Задача про розбиття
У теорії чисел та інформатиці, задачею про розбиття (або розбиття числа[1]) є визначення того, чи можна дану множину S натуральних чисел розбити на дві підмножини S1 і S2 так, щоб сума чисел у S1 дорівнювала сумі чисел в S2. Хоча задача про розбиття NP-повна, існує псевдо-поліноміальне рішення динамічного програмування часу, і є евристики, які вирішують цю задачу оптимально або приблизно. З цієї причини її назвали «найлегшою NP-важкою задачею» [2].
Існує версія оптимізації задачі про розбиття, яка полягає в розбитті мультимножини S на дві підмножини S1, S2, так що різниця між сумою елементів в S1 і сумою елементів в S2 мінімізована. Оптимізаційна версія NP-важка, але на практиці її можна ефективно вирішити.[3]
Задача про розбиття є окремим випадком задачі про суми підмножин, тому її можна точно розв'язати за час O(2S/2).
Приклади
Якщо S = {3,1,1,2,2,1}, дійсним рішенням задачі розподілу є дві множини S1 = {1,1,1,2} and S2 = {2,3}. Обидва набори мають суму 5, та утворюють розбиття множини S. Зверніть увагу, що це рішення не є унікальним. S1 = {3,1,1} and S2 = {2,2,1} - інше рішення. Не кожну множину позитивних цілих чисел можна розбити на дві частини з однаковою сумою. Прикладом такого набору є S = {2,5}.
Алгоритм псевдо-поліноміального часу
Задача може бути вирішена за допомогою динамічного програмування, коли розмір набору і розмір суми цілих чисел в наборі не надто великі, щоб зробити вимоги до зберігання недосяжними.
Припустимо, що вхідним значенням для алгоритму є список форми: S = x1, ..., xn
Нехай N - кількість елементів в S. Нехай K - сума всіх елементів в S. Тобто: K = x1 + ... + xn. Ми побудуємо алгоритм, який визначає, чи існує підмножина S, яка додається до . Якщо є підмножина, то:

Якщо сума K парна, залишок S також підсумовується до
Якщо сума K непарна, то залишок S підсумовується з . Це найкраще рішення.

Рекурентне відношення
Ми хочемо визначити, чи існує підмножина S, котра дорівнює . Нехай:
- p(i, j) буде Істина (True), якщо мультимножина { x1, ..., xj } дорівнює i , та Хибно (False), якщо навпаки.
Тоді p(, n) - це Істина тоді та тільки тоді, коли існує мультимножина S, котра дорівнює . Метою нашого алгоритму буде обчислення p(, n). Для цього ми маємо наступне рекурентне співвідношення:
- p(i, j) істинно, якщо p(i, j − 1) істинно або p(i − xj, j − 1) істинно,
- p(i, j) хибне, навпаки.
Це пояснюється наступним чином: є деяка підмножина S, яке підсумовує з i, використовуючи числа
- x1, ..., xj
Тоді та тільки тоді, коли виконано одну з наступних умов:
- Існує підмножина { x1, ..., xj-1 } , котра дорівнює i;
- Існує підмножина { x1, ..., xj-1 } котра дорівнює i − xj, коли xj + сума підмножини = i.
Псевдо-поліноміальний алгоритм
Алгоритм полягає в тому, щоб створити таблицю розміру по n , що містить значення повторення. Пам'ятайте, що K - це розмір суми, а N - це . кількість елементів. Коли вся таблиця заповнена, поверніть P(, n). Нижче наведено зображення таблиці P. Існує синя стрілка від одного блоку до іншого, якщо значення цільового блоку може залежати від значення вихідного блоку. Ця залежність є властивістю рекурентного співвідношення.
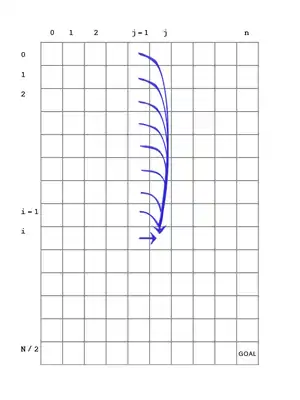
INPUT: A list of integers S OUTPUT: True if S can be partitioned into two subsets that have equal sum 1 function find_partition(S): 2 n ← |S| 3 K ← sum(S) 4 P ← empty boolean table of size ( + 1) by (n + 1) 5 initialize top row (P(0,x)) of P to True 6 initialize leftmost column (P(x, 0)) of P, except for P(0, 0) to False 7 for i from 1 to 8 for j from 1 to n 9 if (i-S[j-1]) >= 0 10 P(i, j) ← P(i, j-1) or P(i-S[j-1], j-1) 11 else 12 P(i, j) ← P(i, j-1) 13 return P(, n)
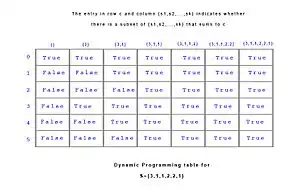
Приклад
Нижче наведена таблиця P для прикладу, що використовується вище S = {3, 1, 1, 2, 2, 1}:
Аналіз
Цей алгоритм працює з часом O(K N), де N - кількість елементів у наборі вхідних даних та K - сума елементів у вхідній множині.
