Генетичний алгоритм
Генети́чний алгори́тм (англ. genetic algorithm) — це еволюційний алгоритм пошуку, що використовується для вирішення задач оптимізації і моделювання шляхом послідовного підбору, комбінування і варіації шуканих параметрів з використанням механізмів, що нагадують біологічну еволюцію.
Особливістю генетичного алгоритму є акцент на використання оператора «схрещення», який виконує операцію рекомбінацію рішень-кандидатів, роль якої аналогічна ролі схрещення в живій природі. «Батьком-засновником» генетичних алгоритмів вважається Джон Голланд (англ. John Holland), книга якого «Адаптація в природних і штучних системах» (англ. Adaptation in Natural and Artificial Systems) є фундаментальною в цій сфері досліджень.
Історія
Перші спроби симуляції еволюції були проведені у 1954 році Нільсом Баричеллі на комп'ютері, встановленому в Інституті перспективних досліджень Принстонського університету.[1][2] Його робота, що була опублікована у тому ж році, привернула увагу громадськості. З 1957 року, [3] австралійський генетик Алекс Фразер опублікував серію робіт з симуляції штучного відбору серед організмів з множинним контролем вимірюваних характеристик. Це дозволило комп'ютерній симуляції еволюційних процесів та методам, які були описані у книгах Фразера та Барнела(1970)[4] та Кросбі(1975)[5], з 1960-х років стати більш розповсюдженим видом діяльності серед біологів. Симуляції Фразера містили усі найважливіші елементи сучасних генетичних алгоритмів. До того ж, Ганс-Іоахім Бремерман в 1960-х опублікував серію робіт, які також приймали підхід використання популяції рішень, що піддаються відбору, мутації та рекомбінації, в проблемах оптимізації. Дослідження Бремермана також містили елементи сучасних генетичних алгоритмів.[6] Також варто відмітити Річарда Фрідберга, Джоржа Фрідмана та Майкла Конрада[джерело?].
Хоча Баричеллі у своїй роботі 1963 р. займався симуляцією можливості машини грати у просту гру,[7] штучна еволюція стала загальновизнаним методом оптимізації після роботи Інго Рехенберга та Ханса-Пауля Швереля у 60-х та на початку 70-х років двадцятого століття — група Рехенсберга змогла вирішити складні інженерні проблеми згідно зі стратегіями еволюції.[8][9][10][11] Іншим підходом була техніка еволюційного програмування Лоренса Дж. Фогеля, яка була запропонована для створення штучного інтелекту. Еволюційне програмування, яке спочатку використовувало кінцеві автомати для передбачення обставин, та використовували різноманіття та відбір для оптимізації логіки передбачення. Генетичні алгоритми стали особливо відомі завдяки роботі Дж. Холанда на початку 70-х років та його книзі «Адаптація у природних та штучних системах» (1975)[12].Його дослідження були основані на експериментах з клітинними автоматами та на його роботах, що були написані в університеті Мічигану. Він ввів формалізований підхід для передбачення якості наступного покоління, відомий як Теорема схем. Дослідження в області генетичних алгоритмів залишалось більше теоретичним до середини 80-х років, коли була, нарешті, проведена Перша міжнародна конференція з генетичних алгоритмів (Піттсбург, Пенсильванія (США)).
З ростом дослідницького інтересу суттєво виросла обчислювальна потужність комп'ютерів, що дозволило використовувати нову обчислювальну техніку на практиці. Наприкінці 80-х років, компанія General Electric почала продаж першого в світі продукту, який працював з використанням генетичного алгоритму. Це був набір промислових обчислювальних засобів. В 1989 інша компанія Axcelis, Inc. випустила Evolver — перший у світі комерційний продукт на генетичному алгоритмі для персональних комп'ютерів. Журналіст The New York Times в технологічній сфері Джон Маркофф писав[13] про Evolver у 1990 році.
