Grammatical Framework
Grammatical Framework (граматичний фреймворк, скорочено GF або ГФ) — мова програмування для розробки граматик природних мов. За допомогою ГФ можливий розбір і генерація текстів кількома мовами одночасно, при цьому представлення значення залишається незалежним від мови. Розроблені у ГФ граматики можуть бути скомпільовані у різні цільові формати, включно з JavaScript і Java, і використані як компоненти програмного забезпечення. Доповненням ГФ є бібліотека граматик (GF Resource Grammar Library), яка допомагає у роботі з морфологією і синтаксисом великої кількості природних мов.
ГФ і бібліотека граматик є відкритими програмами. З точки зору типології, ГФ — це функціональна мова програмування, математично — формальна система на основі теорії типів (точніше, логічний фреймворк). Фундаментом ГФ є теорія типів Мартіна-Льофа, з додатковими судженнями, пристосованими спеціально для потреб лінгвістики.
Особливості мови
- Статична система типів, що допомагає виявляти помилки у програмуванні
- Функціональне програмування, потужна підтримка абстракцій
- Бібліотечні модулі, що можуть використовуватися у інших граматиках
- Інструментальні засоби для екстракції інформації та конвертації інших лінгвістичних ресурсів у формат ГФ[1]
Опис
Нижче наведено приклади створення простих граматик, за допомогою яких можна отримати багатомовну генерацію фрази про те, що одна людина любить іншу людину.
Абстрактні і конкретні модулі
Граматики у ГФ можуть бути представлені двома типами модулів:
- абстрактний модуль, що містить форми суджень cat і fun:
- cat, або декларація категорії, служить для побудови категорій, тобто всіх можливих типів дерев,
- fun, або декларація функції, встановлює функції і їхні типи (імплементація міститься у конкретних модулях, див. нижче)
- один чи більше конкретних модулів, що містять форми суджень lincat і lin.
- lincat, або означення типу лінеаризації, показує які типи об'єктів продукуються в результаті лінеаризації кожної категорії, зазначеної у cat.
- lin, або правило лінеаризації, імплементує функції, декларовані у fun. Правила показують, як лінеаризуються дерева.
Наприклад, ми можемо визначити абстрактний синтаксис для конструювання речення типу «Іван любить Марію», а також конкретний синтаксис для виводу готового речення англійською мовою:
Абстрактний синтаксис
abstract Zero = {
cat
S ; NP ; VP ; V2 ;
fun
Pred : NP -> VP -> S ;
Compl : V2 -> NP -> VP ;
John, Mary : NP ;
Love : V2 ;
}
Тут категорією S позначено речення (англ. Sentence), NP - іменникове словосполучення (англ. Noun Phrase), VP - дієслівне словосполучення (англ. Verb Phrase), V2 - дієслово з двома залежними словами.
Конкретний синтаксис для англійської мови
concrete ZeroEng of Zero = {
lincat
S, NP, VP, V2 = Str ;
lin
Pred np vp = np ++ vp ;
Compl v2 np = v2 ++ np ;
John = "John" ;
Mary = "Mary" ;
Love = "loves" ;
}
Примітка: у цьому прикладі вказується, що Str (список токенів, або «рядок») є єдиним типом лінеаризації.
Багатомовна граматика
Єдиний абстрактний синтаксис може бути застосовано до багатьох конкретних синтаксисів (у нашому випадку — до синтаксису окремих природних мов). Конкретний синтаксис описує, зокрема, наступне:
- різні слова
- порядок слідування слів
- різні типи лінеаризації
Приклад конкретного синтаксису у ГФ для французької мови:
concrete ZeroFre of Zero = {
lincat
S, NP, VP, V2 = Str ;
lin
Pred np vp = np ++ vp ;
Compl v2 np = v2 ++ np ;
John = "Jean" ;
Mary = "Marie" ;
Love = "aime" ;
}
Переклад і багатомовна генерація тексту
Після того, як визначено модулі конкретного синтаксису, ГФ стає інструментом для точного перекладу між мовами. Означивши правило французької мови (див. вище), у оболонці ГФ (англ. GF shell) можна виконати наступні команди:
Імпорт граматик з однаковим абстрактним синтаксисом
> import ZeroEng.gf ZeroFre.gf
Languages: ZeroEng ZeroFre
Переклад: синтаксичний розбір → лінеаризація французькою
> parse -lang=Eng "John loves Mary" | linearize -lang=Fre
Jean aime Marie
Багатомовна генерація тексту: лінеаризація у всі підтримувані мови
> generate_random | linearize -treebank
Zero: Pred Mary (Compl Love Mary)
ZeroEng: Mary loves Mary
ZeroFre: Marie aime Marie
Параметри, таблиці
Українська мова має відмінки - називний для суб'єкта і знахідний для об'єкта.