Алгоритм може бути розширений до k-задачі багаторозбиття, але потім приймає O(n(k − 1)mk − 1) пам'ять, де m - найбільше число на вході, що робить його непрактичним навіть для k = 3 , якщо входи не є дуже маленькими числами. [3]
Цей алгоритм можна узагальнити для вирішення задачі про суми підмножин.
Апроксимаційні алгоритми
Існує кілька евристичних алгоритмів для отримання наближень до задачі оптимізації розбиття. Вони можуть бути розширені до точних алгоритмів лінійного простору.[3]
Жадібний алгоритм
Один з підходів до задачі, що імітує те, як діти вибирають команди для гри, — це жадібний алгоритм, який виконує ітерацію за номерами в порядку убування, привласнюючи кожному з них те, що підмножина має меншу суму. Цей підхід має час роботи O(n log n). Ця евристика добре працює на практиці, коли цифри в наборі приблизно того ж розміру, що і потужність, або менше, але не гарантується, що буде створений найкращий розділ. Наприклад, якщо ввести S = {4, 5, 6, 7, 8} як вхідні дані, цей жадібний алгоритм розбив би S на підмножини {4, 5, 8} та {6, 7}; однак, S має точно збалансоване розбиття на підмножини {7, 8} та {4, 5, 6}.
Відомо, що цей жадібний підхід дає 7⁄6-наближення до оптимального рішення версії оптимізації; Тобто, якщо жадібний алгоритм виводить два набори A та B, то max(∑A, ∑B) ≤ 76 OPT, де OPT це розмір більшого набору в найкращому можливому розділі.[4]Нижче наведено приклад (написаний на мові Python) для жадібного алгоритму..
def find_partition(int_list):
"returns: An attempt at a partition of `int_list` into two sets of equal sum"
A = set()
B = set()
for n in sorted(int_list, reverse=True):
if sum(A) < sum(B):
A.add(n)
else:
B.add(n)
return (A, B)
Цей алгоритм може бути поширений на випадок k > 2 множин: для того, щоб узяти k найбільших елементів і для кожного розбиття їх розширює розділ, послідовно додаючи інші елементи в залежності від того, який набір менше. (Проста версія вище відповідає k = 2.) Ця версія працює в часі O(2k n2) і, як відомо, дає (k + 2)(k + 1) наближення.[4] Таким чином, ми маємо схему наближення поліноміального часу (PTAS)для завдання про розбиття чисел, хоча це не повністю поліноміальна схема наближення часу (час роботи є експоненціальним у гарантованій задачі наближення). Однак існують варіанти цієї ідеї, які є повністю поліноміальними схемами апроксимації для завдання підмножини, а отже, і для завдання розбиття.[5]
Метод найбільшої різниці
Іншою евристикою є метод найбільшої різниці (largest differencing method, LDM),[6] що також має назву евристика Кармаркар—Карпа, за прізвищами пари вчених, що опублікували роботу по цій темі в 1982 році.[7] LDM працює в два етапи. Перша фаза алгоритму приймає два найбільших числа від входу і замінює їх їхньою різницею. Це повторюється до тих пір, поки не залишиться тільки одне число. Заміна є рішення розмістити два числа в різних наборах, не вдаючись до негайного визначення того, в якому з них встановлено. В кінці першого етапу єдиним числом, що залишилося, буде різниця двох сум підмножини. Друга фаза реконструює фактичне рішення.[2]
Евристика різниць працює краще, ніж жадібна, але все ще погано для випадків, коли числа є експонентними за розміром набору.[2]
Наступна програма на Java реалізує перший етап Кармаркар—Карпа. Він використовує купу, щоб знайти пару найбільших чисел, які залишилися.
int karmarkarKarpPartition(int[] baseArr) {
// create max heap
PriorityQueue<Integer> heap = new PriorityQueue<Integer>(baseArr.length, REVERSE_INT_CMP);
for (int value : baseArr) {
heap.add(value);
}
while(heap.size() > 1) {
int val1 = heap.poll();
int val2 = heap.poll();
heap.add(val1 - val2);
}
return heap.poll();
}
Інші підходи
Існують також алгоритми будь-якого часу, засновані на евристичному різницевої аналізі, які спочатку знаходять рішення, повернене евристикою разностного аналізу, потім знаходять прогресивно кращі рішення в міру того, як дозволяє час (можливо, вимагаючи експоненціального часу для досягнення оптимальності для найгірших випадків).[8]
Жорсткі інстанції
Набори з одним або без поділу, як правило, складніше (або найбільш дорогі) вирішувати в порівнянні з їх розмірами введення. Коли значення малі в порівнянні з розміром набору, більш досконалі розділи більш вірогідні. Відомо, що задача зазнає «фазовий перехід»; Ймовірно, для деяких наборів і малоймовірно для інших. Якщо m — число біт, необхідне для вираження будь-якого числа в наборі, а n — розмір набору, то має багато рішень і , як правило, мало або взагалі не має рішень. У міру того як n і m стають більше, ймовірність вчиненого розбиття дорівнює 1 або 0 відповідно. Це спочатку стверджувалося на основі емпіричних даних Гента і Уолша[9], потім використовуючи методи статистичної фізики Мертенса[10], а потім довів Боргс, Чайс і Піттель.[11]


Варіанти та узагальнення
Існує задача, звана задача про трирозбиття, яка полягає в розбитті множини S до |S|/3 трійок з однаковою сумою. Ця задача суттєво відрізняється від задачі розділу і не має псевдо-поліноміального алгоритму часу, якщо P = NP.[12]
Задача багатосторінкового розділу узагальнює оптимізаційну версію задачі про розбиття. Тут мета полягає в тому, щоб розбити безліч або мультимножину з n цілих чисел на задане число k підмножин, мінімізуючи різницю між найменшою і найбільшою сумою підмножини.[3]
Для подальших узагальнень задачі про розбиття див. задачі про пакування в ємності.
