Штучна нейронна мережа
Шту́чні нейро́нні мере́жі (ШНМ, англ. artificial neural networks, ANN), або конективістські системи (англ. connectionist systems) — це обчислювальні системи, натхнені біологічними нейронними мережами, що складають мозок тварин. Такі системи навчаються задач (поступально покращують свою продуктивність на них), розглядаючи приклади, загалом без спеціального програмування під задачу. Наприклад, у розпізнаванні зображень вони можуть навчатися ідентифікувати зображення, які містять котів, аналізуючи приклади зображень, мічені як «кіт» і «не кіт», і використовуючи результати для ідентифікування котів в інших зображеннях. Вони роблять це без жодного апріорного знання про котів, наприклад, що вони мають хутро, хвости, вуса та котоподібні писки. Натомість, вони розвивають свій власний набір доречних характеристик з навчального матеріалу, який вони оброблюють.
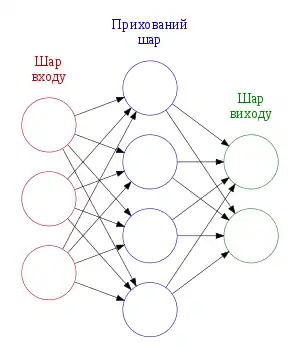
ШНМ ґрунтується на сукупності з'єднаних вузлів, що називають штучними нейронами (аналогічно до біологічних нейронів у головному мозку тварин). Кожне з'єднання (аналогічне синапсові) між штучними нейронами може передавати сигнал від одного до іншого. Штучний нейрон, що отримує сигнал, може обробляти його, й потім сигналізувати штучним нейронам, приєднаним до нього.
В поширених реалізаціях ШНМ сигнал на з'єднанні між штучними нейронами є дійсним числом, а вихід кожного штучного нейрону обчислюється нелінійною функцією суми його входів. Штучні нейрони та з'єднання зазвичай мають вагу, яка підлаштовується в перебігу навчання. Вага збільшує або зменшує силу сигналу на з'єднанні. Штучні нейрони можуть мати такий поріг, що сигнал надсилається лише якщо сукупний сигнал перетинає цей поріг. Штучні нейрони зазвичай організовано в шари. Різні шари можуть виконувати різні види перетворень своїх входів. Сигнали проходять від першого (входового) до останнього (виходового) шару, можливо, після проходження шарами декілька разів.
Первинною метою підходу ШНМ було розв'язання задач таким же способом, як це робив би людський мозок. З часом увага зосередилася на відповідності певним розумовим здібностям, ведучи до відхилень від біології. ШНМ використовували в ряді різноманітних задач, включно з комп'ютерним баченням, розпізнаванням мовлення, машинним перекладом, соціально-мережевим фільтруванням, грою в настільні та відеоігри, та медичним діагностуванням.
Історія
Воррен Маккалох та Волтер Піттс[1] (1943) створили обчислювальну модель для нейронних мереж на основі математики та алгоритмів, названою пороговою логікою. Ця модель проклала шлях до поділу досліджень нейронних мереж на два підходи. Один підхід зосереджується на біологічних процесах у мозку, тоді як інший зосереджується на застосуванні нейронних мереж до штучного інтелекту. Ця праця привела до роботи над мережами нервів та їхнього зв'язку зі скінченними автоматами.[2]
Геббове навчання
Наприкінці 1940-х років Дональд Гебб[3] створив гіпотезу навчання, засновану на механізмі нейропластичності, яка стала відомою як геббове навчання. Геббове навчання є спонтанним навчанням. Воно розвинулося в моделі довготривалого потенціювання. Дослідники почали застосовувати ці ідеї до обчислювальних моделей 1948 року в машинах Тюрінга типу B.
Фарлі та Кларк[4] (1954) вперше використали обчислювальні машини, звані тоді «калькуляторами» (англ. calculators), щоби відтворити геббову мережу. Інші нейромережеві обчислювальні машини було створено Рочестером, Голландом, Гебітом та Дудою (1956).[5]
Розенблат[6] (1958) створив перцептрон, алгоритм для розпізнавання образів. За допомогою математичного запису Розенблат описав схему не примітивного перцептрону, таку як схема виключного «або», яке в той час обробляти нейронними мережами було неможливо.[7]
1959 року біологічну модель, запропоновану нобелівськими лауреатами Г'юбелем та Візелем, було засновано на їхньому відкритті двох типів клітин у первинній зоровій корі: простих клітин та складних клітин.[8]
Перші працездатні мережі з багатьма шарами було опубліковано Івахненком та Лапою 1965 року, вони стали методом групового урахування аргументів.[9][10][11]
Дослідження нейронних мереж зазнало застою після дослідження машинного навчання Мінського та Пейперта (1969),[12] які відкрили дві ключові проблеми з обчислювальними машинами, що обробляли нейронні мережі. Першою було те, що базові перцептрони були нездатні обробляти схему виключного «або». Другою було те, що комп'ютери не мали достатньої обчислювальної потужності для ефективного виконання роботи, потрібної великим нейронним мережам. Дослідження нейронних мереж уповільнилося, поки комп'ютери не досягли набагато більшої обчислювальної потужності.
Значну частину штучного інтелекту було зосереджено на оброблюваних алгоритмами високорівневих (символьних) моделях, які характеризують, наприклад, експертні системи зі знаннями, втіленими в правилах «якщо — то», поки наприкінці 1980-х років дослідження не поширилися на низькорівневе (саб-символьне) машинне навчання, що характеризується втіленням знання в параметрах пізнавальної моделі.[джерело?]
Зворотне поширення
Ключовим активатором відновлення зацікавленості нейронними мережами та навчанням був алгоритм зворотного поширення Вербоса (1975), який ефективно розв'язував проблему виключного «або», і загалом прискорив навчання багатошарових мереж. Зворотне поширення розповсюджувало член похибки шарами в зворотному напрямку, змінюючи ваги в кожному вузлі.[7]
В середині 1980-х років набула популярності розподілена паралельна обробка під назвою конективізму. Румельхарт та МакКлелланд (1986) описали застосування конективізму для моделювання нейронних процесів.[13]
Метод опорних векторів та інші, значно простіші методи, такі як лінійні класифікатори, поступово наздогнали нейронні мережі за популярністю в машинному навчанні.
Попередні виклики в тренуванні глибинних нейронних мереж було успішно розв'язано за допомогою таких методів, як спонтанне попереднє тренування, в той час як доступна обчислювальна потужність зросла через застосування ГП та розподілених обчислень. Нейронні мережі було розгорнуто в великому масштабі, зокрема, в задачах розпізнавання зображень та відео. Це стало відомим як «глибинне навчання», хоча глибинне навчання не є строго синонімічним до глибинних нейронних мереж.
1992 року було представлено максимізаційне агрегування, щоби допомогти з інваріантністю відносно найменшого зсуву та терпимістю до деформації для допомоги в розпізнаванні тривимірних об'єктів.[14][15][16]
Проблема зникання градієнту впливає на багатошарові мережі прямого поширення, які використовують зворотне поширення, а також на рекурентні нейронні мережі (РНМ).[17][18] З поширенням похибок від шару до шару, вони скорочуються експоненційно з кількістю шарів, стримуючи налаштування ваг нейронів, яке ґрунтується на цих похибках, й особливо вражаючи глибинні мережі.
Щоби подолати цю проблему, Шмідгубер обрав багатошарову ієрархію мереж (1992), попередньо тренованих по одному шарові за раз за допомогою спонтанного навчання, а потім тонко налаштовуваних зворотним поширенням.[19] Бенке (2003) в таких задачах, як відбудова зображень та визначення положень облич, покладався лише на знак градієнту (еластичне зворотне поширення).[20]
Хінтон та ін. (2006) запропонували навчання високорівневих представлень із застосуванням послідовних шарів двійкових або дійснозначних латентних змінних з обмеженою машиною Больцмана[21] для моделювання кожного шару. Щойно навчено достатньо багато шарів, можна застосовувати глибинну архітектуру як породжувальну модель, відтворюючи дані здійсненням вибірки моделлю донизу («спадковий прохід») від збудження ознак верхнього рівня.[22][23] 2012 року Ин та Дін створили мережу, яка вчилася розпізнавати високорівневі поняття, такі як коти, лише з перегляду немічених зображень, взятих з відео YouTube.[24]
Апаратні конструкції
Було створено обчислювальні пристрої в КМОН, як для біофізичного моделювання, так і для нейроморфних обчислень. Нанопристрої[25] для надвеликомасштабного аналізу головних компонент та згортки можуть утворити новий клас нейронних обчислень, оскільки вони є фундаментально аналоговими, а не цифровими (хоча перші втілення й можуть використовувати цифрові пристрої).[26] Чирешан з колегами (2010)[27] з групи Шмідгубера показали, що, незважаючи на проблему зникання градієнту, ГП роблять зворотне поширення придатним для багатошарових нейронних мереж прямого поширення.
Змагання
В період з 2009 по 2012 рік рекурентні нейронні мережі та глибинні нейронні мережі прямого поширення, розроблені в дослідницькій групі Шмідгубера, виграли вісім міжнародних змагань з розпізнавання образів та машинного навчання.[28][29] Наприклад, двоспрямована та багатовимірна довга короткочасна пам'ять (ДКЧП, англ. long short-term memory, LSTM)[30][31][32][33] Ґрейвса та ін. виграла три змагання з розпізнаванні неперервного рукописного тексту на Міжнародній конференції з аналізу та розпізнавання документів (англ. ICDAR) 2009 року без жодного попереднього знання про три мови, яких було потрібно навчитися.[32][31]
Чирешан з колегами виграли змагання з розпізнавання образів, включно зі Змаганням з розпізнавання дорожніх знаків IJCNN 2011 року,[34] Змаганням із сегментування нейронних структур у стеках електронної мікроскопії ISBI 2012 року[35] та іншими. Їхні нейронні мережі були першими, що досягли порівняної з людською, або навіть надлюдської продуктивності[36] на таких еталонах, як розпізнавання дорожніх знаків (IJCNN 2012) та задача рукописних цифр MNIST.
Дослідники показали (2010), що глибинні нейронні мережі, з'єднані з прихованою марковською моделлю з контекстно-залежними станами, які визначають шар виходу нейронної мережі, можуть докорінно знижувати похибки в задачах великословникового розпізнавання мовлення, таких як голосовий пошук.
Втілення цього підходу на основі ГП[37] виграли багато змагань з розпізнавання образів, включно зі Змаганням з розпізнавання дорожніх знаків IJCNN 2011 року,[34] Змаганням із сегментування нейронних структур в ЕМ-стеках ISBI 2012 року,[38] змаганням ImageNet[39] та іншими.
Глибинні, високонелінійні нейронні архітектури, подібні до неокогнітрону[40] та «стандартної архітектури бачення»,[41] натхнені простими та складними клітинами, було попередньо треновано спонтанними методами Хінтоном.[42][22] Команда з його лабораторії виграла змагання 2012 року, спонсороване компанією Merck, для розробки програмного забезпечення для допомоги в пошуку молекул, які можуть ідентифікувати нові ліки.[43]
Згорткові мережі
Починаючи з 2011 року, передовою в мережах прямого поширення глибинного навчання була почерговість згорткових шарів та шарів максимізаційного агрегування,[37][44] увінчаних декількома повно- або частково зв'язаними шарами, за якими йде рівень остаточної класифікації. Навчання зазвичай виконується без спонтанного попереднього навчання.
Такі керовані методи глибинного навчання були першими, що досягли в певних задачах продуктивності, порівняної з людською.[36]
ШНМ змогли гарантувати інваріантність до зсуву, щоби обходитися з маленькими та великими природними об'єктами у великих загромаджених сценах, лише коли інваріантність поширилася за межі зсуву, на всі навчені ШНМ поняття, такі як розташування, тип (мітка класу об'єкта), масштаб, освітлення та інші. Це було реалізовано в еволюційних мережах (ЕМ, англ. Developmental Networks, DN),[45] чиїми втіленнями є мережі «де—що» (англ. Where-What Networks), від WWN-1 (2008)[46] до WWN-7 (2013).[47]
Моделі
(Штучна) нейронна мережа — це мережа простих елементів, званих нейронами, які отримують вхід, змінюють свій внутрішній стан (збудження) відповідно до цього входу, і виробляють вихід, залежний від входу та збудження. Мережа утворюється з'єднанням виходів певних нейронів зі входами інших нейронів з утворенням орієнтованого зваженого графу. Ваги, як і функції, що обчислюють збудження, можуть змінюватися процесом, званим навчанням, який керується правилом навчання.[48]
Нейрони
Нейрон з міткою , що отримує вхід від нейронів-попередників, складається з наступних складових:[48]


- збудження (англ. activation) , що залежить від дискретного параметра часу,
- можливо, порогу (англ. threshold) , що залишається незмінним, якщо його не змінить функція навчання,
- функції збудження (англ. activation function) , яка обчислює нове збудження в заданий час з , та мережевого входу , даючи в результаті відношення




- ,

- та функції виходу (англ. output function) , яка обчислює вихід з активації

- .

Функція виходу часто є просто тотожною функцією.
Нейрон входу (англ. input neuron) не має попередників, а слугує інтерфейсом входу для всієї мережі. Аналогічно, нейрон виходу (англ. output neuron) не має наступників, і відтак слугує інтерфейсом виходу для всієї мережі.
З'єднання та ваги
Мережа (англ. network) складається зі з'єднань (англ. connection), кожне з яких передає вихід нейрону до входу нейрону . В цьому сенсі є попередником (англ. predecessor) , а є наступником (англ. successor) . Кожному з'єднанню призначено вагу (англ. weight) .[48]


Функція поширення
Функція поширення (англ. propagation function) обчислює вхід до нейрону з виходів нейронів-попередників, і зазвичай має вигляд[48]

- .

Правило навчання
Правило навчання (англ. learning rule) — це правило або алгоритм, який змінює параметри нейронної мережі, щоби заданий вхід до мережі видавав придатний вихід. Цей процес навчання зазвичай полягає в зміні ваг та порогів змінних мережі.[48]
Нейронні мережі як функції
Нейромережеві моделі можна розглядати як прості математичні моделі, що визначають функцію , або розподіл над , або над та . Іноді моделі тісно пов'язують з певним правилом навчання. Поширене використання фрази «модель ШНМ» насправді є визначенням класу таких функцій (де членів цього класу отримують варіюванням параметрів, ваг з'єднань, або особливостей архітектури, таких як число нейронів або їхня зв'язність).



З математичної точки зору, нейромережеву функцію визначають як композицію інших функцій , які може бути розкладено далі на інші функції. Це може бути зручно представляти як мережеву структуру, де стрілки зображують залежність між функціями. Широко вживаним способом компонування є нелінійна зважена сума, де , де (що часто називають функцією збудження, англ. activation function[49]) є визначеною наперед функцією, такою як гіперболічний тангенс, або сигмоїдна функція, або нормована експоненційна функція, або випрямляльна функція. Важливою характеристикою функції збудження є те, що вона забезпечує плавний перехід при зміні значень входу, тобто, невелика зміна входу призводить до невеликої зміни виходу. Наведене нижче розглядає набір функцій як вектор .






.svg.png.webp)
Ця схема зображує такий розклад , із залежностями між змінними, показаними стрілками. Їх може бути інтерпретовано двома способами.

Перший погляд є функційним: вхід перетворювано на 3-вимірний вектор , який відтак перетворювано на 2-вимірний вектор , який нарешті перетворювано на . Цей погляд найчастіше зустрічається в контексті оптимізації.



Другий погляд є ймовірнісним: випадкова змінна залежить від випадкової змінної , яка залежить від , яка залежить від випадкової змінної . Цей погляд найчастіше зустрічається в контексті графових моделей.



