Тематичне моделювання
Тематичне моделювання — спосіб побудови моделі колекції текстових документів, яка визначає, до яких тем належить кожен з документів[1].
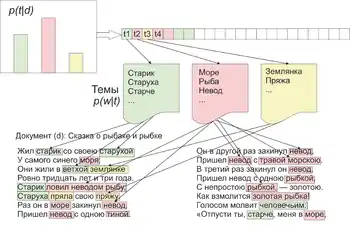






Тематична модель (англ. topic model) колекції текстових документів визначає, до яких тем належить кожен документ, і які слова (терміни) утворюють кожну тему[2].
Перехід з простору термінів в простір знайдених тематик допомагає вирішувати синонімію і полісемію термінів, а також ефективніше вирішувати такі завдання як тематичний пошук, класифікація, сумаризація і анотація колекцій документів і новинних потоків.
Тематичне моделювання як вид статистичних моделей для знаходження прихованих тем, що зустрічаються в колекції документів, знайшло своє застосування в таких областях як машинне навчання і обробка природної мови. Дослідники використовують різні тематичні моделі для аналізу текстів, текстових архівів документів, для аналізу зміни тем у наборах документів[⇨]. Інтуїтивно розуміючи, що документ відноситься до певної теми, в документах, присвячених одній темі, можна зустріти деякі слова частіше за інші. Наприклад, слова «собака» і «кістка» зустрічаються частіше в документах про собак; «кішки» і «молоко» будуть зустрічатися в документах про кошенят, прийменники «в» та «на» будуть зустрічатися в обох тематиках. Зазвичай документ стосується кількох тем в різних пропорціях. Таким чином, для документу, в якому 10 % теми складають кішки, а 90 % теми — собаки, можна припустити, що слів про собак в 9 разів більше. Тематичне моделювання відображає цю інтуїцію в математичній структурі, яка дозволяє на підставі вивчення колекції документів і дослідження частотних характеристик слів в кожному документі зробити висновок, що кожен документ — це деякий баланс тем.
Найбільше застосування в сучасних додатках знаходять підходи, що ґрунтуються на Баєсових мережах — імовірнісних моделях на орієнтованих графах. Імовірнісні тематичні моделі — це відносно молода область досліджень в теорії навчання без учителя. Одним з перших був запропонований імовірнісний латентно-семантичний аналіз (PLSA)[⇨], заснований на принципі максимуму правдоподібності, як альтернатива класичним методам кластеризації, заснованим на обчисленні функцій відстані. Слідом за PLSA був запропонований метод прихованого розподілу Діріхле і його численні узагальнення[3][⇨].
Імовірнісні тематичні моделі здійснюють «м'яку» кластеризацію, дозволяючи документу або терміну відноситися відразу до декількох тем з різними ймовірностями. Імовірнісні тематичні моделі описують кожну тему дискретним розподілом на безлічі термінів, кожен документ — дискретним розподілом на безлічі тем. Передбачається, що колекція документів — це послідовність термінів, обраних випадково і незалежно з суміші таких розподілів, і ставиться завдання відновлення компонентів суміші по вибірці[4][⇨].
Хоча тематичне моделювання традиційно описувалося і застосовувалося в обробці природної мови, воно знайшло своє застосування і в інших областях, наприклад, таких як біоінформатика.
Історія
Перший опис тематичного моделювання з'явилося в роботі Рагавана, Пападімітріу, Томакі і Вемполи 1998 року[5]. Томас Гофман в 1999 році[6] запропонував імовірнісне приховане семантичне індексування (PLSI). Одна з найпоширеніших тематичних моделей – це латентне розміщення Діріхле (LDA). Ця модель є узагальненням імовірнісного семантичного індексування і розроблена Девідом Блеєм, Ендрю Ином і Майклом Джорданом у 2002 році[7]. Інші тематичні моделі, як правило, є розширенням LDA, наприклад, розміщення патінко покращує LDA за рахунок введення додаткових кореляційних коефіцієнтів для кожного слова, яке становить тему.
Тематичні дослідження
Темплтон зробив огляд робіт з тематичного моделювання в гуманітарних науках, згрупованих за синхронним і діахронічним підходом[8]. Синхронні підходи виділяють теми в певний момент часу, наприклад, Джокерс за допомогою тематичної моделі досліджував, про що писали блогери в День цифрових гуманітарних наук в 2010 році[9].
Діахронічні підходи, включаючи визначення Блока та Ньюмана про часову динаміку тем у Пенсільванській газеті 1728-1800 року[10]. Грифітс і Стейверс використовували тематичне моделювання для оглядів журналу PNAS, визначали зміни популярності тем з 1991 по 2001 рік[11]. Блевін створив тематичну модель щоденника Марти Балладс[12]. Мімно використовував тематичне моделювання для аналізу 24 журналів з класичної філології та археології за 150 років, щоб визначити зміни популярності тем і дізнатися, наскільки сильно змінилися журнали за цей час[13].
Алгоритми тематичного моделювання
У роботі Девіда Блея «Введення в тематичне моделювання» розглянуто найбільш популярний алгоритм – Латентне розміщення Діріхле[⇨][14]. На практиці дослідники використовують одну з евристик методу максимальної правдоподібності, методи сингулярного розкладу (SVD), метод моментів, алгоритм, заснований на невід'ємній матриці факторизації (NMF), імовірнісні тематичні моделі, імовірнісний латентно-семантичний аналіз, латентне розміщення Діріхле. У роботі Воронцова К. В. розглянуто варіації основних алгоритмів тематичного моделювання: робастна тематична модель, тематичні моделі класифікації, динамічні тематичні моделі, ієрархічні тематичні моделі, багатомовні тематичні моделі, моделі тексту як послідовності слів, багатомодальні тематичні моделі [2].
Імовірнісні тематичні моделі засновані на наступних припущеннях[15][16][17][18]:
- Порядок документів у колекції не має значення
- Порядок слів у документі не має значення, документ – мішок слів
- Слова, що зустрічаються часто в більшості документів, не важливі для визначення тематики
- Колекцію документів можна представити як вибірку пар документ-слово , ,
- Кожна тема описується невідомим розподілом на безлічі слів
- Кожен документ описується невідомим розподілом на безлічі тем
- Гіпотеза умовної незалежності