Опис алгоритму
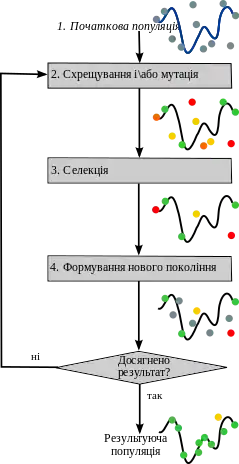
Задача кодується таким чином, щоб її вирішення могло бути представлено в вигляді масиву подібного до інформації складу хромосоми. Цей масив часто називають саме так «хромосома». Випадковим чином в масиві створюється деяка кількість початкових елементів «осіб», або початкова популяція. Особи оцінюються з використанням функції допасованості, в результаті якої кожній особі присвоюється певне значення допасованості, яке визначає можливість виживання особи. Після цього з використанням отриманих значень допасованості вибираються особи, допущені до схрещення (селекція). До осіб застосовується «генетичні оператори» (в більшості випадків це оператор схрещення (crossover) і оператор мутації (mutation)), створюючи таким чином наступне покоління осіб. Особи наступного покоління також оцінюються застосуванням генетичних операторів і виконується селекція і мутація. Так моделюється еволюційний процес, що продовжується декілька життєвих циклів (поколінь), поки не буде виконано критерій зупинки алгоритму. Таким критерієм може бути[джерело?]:
- знаходження глобального, або надоптимального вирішення;
- вичерпання числа поколінь, що відпущені на еволюцію;
- вичерпання часу, відпущеного на еволюцію.
Генетичні алгоритми можуть використовувати для пошуку рішень в дуже великих і важких просторах пошуку.
Різновиди і особливості алгоритму в різних галузях хімії
- У комбінаторній хімії — метод дизайну бібліотеки шляхом оцінки відповідності певних бажаних властивостей (пр., рівня активності в біологічних пошуках, або розрахунково визначених властивостей набору речовин), передбачених за допомогою функції, встановленої статистичними методами при аналізі співвідношення структура — властивість. Ще більш оптимальний дизайн пов'язаний з евристичним процесом, який нагадує генетичну селекцію, де застосовується реплікація, мутація, вилучення[джерело?].
- У хемометриці — механізм оптимізації, заснований на механізмі дарвінівської еволюції, де використовуються випадкові мутації, процедури схрещення та відбору для розробки кращої моделі чи розв'язку порівняно з тим, які було отримано, виходячи зі стартової сукупності чи вибірки[джерело?].
- У комп'ютерній хімії — комп'ютерний метод генерування та тестування комбінацій можливих вхідних параметрів для знаходження оптимальних вихідних значень. Використовується для оптимізації у випадку систем з великою кількістю змінних параметрів, зокрема при конформаційному аналізі багатоатомних складних молекул. Включає методи, що базуються на поняттях природної еволюції, такі як генетична комбінація, мутація та природний відбір[джерело?].
Етапи генетичного алгоритму
Можна виділити такі етапи генетичного алгоритму:
- Створення початкової популяції:
- Обчислення функції допасованості для осіб популяції (оцінювання)
- Повторювання до виконання критерію зупинки алгоритму:
- Вибір індивідів із поточної популяції (селекція)
- Схрещення або/та мутація
- Обчислення функції допасованості для всіх осіб
- Формування нового покоління
Створення початкової популяції
Перед першим кроком необхідно випадковим чином створити деяку початкову популяцію. Навіть якщо популяція виявиться абсолютно неконкурентоздатною, генетичний алгоритм все одно достатньо швидко переведе її в придатну для життя популяцію. Таким чином, на першому кроці можна не старатися зробити надто допасованих осіб, достатньо, щоб вони відповідали формату осіб популяції, і на них можна було порахувати функцію допасованості. Наслідком першого кроку є популяція H, що налічує N осіб.
Відбір
На етапі відбору необхідно із всієї популяції вибрати її певну долю, яка залишиться в «живих» на цьому етапі популяції. Є декілька способів провести відбір. Ймовірність виживання особи h повинна залежати від значення її допасованості Fitness(h). Сама ж доля відібраних s зазвичай є параметром генетичного алгоритму, і її просто задають заздалегідь. Внаслідок відбору із N осіб популяції H повинні залишитись sN осіб, які ввійдуть в наступну популяцію H'. Решта осіб «загине».