Ці два погляди є здебільшого рівнозначними. В кожному з випадків, для цієї конкретної архітектури, складові окремих шарів не залежать одна від одної (наприклад, складові є незалежними одна від одної за заданого їхнього входу ). Це природно уможливлює якусь міру паралелізму в реалізації.
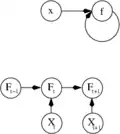
Такі мережі, як попередня, зазвичай називають мережами прямого поширення, оскільки їхній граф є спрямованим ациклічним графом. Мережі з циклами зазвичай називають рекурентними. Такі мережі зазвичай зображують у спосіб, показаний у верхній частині малюнка, де показано як залежну від самої себе. Проте, не показано часову залежність, що мається на увазі.
Навчання
Найбільше зацікавлення нейронними мережами викликала можливість навчання. Для заданої конкретної задачі для розв'язання та класу функцій навчання означає використання набору спостережень для знаходження , яка розв'язує цю задачу в певному оптимальному сенсі.


Це тягне за собою визначення такої функції витрат (англ. cost function) , що, для оптимального розв'язку , — тобто, жоден розв'язок не має витрат, менших за витрати оптимального розв'язку (див. математичну оптимізацію).




Функція витрат є важливим поняттям у навчанні, оскільки вона є мірою того, наскільки далеким є певний розв'язок від оптимального розв'язку задачі, яку потрібно розв'язати. Алгоритми навчання здійснюють пошук простором розв'язків, щоби знайти функцію, яка має найменші можливі витрати.

Для тих застосувань, де розв'язок залежить від даних, витрати обов'язково мусять бути функцією від спостережень, бо інакше модель не матиме зв'язку з даними. Їх часто визначають як статистику, для якої може бути зроблено лише наближення. Як простий приклад, розгляньмо задачу знаходження моделі , яка зводить до мінімуму для пар даних , що витягають з певного розподілу . В практичних ситуаціях ми матимемо лише зразків з , і, відтак, для наведеного вище прикладу ми будемо зводити до мінімуму лише . Таким чином, витрати зводяться до мінімуму над вибіркою з даних, а не над усім розподілом.





Коли , мусить застосовуватися якийсь різновид інтерактивного машинного навчання, в якому витрати знижуються з кожним побаченим зразком. І хоча інтерактивне машинне навчання часто застосовують за незмінного , найкориснішим воно є у випадку, коли цей розподіл повільно змінюється з часом. В нейромережевих методах якісь різновиди інтерактивного машинного навчання часто застосовують для скінченних наборів даних.

Обирання функції витрат
Навіть коли можливо визначити функцію витрат ad hoc, часто використовують конкретні витрати (функцію витрат), або через те, що вони мають бажані властивості (такі як опуклість), або через те, що вони природно виникають з певного формулювання задачі (наприклад, у ймовірнісному формулюванні як обернені витрати можна використовувати апостеріорну ймовірність моделі). Кінець кінцем, функція витрат залежить від задачі.
Зворотне поширення
ГНМ може бути треновано розрізнювально за допомогою стандартного алгоритму зворотного поширення (англ. backpropagation). Зворотне поширення — це метод обчислення градієнту функції втрат (видає витрати, пов'язані з заданим станом) по відношенню до ваг в ШНМ.
Основи неперервного зворотного поширення[9][50][51][52] було виведено в контексті теорії керування Келлі[53] 1960 року та Брайсоном 1961 року[54] з використанням принципів динамічного програмування. 1962 року Дрейфус опублікував простіше виведення, засноване лише на ланцюговому правилі.[55] Брайсон та Хо описали його як метод багатоетапної оптимізації динамічних систем 1969 року.[56][57] 1970 року Ліннаінмаа остаточно опублікував загальний метод автоматичного диференціювання (АД) дискретних зв'язних мереж вкладених диференційовних функцій.[58][59] Він відповідає сучасному баченню зворотного поширення, яке є ефективним навіть коли мережі є розрідженими.[9][50][60][61] 1973 року Дрейфус застосував зворотне поширення для пристосування параметрів контролерів пропорційно градієнтам похибок.[62] 1974 року Вербос зазначив можливість застосування цього принципу до ШНМ,[63] і 1982 року він застосував метод АД Ліннаінмаа до нейронних мереж способом, який широко застосовується сьогодні.[50][64] 1986 року Румельхарт, Хінтон та Вільямс зазначили, що цей метод може породжувати корисні внутрішні представлення вхідних даних в прихованих шарах нейронних мереж.[65] 1993 року Ван став першим[9] переможцем міжнародного змагання з розпізнавання образів за допомогою зворотного поширення.[66]
Уточнення ваг зворотного поширення можливо здійснювати за допомогою стохастичного градієнтного спуску із застосуванням наступного рівняння:

де є темпом навчання, є функцією витрат (втрат), а — стохастичним членом. Вибір функції витрат залежить від таких чинників як тип навчання (кероване, спонтанне, з підкріпленням тощо) та функції збудження. Наприклад, при здійсненні керованого навчання на задачі багатокласової класифікації поширеними варіантами вибору функції збудження та функції витрат є нормована експоненційна функція та функція перехресної ентропії відповідно. Нормалізовану експоненційну функцію визначають як , де представляє ймовірність класу (вихід вузла ), а та представляють загальний вхідний сигнал вузлів та одного й того ж рівня відповідно. Перехресну ентропію визначають як , де представляє цільову ймовірність для вузла виходу , а є виходом ймовірності для після застосування функції збудження.[67]










Це можливо використовувати для виведення обмежувальних коробок об'єкта у вигляді двійкової маски. Їх також використовують для багатомасштабної регресії для підвищення точності визначення положення. Регресія на основі ГНМ може навчатися ознак, що схоплюють геометричну інформацію, на додачу до того, що вони слугують добрим класифікатором. Вони усувають вимогу явного моделювання частин та їхніх взаємозв'язків. Це допомагає розширити розмаїття об'єктів, яких можна навчитися. Модель складається з декількох шарів, кожен з яких має випрямляч як функцію збудження для нелінійного перетворення. Деякі шари є згортковими, тоді як деякі є повнозв'язними. Кожен згортковий шар має додаткове максимізаційне агрегування. Мережу тренують для зведення до мінімуму похибки L2 для передбачування маски, що пробігає весь тренувальний набір, що містить обмежувальні коробки, представлені як маски.
До альтернатив зворотному поширенню належать машини екстремального навчання,[68] «безпоширні» (англ. «No-prop») мережі,[69] тренування без пошуку з вертанням,[70] «безвагові» (англ. weightless) мережі[71][72] та не-конективістські нейронні мережі.
Парадигми навчання
Існує три основні парадигми навчання, кожна з яких відповідає певній навчальній задачі. Ними є кероване навчання, спонтанне навчання та навчання з підкріпленням.
Кероване навчання
Кероване навчання (англ. supervised learning) використовує набір прикладів пар , і має на меті пошук функції в дозволеному класі функцій, яка відповідає цим прикладам. Іншими словами, ми хочемо вивести відображення, на яке натякають ці дані; функцію витрат пов'язано з невідповідністю між нашим відображенням та даними, і вона неявно містить апріорне знання про предметну область.[73]


Широко вживаними витратами є середньоквадратична похибка, яка намагається звести до мінімуму усереднену квадратичну похибку між виходом мережі, , та цільовим значення над усіма прикладами пар. Зведення до мінімуму цих витрат за допомогою градієнтного спуску для класу нейронних мереж, званого багатошаровими перцептронами (БШП), дає алгоритм зворотного поширення для тренування нейронних мереж.


Задачами, що вписуються до парадигми керованого навчання, є розпізнавання образів (відоме також як класифікація) та регресія (відома також як наближення функцій). Парадигма керованого навчання є застосовною також і до послідовнісних даних (наприклад, до розпізнавання писання вручну, мовлення та жестів). Його можна розглядати як навчання з «учителем» у вигляді функції, яка забезпечує постійний зворотний зв'язок стосовно якості отриманих досі розв'язків.
Спонтанне навчання
У спонтанному навчанні (англ. unsupervised learning) даються якісь дані та функція витрат для зведення до мінімуму, якою може бути будь-яка функція від даних та виходу мережі .
Функція витрат залежить від задачі (предметної області моделі) та наявних апріорних припущень (неявних властивостей моделі, її параметрів, та спостережуваних змінних).
Як тривіальний приклад, розгляньмо модель , де є сталою, а витрати . Зведення до мінімуму цих витрат дає значення , яке дорівнює середньому значенню даних. Функція витрат може бути набагато складнішою. Її вигляд залежить від застосування: наприклад, у стисненні її може бути пов'язано зі взаємною інформацією між та , тоді як у статистичному моделюванні її може бути пов'язано з апостеріорною ймовірністю моделі за заданих даних (зауважте, що в обох цих прикладах ці величини зводитимуться до максимуму, а не до мінімуму).



Задачі, що вписуються до парадигми спонтанного навчання, є загалом задачами оцінювання; до застосувань належать кластерування, оцінювання статистичних розподілів, стиснення та фільтрування.
Навчання з підкріпленням
У навчанні з підкріпленням (англ. reinforcement learning) дані зазвичай не надаються, а породжуються взаємодією агента з середовищем. В кожен момент часу агент виконує дію , а середовище породжує спостереження та миттєві витрати відповідно до якоїсь (зазвичай невідомої) динаміки. Метою є визначити таку стратегію (англ. policy) вибору дій, яка зводить до мінімуму якусь міру довготривалих витрат, наприклад, очікувані сукупні витрати. Динаміка середовища та довготривалі витрати для кожної зі стратегій є зазвичай невідомими, але їх може бути оцінено.




Формальніше, середовище моделюють як марковський процес вирішування (МПВ) зі станами та діями з наступними розподілами ймовірності: розподілом миттєвих витрат , розподілом спостережень та переходом , тоді як стратегію визначають як умовний розподіл над діями за заданих спостережень. Взята разом, ця двійка відтак утворює марковський ланцюг (МЛ). Метою є визначити таку стратегію (тобто, МЛ), що зводить витрати до мінімуму.





ШНМ часто використовують у навчанні з підкріпленням як частину загального алгоритму.[74][75] Динамічне програмування було зв'язано з ШНМ (давши нейродинамічне програмування) Берцекасом та Цициклісом[76] і застосовано до багатовимірних нелінійних задач, таких як присутні в маршрутизувані транспорту,[77] природокористуванні[78][79] та медицині,[80] через здатність ШНМ пом'якшувати втрати точності навіть при зниженні щільності ґратки дискретизації для чисельного наближення розв'язків первинних задач керування.
Задачами, які вписуються до парадигми навчання з підкріпленням, є задачі керування, ігри та інші задачі послідовного ухвалювання рішень.
Алгоритм збіжного рекурсивного навчання
Алгоритм збіжного рекурсивного навчання (англ. convergent recursive learning algorithm) — метод навчання, розроблений спеціально для нейронних мереж артикуляційних контролерів мозочкової моделі (АКММ, англ. cerebellar model articulation controller, CMAC). 2004 року було представлено рекурсивний алгоритм найменших квадратів для інтерактивного тренування нейронної мережі АКММ.[81] Цей алгоритм може збігатися за один крок та уточнювати всі ваги за один крок із будь-якими новими вхідними даними. Початково він мав обчислювальну складність O(N3). На основі QR-розкладу цей рекурсивний алгоритм навчання було спрощено до O(N).[82]
Алгоритми навчання
Тренування нейронної мережі по суті означає вибирання однієї моделі з множини дозволених моделей (або, в баєсовій системі, визначення розподілу над множиною дозволених моделей), що зводить витрати до мінімуму. Доступні численні алгоритми для тренування нейромережевих моделей; більшість із них можна розглядати як безпосереднє застосування теорії оптимізації та статистичного оцінювання.
Більшість використовують градієнтний спуск якогось вигляду, застосовуючи зворотне поширення для обчислення фактичних градієнтів. Це здійснюється просто взяттям похідної від функції витрат по відношенню до параметрів мережі, з наступною зміною цих параметрів у пов'язаному з градієнтом напрямку. Алгоритми тренування зворотним поширенням поділяються на три категорії:
- найшвидший спуск (зі змінним темпом навчання та імпульсом, еластичним зворотним поширенням);
- квазі-ньютонові (Бройден — Флетчер — Гольдфарб — Шанно, однокрокова січна);
- Левенберг — Марквардт та спряжені градієнти (уточнення Флетчера — Рівза, уточнення Поляка — Ріб'єра, перезапуск Павелла — Біла, масштабований спряжений градієнт).[83]
Іншими методами для тренування нейронних мереж є еволюційні методи,[84] генно-експресійне програмування,[85] імітування відпалювання,[86] очікування-максимізація, непараметричні методи та метод рою часток.[87]
Варіанти
Метод групового урахування аргументів
Метод групового урахування аргументів (МГУА, англ. Group Method of Data Handling, GMDH)[88] демонструє повністю автоматичну структурну та параметричну оптимізацію моделей. Функціями збудження вузлів є поліноми Колмогорова — Габора, що дозволяють додавання та множення. Він використовує глибинний багатошаровий перцептрон прямого поширення з вісьмома шарами.[89] Він є мережею керованого навчання, що росте шар за шаром, де кожен з шарів треновано регресійним аналізом. Непотрібні елементи виявляються застосуванням затверджувального набору та обрізаються шляхом регуляризації. Розмір та глибина отримуваної в результаті мережі залежить від задачі.[90]
Згорткові нейронні мережі
Згорткова нейронна мережа (ЗНМ, англ. convolutional neural network, CNN) — це клас глибинних мереж прямого поширення, складених з одного чи більше згорткових шарів, із повноз'єднаними шарами (що відповідають шарам звичайних ШНМ) на верхівці. Він використовує зв'язані ваги та шари агрегування. Зокрема, за згортковою архітектурою Фукусіми[91] часто зорганізовують максимізаційне агрегування.[15] Ця архітектура дозволяє ЗНМ отримувати користь від двовимірної структури вхідних даних.
ЗНМ є зручними для обробки візуальних та інших двовимірних даних.[92][93] Вони показали чудові результати в застосуваннях як для зображень, так і для мовлення. Їх може бути треновано стандартним зворотним поширенням. ЗНМ є простішими для тренування за інші звичайні глибинні нейронні мережі прямого поширення, і мають набагато менше параметрів, що треба оцінювати.[94] До прикладів застосування в комп'ютерному баченні належить DeepDream.[95]
Довга короткочасна пам'ять
Мережі довгої короткочасної пам'яті (ДКЧП, англ. long short-term memory, LSTM) — це РНМ, які уникають проблеми зникання градієнту.[96] ДКЧП зазвичай доповнювано рекурентними вентилями, які називають забувальними (англ. forget gates).[97] Мережі ДКЧП запобігають зниканню та вибуханню зворотно поширюваних похибок.[17] Натомість, похибки можуть плинути в зворотному напрямку необмеженим числом віртуальних шарів розгорнутої в просторі ДКЧП. Таким чином, ДКЧП може вчитися задач „дуже глибокого навчання“ (англ. "very deep learning"),[9] що потребують спогадів про події, які сталися тисячі або навіть мільйони дискретних кроків часу тому. Можливо виводити проблемно-орієнтовані ДКЧП-подібні архітектури.[98] ДКЧП може мати справу з тривалими затримками та сигналами, які містять суміш низько- та високочастотних складових.
Стопки РНМ ДКЧП,[99] треновані нейромережевою часовою класифікацією (НЧК, англ. Connectionist Temporal Classification, CTC),[100] можуть знаходити матрицю ваг РНМ, яка зводить до максимуму ймовірність послідовностей міток у тренувальному наборі для відповідних заданих вхідних послідовностей. НЧК досягає як вирівнювання, так і розпізнавання.
2003 року ДКЧП почала ставати конкурентноздатною в порівнянні з традиційними розпізнавачами мовлення.[101] 2007 року, в поєднанні з НЧК, досягла перших добрих результатів на даних мовлення.[102] 2009 року ДКЧП, тренована НЧК, стала першою РНМ, яка перемогла в змаганнях із розпізнавання образів, коли вона виграла кілька змагань із неперервного рукописного розпізнавання.[9][32] 2014 року Baidu використала ДКЧП на основі НЧК, щоби перевершити еталон розпізнавання мовлення Switchboard Hub5'00, без традиційних методів обробки мовлення.[103] ДКЧП також поліпшила велико-словникове розпізнавання мовлення,[104][105] синтез мовлення з тексту,[106] для Google Android,[50][107] і фото-реалістичні голови, що розмовляють.[108] 2015 року розпізнавання мовлення Google зазнало 49-відсоткового покращення завдяки ДКЧП, тренованій НЧК.[109]
ДКЧП набула популярності в обробці природної мови. На відміну від попередніх моделей на основі ПММ та подібних концепцій, ДКЧП може навчатися розпізнавання контекстно-чутливих мов.[110] ДКЧП поліпшила машинний переклад,[111] моделювання мов[112] та багатомовну обробку мов.[113] ДКЧП у поєднанні з ЗНМ поліпшила автоматичний опис зображень.[114]
Глибинне резервуарне обчислення
Глибинне резервуарне обчислення (англ. Deep Reservoir Computing) та глибинні мережі з відлунням стану (англ. Deep Echo State Networks, deepESN)[115][116] забезпечують систему для ефективного тренування моделей для ієрархічної обробки часових даних, в той же час уможливлюючи дослідження властивої ролі шаруватого компонування РНМ.
Глибинні мережі переконань
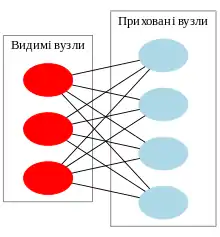
Глибинна мережа переконань (ГМП, англ. deep belief network, DBN) — це ймовірнісна породжувальна модель, складена з декількох шарів прихованих вузлів. Її можна розглядати як композицію простих модулів навчання, що складають кожен з шарів.[117]
ГМП можливо використовувати для породжувального попереднього тренування ГНМ шляхом використання навчених ваг ГМП як початкових ваг ГНМ. Ці ваги потім може налаштовувати зворотне поширення або інші розрізнювальні алгоритми. Це є особливо корисним, коли тренувальні дані є обмеженими, оскільки ваги з погано заданими початковими значеннями можуть значно заважати продуктивності моделі. Ці попередньо натреновані ваги перебувають в області простору ваг, що є ближчою до оптимальних ваг, ніж якби їх було обрано випадково. Це уможливлює як поліпшене моделювання, так і швидшу збіжність фази тонкого налаштування.[118]
Нейронні мережі зберігання та вибірки великої пам'яті
Нейронні мережі зберігання та вибірки великої пам'яті (англ. large memory storage and retrieval, LAMSTAR)[119][120] є швидкими нейронними мережами глибинного навчання з багатьма шарами, які можуть використовувати багато фільтрів одночасно. Ці фільтри можуть бути нелінійними, стохастичними, логічними, не стаціонарними та навіть не аналітичними. Вони є біологічно натхненними, і навчаються безперервно.
Нейронна мережа LAMSTAR може слугувати динамічною нейронною мережею в просторовій, часовій області визначення, та в обох. Її швидкість забезпечується геббовими вагами з'єднань,[121] що об'єднують різні та, як правило, несхожі фільтри (функції попередньої обробки) у її численні шари, і для динамічного ранжування значимості різних шарів та функцій по відношенню до заданої задачі для навчання. Це грубо імітує біологічне навчання, що об'єднує різні попередні обробники (зави́тку, сітківку тощо), кори (слухову, зорову тощо) та різні їхні області. Її здатність до глибинного навчання додатково підсилюється використанням пригнічування, кореляції та її здатністю впоруватися з неповними даними, або „втраченими“ нейронами чи шарами навіть посеред завдання. Через свої ваги з'єднань вона є повністю прозорою. Ці ваги з'єднань також уможливлюють динамічне визначення нововведення й надмірності, та слугують ранжуванню по відношенню до завдання шарів, фільтрів та окремих нейронів.
LAMSTAR застосовували в багатьох областях, включно з медичними[122][123][124] та фінансовими прогнозуваннями,[125] адаптивним фільтруванням зашумленого мовлення в невідомому шумі,[126] розпізнаванням нерухомих зображень,[127] розпізнаванням відеозображень,[128] безпекою програмного забезпечення[129] та адаптивним керуванням нелінійними системами.[130] LAMSTAR мала значно вищу швидкість навчання та дещо нижчий рівень похибок, ніж ЗНМ на основі фільтрів на випрямлячі та максимізаційному агрегуванні, у 20 порівняльних дослідженнях.[131]
Ці застосування показують занурення в аспекти даних, що є прихованими від мереж поверхневого навчання та людських чуттів, як у випадках передбачення настання подій апное уві сні,[123] електрокардіограми плоду при записі з електродів, розташованих на поверхні шкіри живота матері в ранній період вагітності,[124] фінансового прогнозування[119] та сліпого фільтрування зашумленого мовлення.[126]
LAMSTAR було запропоновано 1996 року (A U.S. Patent 5 920 852 A), і розвинуто далі Ґраупе та Кордилевським у 1997—2002 роках.[132][133][134] Видозмінену версію, відому як LAMSTAR 2, було розроблено Шнайдером та Ґраупе 2008 року.[135][136]
Складені (знешумлювальні) автокодувальники
Ідею автокодувальника продиктовано поняттям доброго представлення. Наприклад, для класифікатора добре представлення може бути визначено як таке, що дає ефективніший класифікатор.
Кодувальник (англ. encoder) — це детерміністське відображення , що перетворює вхідний вектор x на приховане представлення y, де , є ваговою матрицею, а b є вектором зсуву (англ. offset, bias). Декодувальник (англ. decoder) відображає приховане представлення y назад на відтворюваний вхід z через . Весь процес автокодування є порівнянням цього відтвореного входу з оригінальним, і намаганням мінімізувати цю похибку, щоби зробити відтворене значення якомога ближчим до оригінального.