Побудувати тематичну модель – значить, знайти матриці та по колекції . У більш складних імовірнісних тематичних моделях деякі з цих припущень замінюються більш реалістичними.



Імовірнісний латентно-семантичний аналіз
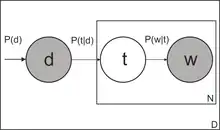




Імовірнісний латентно-семантичний аналіз (PLSA) запропонований Томасом Гофманом у 1999 році. Імовірнісна модель появи пари «документ-слово» може бути записана трьома еквівалентними способами:

де — безліч тем;

- — невідомий апріорний розподіл тем у всій колекції;
- — апріорний розподіл на безлічі документів, емпірична оцінка , де — сумарна довжина всіх документів;
- — апріорний розподіл на безлічі слів, емпірична оцінка , де — число входжень слова в усі документи;






Шукані умовні розподілу виражаються через за формулою Баєса:


Для ідентифікації параметрів тематичної моделі по колекції документів застосовується принцип максимуму правдоподібності, який призводить до задачі максимізації функціоналу[19]

при обмеженнях нормування
де — число входжень слова у документ . Для вирішення даної оптимізаційної задачі зазвичай застосовується EM-алгоритм.


Основні недоліки PLSA:
- Число параметрів зростає лінійно по числу документів в колекції, що може призводити до перенавчання моделі.
- При додаванні нового документа у колекцію, розподіл неможливо обчислити за тими ж формулами, що і для інших документів, не перебудовуючи всю модель заново.
Латентне розміщення Діріхле
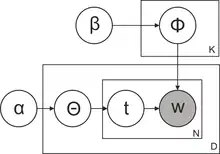



Метод латентного розміщення Діріхле (LDA) був запропонований Девідом Блеєм у 2003 році.
У цьому методі усунені основні недоліки PLSA.
Метод LDA заснований на тій самій імовірнісній моделі:

при додаткових припущеннях:
- вектори документів породжуються одним і тим же імовірнісним розподілом на нормованих -мірних векторах; цей розподіл зручно взяти з параметричного сімейства розподілів Діріхле ;
- вектори тем породжуються одним і тим же імовірнісним розподілом на нормованих векторах розмірності ; цей розподіл зручно взяти з параметричного сімейства розподілів Діріхле .