Розмноження
Розмноження в генетичних алгоритмах зазвичай статеве — щоб «народити» нащадка, необхідно декілька батьків, зазвичай потрібна участь двох. Розмноження в різних алгоритмах описується по різному — воно, звісно, залежить від формату осіб. Головна вимога до розмноження — щоб нащадок чи нащадки мали можливість успадкувати риси всіх батьків, «змішавши» їх якимось достатньо розумним чином.
Розмноження або оператор рекомбінації застосовують відразу ж після оператора відбору батьків для отримання нових особин-нащадків. Сенс рекомбінації полягає в тому, що створені нащадки повинні наслідувати генну інформацію від обох батьків. Розрізняють дискретну рекомбінацію і кросинговер.
Приклад операції розмноження: Вибрати (1-s)p/2 пар гіпотез із H і провести з ними розмноження, отримавши по два нащадка від кожної пари (якщо розмноження описано так, щоб давати одного нащадка, необхідно вибрати (1 — s)p пар), і додати цих нащадків в H'. В результаті H' буде складатися з N осіб.
Особи для розмноження зазвичай вибираються із всієї популяції H, а не із тих, що вижили на першому кроці (хоча останній варіант теж має право на існування). Справа в тому, що головна проблема генетичних алгоритмів — недостача різноманітності (diversity) в особах. Достатньо швидко виділяється єдиний генотип, який являє собою локальний максимум і згодом всі елементи популяції програють йому в відборі, і вся популяція «забивається» копіями цієї особи. Існують різні способи боротьби із таким небажаним ефектом; один з них — вибір для розмноження не з самих «допасованих», а взагалі зі всіх осіб.
Мутації
До мутацій відноситься все те ж, що і до розмноження: є деяка доля мутантів m, що є параметром генетичного алгоритму, і на кроці мутацій необхідно вибрати mN осіб, а згодом змінити їх згідно з заздалегідь заданими операціями мутації.
Застосування генетичних алгоритмів
Генетичні алгоритми застосовується для вирішення наступних задач:
- Оптимізація функцій
- Оптимізація запитів в базах даних
- Різноманітні задачі на графах (задача комівояжера, розфарбування)
- Налаштування і навчання штучної нейронної мережі
- Задачі компоновки
- Створення розкладів
- Ігрові стратегії
- Апроксимація функцій
- Штучне життя
- Біоінформатика (згортання білків)
- Синтез конструкцій антен[14][15]
Приклад простої реалізації на C++
Пошук в одномірному просторі, без схрещення. Ця програма вважає більші за значенням елементи представлені цілими числами найбільш життєздатними.
# include <iostream.h>
# include <algorithm.h>
# include <numeric.h>
using namespace std;
int main()
{
//початковий масив (популяція) з 1000 елементів (осіб).
const int N = 1000;
int a[N];
//заповнимо елементи нулями
fill(a, a+N, 0);
for (;;)
{
//Мутація кожного елемента.
//Випадково збільшуємо або зменшуємо значення елементу на один;
for (int i = 0; i < N; ++i)
if (rand()%2 == 1)
a[i] += 1;
else
a[i] -= 1;
//відсортуванням по зростанню вибираємо більші за значенням...
sort(a, a+N);
//... і тоді більші за значенням виявляться в другій частині масиву.
//скопіюємо більші в першу половину, коли вони залишили нащадків, а перші померли:
copy(a+N/2, a+N, a /*куди*/);
//тепер поглянемо на середнє значення елементу популяції. Як бачимо, середнє значення все більше і більше.
cout << accumulate(a, a+N, 0) / N << endl;
}
}
Приклад простої реалізації на Delphi
Пошук в одномірному просторі, без схрещення.