В складених знешумлювальних автокодувальниках (англ. stacked denoising auto encoders) частково спотворений вихід очищується (знешумлюється, англ. de-noised). Цю ідею було представлено 2010 року Венсаном та ін.[137] разом з особливим підходом до доброго представлення, добре представлення є таким, що може бути надійно отримано зі спотвореного входу, і буде корисним для відновлення відповідного чистого входу. Неявними в цьому визначенні є наступні ідеї:
- Представлення вищого рівня є відносно стабільними й стійкими до спотворень входу;
- Необхідно виділяти ознаки, що є корисними для представлення розподілу входу.
Алгоритм починається зі стохастичного відображення на через , це є спотворювальним кроком. Потім спотворений вхід проходить основним процесом автокодування, і відображується на приховане представлення . З цього прихованого представлення ми можемо відтворити . На останній стадії з метою отримання z якомога ближче до неспотвореного входу виконується алгоритм мінімізації. Похибка відтворення може бути або перехресно-ентропійною втратою з афінно-сигмоїдним декодувальником, або квадратично-похибковою втратою з афінним декодувальником.[137]






Для отримання глибинної архітектури автокодувальники накладають.[138] Щойно кодувальної функції першого знешумлювального автокодувальника навчено, й використано її для знеспотворення входу (спотвореного входу), то може бути треновано другий рівень.[137]
Щойно складений автокодувальник натреновано, його вихід може бути використано як вхід до алгоритму керованого навчання, такого як класифікатор методом опорних векторів або багатокласова логістична регресія.[137]
Глибинні складальні мережі
Глибинна складальна мережа (ГСМ, англ. deep stacking network, DSN)[139] (глибинна опукла мережа, англ. deep convex network) ґрунтується на ієрархії блоків спрощених нейромережевих модулів. Її було представлено 2011 року Деном та Доном.[140] Вона формулює навчання як задачу опуклої оптимізації з розв'язком замкненого вигляду, підкреслюючи подібність цього механізму до складеного узагальнення (англ. stacked generalization).[141] Кожен блок ГСМ є простим модулем, який легко тренувати сам по собі керованим чином без зворотного поширення для всіх блоків.[142]
Кожен блок складається зі спрощеного багатошарового перцептрону (БШП) з єдиним прихованим шаром. Прихований шар h має логістичні сигмоїдні вузли, а шар виходу має лінійні вузли. З'єднання між цими шарами представлено ваговою матрицею U; з'єднання з вхідного до прихованого шару мають вагову матрицю W. Цільові вектори t утворюють стовпчики матриці T, а вектори вхідних даних x утворюють стовпчики матриці X. Матрицею прихованих вузлів є . Модулі тренуються по черзі, тож ваги нижчого рівня W на кожному етапі є відомими. Функція виконує поелементну логістичну сигмоїдну дію. Кожен із блоків оцінює один і той самий клас кінцевих міток y, і його оцінка поєднується з первинним входом X, утворюючи розширений вхід для наступного блоку. Таким чином, вхід до першого блоку містить лише первинні дані, тоді як до входів блоків нижче за течією додається також і вихід попередніх блоків. Тоді навчання вагової матриці U вищого рівня за заданих ваг в мережі може бути сформульовано як задачу опуклої оптимізації:


що має розв'язок замкненого вигляду.
На відміну від інших глибинних архітектур, таких як ГМП, метою є не відкриття представлення в перетворених ознаках. Структура ієрархії цього типу архітектури робить паралельне тренування прямолінійним, як задачу оптимізації в пакетному режимі. В чисто розрізнювальних задачах ГСМ працюють краще за звичайні ГМП.[139]
Тензорні глибинні складальні мережі
Ця архітектура є розширенням глибинних складальних мереж (ГСМ). Вона пропонує два важливі поліпшення: вона використовує інформацію вищого порядку з коваріаційних статистик, і перетворює неопуклу задачу нижчого рівня на опуклу підзадачу вищого рівня.[143] ТГСМ використовують коваріаційні статистики у білінійному відображенні з кожного з двох окремих наборів прихованих вузлів одного й того ж рівня на передбачення, через тензор третього порядку.
Хоча розпаралелювання та масштабованість і не розглядаються серйозно в звичайних ГНМ,[144][145][146] все навчання ГСМ і ТГСМ здійснюється в пакетному режимі, щоби уможливлювати розпаралелювання.[140][139] Розпаралелювання дозволяє масштабувати цю конструкцію на більші (глибші) архітектури та набори даних.
Основна архітектура є придатною для різнопланових задач, таких як класифікація та регресія.
Піково-пластинові обмежені машини Больцмана
Потреба в глибинному навчанні з дійснозначними входами, як у ґаусових обмежених машинах Больцмана, привела до піково-пластинових ОМБ (ппОМБ, англ. spike and slab Restricted Boltzmann machine, ssRBM), які моделюють безперервнозначні входи строго двійковими латентними змінними.[147] Подібно до базових ОМБ та її варіантів, піково-пластинова ОМБ є двочастковим графом, але, як у ҐОМБ, видимі вузли (входи) є дійснозначними. Відмінність є в прихованому шарі, де кожен прихований вузол має змінну двійкового піку (англ. spike) та змінну дійснозначної пластини (англ. slab). Пік є дискретною масою ймовірності на нулі, тоді як пластина є густиною ймовірності над безперервною областю визначення;[148] їхня суміш формує апріорне.[149]
Розширення ппОМБ, що називається µ-ппОМБ, забезпечує додаткові моделювальні потужності, використовуючи додаткові члени в енергетичній функції. Один із цих членів дає моделі можливість формувати умовний розподіл пікових змінних знеособленням пластинових змінних за заданого спостереження.
Змішані ієрархічно-глибинні моделі
Змішані ієрархічно-глибинні моделі (англ. compound hierarchical-deep models, compound HD models) компонують глибинні мережі з непараметричними баєсовими моделями. Ознак можливо навчатися із застосуванням таких глибинних архітектур як ГМП,[150] ГМБ,[151] глибинні автокодувальники,[152] згорткові варіанти,[153][154] ппОМБ,[148] мережі глибинного кодування,[155] ГМП з розрідженим навчанням ознак,[156] РНМ,[157] умовні ГМП,[158] знешумлювальні автокодувальники.[159] Це забезпечує краще представлення, уможливлюючи швидше навчання та точнішу класифікацію із даними високої розмірності. Проте ці архітектури є слабкими в навчанні нововведених класів на кількох прикладах, оскільки всі вузли мережі залучено до представлення входу (розподілене представлення), і мусить бути приладжувано разом (високий ступінь свободи). Обмеження ступеню свободи знижує кількість параметрів для навчання, допомагаючи навчанню нових класів з кількох прикладів. Ієрархічні баєсові (ІБ) моделі (англ. Hierarchical Bayesian (HB) models) забезпечують навчання з кількох прикладів, наприклад,[160][161][162][163][164] для комп'ютерного бачення, статистики та когнітивної науки.
Змішані ІГ-архітектури мають на меті поєднання характеристик як ІБ, так і глибинних мереж. Змішана архітектура ІПД-ГМБ є ієрархічним процесом Діріхле (ІПД) як ієрархічною моделлю, об'єднаною з архітектурою ГМБ. Вона є повністю породжувальною моделлю, узагальнюваною з абстрактних понять, що течуть крізь шари цієї моделі, яка є здатною синтезувати нові приклади нововведених класів, що виглядають «досить» природними. Навчання всіх рівнів відбувається спільно, зведенням до максимуму функції внеску логарифмічної ймовірності.[165]
У ГМБ з трьома прихованими шарами ймовірністю видимого входу ν є

де є набором прихованих вузлів, а є параметрами моделі, що представляють умови симетричної взаємодії видимі-приховані та приховані-приховані.


Навчена модель ГМБ є неорієнтованою моделлю, що визначає спільний розподіл . Одним із шляхів вираження того, чого було навчено, є умовна модель та апріорний член .



