання розріджених словників.
В цьому методі дані представляються лінійною комбінацією базисних функцій, і передбачається, що коефіцієнти є розрідженими. Нехай x є d-вимірними даними, а D є матрицею d на n, кожен стовпчик якої представляє базисну функцію. r є коефіцієнтом для представлення x за допомогою D. З математичної точки зору, навчання розрідженого словника (англ. sparse dictionary learning) означає розв'язання , де r є розрідженим. Взагалі кажучи, передбачається, що n є більшим за d, щоби дати свободу для розрідженого представлення.

Навчання словника разом із розрідженим представленням є строго NP-складним, і є також складним і для наближеного розв'язання.[28] Популярним евристичним методом навчання розріджених словників є K-СРМ.
Навчання розріджених словників застосовувалося в кількох контекстах. У класифікації задачею є визначення, до яких класів належать раніше не бачені дані. Припустімо, що словник для кожного з класів вже було побудовано. Тоді нові дані асоціюються з таким класом, у словникові якого вони розріджено представлені найкраще. Навчання розріджених словників застосовувалося також у знешумлюванні зображень. Ключова ідея полягає в тому, що чистий клаптик зображення може бути розріджено представлено словником зображення, а шум — ні.[29]
Генетичні алгоритми
Генетичний алгоритм (ГА, англ. genetic algorithm, GA) — це евристичний алгоритм пошуку, який імітує процес природного добору, і використовує такі методи як мутація та схрещування для породження нового генотипу в надії знайти добрі розв'язки заданої задачі. В машинному навчанні генетичні алгоритми знаходили деякі застосування в 1980-х та 1990-х роках.[30][31] І навпаки, методики машинного навчання використовувалися для покращення продуктивності генетичних та еволюційних алгоритмів.[32]
Машинне навчання на основі правил
Машинне навчання на основі правил (англ. rule-based machine learning) — це загальний термін для будь-якого методу машинного навчання, що ідентифікує, навчається або виводить «правила» для зберігання, маніпулювання або застосування знань. Визначальною характеристикою системи машинного навчання на основі правил є ідентифікування та використання набору реляційних правил, які сукупно представляють знання, отримані системою. Це є протилежністю до інших систем машинного навчання, які зазвичай ідентифікують одиничну модель, яку для отримування передбачення можливо універсально застосовувати до будь-якого випадку.[33] До підходів машинного навчання на основі правил належать системи навчання класифікації, навчання асоціативних правил та штучні імунні системи.
Системи навчання класифікації
Детальніші відомості з цієї теми ви можете знайти в статті Система навчання класифікації.
Системи навчання класифікації (англ. learning classifier systems, LCS) — це сімейство алгоритмів машинного навчання на основі правил, які поєднують відкривальну складову (наприклад, зазвичай, генетичний алгоритм) з навчальною складовою (що виконує кероване навчання, навчання з підкріпленням, або спонтанне навчання). Вони прагнуть ідентифікувати набір контекстно-залежних правил, які сукупно зберігають та застосовують знання кусковим чином, щоби робити передбачення.[34]
Застосування
До застосувань машинного навчання належать:
- Автоматизоване доведення теорем[35][36]
- Адаптивні вебсайти[джерело?]