- Іван (називний) любить Марію (знахідний)
- Марія (називний) любить Івана (знахідний)
Ми використаємо тип параметра (англ. parameter type) для зберігання інформації про відмінок (для двох з семи відмінків української мови). Типом лінеаризації NP буде табличний тип (англ. table type): відображення з Case в Str. Лінеаризацією категорії John буде таблиця відмінювання. Коли категорія NP буде використовуватись, ми обиратимемо (оператор !) потрібну форму з таблиці відмінювання.
concrete ZeroUkr of Zero = {
lincat
S, VP, V2 = Str ;
NP = Case => Str ;
lin
Pred np vp = np ! Nom ++ vp ;
Compl v2 np = v2 ++ np ! Acc ;
John = table {Nom => "Іван" ; Acc => "Івана"} ;
Mary = table {Nom => "Марія" ; Acc => "Марію"} ;
Love = "любить" ;
param
Case = Nom | Acc ;
}
Розривні складові, записи
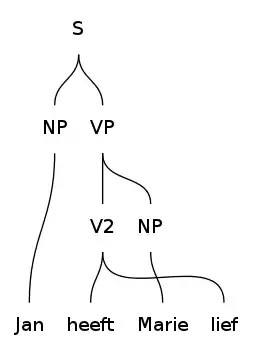
В Нідерландській мові, дієслово heeft lief - складається з розривних сладових (англ. discontinuous constituent). В реченні це виглядатиме наступним чином: "Jan heeft Marie lief".
Тип лінеаризації категорії V2 - запис (англ. record type) з двома полями. Лінеаризація Love - це об'єкт типу запис (англ. record). Доступ до полів запису можна отримати за допомогою оператора проекції (англ. projection): ".".
concrete ZeroDut of Zero = {
lincat
S, NP, VP = Str ;
V2 = {v : Str ; p : Str} ;
lin
Pred np vp = np ++ vp ;
Compl v2 np = v2.v ++ np ++ v2.p ;
John = "Jan" ;
Mary = "Marie" ;
Love = {v = "heeft" ; p = "lief"} ;
}
Візуалізація дерев синтаксичного розбору
ГФ має вбудовані функції для візуалізації дерев синтаксичного розбору і порядку слідування слів.
Наступні команди згенерують дерева розбору для заданих фраз у вигляді PNG-файлів і відкриють переглядач eog.
> parse -lang=Eng "John loves Mary" | visualize_parse -view="eog"
> parse -lang=Dut "Jan heeft Marie lief" | visualize_parse -view="eog"

| 
|
Порядок слів
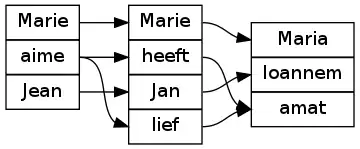
Grammatical Framework може генерувати діаграми що порівнюють порядок слів в різних мовах.
- Для мов L1 та L2 кожне слово зв'язується з найменшим деревом що їх покриває.
- Зв'язки між деревами перетворюються на прямі зв'язки між словами мов L1 і L2, дерево витирається.
Зв'язки можуть перетинатись, фрази можуть розриватись. Цей алгоритм запускається командою align_words, яка використовується наступним чином:
> parse -lang=Ukr "Марія любить Івана" | align_words -lang=Fre,Dut,Lat -view="eog"
Бібліотека граматик
Бібліотека граматик ГФ допомагає впорядковувати і організовувати тисячі різноманітних деталей синтаксису, лексики, морфології природних мов. Підтримуються наступні мови (20): aмхарська (частково), арабська (частково), болгарська, каталонська, данська, нідерландська, англійська, фінська, французька, німецька, гінді (фрагментарно), інтерлінґва, італійська, латинська (фрагментарно), непальська, норвезька (bokmål), перська, польська, пенджабська, румунська, російська, іспанська, шведська, тайська (фрагментарно), турецька (фрагментарно), урду.
Повна документація на програмний інтерфейс (API) бібліотеки доступна на сайті фреймворку RGL Synopsis. Сторінка статусу RGL містить інформацію про доступні на даний момент мови і рівень підтримки.
Історія і застосування
Перша версія ГФ була створена у 1998 році у Європейському центрі досліджень Xerox[2] (Ґренобль), як частина проекту «Multilingual Document Authoring». Зокрема, ГФ використовувалася для таких прототипів як книга ресторанних фраз, система запиту бази даних, формалізація інструкцій на випадок тривоги з автоматичним перекладом п'ятьма мовами, система виписування рецептів на ліки.
Багаторічний проект Європейського союзу MOLTO (мета: багатомовний онлайн-переклад) також базувався на ГФ як основній системі.
Джерела
- Ranta, Aarne (2011). Grammatical Framework: Programming with Multilingual Grammars. CSLI Publications, Center for the Study of Language and Information. с. 8–9. ISBN 978-1-57586-627-7.
- Європейський центр досліджень Xerox (фр.).