Тут представляє умовну модель ГМБ, що можливо розглядати як двошарову ГМБ, але з умовами зсуву, що задаються станами :


Глибинні передбачувальні кодувальні мережі
Глибинна передбачувальна кодувальна мережа (ГПКМ, англ. Deep predictive coding network, DPCN) — це передбачувальна схема кодування, що використовує спадну інформацію для емпіричного підлаштовування апріорних, необхідних для процедури висхідного висновування, засобами глибинної локально з'єднаної породжувальної моделі. Це працює шляхом виділяння розріджених ознак зі спостережень, що змінюються в часі, із застосуванням лінійної динамічної моделі. Потім для навчання інваріантних представлень ознак застосовується стратегія агрегування (англ. pooling). Ці блоки компонуються, щоби сформувати глибинну архітектуру, і тренуються жадібним пошаровим спонтанним навчанням. Шари утворюють щось на зразок марковського ланцюга, такого, що стани на будь-якому шарі залежать лише від наступного та попереднього шарів.
ГПКМ передбачують представлення шару, використовуючи спадний підхід із застосуванням інформації з вищого шару та часових залежностей від попередніх станів.[166]
ГПКМ можливо розширювати таким чином, щоби утворювати згорткову мережу.[166]
Мережі з окремими структурами пам'яті
Поєднання зовнішньої пам'яті з ШНМ бере свій початок у ранніх дослідженнях розподілених представлень[167] та самоорганізаційних відображень Кохонена. Наприклад, у розрідженій розподіленій пам'яті та ієрархічній часовій пам'яті зразки, закодовані нейронними мережами, використовуються як адреси для асоціативної пам'яті, з «нейронами», що по суті слугують шифраторами та дешифраторами адреси. Проте, ранні контролери таких типів пам'яті не були диференційовними.
Диференційовні структури пам'яті, пов'язані з ДКЧП
Окрім довгої короткочасної пам'яті (ДКЧП), диференційовну пам'ять до рекурентних функцій також додали й інші підходи. Наприклад:
- Диференційовні дії проштовхування та виштовхування для мереж альтернативної пам'яті, що називаються нейронними стековими машинами (англ. neural stack machines)[168][169]
- Мережі пам'яті, в яких зовнішнє диференційовне сховище керівної мережі знаходиться у швидких вагах іншої мережі[170]
- Забувальні вентилі ДКЧП[171]
- Автореферентні РНМ з особливими вузлами виходу для адресування та швидкого маніпулювання власними вагами РНМ на диференційовний манір (внутрішнє сховище)[172][173]
- Навчання перетворення з необмеженою пам'яттю[174]
Нейронні машини Тюрінга
Нейронні машини Тюрінга (англ. Neural Turing machines)[175] спаровують мережі ДКЧП із зовнішніми ресурсами пам'яті, з якими вони можуть взаємодіяти за допомогою процесів уваги (англ. attentional processes). Ця зв'язана система є аналогічною машині Тюрінга, але є диференційовною з краю в край, що дозволяє їй дієво навчатися градієнтним спуском. Попередні результати показують, що нейронні машини Тюрінга можуть виводити з прикладів входу та виходу прості алгоритми, такі як копіювання, впорядкування та асоціативне пригадування.
Диференційовні нейронні комп'ютери (англ. Differentiable neural computers, DNC) — це розширення нейронних машин Тюрінга. На задачах обробки послідовностей вони перевершили нейронні машини Тюрінга, системи довгої короткочасної пам'яті та мережі з пам'яттю.[176][177][178][179][180]
Семантичне гешування
Підходи, які представляють попередній досвід безпосередньо, і використовують схожий досвід для формування локальної моделі, часто називають методами найближчого сусіда або k-найближчих сусідів.[181] В семантичному гешуванні (англ. semantic hashing) є корисним глибинне навчання,[182] де з великого набору документів отримується глибинна графова модель векторів кількостей слів.[183] Документи відображуються на комірки пам'яті таким чином, що семантично схожі документи розташовуються за близькими адресами. Потім документи, схожі на документ із запиту, можливо знаходити шляхом простого доступу до всіх адрес, що відрізняються від адреси документа із запиту лише кількома бітами. На відміну від розрідженої розподіленої пам'яті, що оперує 1000-бітними адресами, семантичне гешування працює на 32- або 64-бітних адресах, що зустрічаються в традиційній комп'ютерній архітектурі.
Мережі з пам'яттю
Мережі з пам'яттю (англ. memory networks)[184][185] є іншим розширенням нейронних мереж, що включає довготривалу пам'ять. Довготривала пам'ять може читатися або записуватися з метою використання її для передбачення. Ці моделі застосовувалися в контексті питально-відповідальних систем (англ. question answering, QA), де довготривала пам'ять ефективно діє як (динамічна) база знань, а вихід є текстовою відповіддю.[186]
Вказівникові мережі
Глибинні мережі може бути потенційно поліпшено поглибленням та скороченням параметрів, за збереження здатності до навчання. В той час як тренування надзвичайно глибоких (наприклад, завглибшки мільйон шарів) нейронних мереж може бути непрактичним, ЦП-подібні архітектури, такі як вказівникові мережі (англ. pointer networks)[187] та нейронні машини з довільним доступом (англ. neural random-access machines),[188] долають це обмеження завдяки застосуванню зовнішньої пам'яті з довільним доступом та інших складових, що зазвичай належать до комп'ютерної архітектури, таких як регістри, АЛП та вказівники. Такі системи працюють на векторах розподілів імовірностей, що зберігаються в комірках пам'яті та регістрах. Таким чином, ця модель є повністю диференційовною і тренується з краю в край. Ключовою характеристикою цих моделей є те, що їхня глибина, розмір їхньої короткочасної пам'яті та число параметрів можливо змінювати незалежно — на відміну від моделей на кшталт ДКЧП, чиє число параметрів зростає квадратично з розміром пам'яті.
Кодувально-декодувальні мережі
Кодувально-декодувальні системи (англ. encoder–decoder frameworks) ґрунтуються на нейронних мережах, що відображують високоструктурований вхід на високоструктурований вихід. Цей підхід виник у контексті машинного перекладу,[189][190][191] де вхід та вихід є писаними реченнями двома природними мовами. В тій праці РНМ або ЗНМ ДКЧП використовувалася як кодувальник для отримання зведення про вхідне речення, і це зведення декодувалося умовною РНМ-моделлю мови для продукування перекладу.[192] Для цих систем є спільними будівельні блоки: вентильні (англ. gated) РНМ та ЗНМ, і треновані механізми уваги.
Багатошарова ядрова машина
Багатошарові ядрові машини (БЯМ, англ. Multilayer Kernel Machine, MKM) — це спосіб навчання високо нелінійних функцій за допомогою ітеративного застосування слабко нелінійних ядер. Вони використовують ядровий метод головних компонент (ЯМГК, англ. kernel principal component analysis, KPCA)[193] як метод для спонтанного жадібного пошарового передтренувального кроку архітектури глибинного навчання.[194]
-й шар навчається представлення попереднього шару , виділяючи головних компонент (ГК, англ. principal component, PC) проекції, яку шар виводить в область визначення ознак під дією ядра. Заради зниження в кожному шарі розмірності уточненого представлення пропонується керована стратегія для вибору найінформативніших ознак серед виділених ЯМГК. Цей процес є таким:



- вишикувати ознак відповідно до їхньої взаємної інформації з мітками класів;
- для різних значень K та обчислити рівень похибки класифікації методом K-найближчих сусідів (К-НС, англ. K-nearest neighbor, K-NN), використовуючи лише ознак, найінформативніших на затверджувальному наборі;
- значення , з яким класифікатор досяг найнижчого рівня похибки, визначає число ознак для збереження.


Метод ЯМГК як будівельні блоки для БЯМ супроводжують деякі недоліки.
Для розуміння усного мовлення було розроблено простіший спосіб застосування ядрових машин для глибинного навчання.[195] Головна ідея полягає у використанні ядрової машини для наближення поверхневої нейронної мережі з нескінченним числом прихованих вузлів, і подальшому застосуванні складання для зрощування виходу цієї ядрової машини та сирого входу при побудові наступного, вищого рівня ядрової машини. Число рівнів у цій глибинній опуклій мережі є гіперпараметром системи в цілому, який повинен визначатися перехресною перевіркою.
Використання
Використання ШНМ вимагає розуміння їхніх характеристик.
- Вибір моделі: Це залежить від представлення даних та застосування. Надмірно складні моделі уповільнюють навчання.
- Алгоритм навчання: Існують численні компроміси між алгоритмами навчання. Майже кожен алгоритм працюватиме добре з правильними гіперпараметрами для тренування на певному наборі даних. Проте, обрання та налаштування алгоритму для тренування на небачених даних вимагає значного експериментування.
- Робастність: Якщо модель, функція витрат та алгоритм навчання обрано належним чином, то отримувана в результаті ШНМ може стати робастною.
Можливості ШНМ підпадають під наступні широкі категорії:[джерело?]
- Наближення функцій, або регресійний аналіз, включно з передбачуванням часових рядів, наближенням пристосованості та моделюванням.
- Класифікація, включно з розпізнаванням образів та послідовностей, виявленням нововведень та послідовним ухвалюванням рішень.
- Обробка даних, включно з фільтруванням, кластеруванням, сліпим відокремлюванням сигналу та стисненням.
- Робототехніка, включно зі скеровуванням маніпуляторів та протезів.
- Автоматичне керування, включно з числовим програмним керуванням.
Застосування
Через свою здатність відтворювати та моделювати нелінійні процеси, ШНМ знайшли застосування в широкому діапазоні дисциплін.
До областей застосування належать ідентифікація систем та керування (керування транспортними засобами, передбачування траєкторії,[196] автоматизація виробничих процесів, природокористування), квантова хімія,[197] гра в ігри та ухвалювання рішень (короткі нарди, шахи, покер), розпізнавання образів (радарні системи, ідентифікація облич, класифікація сигналів,[198] розпізнавання об'єктів та ін.), розпізнавання послідовностей (жестів, мовлення, рукописного тексту), медична діагностика, фінанси[199] (наприклад, автоматизовані системи торгівлі), добування даних, унаочнення, машинний переклад, соціально-мережеве фільтрування[200] та фільтрування спаму електронної пошти.
ШНМ застосовували в діагностуванні раку, включно з раком легені,[201] простати, колоректальним раком,[202] а також щоби відрізняти лінії ракових клітин, сильно схильні до розповсюдження, від менш схильних до розповсюдження ліній, із застосуванням лише інформації про форму клітин.[203][204]
ШНМ також використовували для побудови чорноскринькових моделей в геонауках: гідрологія,[205][206] моделювання океану та прибережна інженерія,[207][208] та геоморфологія[209] є лише деякими з прикладів такого роду.
Нейронаука
Теоретична на обчислювальна нейронаука займається теоретичним аналізом та обчислювальним моделюванням біологічних нейронних систем. Оскільки нейронні системи намагаються відображувати пізнавальні процеси та поведінку, ця область є тісно пов'язаною з пізнавальним та поведінковим моделюванням.
Щоби досягти розуміння цього, нейробіологи намагаються зв'язати спостережувані біологічні процеси (дані), біологічно правдоподібні механізми нейронної обробки та навчання (моделі біологічних нейронних мереж) та теорію (теорію статистичного навчання та теорію інформації).
Дослідження мозку неодноразово приводили до нових підходів на основі ШНМ, таких як використання з'єднань для з'єднування нейронів у різних шарах, а не суміжних нейронів в одному шарі. Інше дослідження розвідувало використання декількох типів сигналу, або тоншого контролю, ніж булеві змінні (увімкнено/вимкнено). Динамічні нейронні мережі можуть динамічно утворювати нові з'єднання, та навіть нові нейронні вузли, в той же час деактивуючи інші.[210]
Типи моделей
Використовується багато типів моделей, визначених на різних рівнях абстрагування, та з моделюванням різних аспектів нейронних систем. Вони сягають від моделей короткотермінової поведінки окремих нейронів,[211] моделей того, як динаміка компонувань нейронних схем постає із взаємодії між окремими нейронами, і, нарешті, до моделей того, як може поставати поведінка з абстрактних нейронних модулів, які представляють цілі підсистеми. До них належать моделі короткотермінової та довготермінової пластичності, нейронних систем та їхнього відношення до навчанням та пам'яті від окремого нейрону й до рівня системи.
Теоретичні властивості
Обчислювальна сила
Як доведено теоремою Цибенка, багатошаровий перцептрон є універсальним наближувачем функцій. Проте, це доведення не є конструктивним відносно числа потрібних нейронів, топології мережі, ваг та параметрів навчання.
Особлива рекурентна архітектура з раціальнозначними вагами (на противагу до повноточнісних дійснозначних ваг) має повну силу універсальної машини Тюрінга,[212] використовуючи скінченне число нейронів та стандартні лінійні з'єднання. Крім того, використання ірраціональних значень для ваг дає в результаті машину з надтюринговою силою.[213]
Місткість
Властивість «місткості» (англ. "capacity") моделі грубо відповідає її здатності моделювати будь-яку задану функцію. Вона пов'язана з обсягом інформації, яку може бути збережено в мережі, та з поняттям складності.[джерело?]
Збіжність
Моделі можуть не збігатися послідовно на єдиному розв'язку, по-перше, через можливість існування багатьох локальних мінімумів, залежно від функції витрат та моделі. По-друге, вживаний метод оптимізації може не гарантувати збіжності, якщо він починається далеко від будь-якого локального мінімуму. По-третє, для достатньо великих даних або параметрів, деякі методи стають непрактичними. Проте, для тренування нейронної мережі АКММ було представлено рекурсивний алгоритм найменших квадратів, і для цього алгоритму може бути гарантовано збіжність за один крок.[81]
Узагальнення та статистика
Застосування, чиєю метою є створення системи, яка добре узагальнюється до небачених зразків, стикаються з можливістю перетренування. Воно виникає в закручених або надмірно визначених системах, коли місткість мережі значно перевершує потребу в вільних параметрах. Існує два підходи, як впоруватися з перетренуванням. Першим є використовувати перехресне затверджування та подібні методи, щоби перевіряти на наявність перетренування та оптимально обирати гіперпараметри для зведення похибки узагальнення до мінімуму. Другим є використовувати якийсь із видів регуляризації. Це поняття виникає в імовірнісній (баєсовій) системі, де регуляризацію можливо виконувати шляхом обирання більшої апріорної ймовірності над простішими моделями, але також і в теорії статистичного навчання, де метою є зводити до мінімуму дві величини: «емпіричний ризик» та «структурний ризик», що грубо відповідають похибці над тренувальним набором та передбаченій похибці в небачених даних через перенавчання.
Керовані нейронні мережі, які використовують як функцію втрат середньоквадратичну похибку (СКП), для визначення довіри до тренованої моделі можуть використовувати формальні статистичні методи. СКП на затверджувальному наборі можливо використовувати для оцінювання дисперсії. Це значення потім можливо використовувати для обчислення довірчого інтервалу виходу мережі, виходячи з нормального розподілу. Здійснений таким чином аналіз довіри є статистично чинним, поки розподіл імовірності виходу залишається незмінним, і не вноситься змін до мережі.
Призначаючи нормовану експоненційну функцію, узагальнення логістичної функції, як функцію збудження шарові виходу нейронної мережі (або нормалізовану експоненційну складову в нейронній мережі на основі складових) для категорійних цільових змінних, виходи можна інтерпретувати як апостеріорні ймовірності. Це є дуже корисним у класифікації, бо дає міру впевненості в класифікаціях.
Нормалізованою експоненційною функцією збудження є:

Критика
Питання тренування
Поширеною критикою нейронних мереж, зокрема в робототехніці, є те, що для функціювання в реальному світі вони вимагають забагато тренування.[джерело?] До потенційних розв'язань належить випадкове переставляння тренувальних зразків, застосування алгоритму чисельної оптимізації, який не вимагає завеликих кроків при зміні з'єднань мережі слідом за зразком, та групування зразків до так званих міні-пакетів. Поліпшення дієвості навчання та здатності до збіжності для нейронних мереж завжди було областю постійних досліджень. Наприклад, завдяки введенню для нейронної мережі АКММ алгоритму рекурсивних найменших квадратів, процесові навчання, щоби збігтися, потрібен лише один крок.[81]
Теоретичні питання
Жодна нейронна мережа не розв'язала таких обчислювально складних задач, як задача про вісім ферзів, задача комівояжера чи задача розкладання великих цілих чисел.
Фундаментальна перешкода полягає в тім, що вони не відображують роботу справжніх нейронів. Зворотне поширення є критичною частиною більшості штучних нейронних мереж, тоді як в біологічних нейронних мережах такого механізму не існує.[214] Як інформацію кодовано справжніми нейронами — не відомо. Сенсо́рні нейрони генерують потенціал дії частіше, коли сенсор активовано, а м'язові клітини натягуються сильніше, коли пов'язані з ними мотонейрони частіше отримують потенціал дії.[215] Крім цієї справи передавання інформації від сенсорного нейрону до мотонейрону, про принципи обробки інформації біологічною нейронною мережею не відомо майже нічого.
Мотиви, що стоять за ШНМ, полягають не обов'язково в точному відтворенні нейронної функціональності, а в використанні біологічних нейронних мереж як натхнення. Тож головною претензією ШНМ є те, що вона втілює якийсь новий та потужний загальний принцип обробки інформації. На жаль, ці загальні принципи не є чітко визначеними. Часто претендують на те, що вони виникають із самої мережі. Це дозволяє простій статистичній асоціації (основній функції штучних нейронних мереж) бути описуваною як навчання або розпізнавання. Олександр Дьюдні зауважив, що, в результаті, штучні нейронні мережі мають «риси чогось дармового, чогось наділеного особливою аурою ледарства та виразної відсутності зацікавлення хоч би тим, наскільки добрими ці комп'ютерні системи є. Жодного втручання людської руки (та розуму), розв'язки знаходяться мов чарівною силою, і ніхто, схоже, так нічого й не навчився».[216]
Біологічні мізки використовують як поверхневі, так і глибинні схеми, як про це каже анатомія мозку,[217] демонструючи велику різноманітність інваріантності. Венг[218] стверджував, що мозок самоз'єднується великою мірою відповідно до статистики сигналів, і, відтак, послідовний каскад не здатен вловлювати всі важливі статистичні залежності.
Апаратні питання
Великі та ефективні обчислювальні нейронні мережі вимагають значних обчислювальних ресурсів.[219] В той час як мозок має апаратне забезпечення, ідеально пристосоване для задачі обробки сигналів графом нейронів, імітування навіть спрощеного нейрону на архітектурі фон Неймана може змушувати розробника нейронної мережі заповнювати багато мільйонів рядків бази даних для його з'єднань, що може вимагати споживання незмірної кількості пам'яті та дискового простору. Крім того, розробникові часто потрібно передавати сигнали багатьма цими з'єднаннями та пов'язаними з ними нейронами, і цій задачі часто мусить відповідати величезна обчислювальна потужність та час ЦП.
Шмідгубер зауважує, що реанімацію нейронних мереж у двадцять першому сторіччі великою мірою обумовлено досягненнями в апаратному забезпеченні: з 1991 до 2015 року обчислювальна потужність, особливо забезпечувана ГПЗП (на ГП), зросла приблизно в мільйон разів, зробивши стандартний алгоритм зворотного поширення придатним для тренування мереж, які є на декілька шарів глибшими, ніж раніше.[220] Застосування паралельних ГП може скорочувати тривалості тренування з місяців до днів.[219]
Нейроморфна інженерія розв'язує цю апаратну складність безпосередньо, конструюючи не-фон-нейманові мікросхеми для безпосереднього втілення нейронних мереж у схемах. Ще одна мікросхема, оптимізована для обробки нейронних мереж, зветься тензорним процесором, або ТП (англ. Tensor Processing Unit, TPU).[221]
Практичні контрприклади до критики
Аргументами проти позиції Дьюдні є те, що нейронні мережі успішно застосовувалися для розв'язання багатьох складних і різнотипних задач, починаючи від автономних літальних апаратів,[222] і до виявлення шахрайств із кредитними картками та опанування гри Ґо.
Технічний письменник Роджер Бріджмен прокоментував це так:
Нейронні мережі, наприклад, знаходяться в обоймі не лише тому, що їх було піднесено до високих небес (що не було?), але також і тому, що ви можете створити успішну мережу без розуміння того, як вона працює: жмут чисел, що охоплює її поведінку, за всією ймовірністю буде «непрозорою, нечитабельною таблицею... нічого не вартою, як науковий ресурс». Незважаючи на його рішучу заяву, що наука не є технологією, Дьюдні тут, здається, ганьбить нейронні мережі як погану науку, тоді як більшість із тих, хто їх розробляє, просто намагаються бути добрими інженерами. Нечитабельна таблиця, яку може читати корисна машина, все одно буде вельми варта того, щоби її мати.Оригінальний текст (англ.)Neural networks, for instance, are in the dock not only because they have been hyped to high heaven, (what hasn't?) but also because you could create a successful net without understanding how it worked: the bunch of numbers that captures its behaviour would in all probability be "an opaque, unreadable table...valueless as a scientific resource". In spite of his emphatic declaration that science is not technology, Dewdney seems here to pillory neural nets as bad science when most of those devising them are just trying to be good engineers. An unreadable table that a useful machine could read would still be well worth having.
Незважаючи на те, що аналізувати, чого навчилася штучна нейронна мережа, дійсно складно, робити це набагато простіше, ніж аналізувати, чого навчилася нейронна мережа біологічна. Крім того, дослідники, які беруть участь в пошуку алгоритмів навчання для нейронних мереж, поступово розкривають загальні принципи, що дозволяють машині, що вчиться, бути успішною. Наприклад, локальне й нелокальне навчання, та поверхнева й глибинна архітектура.[224]
Типи
Детальніші відомості з цієї теми ви можете знайти в статті Типи штучних нейронних мереж.
Штучні нейронні мережі мають багато різновидів. Найпростіші, статичні, типи мають одну або більше статичних складових, включно з числом вузлів, числом шарів, вагами вузлів та топологією. Динамічні типи дозволяють одній або більше з них змінюватися в процесі навчання. Останні є набагато складнішими, але можуть скорочувати періоди навчання та давати кращі результати. Деякі типи дозволяють/вимагають, щоби навчання було «керованим» оператором, тоді як інші діють незалежно. Деякі типи працюють виключно в апаратному забезпеченні, тоді як інші є чисто програмними, і працюють на комп'ютерах загального призначення.
За типом вхідної інформації
- Аналогові нейронні мережі (використовують інформацію у формі дійсних чисел);
- Двійкові нейронні мережі (оперують з інформацією, представленою в двійковому вигляді).
За характером налаштування синапсів
- Мережі з фіксованими зв'язками (вагові коефіцієнти нейронної мережі вибираються відразу, виходячи з умов завдання, при цьому: dW / dt = 0 , де W — вагові коефіцієнти мережі);
- Мережі з динамічними зв'язками (для них в процесі навчання відбувається налаштування синаптичних зв'язків, тобто dW / dt ≠ 0, де W — вагові коефіцієнти мережі).
За представленнями
Якщо обчислювальна мережа має представляти елементи з якоїсь множини і кожному елементу відповідає якийсь вузол мережі, таке представлення називається локальним представленням. Його просто зрозуміти і реалізувати. Проте іноді представляти елементи множини вигідніше певним шаблоном активності, розподіленої на багатьох елементах мережі. Таке представлення називають розподіленим. Використання такого представлення може збільшити ефективність мережі.[227]
Галерея
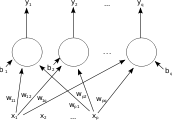 Одношарова штучна нейронна мережа прямого поширення. Стрілки, що виходять з , для наочності опущено. Є p входів до цієї мережі, й q виходів. У цій системі значення q-того виходу обчислюватиметься як
Одношарова штучна нейронна мережа прямого поширення. Стрілки, що виходять з , для наочності опущено. Є p входів до цієї мережі, й q виходів. У цій системі значення q-того виходу обчислюватиметься як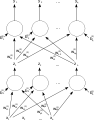 Двошарова штучна нейронна мережа прямого поширення.
Двошарова штучна нейронна мережа прямого поширення. Штучна нейронна мережа.
Штучна нейронна мережа.- Граф залежностей ШНМ.
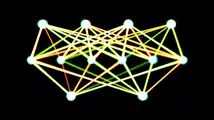 Одношарова штучна нейронна мережа прямого поширення з 4 входами, 6 прихованими вузлами, та 2 виходами. Для заданого стану положення та напряму виводить значення керування для коліс.
Одношарова штучна нейронна мережа прямого поширення з 4 входами, 6 прихованими вузлами, та 2 виходами. Для заданого стану положення та напряму виводить значення керування для коліс. Двошарова штучна нейронна мережа прямого поширення з 8 входами, 2x8 прихованими вузлами, та 2 виходами. Для заданого стану положення, напряму та інших змінних середовища, видає значення керування для маневрових двигунів.
Двошарова штучна нейронна мережа прямого поширення з 8 входами, 2x8 прихованими вузлами, та 2 виходами. Для заданого стану положення, напряму та інших змінних середовища, видає значення керування для маневрових двигунів.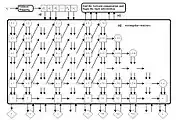 Паралельно-конвеєрна структура нейронної мережі АКММ. Цей алгоритм навчання здатен збігатися за один крок.
Паралельно-конвеєрна структура нейронної мережі АКММ. Цей алгоритм навчання здатен збігатися за один крок.