- Аналіз поведінки користувачів
- Аналіз тональності текстів (або добування поглядів)
- Аналіз фінансових ринків
- Біоінформатика
- Виявлення інтернет-шахрайств[24]
- Виявлення шахрайств із кредитними картками
- Гра в ігри
- Добування послідовностей
- Економіка
- Емоційні обчислення
- Землеробство
- Інформаційний пошук
- Інтернет-реклама
- Керування машинного навчання
- Класифікація послідовностей ДНК
- Комп'ютерний зір, включно з розпізнаванням об'єктів
- Комп'ютерні мережі
- Контроль утомного пошкодження
- Маркетинг
- Машинне чуття
- Медична діагностика
- Мовознавство
- Мультимодальний аналіз тональності
- Нейрокомп'ютерні інтерфейси
- Обробка природної мови
- Обчислювальна анатомія
- Оптимізація та метаевристика
- Переклад[37]
- Пересування роботів
- Пошукові системи
- Прогнозування часових рядів
- Програмна інженерія
- Рекомендаційні системи
- Розпізнавання мовлення та рукописного введення
- Розуміння природної мови[38]
- Синтаксичне розпізнавання образів
- Страхування
- Телекомунікації
- Універсальні ігрові програми[39]
- Хемоінформатика
2006 року компанія інтернет-телебачення Netflix провела перші змагання Netflix Prize, щоби знайти програму для кращого передбачення вподобань користувачів, і покращити точність її наявного алгоритму рекомендації кінематографічних фільмів щонайменше на 10 %. Об'єднана команда дослідників з AT&T Labs-Research у співпраці з командами Big Chaos та Pragmatic Theory побудувала ансамблеву модель, яка 2009 року виграла головний приз сумою 1 мільйон доларів.[40] Незабаром після призначення призу Netflix зрозуміли, що рейтинги користувачів були не найкращими показниками їхніх моделей перегляду («всі рекомендації»), і вони змінили свій рекомендаційний рушій відповідно.[41]
2010 року газета The Wall Street Journal написала про компанію Rebellion Research та їхнє застосування машинного навчання для прогнозування фінансової кризи.[42]
2012 року співзасновник Sun Microsystems Вінод Хосла спрогнозував, що протягом двох наступних десятиріч 80 % робочих місць медичних працівників буде втрачено до автоматизованого медичного діагностичного програмного забезпечення з машинним навчанням.[43]
2014 року було повідомлено про застосування алгоритму машинного навчання в історії мистецтв для дослідження витонченого мистецтва живопису, і що воно могло виявити доти нерозпізнані впливи між митцями.[44]
Оцінювання моделей
Хоча машинне навчання й виявилося дуже перетворювальним в деяких галузях, ефективне машинне навчання є складним, оскільки пошук закономірностей є важким, і наявних тренувальних даних часто не достатньо; в результаті, програми машинного навчання часто не вдається здати.[45][46]
Класифікувальні моделі машинного навчання можливо затверджувати за допомогою таких методик оцінювання точності як метод притримування, що розбиває дані на тренувальний та випробувальний набори (загальноприйнято призначають 2/3 тренувального набору та 1/3 випробувального) та оцінює продуктивність моделі тренування на випробувальному наборі. Для порівняння, метод k-кратного перехресного затверджування випадковим чином розбиває дані на k підмножин, де k - 1 підмножин даних використовують для тренування моделі, тоді як k-ту використовують для випробування передбачувальної здатності моделі тренування. На додачу до методів притримування та перехресної перевірки, для оцінювання точності моделі можливо використовувати й натяжку, яка відбирає з набору даних n зразків із заміною.[47]
На додачу до загальної точності, дослідники часто повідомляють чутливість і специфічність, що означають істинно позитивний та істинно негативний рівні відповідно. Аналогічно, дослідники іноді повідомляють хибнопозитивний та хибнонегативний рівні. Проте, ці рівні є відношеннями, що не розкривають своїх чисельників та знаменників. Ефективним методом вираження діагностичної здатності моделі є загальна робоча характеристика. Вона показує чисельники та знаменники згаданих вище рівнів, і, таким чином, забезпечує більше інформації, ніж широко застосовувана робоча характеристика приймача, та пов'язана з нею площа під кривою.[48]
Етика
Машинне навчання ставить безліч етичних питань. Системи, треновані на наборах даних, зібраних з упередженнями, можуть проявляти ці упередження при використанні (алгоритмічне упередження), оцифровуючи таким чином культурні забобони, такі як інституційний расизм або класизм.[49] Наприклад, використання даних про наймання працівників від компанії з расистськими політиками наймання може призвести до дублювання цього упередження системою машинного навчання шляхом ранжування претендентів на робоче місце згідно з подібностю до попередніх успішних претендентів.[50][51] Таким чином, відповідальне збирання даних та документування алгоритмічних правил, що використовуються системою, є критичною частиною машинного навчання.
Для алгоритмів кредитного скорингу, страхування, оцінювання кандидатів на роботу, а також у будь-якій ситуації автоматизованого ухвалення рішення про розподіл ресурсів чи покарань, різні визначення того, що є справедливим, неодмінно виявляться несумісними, що не може бути виправлено в межах алгоритму та є типовим для такого типу проблем.[52] Однак алгоритм, який є комерційною таємницею, позбавляє можливості оцінити процес ухвалювання рішення, внаслідок чого втрачається публічна відповідальність.[52] Одним із розв'язань цієї проблеми може бути обов'язковий аудит систем машинного навчання на упередженість і дискримінацію[52].