Імовірнісна версія
Пов'язана з цим задача, в чомусь схожа на парадокс днів народження, полягає у визначенні розміру вхідної множини так, щоб ймовірність існування розв'язку була 50%, за припущення, що кожен елемент в наборі вибирається випадково за рівномірним розподілом між 1 і деяким заданим значенням.
Вирішення цієї задачі може бути нелогічним, як парадокс дня народження. Наприклад, якщо елементи вибираються випадковим чином в межах від 1 до 1 мільйона, інтуїція багатьох людей полягає в тому, що відповідь знаходиться в тисячах, десятках або навіть в сотнях тисяч, тоді як правильна відповідь становить приблизно 23 (див. Парадокс днів народження § апроксимація).[джерело?]
Нотатки
- Hayes, Brian (May–June 2002). The Easiest NP Hard Problem. American Scientist.
- Karmarkar, Narenda; Karp, Richard M (1982). The Differencing Method of Set Partitioning. Technical Report UCB/CSD 82/113 (University of California at Berkeley: Computer Science Division (EECS)).
- Gent, Ian; Walsh, Toby (August 1996). Phase Transitions and Annealed Theories: Number Partitioning as a Case Study. У Wolfgang Wahlster. Proceedings of 12th European Conference on Artificial Intelligence ECAI-96. John Wiley and Sons. с. 170–174.
- Gent, Ian; Walsh, Toby (1998). Analysis of Heuristics for Number Partitioning. Computational Intelligence 14 (3): 430–451. doi:10.1111/0824-7935.00069.
- Mertens, Stephan (November 1998). Phase Transition in the Number Partitioning Problem. Physical Review Letters 81 (20): 4281. Bibcode:1998PhRvL..81.4281M. arXiv:cond-mat/9807077. doi:10.1103/PhysRevLett.81.4281. Процитовано 3 жовтня 2009.
- Mertens, Stephan (2001). A physicist's approach to number partitioning. Theoretical Computer Science 265 (1-2): 79–108. doi:10.1016/S0304-3975(01)00153-0.
- Mertens, Stephan (2006). The Easiest Hard Problem: Number Partitioning. У Allon Percus; Gabriel Istrate; Cristopher Moore. Computational complexity and statistical physics. Oxford University Press US. с. 125. Bibcode:2003cond.mat.10317M. ISBN 9780195177374. arXiv:cond-mat/0310317.
- Borgs, Christian; Chayes, Jennifer; Pittel, Boris (2001). Phase transition and finite-size scaling for the integer partitioning problem. Random Structures and Algorithms 19 (3-4): 247–288. doi:10.1002/rsa.10004. Процитовано 4 жовтня 2009.
- Korf, Richard E. (1998). A complete anytime algorithm for number partitioning. Artificial Intelligence 106 (2): 181–203. ISSN 0004-3702. doi:10.1016/S0004-3702(98)00086-1. Процитовано 4 жовтня 2009.
- Mertens, Stephan (1999). A complete anytime algorithm for balanced number partitioning. Bibcode:1999cs........3011M. arXiv:cs/9903011.
Примітки
- Korf, 1998
- Hayes, 2002
- Korf, Richard E. (2009). Multi-Way Number Partitioning IJCAI.
- Ron L. Graham (1969). Bounds on multiprocessor timing anomalies. SIAM J. Appl. Math. 17 (2). с. 416–429.
- Martello, Silvano; Toth, Paolo (1990). 4 Subset-sum problem. Knapsack problems: Algorithms and computer interpretations. Wiley-Interscience. с. 105–136. ISBN 0-471-92420-2. MR 1086874.
- Michiels, Wil; Korst, Jan; Aarts, Emile (2003). Performance ratios for the Karmarkar–Karp differencing method. Electronic Notes in Discrete Mathematics 13: 71–75.
- Karmarkar & Karp, 1982
- Korf, 1998, Mertens, 1999
- Gent & Walsh, 1996
- Mertens, 1998
- Borgs, Chayes & Pittel, 2001
- Garey, Michael; Johnson, David (1979). Computers and Intractability; A Guide to the Theory of NP-Completeness. с. 96–105. ISBN 0-7167-1045-5.