Див. також
- 20Q
- Автокодувальник
- ADALINE
- Адаптивне табулювання на місці
- Артикуляційний контролер мозочкової моделі (АКММ, англ. CMAC)
- Асоціативна пам'ять
- Біокібернетика
- Біологічно натхнені обчислення
- Генетичне програмування
- Генетичний алгоритм
- Генно-експресійне програмування
- Глибинне навчання
- Encog
- Звикання
- Згорткова нейронна мережа (ЗНМ, англ. CNN)
- Ієрархічна часова пам'ять
- Катастрофічна інтерференція
- Когнітивна архітектура
- Когнітивна наука
- Конективістська експертна система
- Конектоміка
- Культивована нейронна мережа
- Мережа радіально-базисних функцій
- Метод групового урахування аргументів
- Мікросхема Ni1000
- Моделі нейронного обчислення
- Нейроеволюція
- Нейронаука
- Нейронна мережа з потенціалом дії
- Нейронна мережа з часовою затримкою (англ. TDNN)
- Нейронний газ
- Нейронний машинний переклад
- Нелінійна ідентифікація систем
- Нервове кодування
- Нечітка логіка
- Оптична нейронна мережа
- Конекціонізм
- Поняття машинного навчання
- Програмне забезпечення нейронних мереж
- Проект Blue Brain
- Процеси паралельного задоволення обмежень (англ. PCSP)
- Рекурентні нейронні мережі
- Роботи BEAM
- Самоорганізаційне відображення
- Систолічний масив
- Тензорно-добуткова мережа
- Теорія адаптивного резонансу
- Цифровий морфогенез
- Штучне життя
Примітки
- McCulloch, Warren; Walter Pitts (1943). A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics 5 (4): 115–133. doi:10.1007/BF02478259. (англ.)
- Kleene, S.C. (1956). Representation of Events in Nerve Nets and Finite Automata. Annals of Mathematics Studies (англ.) (34) (Princeton University Press). с. 3–41. Процитовано 17 червня 2017. (англ.)
- Hebb, Donald (1949). The Organization of Behavior. New York: Wiley. ISBN 978-1-135-63190-1. (англ.)
- Farley, B.G.; W.A. Clark (1954). Simulation of Self-Organizing Systems by Digital Computer. IRE Transactions on Information Theory 4 (4): 76–84. doi:10.1109/TIT.1954.1057468. (англ.)
- Rochester, N.; J.H. Holland; L.H. Habit; W.L. Duda (1956). Tests on a cell assembly theory of the action of the brain, using a large digital computer. IRE Transactions on Information Theory 2 (3): 80–93. doi:10.1109/TIT.1956.1056810. (англ.)
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model For Information Storage And Organization In The Brain. Psychological Review 65 (6): 386–408. PMID 13602029. doi:10.1037/h0042519. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Werbos, P.J. (1975). Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. (англ.)
- David H. Hubel and Torsten N. Wiesel (2005). Brain and visual perception: the story of a 25-year collaboration. Oxford University Press US. с. 106. ISBN 978-0-19-517618-6. (англ.)
- Schmidhuber, J. (2015). Deep Learning in Neural Networks: An Overview. Neural Networks 61: 85–117. PMID 25462637. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. (англ.)
- Ivakhnenko, A. G. (1973). Cybernetic Predicting Devices. CCM Information Corporation. (англ.)
- Ivakhnenko, A. G.; Grigorʹevich Lapa, Valentin (1967). Cybernetics and forecasting techniques. American Elsevier Pub. Co. (англ.)
- Minsky, Marvin; Papert, Seymour (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press. ISBN 0-262-63022-2. (англ.)
- Rumelhart, D.E; McClelland, James (1986). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Cambridge: MIT Press. ISBN 978-0-262-63110-5. (англ.)
- J. Weng, N. Ahuja and T. S. Huang, "Cresceptron: a self-organizing neural network which grows adaptively, " Proc. International Joint Conference on Neural Networks, Baltimore, Maryland, vol I, pp. 576—581, June, 1992. (англ.)
- J. Weng, N. Ahuja and T. S. Huang, "Learning recognition and segmentation of 3-D objects from 2-D images, " Proc. 4th International Conf. Computer Vision, Berlin, Germany, pp. 121—128, May, 1993. (англ.)
- J. Weng, N. Ahuja and T. S. Huang, "Learning recognition and segmentation using the Cresceptron, " International Journal of Computer Vision, vol. 25, no. 2, pp. 105—139, Nov. 1997. (англ.)
- S. Hochreiter., "Untersuchungen zu dynamischen neuronalen Netzen, " Diploma thesis. Institut f. Informatik, Technische Univ. Munich. Advisor: J. Schmidhuber, 1991. (нім.)
- Hochreiter, S.; et al. (15 січня 2001). Gradient flow in recurrent nets: the difficulty of learning long-term dependencies. У Kolen, John F.; Kremer, Stefan C. A Field Guide to Dynamical Recurrent Networks. John Wiley & Sons. ISBN 978-0-7803-5369-5. (англ.)
- J. Schmidhuber., "Learning complex, extended sequences using the principle of history compression, " Neural Computation, 4, pp. 234—242, 1992. (англ.)
- Sven Behnke (2003). Hierarchical Neural Networks for Image Interpretation.. Lecture Notes in Computer Science 2766. Springer. (англ.)
- Smolensky, P. (1986). Information processing in dynamical systems: Foundations of harmony theory.. У D. E. Rumelhart, J. L. McClelland, & the PDP Research Group. Parallel Distributed Processing: Explorations in the Microstructure of Cognition 1. с. 194–281.
- Hinton, G. E.; Osindero, S.; Teh, Y. (2006). A fast learning algorithm for deep belief nets. Neural Computation 18 (7): 1527–1554. PMID 16764513. doi:10.1162/neco.2006.18.7.1527. (англ.)
- Hinton, G. (2009). Deep belief networks. Scholarpedia 4 (5): 5947. Bibcode:2009SchpJ...4.5947H. doi:10.4249/scholarpedia.5947. (англ.)
- Ng, Andrew; Dean, Jeff (2012). «Building High-level Features Using Large Scale Unsupervised Learning». arXiv:1112.6209 [cs.LG]. (англ.)
- Yang, J. J.; Pickett, M. D.; Li, X. M.; Ohlberg, D. A. A.; Stewart, D. R.; Williams, R. S. (2008). Memristive switching mechanism for metal/oxide/metal nanodevices. Nat. Nanotechnol 3 (7): 429–433. doi:10.1038/nnano.2008.160. (англ.)
- Strukov, D. B.; Snider, G. S.; Stewart, D. R.; Williams, R. S. (2008). The missing memristor found. Nature 453 (7191): 80–83. Bibcode:2008Natur.453...80S. PMID 18451858. doi:10.1038/nature06932. (англ.)
- Cireşan, Dan Claudiu; Meier, Ueli; Gambardella, Luca Maria; Schmidhuber, Jürgen (21 вересня 2010). Deep, Big, Simple Neural Nets for Handwritten Digit Recognition. Neural Computation 22 (12): 3207–3220. ISSN 0899-7667. doi:10.1162/neco_a_00052. (англ.)
- 2012 Kurzweil AI Interview Архівовано 31 серпня 2018 у Wayback Machine. with Jürgen Schmidhuber on the eight competitions won by his Deep Learning team 2009—2012 (англ.)
- How bio-inspired deep learning keeps winning competitions | KurzweilAI. www.kurzweilai.net (амер.). Архів оригіналу за 31 серпня 2018. Процитовано 16 червня 2017. (англ.)
- Graves, Alex; and Schmidhuber, Jürgen; Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks, in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.; and Culotta, Aron (eds.), Advances in Neural Information Processing Systems 22 (NIPS'22), 7–10 December 2009, Vancouver, BC, Neural Information Processing Systems (NIPS) Foundation, 2009, pp. 545—552. (англ.)
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. (2009). A Novel Connectionist System for Improved Unconstrained Handwriting Recognition (PDF). IEEE Transactions on Pattern Analysis and Machine Intelligence 31 (5): 855–868. doi:10.1109/tpami.2008.137. (англ.)
- Graves, Alex; Schmidhuber, Jürgen (2009). Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. У Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris editor-K. I.; Culotta, Aron. Neural Information Processing Systems (NIPS) Foundation: 545–552. (англ.)
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. (May 2009). A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 31 (5): 855–868. ISSN 0162-8828. doi:10.1109/tpami.2008.137. (англ.)
- Cireşan, Dan; Meier, Ueli; Masci, Jonathan; Schmidhuber, Jürgen (August 2012). Multi-column deep neural network for traffic sign classification. Neural Networks. Selected Papers from IJCNN 2011 32: 333–338. doi:10.1016/j.neunet.2012.02.023. (англ.)
- Ciresan, Dan; Giusti, Alessandro; Gambardella, Luca M.; Schmidhuber, Juergen (2012). У Pereira, F.; Burges, C. J. C.; Bottou, L. та ін. Advances in Neural Information Processing Systems 25. Curran Associates, Inc. с. 2843–2851. (англ.)
- Ciresan, Dan; Meier, U.; Schmidhuber, J. (June 2012). Multi-column deep neural networks for image classification. 2012 IEEE Conference on Computer Vision and Pattern Recognition: 3642–3649. ISBN 978-1-4673-1228-8. doi:10.1109/cvpr.2012.6248110. (англ.)
- Ciresan, D. C.; Meier, U.; Masci, J.; Gambardella, L. M.; Schmidhuber, J. (2011). Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence. doi:10.5591/978-1-57735-516-8/ijcai11-210. (англ.)
- Ciresan, Dan; Giusti, Alessandro; Gambardella, Luca M.; Schmidhuber, Juergen (2012). У Pereira, F.; Burges, C. J. C.; Bottou, L. та ін. Advances in Neural Information Processing Systems 25. Curran Associates, Inc. с. 2843–2851. (англ.)
- Krizhevsky, Alex; Sutskever, Ilya; Hinton, Geoffry (2012). ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012: Neural Information Processing Systems, Lake Tahoe, Nevada. (англ.)
- Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics 36 (4): 93–202. PMID 7370364. doi:10.1007/BF00344251. (англ.)
- Riesenhuber, M; Poggio, T (1999). Hierarchical models of object recognition in cortex. Nature Neuroscience 2 (11): 1019–1025. doi:10.1038/14819. (англ.)
- Hinton, Geoffrey (31 травня 2009). Deep belief networks. Scholarpedia (англ.) 4 (5): 5947. Bibcode:2009SchpJ...4.5947H. ISSN 1941-6016. doi:10.4249/scholarpedia.5947. (англ.)
- Markoff, John (23 листопада 2012). Scientists See Promise in Deep-Learning Programs. New York Times. (англ.)
- Martines, H.; Bengio, Y.; Yannakakis, G. N. (2013). Learning Deep Physiological Models of Affect. IEEE Computational Intelligence 8 (2): 20–33. doi:10.1109/mci.2013.2247823. (англ.)
- J. Weng, "Why Have We Passed `Neural Networks Do not Abstract Well'?, " Natural Intelligence: the INNS Magazine, vol. 1, no.1, pp. 13-22, 2011. (англ.)
- Z. Ji, J. Weng, and D. Prokhorov, "Where-What Network 1: Where and What Assist Each Other Through Top-down Connections," Proc. 7th International Conference on Development and Learning (ICDL'08), Monterey, CA, Aug. 9-12, pp. 1-6, 2008. (англ.)
- X. Wu, G. Guo, and J. Weng, "Skull-closed Autonomous Development: WWN-7 Dealing with Scales," Proc. International Conference on Brain-Mind, July 27–28, East Lansing, Michigan, pp. +1-9, 2013. (англ.)
- Zell, Andreas (1994). chapter 5.2. Simulation Neuronaler Netze [Simulation of Neural Networks] (German) (вид. 1st). Addison-Wesley. ISBN 3-89319-554-8. (нім.)
- The Machine Learning Dictionary. Архів оригіналу за 26 серпня 2018. Процитовано 13 січня 2018. (англ.)
- Schmidhuber, Jürgen (2015). Deep Learning. Scholarpedia 10 (11): 32832. Bibcode:2015SchpJ..1032832S. doi:10.4249/scholarpedia.32832. (англ.)
- Dreyfus, Stuart E. (1 вересня 1990). Artificial neural networks, back propagation, and the Kelley-Bryson gradient procedure. Journal of Guidance, Control, and Dynamics 13 (5): 926–928. Bibcode:1990JGCD...13..926D. ISSN 0731-5090. doi:10.2514/3.25422. (англ.)
- Eiji Mizutani, Stuart Dreyfus, Kenichi Nishio (2000). On derivation of MLP backpropagation from the Kelley-Bryson optimal-control gradient formula and its application. Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN 2000), Como Italy, July 2000. Online[недоступне посилання з травня 2019] (англ.)
- Kelley, Henry J. (1960). Gradient theory of optimal flight paths. Ars Journal 30 (10): 947–954. doi:10.2514/8.5282. (англ.)
- Arthur E. Bryson (1961, April). A gradient method for optimizing multi-stage allocation processes. In Proceedings of the Harvard Univ. Symposium on digital computers and their applications. (англ.)
- Dreyfus, Stuart (1962). The numerical solution of variational problems. Journal of Mathematical Analysis and Applications 5 (1): 30–45. doi:10.1016/0022-247x(62)90004-5. (англ.)
- Russell, Stuart J.; Norvig, Peter (2010). Artificial Intelligence A Modern Approach. Prentice Hall. с. 578. ISBN 978-0-13-604259-4. «The most popular method for learning in multilayer networks is called Back-propagation.» (англ.)
- Bryson, Arthur Earl (1969). Applied Optimal Control: Optimization, Estimation and Control. Blaisdell Publishing Company or Xerox College Publishing. с. 481. (англ.)
- Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 6-7. (англ.)
- Linnainmaa, Seppo (1976). Taylor expansion of the accumulated rounding error. BIT Numerical Mathematics 16 (2): 146–160. doi:10.1007/bf01931367. (англ.)
- Griewank, Andreas (2012). Who Invented the Reverse Mode of Differentiation?. Documenta Matematica, Extra Volume ISMP: 389–400. Архів оригіналу за 21 липня 2017. Процитовано 13 січня 2018. (англ.)
- Griewank, Andreas; Walther, Andrea (2008). Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, Second Edition. SIAM. ISBN 978-0-89871-776-1. (англ.)
- Dreyfus, Stuart (1973). The computational solution of optimal control problems with time lag. IEEE Transactions on Automatic Control 18 (4): 383–385. doi:10.1109/tac.1973.1100330. (англ.)
- Paul Werbos (1974). Beyond regression: New tools for prediction and analysis in the behavioral sciences. PhD thesis, Harvard University. (англ.)
- Werbos, Paul (1982). Applications of advances in nonlinear sensitivity analysis. System modeling and optimization. Springer. с. 762–770. (англ.)
- Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (1986). Learning representations by back-propagating errors. Nature 323 (6088): 533–536. Bibcode:1986Natur.323..533R. doi:10.1038/323533a0. (англ.)
- Eric A. Wan (1993). Time series prediction by using a connectionist network with internal delay lines. In SANTA FE INSTITUTE STUDIES IN THE SCIENCES OF COMPLEXITY-PROCEEDINGS (Vol. 15, pp. 195—195). Addison-Wesley Publishing Co. (англ.)
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G. E.; Mohamed, A. r; Jaitly, N.; Senior, A.; Vanhoucke, V. та ін. (November 2012). Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Processing Magazine 29 (6): 82–97. Bibcode:2012ISPM...29...82H. ISSN 1053-5888. doi:10.1109/msp.2012.2205597. (англ.)
- Huang, Guang-Bin; Zhu, Qin-Yu; Siew, Chee-Kheong (2006). Extreme learning machine: theory and applications. Neurocomputing 70 (1): 489–501. doi:10.1016/j.neucom.2005.12.126. (англ.)
- Widrow, Bernard (2013). The no-prop algorithm: A new learning algorithm for multilayer neural networks. Neural Networks 37: 182–188. doi:10.1016/j.neunet.2012.09.020. (англ.)
- Ollivier, Yann; Charpiat, Guillaume (2015). «Training recurrent networks without backtracking». arXiv:1507.07680 [cs.NE]. (англ.)
- ESANN. 2009 (англ.)
- Hinton, G. E. (2010). A Practical Guide to Training Restricted Boltzmann Machines. Tech. Rep. UTML TR 2010-003,. (англ.)
- Ojha, Varun Kumar; Abraham, Ajith; Snášel, Václav (1 квітня 2017). Metaheuristic design of feedforward neural networks: A review of two decades of research. Engineering Applications of Artificial Intelligence 60: 97–116. doi:10.1016/j.engappai.2017.01.013. (англ.)
- Dominic, S.; Das, R.; Whitley, D.; Anderson, C. (July 1991). Genetic reinforcement learning for neural networks. IJCNN-91-Seattle International Joint Conference on Neural Networks IJCNN-91-Seattle International Joint Conference on Neural Networks. Seattle, Washington, USA: IEEE. ISBN 0-7803-0164-1. doi:10.1109/IJCNN.1991.155315. Процитовано 29 липня 2012. (англ.)
- Hoskins, J.C.; Himmelblau, D.M. (1992). Process control via artificial neural networks and reinforcement learning. Computers & Chemical Engineering 16 (4): 241–251. doi:10.1016/0098-1354(92)80045-B. (англ.)
- Bertsekas, D.P.; Tsitsiklis, J.N. (1996). Neuro-dynamic programming. Athena Scientific. с. 512. ISBN 1-886529-10-8. (англ.)
- Secomandi, Nicola (2000). Comparing neuro-dynamic programming algorithms for the vehicle routing problem with stochastic demands. Computers & Operations Research 27 (11–12): 1201–1225. doi:10.1016/S0305-0548(99)00146-X. (англ.)
- de Rigo, D.; Rizzoli, A. E.; Soncini-Sessa, R.; Weber, E.; Zenesi, P. (2001). Neuro-dynamic programming for the efficient management of reservoir networks. Proceedings of MODSIM 2001, International Congress on Modelling and Simulation MODSIM 2001, International Congress on Modelling and Simulation. Canberra, Australia: Modelling and Simulation Society of Australia and New Zealand. ISBN 0-867405252. doi:10.5281/zenodo.7481. Процитовано 29 липня 2012. (англ.)