Оскільки мова містить упередження, машини, треновані на мовних корпусах обов'язково також навчатимуться упереджень.[53]
В охороні здоров'я є помітнішими інші види етичних викликів, не пов'язаних з особистими упередженнями. Серед фахівців з охорони здоров'я існують занепокоєння, що ці системи може бути розроблювано не в суспільних інтересах, а як машини для генерування доходу. Це є особливо актуальним у Сполучених Штатах, де існує вічна етична дилема покращення охорони здоров'я, але також і підвищення доходів. Наприклад, ці алгоритми може бути розроблено таким чином, щоби забезпечувати пацієнтів непотрібними аналізами чи ліками, в яких власники алгоритму мають долю. В машинного навчання існує величезний потенціал в охороні здоров'я, щоби забезпечувати фахівців чудовим інструментом для діагностування, призначення ліків та навіть планів відновлення для пацієнтів, але цього не станеться, поки не буде дано раду згаданим вище особистим, та цим «жадібним» упередженням.[54]
Апаратне забезпечення
Починаючи з 2010-х років прогрес як в алгоритмах машинного навчання, так і в комп'ютерному обладнанні призвів до появи ефективніших методів навчання глибинних нейронних мереж (особливої вузької підобласті машинного навчання), які містять багато шарів нелінійних прихованих вузлів.[55] До 2019 року графічні процесори (ГП), часто зі специфічними вдосконаленнями для ШІ, витіснили ЦП як панівний метод тренування великомасштабного комерційного хмарного ШІ.[56] OpenAI підрахувала апаратні обчислення, що використовували в найбільших проєктах глибинного навчання, від AlexNet (2012), і до AlphaZero (2017), і виявила 300 000-кратне збільшення обсягу необхідних обчислень, із тенденцією подвоєння часу кожні 3,4 місяці.[57]
Програмне забезпечення
До програмних пакетів, які містять ряд алгоритмів машинного навчання, належать наступні:
Вільне та відкрите програмне забезпечення
- CNTK
- Deeplearning4j
- ELKI
- H2O
- Mahout
- Mallet
- MLPACK
- OpenNN
- Orange
- scikit-learn
- Shogun
- Spark MLlib
- TensorFlow
- Torch / PyTorch
- Weka / MOA
- Yooreeka
Власницьке програмне забезпечення з вільними або відкритими редакціями
- KNIME
- RapidMiner
Власницьке програмне забезпечення
- Amazon Machine Learning
- Angoss KnowledgeSTUDIO
- Ayasdi
- IBM Data Science Experience
- Google Prediction API
- IBM SPSS Modeler
- KXEN Modeler
- LIONsolver
- Mathematica
- MATLAB
- Microsoft Azure Machine Learning
- Neural Designer
- NeuroSolutions
- Oracle Data Mining
- Oracle AI Platform Cloud Service
- RCASE
- SAP Leonardo Machine Learning
- SAS Enterprise Miner
- SequenceL
- Splunk
- STATISTICA Data Miner
Журнали
- «Journal of Machine Learning Research»
- «Machine Learning»
- «Neural Computation»
Конференції
- Conference on Neural Information Processing Systems
- International Conference on Machine Learning
- International Conference on Learning Representations
- Open Data Science Conference (ODSC)
Див. також
- Автоматизоване машинне навчання
- Автоматичне міркування
- Важливі публікації в машинному навчанні
- Великі дані
- Глибинне навчання
- Екзистенційний ризик від штучного розуму
- Етика штучного інтелекту
- Застосування машинного навчання в біоінформатиці
- Квантове машинне навчання
- Навчання на основі пояснень
- Навчання подібностей
- Наука про дані
- Обчислювальна нейронаука
- Обчислювальний інтелект
- Перелік алгоритмів машинного навчання
- Перелік наборів даних для досліджень машинного навчання
- Штучний інтелект
Примітки
- Приблизне перефразування з Samuel, Arthur (1959). Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development 3 (3): 210–229. doi:10.1147/rd.33.0210. (англ.)
Див., наприклад, Koza, John R.; Bennett, Forrest H.; Andre, David; Keane, Martin A. (1996). Automated Design of Both the Topology and Sizing of Analog Electrical Circuits Using Genetic Programming Artificial Intelligence in Design '96 (англ.). Springer, Dordrecht. с. 151–170. doi:10.1007/978-94-009-0279-4_9. «Перефразовуючи Артура Семюеля (1959), питанням є: Як можуть комп'ютери навчатися розв'язування задач без того, щоби бути програмованими явно? (англ. How can computers learn to solve problems without being explicitly programmed?)» - Samuel, Arthur L. (1988). Some Studies in Machine Learning Using the Game of Checkers. I. Computer Games I (англ.). Springer, New York, NY. с. 335–365. ISBN 9781461387183. doi:10.1007/978-1-4613-8716-9_14. (англ.)