Для ідентифікації параметрів моделі LDA по колекції документів застосовується семплювання Гіббса, варіаційний баєсівський висновок або метод поширення очікування.
Див. також
- Explicit semantic analysis
- Иерархический процесс Дирихле
Примітки
- Коршунов, 2012.
- Воронцов, 2013.
- Ali10, 2010.
- Воронцов12, 2012.
- Пападимитриу, 1998.
- Хофманн, 1999.
- Блей2003, 2003.
- Тэмплтон, 2011.
- Джокерс, 2010.
- НьюманБлок, 2006.
- Грифитс, 2004.
- Блевин, 2010.
- Мимно, 2012.
- Блей2012, 2012.
- Коршунов, 2012, с. 229.
- Воронцов, 2013, с. 6.
- Воронцов13, 2013, с. 5.
- ВоронцовМЛ, 2013, с. 5.
- К. В. Воронцов. Вероятностное тематическое моделирование (русский).
Література
- Коршунов Антон; Гомзин Андрей (2012). Тематическое моделирование текстов на естественном языке (журнал) (вид. Труды Института системного программирования РАН).
- Воронцов К.В. (2013). Вероятностное тематическое моделирование (web) (вид. www.machinelearning.ru).
- Воронцов К.В.; Потапенко А.А. (2012). Регуляризация, робастность и разреженность вероятностных тематических моделей (журнал) (вид. Компьютерные исследования и моделирование). с. 693–706.
- Воронцов К.В. (2013). Аддитивная регуляризация вероятностных тематических моделей Презентация (web) (вид. www.machinelearning.ru).
- Воронцов К.В. (2013). Вероятностные тематические модели коллекции текстовых документов Презентация (web) (вид. www.machinelearning.ru).
- Марк Стейверс; Tom Griffiths (2007). Вероятностная тематическая модель.. Справочник скрытого семантического анализа. Psychology Press. ISBN 978-0-8058-5418-3. Архівовано червень 24, 2013 на сайті Wayback Machine.
- Daud Ali; Li Juanzi; Zhou Lizhu; Muhammad Faqir (2010). Knowledge discovery through directed probabilistic topic models: a survey. In Proceedings of Frontiers of Computer Science in China. (web) (вид. www.researchgate.net).
- Christos Papadimitriou; Prabhakar Raghavan; Hisao Tamaki; Santosh Vempala (1998). Latent Semantic Indexing: A probabilistic analysis (вид. Proceedings of ACM PODS). Архів оригіналу за 9 травня 2013.
- Thomas Hoffman (1999). Probabilistic Latent Semantic Indexing (вид. Proceedings of the Twenty-Second Annual International SIGIR Conference on Research and Development in Information Retrieval). Архів оригіналу за 14 грудня 2010.
- David M. Blei; Andrew Y. Ng; Michael I. Jordan (2003). Latent Dirichlet Allocation (вид. Journal of Machine Learning Research). Архів оригіналу за 1 травня 2012.
- David Blei (2012). Introduction to Probabilistic Topic Models (вид. Communications of the ACM). с. 77–84. Архів оригіналу за 15 лютого 2017.
- David Blei; J.D. Lafferty (2009). Topic models (web). Архів оригіналу за 31 травня 2013.
- David Blei; J.D. Lafferty (2007). Introduction to Probabilistic Topic Models (вид. Annals of Applied Statistics). с. 17–35. doi:10.1214/07-AOAS114. Архів оригіналу за 15 лютого 2017.
- David Mimno (2012). Computational Historiography: Data Mining in a Century of Classics Journals (журнал) (вид. Journal on Computing and Cultural Heritag). doi:10.1145/2160165.2160168.
- Matthew L. Jockers (2010). Who's your DH Blog Mate: Match-Making the Day of DH Bloggers with Topic Modeling (web).
- E. Микс (2011). Понимание цифровых гуманитарных наук (web).
- C. Тэмплтон (2011). Тематическое моделирование в гуманитарных науках: обзор. (web) (вид. Maryland Institute for Technology in the Humanities Blog).
- T. Гифитс; М. Стейверс (2004). Нахождение научных тем (журнал) (вид. Proceedings of the National Academy of Sciences). PMID 14872004. doi:10.1073/pnas.0307752101.
- T. Янг; A Торгет; Р. Mihalcea (2011). Тематическое моделирование в исторических газетах (журнал) (вид. Proceedings of the 5th ACL-HLT Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. The Association for Computational Linguistics, Madison). с. 96–104. Архів оригіналу за 27 березня 2014.
- С. Блок (2006). Делаем больше с оцифровкой- введение в тематическое моделирование в ранних американских источниках (журнал) (вид. Common-place The Interactive Journal of Early American Life).
- Д. Ньюман; С. Блок (2006). Вероятностное тематическое разложение в газетах 18 века (журнал) (вид. Journal of the American Society for Information Science and Technology). doi:10.1002/asi.20342.
- C. Блевин (2010). Тематическое моделирование дневника Марты Баллардс (web) (вид. historying).
Посилання
- Лекция: Тематическое моделирование — К. В. Воронцов // Школа аналізу даних (відео-лекції).
- Лекция 2: Тематическое моделирование — К. В. Воронцов // Школа аналізу даних (відео-лекції).
- Тематическое моделирование.
- Коллекции документов для тематического моделирования.
- Полностью разреженные тематические модели (перевод) / Fully Sparse Topic Models.
- Обзор по вероятностным тематическим моделям.
- Тематические модели для коллекции текстов.
- Байесовские методы машинного обучения (курс лекций, Д. П. Ветров, Д. А. Кропотов).
- Тепллтон, Клай. Тематическое моделирование в гуманитарных науках. Общий обзор. (вид. Maryland Institute for Technology in the Humanities).
- Применение тематического моделирования для анализа новостей и ревю. Video of a Google Tech Talk presentation by Alice Oh on topic modeling with Latent Dirichlet allocation
- Моделирование науки: Динамическое тематическое моделирование научных исследований. Video of a Google Tech Talk presentation by David M. Blei
- Автоматизированная тематическая модель в политической науке. Video of a presentation by Brandon Stewart at the Tools for Text Workshop, 14 June 2010
- Лекция: Тематическое моделирование — Дэвид Блей 2009 г. Відео-лекція від Принстонського університету
- Регуляризация вероятностных тематических моделей для повышения интерпретируемости и определения числа тем Диалог 2014
- Parsimonious Topic Models with Salient Word Discovery
Програмне забезпечення та програмні бібліотеки
- Малет (програма)
- Інструментарій Стенфордського університету з тематичного моделювання
- GenSim — «тематичне моделювання для людей»
- LDA C# LDA in Infer.NET