- Damas, M.; Salmeron, M.; Diaz, A.; Ortega, J.; Prieto, A.; Olivares, G. (2000). Genetic algorithms and neuro-dynamic programming: application to water supply networks. Proceedings of 2000 Congress on Evolutionary Computation 2000 Congress on Evolutionary Computation. La Jolla, California, USA: IEEE. ISBN 0-7803-6375-2. doi:10.1109/CEC.2000.870269. Процитовано 29 липня 2012. (англ.)
- Deng, Geng; Ferris, M.C. (2008). Neuro-dynamic programming for fractionated radiotherapy planning. Springer Optimization and Its Applications. Springer Optimization and Its Applications 12: 47–70. ISBN 978-0-387-73298-5. doi:10.1007/978-0-387-73299-2_3. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Ting Qin, et al. «A learning algorithm of CMAC based on RLS.» Neural Processing Letters 19.1 (2004): 49-61. (англ.)
- Ting Qin, et al. «Continuous CMAC-QRLS and its systolic array.» Neural Processing Letters 22.1 (2005): 1-16. (англ.)
- M. Forouzanfar; H. R. Dajani; V. Z. Groza; M. Bolic; S. Rajan (July 2010). Comparison of Feed-Forward Neural Network Training Algorithms for Oscillometric Blood Pressure Estimation 4th Int. Workshop Soft Computing Applications. Arad, Romania: IEEE. Проігноровано невідомий параметр
|last-author-amp=(довідка) (англ.) - de Rigo, D., Castelletti, A., Rizzoli, A.E., Soncini-Sessa, R., Weber, E. (January 2005). A selective improvement technique for fastening Neuro-Dynamic Programming in Water Resources Network Management. У Pavel Zítek. Proceedings of the 16th IFAC World Congress – IFAC-PapersOnLine 16th IFAC World Congress 16. Prague, Czech Republic: IFAC. ISBN 978-3-902661-75-3. doi:10.3182/20050703-6-CZ-1902.02172. Процитовано 30 грудня 2011. (англ.)
- Ferreira, C. (2006). Designing Neural Networks Using Gene Expression Programming. In A. Abraham, B. de Baets, M. Köppen, and B. Nickolay, eds., Applied Soft Computing Technologies: The Challenge of Complexity, pages 517–536, Springer-Verlag. (англ.)
- Da, Y.; Xiurun, G. (July 2005). У T. Villmann. An improved PSO-based ANN with simulated annealing technique New Aspects in Neurocomputing: 11th European Symposium on Artificial Neural Networks. Elsevier. doi:10.1016/j.neucom.2004.07.002. (англ.)
- Wu, J.; Chen, E. (May 2009). У Wang, H., Shen, Y., Huang, T., Zeng, Z. A Novel Nonparametric Regression Ensemble for Rainfall Forecasting Using Particle Swarm Optimization Technique Coupled with Artificial Neural Network 6th International Symposium on Neural Networks, ISNN 2009. Springer. ISBN 978-3-642-01215-0. doi:10.1007/978-3-642-01513-7-6. (англ.)
- Ivakhnenko, Alexey Grigorevich (1968). The group method of data handling – a rival of the method of stochastic approximation. Soviet Automatic Control 13 (3): 43–55. (англ.)
- Ivakhnenko, Alexey (1971). Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics (4) (4): 364–378. doi:10.1109/TSMC.1971.4308320. (англ.)
- Kondo, T.; Ueno, J. (2008). Multi-layered GMDH-type neural network self-selecting optimum neural network architecture and its application to 3-dimensional medical image recognition of blood vessels. International Journal of Innovative Computing, Information and Control 4 (1): 175–187. (англ.)
- Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 36 (4): 193–202. PMID 7370364. doi:10.1007/bf00344251. (англ.)
- LeCun et al., "Backpropagation Applied to Handwritten Zip Code Recognition, « Neural Computation, 1, pp. 541—551, 1989. (англ.)
- Yann LeCun (2016). Slides on Deep Learning Online (англ.)
- Unsupervised Feature Learning and Deep Learning Tutorial. (англ.)
- Szegedy, Christian; Liu, Wei; Jia, Yangqing; Sermanet, Pierre; Reed, Scott; Anguelov, Dragomir; Erhan, Dumitru; Vanhoucke, Vincent та ін. (2014). Going Deeper with Convolutions. Computing Research Repository: 1. ISBN 978-1-4673-6964-0. arXiv:1409.4842. doi:10.1109/CVPR.2015.7298594. (англ.)
- Hochreiter, Sepp; Schmidhuber, Jürgen (1 листопада 1997). Long Short-Term Memory. Neural Computation 9 (8): 1735–1780. ISSN 0899-7667. doi:10.1162/neco.1997.9.8.1735. (англ.)
- Learning Precise Timing with LSTM Recurrent Networks (PDF Download Available). ResearchGate (англ.). с. 115–143. Процитовано 13 червня 2017. (англ.)
- Bayer, Justin; Wierstra, Daan; Togelius, Julian; Schmidhuber, Jürgen (14 вересня 2009). Evolving Memory Cell Structures for Sequence Learning. Artificial Neural Networks – ICANN 2009. Lecture Notes in Computer Science (англ.) (Springer, Berlin, Heidelberg) 5769: 755–764. ISBN 978-3-642-04276-8. doi:10.1007/978-3-642-04277-5_76. (англ.)
- Fernández, Santiago; Graves, Alex; Schmidhuber, Jürgen (2007). Sequence labelling in structured domains with hierarchical recurrent neural networks. In Proc. 20th Int. Joint Conf. on Artificial In℡ligence, Ijcai 2007: 774–779. (англ.)
- Graves, Alex; Fernández, Santiago; Gomez, Faustino (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376. (англ.)
- Graves, Alex; Eck, Douglas; Beringer, Nicole; Schmidhuber, Jürgen (2003). Biologically Plausible Speech Recognition with LSTM Neural Nets. 1st Intl. Workshop on Biologically Inspired Approaches to Advanced Information Technology, Bio-ADIT 2004, Lausanne, Switzerland. с. 175–184. (англ.)
- Fernández, Santiago; Graves, Alex; Schmidhuber, Jürgen (2007). An Application of Recurrent Neural Networks to Discriminative Keyword Spotting. Proceedings of the 17th International Conference on Artificial Neural Networks. ICANN'07 (Berlin, Heidelberg: Springer-Verlag): 220–229. ISBN 3540746935. (англ.)
- Hannun, Awni; Case, Carl; Casper, Jared; Catanzaro, Bryan; Diamos, Greg; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev та ін. (2014-12-17). «Deep Speech: Scaling up end-to-end speech recognition». arXiv:1412.5567 [cs.CL]. (англ.)
- Sak, Hasim; Senior, Andrew; Beaufays, Francoise (2014). Long Short-Term Memory recurrent neural network architectures for large scale acoustic modeling. Архів оригіналу за 24 квітня 2018. (англ.)
- Li, Xiangang; Wu, Xihong (2014-10-15). «Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition». arXiv:1410.4281 [cs.CL]. (англ.)
- Fan, Y.; Qian, Y.; Xie, F.; Soong, F. K. (2014). TTS synthesis with bidirectional LSTM based Recurrent Neural Networks. ResearchGate (англ.). Процитовано 13 червня 2017. (англ.)
- Zen, Heiga; Sak, Hasim (2015). Unidirectional Long Short-Term Memory Recurrent Neural Network with Recurrent Output Layer for Low-Latency Speech Synthesis. Google.com. ICASSP. с. 4470–4474. (англ.)
- Fan, Bo; Wang, Lijuan; Soong, Frank K.; Xie, Lei (2015). Photo-Real Talking Head with Deep Bidirectional LSTM. Proceedings of ICASSP. (англ.)
- Sak, Haşim; Senior, Andrew; Rao, Kanishka; Beaufays, Françoise; Schalkwyk, Johan (September 2015). Google voice search: faster and more accurate. (англ.)
- Gers, Felix A.; Schmidhuber, Jürgen (2001). LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages. IEEE TNN 12 (6): 1333–1340. doi:10.1109/72.963769. (англ.)
- Sutskever, L.; Vinyals, O.; Le, Q. (2014). Sequence to Sequence Learning with Neural Networks. NIPS'14 Proceedings of the 27th International Conference on Neural Information Processing Systems 2: 3104–3112. Bibcode:2014arXiv1409.3215S. arXiv:1409.3215. Проігноровано невідомий параметр
|class=(довідка) (англ.) - Jozefowicz, Rafal; Vinyals, Oriol; Schuster, Mike; Shazeer, Noam; Wu, Yonghui (2016-02-07). «Exploring the Limits of Language Modeling». arXiv:1602.02410 [cs.CL]. (англ.)
- Gillick, Dan; Brunk, Cliff; Vinyals, Oriol; Subramanya, Amarnag (2015-11-30). «Multilingual Language Processing From Bytes». arXiv:1512.00103 [cs.CL]. (англ.)
- Vinyals, Oriol; Toshev, Alexander; Bengio, Samy; Erhan, Dumitru (2014-11-17). «Show and Tell: A Neural Image Caption Generator». arXiv:1411.4555 [cs.CV]. (англ.)
- Gallicchio, Claudio; Micheli, Alessio; Pedrelli, Luca (2017). Deep reservoir computing: A critical experimental analysis. Neurocomputing 268: 87. doi:10.1016/j.neucom.2016.12.089. (англ.)
- Gallicchio, Claudio; Micheli, Alessio (2017). Echo State Property of Deep Reservoir Computing Networks. Cognitive Computation (англ.) 9 (3): 337–350. ISSN 1866-9956. doi:10.1007/s12559-017-9461-9. (англ.)
- Hinton, G.E. (2009). Deep belief networks. Scholarpedia 4 (5): 5947. Bibcode:2009SchpJ...4.5947H. doi:10.4249/scholarpedia.5947. (англ.)
- Larochelle, Hugo; Erhan, Dumitru; Courville, Aaron; Bergstra, James; Bengio, Yoshua (2007). An Empirical Evaluation of Deep Architectures on Problems with Many Factors of Variation. Proceedings of the 24th International Conference on Machine Learning. ICML '07 (New York, NY, USA: ACM): 473–480. ISBN 9781595937933. doi:10.1145/1273496.1273556. (англ.)
- Graupe, Daniel (2013). Principles of Artificial Neural Networks. World Scientific. с. 1–. ISBN 978-981-4522-74-8. (англ.)
- Шаблон:Patent (англ.)
- D. Graupe, „Principles of Artificial Neural Networks.3rd Edition“, World Scientific Publishers, 2013, pp.203-274. (англ.)
- Nigam, Vivek Prakash; Graupe, Daniel (1 січня 2004). A neural-network-based detection of epilepsy. Neurological Research 26 (1): 55–60. ISSN 0161-6412. PMID 14977058. doi:10.1179/016164104773026534. (англ.)
- Waxman, Jonathan A.; Graupe, Daniel; Carley, David W. (1 квітня 2010). Automated Prediction of Apnea and Hypopnea, Using a LAMSTAR Artificial Neural Network. American Journal of Respiratory and Critical Care Medicine 181 (7): 727–733. ISSN 1073-449X. doi:10.1164/rccm.200907-1146oc. (англ.)
- Graupe, D.; Graupe, M. H.; Zhong, Y.; Jackson, R. K. (2008). Blind adaptive filtering for non-invasive extraction of the fetal electrocardiogram and its non-stationarities. Proc. Inst. Mech Eng., UK, Part H: Journal of Engineering in Medicine 222 (8): 1221–1234. doi:10.1243/09544119jeim417. (англ.)
- Graupe, 2013, pp. 240–253
- Graupe, D.; Abon, J. (2002). A Neural Network for Blind Adaptive Filtering of Unknown Noise from Speech. Intelligent Engineering Systems Through Artificial Neural Networks (англ.) (Technische Informationsbibliothek (TIB)) 12: 683–688. Процитовано 14 червня 2017. (англ.)
- D. Graupe, „Principles of Artificial Neural Networks.3rd Edition“, World Scientific Publishers», 2013, pp.253-274. (англ.)
- Girado, J. I.; Sandin, D. J.; DeFanti, T. A. (2003). Real-time camera-based face detection using a modified LAMSTAR neural network system. Proc. SPIE 5015, Applications of Artificial Neural Networks in Image Processing VIII. Applications of Artificial Neural Networks in Image Processing VIII 5015: 36. Bibcode:2003SPIE.5015...36G. doi:10.1117/12.477405. (англ.)
- Venkatachalam, V; Selvan, S. (2007). Intrusion Detection using an Improved Competitive Learning Lamstar Network. International Journal of Computer Science and Network Security 7 (2): 255–263. (англ.)
- Graupe, D.; Smollack, M. (2007). Control of unstable nonlinear and nonstationary systems using LAMSTAR neural networks. ResearchGate (англ.). Proceedings of 10th IASTED on Intelligent Control, Sect.592,. с. 141–144. Процитовано 14 червня 2017. (англ.)
- Graupe, Daniel (7 липня 2016). Deep Learning Neural Networks: Design and Case Studies. World Scientific Publishing Co Inc. с. 57–110. ISBN 978-981-314-647-1. (англ.)
- Graupe, D.; Kordylewski, H. (August 1996). Network based on SOM (Self-Organizing-Map) modules combined with statistical decision tools. Proceedings of the 39th Midwest Symposium on Circuits and Systems 1: 471–474 vol.1. ISBN 0-7803-3636-4. doi:10.1109/mwscas.1996.594203. (англ.)
- Graupe, D.; Kordylewski, H. (1 березня 1998). A Large Memory Storage and Retrieval Neural Network for Adaptive Retrieval and Diagnosis. International Journal of Software Engineering and Knowledge Engineering 08 (1): 115–138. ISSN 0218-1940. doi:10.1142/s0218194098000091. (англ.)
- Kordylewski, H.; Graupe, D; Liu, K. (2001). A novel large-memory neural network as an aid in medical diagnosis applications. IEEE Transactions on Information Technology in Biomedicine 5 (3): 202–209. doi:10.1109/4233.945291. (англ.)
- Schneider, N.C.; Graupe (2008). A modified LAMSTAR neural network and its applications. International journal of neural systems 18 (4): 331–337. doi:10.1142/s0129065708001634. (англ.)
- Graupe, 2013, p. 217 (англ.)
- Vincent, Pascal; Larochelle, Hugo; Lajoie, Isabelle; Bengio, Yoshua; Manzagol, Pierre-Antoine (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. The Journal of Machine Learning Research 11: 3371–3408. (англ.)
- Ballard, Dana H. (1987). Modular learning in neural networks. Proceedings of AAAI. с. 279–284. (англ.)
- Deng, Li; Yu, Dong; Platt, John (2012). Scalable stacking and learning for building deep architectures. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP): 2133–2136. Архів оригіналу за 4 березня 2016. Процитовано 13 січня 2018. (англ.)
- Deng, Li; Yu, Dong (2011). Deep Convex Net: A Scalable Architecture for Speech Pattern Classification. Proceedings of the Interspeech: 2285–2288. (англ.)
- David, Wolpert (1992). Stacked generalization. Neural Networks 5 (2): 241–259. doi:10.1016/S0893-6080(05)80023-1. (англ.)
- Bengio, Y. (15 листопада 2009). Learning Deep Architectures for AI. Foundations and Trends® in Machine Learning (English) 2 (1): 1–127. ISSN 1935-8237. doi:10.1561/2200000006. (англ.)
- Hutchinson, Brian; Deng, Li; Yu, Dong (2012). Tensor deep stacking networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 1–15 (8): 1944–1957. doi:10.1109/tpami.2012.268. (англ.)
- Hinton, Geoffrey; Salakhutdinov, Ruslan (2006). Reducing the Dimensionality of Data with Neural Networks. Science 313 (5786): 504–507. Bibcode:2006Sci...313..504H. PMID 16873662. doi:10.1126/science.1127647. (англ.)
- Dahl, G.; Yu, D.; Deng, L.; Acero, A. (2012). Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. IEEE Transactions on Audio, Speech, and Language Processing 20 (1): 30–42. doi:10.1109/tasl.2011.2134090. (англ.)
- Mohamed, Abdel-rahman; Dahl, George; Hinton, Geoffrey (2012). Acoustic Modeling Using Deep Belief Networks. IEEE Transactions on Audio, Speech, and Language Processing 20 (1): 14–22. doi:10.1109/tasl.2011.2109382. (англ.)
- Courville, Aaron; Bergstra, James; Bengio, Yoshua (2011). A Spike and Slab Restricted Boltzmann Machine. JMLR: Workshop and Conference Proceeding 15: 233–241. Архів оригіналу за 4 березня 2016. Процитовано 13 січня 2018. (англ.)
- Courville, Aaron; Bergstra, James; Bengio, Yoshua (2011). Unsupervised Models of Images by Spike-and-Slab RBMs. Proceedings of the 28th International Conference on Machine Learning 10. с. 1–8. Архів оригіналу за 4 березня 2016. Процитовано 13 січня 2018. (англ.)
- Mitchell, T; Beauchamp, J (1988). Bayesian Variable Selection in Linear Regression. Journal of the American Statistical Association 83 (404): 1023–1032. doi:10.1080/01621459.1988.10478694. (англ.)
- Hinton, G. E.; Osindero, S.; Teh, Y. (2006). A fast learning algorithm for deep belief nets. Neural Computation 18 (7): 1527–1554. PMID 16764513. doi:10.1162/neco.2006.18.7.1527. (англ.)
- Hinton, Geoffrey; Salakhutdinov, Ruslan (2009). Efficient Learning of Deep Boltzmann Machines 3. с. 448–455. Архів оригіналу за 6 листопада 2015. Процитовано 13 січня 2018. (англ.)
- Larochelle, Hugo; Bengio, Yoshua; Louradour, Jerdme; Lamblin, Pascal (2009). Exploring Strategies for Training Deep Neural Networks. The Journal of Machine Learning Research 10: 1–40. (англ.)
- Coates, Adam; Carpenter, Blake (2011). Text Detection and Character Recognition in Scene Images with Unsupervised Feature Learning. с. 440–445. (англ.)
- Lee, Honglak; Grosse, Roger (2009). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. Proceedings of the 26th Annual International Conference on Machine Learning: 1–8. (англ.)
- Lin, Yuanqing; Zhang, Tong (2010). Deep Coding Network. Advances in Neural . . .: 1–9. Архів оригіналу за 1 серпня 2016. Процитовано 13 січня 2018. (англ.)
- Ranzato, Marc Aurelio; Boureau, Y-Lan (2007). Sparse Feature Learning for Deep Belief Networks. Advances in Neural Information Processing Systems 23: 1–8. Архів оригіналу за 4 березня 2016. Процитовано 13 січня 2018. (англ.)
- Socher, Richard; Lin, Clif (2011). Parsing Natural Scenes and Natural Language with Recursive Neural Networks. Proceedings of the 26th International Conference on Machine Learning. Архів оригіналу за 4 березня 2016. Процитовано 13 січня 2018. (англ.)
- Taylor, Graham; Hinton, Geoffrey (2006). Modeling Human Motion Using Binary Latent Variables. Advances in Neural Information Processing Systems. Архів оригіналу за 4 березня 2016. Процитовано 13 січня 2018. (англ.)