- http://www.britannica.com/EBchecked/topic/1116194/machine-learning (англ.) Це третинне джерело перевикористовує інформацію з інших джерел, не називаючи їх.
- Ron Kohavi; Foster Provost (1998). Glossary of terms. Machine Learning 30: 271–274. (англ.)
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. ISBN 0-387-31073-8. (англ.)
- Dickson, Ben. Exploiting machine learning in cybersecurity. TechCrunch. Процитовано 23 травня 2017. (англ.)
- Wernick, M. N.; Yang, Y.; Brankov, J. G.; Yourganov, G.; Strother, S. C. (2010). Machine Learning in Medical Imaging. IEEE Signal Processing Magazine 27 (4): 25–38. Bibcode:2010ISPM…27…25W. PMC 4220564. doi:10.1109/MSP.2010.936730. (англ.)
- Mannila, Heikki (1996). Data mining: machine learning, statistics, and databases Int'l Conf. Scientific and Statistical Database Management. IEEE Computer Society. (англ.)
- Friedman, Jerome H. (1998). Data Mining and Statistics: What's the connection?. Computing Science and Statistics 29 (1): 3–9. (англ.)
- Dark Reading. (англ.)
- AI Business. (англ.)
- Machine Learning: What it is and why it matters. www.sas.com. Процитовано 29 березня 2016. (англ.)
- Mitchell, T. (1997). Machine Learning. McGraw Hill. с. 2. ISBN 0-07-042807-7. (англ.)
- Harnad, Stevan (2008). The Annotation Game: On Turing (1950) on Computing, Machinery, and Intelligence. У Epstein, Robert; Peters, Grace. The Turing Test Sourcebook: Philosophical and Methodological Issues in the Quest for the Thinking Computer. Kluwer. (англ.)
- R. Kohavi and F. Provost, "Glossary of terms, " Machine Learning, vol. 30, no. 2–3, pp. 271—274, 1998. (англ.)
- Sarle, Warren. Neural Networks and statistical models. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Russell, Stuart; Norvig, Peter (2003) [1995]. Artificial Intelligence: A Modern Approach (вид. 2nd). Prentice Hall. ISBN 978-0137903955. (англ.)
- Langley, Pat (2011). The changing science of machine learning. Machine Learning 82 (3): 275—279. doi:10.1007/s10994-011-5242-y. (англ.)
- Le Roux, Nicolas; Bengio, Yoshua; Fitzgibbon, Andrew (2012). «Improving First and Second-Order Methods by Modeling Uncertainty». Optimization for Machine Learning. MIT Press. p. 404. (англ.)
- Michael I. Jordan (10 вересня 2014). statistics and machine learning. reddit. Процитовано 1 жовтня 2014. (англ.)
- Cornell University Library. Breiman: Statistical Modeling: The Two Cultures (with comments and a rejoinder by the author). Процитовано 8 серпня 2015 р.. (англ.)
- Gareth James; Daniela Witten; Trevor Hastie; Robert Tibshirani (2013). An Introduction to Statistical Learning. Springer. с. vii. (англ.)
- Mohri, Mehryar; Rostamizadeh, Afshin; Talwalkar, Ameet (2012). Foundations of Machine Learning. USA, Massachusetts: MIT Press. ISBN 9780262018258. (англ.)
- Alpaydin, Ethem (2010). Introduction to Machine Learning. London: The MIT Press. ISBN 978-0-262-01243-0. Процитовано 4 лютого 2017. (англ.)
- Honglak Lee, Roger Grosse, Rajesh Ranganath, Andrew Y. Ng. «Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations» Proceedings of the 26th Annual International Conference on Machine Learning, 2009. (англ.)
- Lu, Haiping; Plataniotis, K.N.; Venetsanopoulos, A.N. (2011). A Survey of Multilinear Subspace Learning for Tensor Data. Pattern Recognition 44 (7): 1540–1551. doi:10.1016/j.patcog.2011.01.004. (англ.)