program Program1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.Generics.Defaults,
System.Generics.Collections,
System.SysUtils;
const
N = 1000;
Nh = N div 2;
MaxPopulation = High(Integer);
var
A: array [1..N] of Integer;
I, R, C, Points, BirthRate: Integer;
Iptr: ^Integer;
begin
Randomize;
// Часткова популяція
for I := 1 to N do
A[I] := Random(2);
repeat
// Мутація
for I := 1 to N do
A[I] := A[I] + (-Random(2) or 1);
// Відбір найкращих
TArray.Sort<Integer>(A, TComparer<Integer>.Default);
// Налаштування
Iptr := Addr(A[Nh + 1]);
Points := 0;
BirthRate := 0;
// Результати
for I := 1 to Nh do
begin
Inc(Points, Iptr^);
// Випадковий успіх схрещування
R := Random(2);
Inc(BirthRate, R);
A[I] := Iptr^ * R;
Iptr^ := 0;
Inc(Iptr,1);
end;
// проміжний результат
Inc(C);
until (Points / N >= 1) or (C >= MaxPopulation);
Writeln(Format('Population %d (rate:%f) score:%f', [C, BirthRate / Nh, Points / N]));
end.
Примітки
- Barricelli, Nils Aall (1954). Esempi numerici di processi di evoluzione. Methodos: 45–68.
- Barricelli, Nils Aall (1957). Symbiogenetic evolution processes realized by artificial methods. Methodos: 143–182.
- Fraser, Alex (1957). Simulation of genetic systems by automatic digital computers. I. Introduction. Aust. J. Biol. Sci. 10: 484–491.
- Fraser, Alex; Donald Burnell (1970). Computer Models in Genetics. New York: McGraw-Hill. ISBN 0-07-021904-4.
- Crosby, Jack L. (1973). Computer Simulation in Genetics. London: John Wiley & Sons. ISBN 0-471-18880-8.
- 02.27.96 — UC Berkeley’s Hans Bremermann, professor emeritus and pioneer in mathematical biology, has died at 69
- Barricelli, Nils Aall (1963). Numerical testing of evolution theories. Part II. Preliminary tests of performance, symbiogenesis and terrestrial life. Acta Biotheoretica (16): 99–126.
- Rechenberg, Ingo (1973). Evolutionsstrategie. Stuttgart: Holzmann-Froboog. ISBN 3-7728-0373-3.
- Schwefel, Hans-Paul (1974). Numerische Optimierung von Computer-Modellen (PhD thesis).
- Schwefel, Hans-Paul (1977). Numerische Optimierung von Computor-Modellen mittels der Evolutionsstrategie : mit einer vergleichenden Einführung in die Hill-Climbing- und Zufallsstrategie. Basel; Stuttgart: Birkhäuser. ISBN 3-7643-0876-1.
- Schwefel, Hans-Paul (1981). Numerical optimization of computer models (Translation of 1977 Numerische Optimierung von Computor-Modellen mittels der Evolutionsstrategie. Chichester ; New York: Wiley. ISBN 0-471-09988-0.
- J. H. Holland. Adaptation in natural and artificial systems. University of Michigan Press, Ann Arbor, 1975.
- Markoff, John (29 серпня 1990). What's the Best Answer? It's Survival of the Fittest. New York Times. Процитовано 9 серпня 2009.
- Слюсар В.И. Синтез антенн на основе генетических алгоритмов. //Первая миля. Last mile (Приложение к журналу "Электроника: наука, технология, бизнес"). – 2008. - № 6. -. — С. 16 - 23. .
- Слюсар В.И. Синтез антенн на основе генетических алгоритмов. Часть 2. //Первая миля. Last mile (Приложение к журналу "Электроника: наука, технология, бизнес"). – 2009. - № 1. -. — С. 22 - 25. .
Література
- Poli, R., Langdon, W. B., McPhee, N. F. (2008). A Field Guide to Genetic Programming. Lulu.com, freely available from the internet. ISBN 978-1-4092-0073-4.
- Глосарій термінів з хімії / уклад. Й. Опейда, О. Швайка ; Ін-т фізико-органічної хімії та вуглехімії ім. Л. М. Литвиненка НАН України, Донецький національний університет. — Дон. : Вебер, 2008. — 738 с. — ISBN 978-966-335-206-0.
Посилання
- Популярно про генетичні алгоритми (укр.)
- Субботін С. О., Олійник А. О., Олійник О. О. Неітеративні, еволюційні та мультиагентні методи синтезу нечіткологічних і нейромережних моделей: Монографія / Під заг. ред. С. О. Субботіна. — Запоріжжя: ЗНТУ, 2009. — 375 с.
- Генетичний алгоритм, каталог посилань Open Directory Project