- Vincent, Pascal; Larochelle, Hugo (2008). Extracting and composing robust features with denoising autoencoders. Proceedings of the 25th international conference on Machine learning - ICML '08: 1096–1103. (англ.)
- Kemp, Charles; Perfors, Amy; Tenenbaum, Joshua (2007). Learning overhypotheses with hierarchical Bayesian models. Developmental Science 10 (3): 307–21. PMID 17444972. doi:10.1111/j.1467-7687.2007.00585.x. (англ.)
- Xu, Fei; Tenenbaum, Joshua (2007). Word learning as Bayesian inference. Psychol. Rev. 114 (2): 245–72. PMID 17500627. doi:10.1037/0033-295X.114.2.245. (англ.)
- Chen, Bo; Polatkan, Gungor (2011). The Hierarchical Beta Process for Convolutional Factor Analysis and Deep Learning. Machine Learning . . . Архів оригіналу за 22 лютого 2016. Процитовано 13 січня 2018. (англ.)
- Fei-Fei, Li; Fergus, Rob (2006). One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence 28 (4): 594–611. PMID 16566508. doi:10.1109/TPAMI.2006.79. (англ.)
- Rodriguez, Abel; Dunson, David (2008). The Nested Dirichlet Process. Journal of the American Statistical Association 103 (483): 1131–1154. doi:10.1198/016214508000000553. (англ.)
- Ruslan, Salakhutdinov; Joshua, Tenenbaum (2012). Learning with Hierarchical-Deep Models. IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8): 1958–71. PMID 23787346. doi:10.1109/TPAMI.2012.269. (англ.)
- Chalasani, Rakesh; Principe, Jose (2013). «Deep Predictive Coding Networks». arXiv:1301.3541 [cs.LG]. (англ.)
- Hinton, Geoffrey E. (1984). Distributed representations. (англ.)
- S. Das, C.L. Giles, G.Z. Sun, "Learning Context Free Grammars: Limitations of a Recurrent Neural Network with an External Stack Memory, " Proc. 14th Annual Conf. of the Cog. Sci. Soc., p. 79, 1992. (англ.)
- Mozer, M. C.; Das, S. (1993). A connectionist symbol manipulator that discovers the structure of context-free languages. NIPS 5. с. 863–870. (англ.)
- Schmidhuber, J. (1992). Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation 4 (1): 131–139. doi:10.1162/neco.1992.4.1.131. (англ.)
- Gers, F.; Schraudolph, N.; Schmidhuber, J. (2002). Learning precise timing with LSTM recurrent networks. JMLR 3: 115–143. (англ.)
- Jürgen Schmidhuber (1993). An introspective network that can learn to run its own weight change algorithm. In Proc. of the Intl. Conf. on Artificial Neural Networks, Brighton. IEE. с. 191–195. (англ.)
- Hochreiter, Sepp; Younger, A. Steven; Conwell, Peter R. (2001). Learning to Learn Using Gradient Descent. ICANN 2130: 87–94. (англ.)
- Grefenstette, Edward, et al. «Learning to Transduce with Unbounded Memory.»arXiv:1506.02516 (2015). (англ.)
- Graves, Alex, Greg Wayne, and Ivo Danihelka. «Neural Turing Machines.» arXiv:1410.5401 (2014). Шаблон:Ref-eb
- Burgess, Matt. DeepMind's AI learned to ride the London Underground using human-like reason and memory. WIRED UK (en-GB). Процитовано 19 жовтня 2016. (англ.)
- DeepMind AI 'Learns' to Navigate London Tube. PCMAG. Процитовано 19 жовтня 2016. (англ.)
- Mannes, John. DeepMind’s differentiable neural computer helps you navigate the subway with its memory. TechCrunch. Процитовано 19 жовтня 2016. (англ.)
- Graves, Alex; Wayne, Greg; Reynolds, Malcolm; Harley, Tim; Danihelka, Ivo; Grabska-Barwińska, Agnieszka; Colmenarejo, Sergio Gómez; Grefenstette, Edward та ін. (12 жовтня 2016). Hybrid computing using a neural network with dynamic external memory. Nature (англ.) 538 (7626): 471–476. Bibcode:2016Natur.538..471G. ISSN 1476-4687. PMID 27732574. doi:10.1038/nature20101. (англ.)
- Differentiable neural computers | DeepMind. DeepMind. Процитовано 19 жовтня 2016. (англ.)
- Atkeson, Christopher G.; Schaal, Stefan (1995). Memory-based neural networks for robot learning. Neurocomputing 9 (3): 243–269. doi:10.1016/0925-2312(95)00033-6. (англ.)
- Salakhutdinov, Ruslan, and Geoffrey Hinton. «Semantic hashing.» International Journal of Approximate Reasoning 50.7 (2009): 969—978. (англ.)
- Le, Quoc V.; Mikolov, Tomas (2014). «Distributed representations of sentences and documents». arXiv:1405.4053 [cs.CL]. (англ.)
- Weston, Jason, Sumit Chopra, and Antoine Bordes. «Memory networks.» arXiv:1410.3916 (2014). (англ.)
- Sukhbaatar, Sainbayar, et al. «End-To-End Memory Networks.» arXiv:1503.08895 (2015). (англ.)
- Bordes, Antoine, et al. «Large-scale Simple Question Answering with Memory Networks.» arXiv:1506.02075 (2015). (англ.)
- Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. «Pointer networks.» arXiv:1506.03134 (2015). (англ.)
- Kurach, Karol, Andrychowicz, Marcin and Sutskever, Ilya. «Neural Random-Access Machines.» arXiv:1511.06392 (2015). (англ.)
- Kalchbrenner, N.; Blunsom, P. (2013). Recurrent continuous translation models. EMNLP’2013. (англ.)
- Sutskever, I.; Vinyals, O.; Le, Q. V. (2014). Sequence to sequence learning with neural networks. NIPS’2014. (англ.)
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. (October 2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. Proceedings of the Empiricial Methods in Natural Language Processing 1406: arXiv:1406.1078. Bibcode:2014arXiv1406.1078C. arXiv:1406.1078. (англ.)
- Cho, Kyunghyun, Aaron Courville, and Yoshua Bengio. «Describing Multimedia Content using Attention-based Encoder--Decoder Networks.» arXiv:1507.01053 (2015). (англ.)
- Scholkopf, B; Smola, Alexander (1998). Nonlinear component analysis as a kernel eigenvalue problem. Neural computation (44) (5): 1299–1319. doi:10.1162/089976698300017467. (англ.)
- Cho, Youngmin (2012). Kernel Methods for Deep Learning. с. 1–9. (англ.)
- Deng, Li; Tur, Gokhan; He, Xiaodong; Hakkani-Tür, Dilek (1 грудня 2012). Use of Kernel Deep Convex Networks and End-To-End Learning for Spoken Language Understanding. Microsoft Research (амер.). (англ.)
- Zissis, Dimitrios (October 2015). A cloud based architecture capable of perceiving and predicting multiple vessel behaviour. Applied Soft Computing 35: 652–661. doi:10.1016/j.asoc.2015.07.002. (англ.)
- Roman M. Balabin; Ekaterina I. Lomakina (2009). Neural network approach to quantum-chemistry data: Accurate prediction of density functional theory energies. J. Chem. Phys. 131 (7): 074104. Bibcode:2009JChPh.131g4104B. PMID 19708729. doi:10.1063/1.3206326. (англ.)
- Sengupta, Nandini; Sahidullah, Md; Saha, Goutam (August 2016). Lung sound classification using cepstral-based statistical features. Computers in Biology and Medicine 75 (1): 118–129. doi:10.1016/j.compbiomed.2016.05.013. (англ.)
- French, Jordan. The time traveller's CAPM. Investment Analysts Journal 46 (2): 81–96. doi:10.1080/10293523.2016.1255469. (англ.)
- Schechner, Sam (15 червня 2017). Facebook Boosts A.I. to Block Terrorist Propaganda. Wall Street Journal (амер.). ISSN 0099-9660. Процитовано 16 червня 2017. (англ.)
- Ganesan, N. Application of Neural Networks in Diagnosing Cancer Disease Using Demographic Data. International Journal of Computer Applications. (англ.)
- Bottaci, Leonardo. Artificial Neural Networks Applied to Outcome Prediction for Colorectal Cancer Patients in Separate Institutions. The Lancet. (англ.)
- Alizadeh, Elaheh; Lyons, Samanthe M; Castle, Jordan M; Prasad, Ashok (2016). Measuring systematic changes in invasive cancer cell shape using Zernike moments. Integrative Biology 8 (11): 1183–1193. PMID 27735002. doi:10.1039/C6IB00100A. (англ.)
- Lyons, Samanthe (2016). Changes in cell shape are correlated with metastatic potential in murine. Biology Open 5 (3): 289–299. doi:10.1242/bio.013409. (англ.)
- null null (1 квітня 2000). Artificial Neural Networks in Hydrology. I: Preliminary Concepts. Journal of Hydrologic Engineering 5 (2): 115–123. doi:10.1061/(ASCE)1084-0699(2000)5:2(115). (англ.)
- null null (1 квітня 2000). Artificial Neural Networks in Hydrology. II: Hydrologic Applications. Journal of Hydrologic Engineering 5 (2): 124–137. doi:10.1061/(ASCE)1084-0699(2000)5:2(124). (англ.)
- Peres, D. J.; Iuppa, C.; Cavallaro, L.; Cancelliere, A.; Foti, E. (1 жовтня 2015). Significant wave height record extension by neural networks and reanalysis wind data. Ocean Modelling 94: 128–140. Bibcode:2015OcMod..94..128P. doi:10.1016/j.ocemod.2015.08.002. (англ.)
- Dwarakish, G. S.; Rakshith, Shetty; Natesan, Usha (2013). Review on Applications of Neural Network in Coastal Engineering. Artificial Intelligent Systems and Machine Learning (English) 5 (7): 324–331. (англ.)
- Ermini, Leonardo; Catani, Filippo; Casagli, Nicola (1 березня 2005). Artificial Neural Networks applied to landslide susceptibility assessment. Geomorphology. Geomorphological hazard and human impact in mountain environments 66 (1): 327–343. Bibcode:2005Geomo..66..327E. doi:10.1016/j.geomorph.2004.09.025. (англ.)
- Introduction to Dynamic Neural Networks - MATLAB & Simulink. www.mathworks.com. Процитовано 15 червня 2017. (англ.)
- Forrest MD (April 2015). Simulation of alcohol action upon a detailed Purkinje neuron model and a simpler surrogate model that runs >400 times faster. BMC Neuroscience 16 (27). doi:10.1186/s12868-015-0162-6. (англ.)
- Siegelmann, H.T.; Sontag, E.D. (1991). Turing computability with neural nets. Appl. Math. Lett. 4 (6): 77–80. doi:10.1016/0893-9659(91)90080-F. (англ.)
- Balcázar, José (Jul 1997). Computational Power of Neural Networks: A Kolmogorov Complexity Characterization. Information Theory, IEEE Transactions on 43 (4): 1175–1183. doi:10.1109/18.605580. Процитовано 3 листопада 2014. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Crick, Francis (1989). The recent excitement about neural networks. Nature 337 (6203): 129–132. Bibcode:1989Natur.337..129C. PMID 2911347. doi:10.1038/337129a0. (англ.)
- Adrian, Edward D. (1926). The impulses produced by sensory nerve endings. The Journal of Physiology 61 (1): 49–72. PMC 1514809. PMID 16993776. doi:10.1113/jphysiol.1926.sp002273. (англ.)
- Dewdney, A. K. (1 квітня 1997). Yes, we have no neutrons: an eye-opening tour through the twists and turns of bad science. Wiley. с. 82. ISBN 978-0-471-10806-1. (англ.)
- D. J. Felleman and D. C. Van Essen, "Distributed hierarchical processing in the primate cerebral cortex, " Cerebral Cortex, 1, pp. 1-47, 1991. (англ.)
- J. Weng, "Natural and Artificial Intelligence: Introduction to Computational Brain-Mind, " BMI Press, ISBN 978-0985875725, 2012. (англ.)
- Edwards, Chris (25 червня 2015). Growing pains for deep learning. Communications of the ACM 58 (7): 14–16. doi:10.1145/2771283. (англ.)
- Schmidhuber, Jürgen (2015). Deep learning in neural networks: An overview. Neural Networks 61: 85–117. PMID 25462637. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. (англ.)
- Cade Metz (18 травня 2016). Google Built Its Very Own Chips to Power Its AI Bots. Wired. (англ.)
- NASA — Dryden Flight Research Center — News Room: News Releases: NASA NEURAL NETWORK PROJECT PASSES MILESTONE. Nasa.gov. Retrieved on 2013-11-20. (англ.)
- Roger Bridgman's defence of neural networks Архівовано 19 березня 2012 у Wayback Machine. (англ.)
- Scaling Learning Algorithms towards {AI} - LISA - Publications - Aigaion 2.0. (англ.)
- Sun and Bookman (1990) (англ.)
- Tahmasebi; Hezarkhani (2012). A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation. Computers & Geosciences 42: 18–27. Bibcode:2012CG.....42...18T. doi:10.1016/j.cageo.2012.02.004. (англ.)
- Hinton, Geoffrey E. (1984). Distributed representations. (англ.)
Література
- Bhadeshia H. K. D. H. (1999). Neural Networks in Materials Science. ISIJ International 39 (10): 966–979. doi:10.2355/isijinternational.39.966. (англ.)
- M., Bishop, Christopher (1995). Neural networks for pattern recognition. Clarendon Press. ISBN 0198538499. OCLC 33101074. (англ.)
- Cybenko, G.V. (2006). Approximation by Superpositions of a Sigmoidal function. У van Schuppen, Jan H. Mathematics of Control, Signals, and Systems. Springer International. с. 303–314. PDF (англ.)
- Dewdney, A. K. (1997). Yes, we have no neutrons : an eye-opening tour through the twists and turns of bad science. New York: Wiley. ISBN 9780471108061. OCLC 35558945. (англ.)
- Duda, Richard O.; Hart, Peter Elliot; Stork, David G. (2001). Pattern classification (вид. 2). Wiley. ISBN 0471056693. OCLC 41347061. (англ.)
- Egmont-Petersen, M.; de Ridder, D.; Handels, H. (2002). Image processing with neural networks – a review. Pattern Recognition 35 (10): 2279–2301. doi:10.1016/S0031-3203(01)00178-9. (англ.)
- Gurney, Kevin (1997). An introduction to neural networks. UCL Press. ISBN 1857286731. OCLC 37875698. (англ.)
- Haykin, Simon S. (1999). Neural networks : a comprehensive foundation. Prentice Hall. ISBN 0132733501. OCLC 38908586. (англ.)
- Fahlman, S.; Lebiere, C (1991). The Cascade-Correlation Learning Architecture.created for National Science Foundation, Contract Number EET-8716324, and Defense Advanced Research Projects Agency (DOD), ARPA Order No. 4976 under Contract F33615-87-C-1499. (англ.)
- Hertz, J.; Palmer, Richard G.; Krogh, Anders S. (1991). Introduction to the theory of neural computation. Addison-Wesley. ISBN 0201515601. OCLC 21522159.</ref> (англ.)
- Lawrence, Jeanette (1994). Introduction to neural networks : design, theory and applications. California Scientific Software. ISBN 1883157005. OCLC 32179420. (англ.)
- Information theory, inference, and learning algorithms. Cambridge University Press. ISBN 9780521642989. OCLC 52377690. (англ.)
- MacKay, David, J.C. (2003). Information Theory, Inference, and Learning Algorithms. Cambridge University Press. ISBN 9780521642989. (англ.)
- Masters,, Timothy (1994). Signal and image processing with neural networks : a C++ sourcebook. J. Wiley. ISBN 0471049638. OCLC 29877717. (англ.)
- Ripley, Brian D. (2007). Pattern Recognition and Neural Networks. Cambridge University Press. ISBN 978-0-521-71770-0. (англ.)
- Siegelmann, H.T.; Sontag, Eduardo D. (1994). Analog computation via neural networks. Theoretical Computer Science 131 (2): 331–360. doi:10.1016/0304-3975(94)90178-3. (англ.)
- 1944-, Smith, Murray, (1993). Neural networks for statistical modeling. Van Nostrand Reinhold. ISBN 0442013108. OCLC 27145760.</ref> Smith, Murray (1993) Neural Networks for Statistical Modeling, Van Nostrand Reinhold, ISBN 0-442-01310-8 (англ.)
- Wasserman, Philip D. (1993). Advanced methods in neural computing. Van Nostrand Reinhold. ISBN 0442004613. OCLC 27429729. (англ.)
- Kruse, Rudolf,; Borgelt, Christian; Klawonn, F.; Moewes, Christian; Steinbrecher, Matthias; Held,, Pascal (2013). Computational intelligence : a methodological introduction. Springer. ISBN 9781447150121. OCLC 837524179. (англ.)
- Borgelt,, Christian (2003). Neuro-Fuzzy-Systeme : von den Grundlagen künstlicher Neuronaler Netze zur Kopplung mit Fuzzy-Systemen. Vieweg. ISBN 9783528252656. OCLC 76538146. (нім.)
Посилання
Англійською
- Performance comparison of neural network algorithms tested on UCI data sets
- A close view to Artificial Neural Networks Algorithms
- A Brief Introduction to Neural Networks (D. Kriesel) — Illustrated, bilingual manuscript about artificial neural networks; Topics so far: Perceptrons, Backpropagation, Radial Basis Functions, Recurrent Neural Networks, Self Organizing Maps, Hopfield Networks.
- Neural Networks in Materials Science
- A practical tutorial on Neural Networks
- Applications of neural networks
- An Introduction to Deep Neural Networks.
- A Tutorial of Neural Network in Excel.
- MIT course on Neural Networks на YouTube
- A Concise Introduction to Machine Learning with Artificial Neural Networks
- Neural Networks for Machine Learning — a course by Geoffrey Hinton
- Deep Learning
- Artificial Neural Network for PHP 5.x
- Forecasting Financial Markests using Artificial Neural Networks
Російською
- Лекции по нейроинформатике
- Форум по нейросетям на BaseGroup Labs
- Описание нейросетевых алгоритмов
- Миркес Е. М., Нейроинформатика: Учеб. пособие для студентов с программами для выполнения лабораторных работ.
- Пошаговые примеры реализации наиболее известных типов нейронных сетей на MATLAB, Neural Network Toolbox
- Лекции по нейронным сетям
- Статья противника применения нейронных сетей в прогнозировании цен на акции
- Подборка статей по нейронным сетям
- Лекции по нейроинформатике и смежным вопросам обучения машин
- О приоритете авторства в вопросе пригодности любой нелинейной функции нейрона для возможности представления нейросетью любой функции многих переменных