- Yoshua Bengio (2009). Learning Deep Architectures for AI. Now Publishers Inc. с. 1–3. ISBN 978-1-60198-294-0. (англ.)
- Tillmann, A. M. (2015). On the Computational Intractability of Exact and Approximate Dictionary Learning. IEEE Signal Processing Letters 22 (1): 45–49. Bibcode:2015ISPL...22...45T. arXiv:1405.6664. doi:10.1109/LSP.2014.2345761. (англ.)
- Aharon, M, M Elad, and A Bruckstein. 2006. «K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation.» Signal Processing, IEEE Transactions on 54 (11): 4311–4322 (англ.)
- Goldberg, David E.; Holland, John H. (1988). Genetic algorithms and machine learning. Machine Learning 3 (2): 95–99. doi:10.1007/bf00113892. (англ.)
- Michie, D.; Spiegelhalter, D. J.; Taylor, C. C. (1994). Machine Learning, Neural and Statistical Classification. Ellis Horwood. (англ.)
- Zhang, Jun; Zhan, Zhi-hui; Lin, Ying; Chen, Ni; Gong, Yue-jiao; Zhong, Jing-hui; Chung, Henry S.H.; Li, Yun та ін. (2011). Evolutionary Computation Meets Machine Learning: A Survey. Computational Intelligence Magazine (IEEE) 6 (4): 68–75. doi:10.1109/mci.2011.942584. (англ.)
- Bassel, George W.; Glaab, Enrico; Marquez, Julietta; Holdsworth, Michael J.; Bacardit, Jaume (1 вересня 2011). Functional Network Construction in Arabidopsis Using Rule-Based Machine Learning on Large-Scale Data Sets. The Plant Cell (англ.) 23 (9): 3101–3116. ISSN 1532-298X. PMC 3203449. PMID 21896882. doi:10.1105/tpc.111.088153. (англ.)
- Urbanowicz, Ryan J.; Moore, Jason H. (22 вересня 2009). Learning Classifier Systems: A Complete Introduction, Review, and Roadmap. Journal of Artificial Evolution and Applications (англ.) 2009: 1–25. ISSN 1687-6229. doi:10.1155/2009/736398. (англ.)
- Bridge, James P., Sean B. Holden, and Lawrence C. Paulson. «Machine learning for first-order theorem proving.» Journal of automated reasoning 53.2 (2014): 141—172. (англ.)
- Loos, Sarah, et al. «Deep Network Guided Proof Search.» arXiv preprint arXiv:1701.06972 (2017). (англ.)
- AI-based translation to soon reach human levels: industry officials. Yonhap news agency. Процитовано 4 березня 2017. (англ.)
- Sarikaya, Ruhi, Geoffrey E. Hinton, and Anoop Deoras. «Application of deep belief networks for natural language understanding.» IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 22.4 (2014): 778—784. (англ.)
- Finnsson, Hilmar, and Yngvi Björnsson. «Simulation-Based Approach to General Game Playing Архівовано 18 жовтня 2017 у Wayback Machine..» AAAI. Vol. 8. 2008. (англ.)
- «BelKor Home Page» research.att.com (англ.)
- The Netflix Tech Blog: Netflix Recommendations: Beyond the 5 stars (Part 1). Процитовано 8 серпня 2015 р.. (англ.)
- Scott Patterson (13 липня 2010). Letting the Machines Decide. WSJ. Процитовано 24 червня 2018 р.. (англ.)
- Vonod Khosla (10 січня 2012). Do We Need Doctors or Algorithms?. Tech Crunch. (англ.)
- When A Machine Learning Algorithm Studied Fine Art Paintings, It Saw Things Art Historians Had Never Noticed, The Physics at ArXiv blog (англ.)
- Why Machine Learning Models Often Fail to Learn: QuickTake Q&A. Bloomberg.com. 10 листопада 2016. Процитовано 10 квітня 2017. (англ.)
- Simonite, Tom. Microsoft says its racist chatbot illustrates how AI isn't adaptable enough to help most businesses. MIT Technology Review (англ.). Процитовано 10 квітня 2017. (англ.)
- Kohavi, Ron (1995). A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. International Joint Conference on Artificial Intelligence. (англ.)
- Pontius, Robert Gilmore; Si, Kangping (2014). The total operating characteristic to measure diagnostic ability for multiple thresholds. International Journal of Geographical Information Science 28 (3): 570–583. doi:10.1080/13658816.2013.862623. (англ.)
- Bostrom, Nick (2011). The Ethics of Artificial Intelligence. Процитовано 11 серпня 2016 р.. (англ.)
- Edionwe, Tolulope. The fight against racist algorithms. The Outline. Процитовано 17 листопада 2017. (англ.)
- Jeffries, Adrianne. Machine learning is racist because the internet is racist. The Outline. Процитовано 17 листопада 2017. (англ.)
- Hao, Karen; Stray, Jonathan (17 жовтня 2019). Can you make AI fairer than a judge? Play our courtroom algorithm game [Чи можете ви зробити ШІ справедливішим за суддю? Зіграйте в нашу гру з алгоритмом для суду]. MIT Technology Review (англ.). Процитовано 20 жовтня 2019.
- Narayanan, Arvind (24 серпня 2016). Language necessarily contains human biases, and so will machines trained on language corpora. Freedom to Tinker. (англ.)
- Char, D. S.; Shah, N. H.; Magnus, D. (2018). Implementing Machine Learning in Health Care – Addressing Ethical Challenges. New England Journal of Medicine 378 (11): 981–983. PMID 29539284. doi:10.1056/nejmp1714229. (англ.)
- Research, AI (23 жовтня 2015). Deep Neural Networks for Acoustic Modeling in Speech Recognition. airesearch.com. Процитовано 23 жовтня 2015. (англ.)
- Jeremy Howard, Sylvain Gugger (2020). Deep Learning for Coders with fastai and PyTorch. O'Reilly. ISBN 978-1492045526. (англ.)
- AI and Compute. OpenAI (англ.). 16 травня 2018. Процитовано 11 червня 2020. (англ.)
Література
- Nils J. Nilsson, Introduction to Machine Learning. (англ.)
- Trevor Hastie, Robert Tibshirani and Jerome H. Friedman (2001). The Elements of Statistical Learning, Springer. ISBN 0-387-95284-5. (англ.)
- Pedro Domingos (September 2015), The Master Algorithm, Basic Books, ISBN 978-0-465-06570-7 (англ.)
- Ian H. Witten and Eibe Frank (2011). Data Mining: Practical machine learning tools and techniques Morgan Kaufmann, 664pp., ISBN 978-0-12-374856-0. (англ.)
- Ethem Alpaydin (2004). Introduction to Machine Learning, MIT Press, ISBN 978-0-262-01243-0. (англ.)
- David J. C. MacKay. Information Theory, Inference, and Learning Algorithms Cambridge: Cambridge University Press, 2003. ISBN 0-521-64298-1 (англ.)
- Richard O. Duda, Peter E. Hart, David G. Stork (2001) Pattern classification (2nd edition), Wiley, New York, ISBN 0-471-05669-3. (англ.)
- Christopher Bishop (1995). Neural Networks for Pattern Recognition, Oxford University Press. ISBN 0-19-853864-2. (англ.)
- Stuart Russell & Peter Norvig, (2002). Artificial Intelligence — A Modern Approach. Prentice Hall, ISBN 0-136-04259-7. (англ.)
- Ray Solomonoff, An Inductive Inference Machine, IRE Convention Record, Section on Information Theory, Part 2, pp., 56-62, 1957. (англ.)
- Ray Solomonoff, «An Inductive Inference Machine» A privately circulated report from the 1956 Dartmouth Summer Research Conference on AI. (англ.)
Посилання
- Міжнародна спільнота машинного навчання (англ. International Machine Learning Society) (англ.)
- Популярний онлайн-курс від Ендрю Ина на Coursera. Використовує GNU Octave. Цей курс є безкоштовною версією справжнього курсу Стенфордського університету, який читає Ендрю Ин, лекції якого також доступні безкоштовно. (англ.)
- Курс «Машинне навчання» на Prometheus (укр.)
- Онлайн-курс із машинного навчання від Intellipaat. (англ.)
- mloss — академічна база даних відкритого програмного забезпечення для машинного навчання. (англ.)
- Machine Learning Crash Course від Google. Це — безкоштовний курс із машинного навчання із застосуванням TensorFlow (англ.)
- Популярна книга Machine Intelligence in Design Automation. (англ.)
- Чернеткова копія книги Ендрю Ина. (англ.)
- Онлайн-копія книги з глибинного навчання Яна Ґудфелоу, Йошуа Бенжіо та Аарона Курвіля (англ. Aaron Courville). (англ.)
