Бінарна класифікація
Бінарна класифікація — клас задач класифікації елементів набору даних на дві групи на підставі правила класифікації.
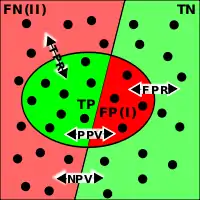
Типові задачі бінарної класифікації:
- медичне тестування, яке дозволяє визначити, наявність або відсутність певного захворювання;
- технічні випробування або контроль якості на виробництві на відповідність або невідповідність виробу вимогам специфікації;
- інформаційний пошук, за результатами якого приймається рішення про включення або невключення деякого інформаційного ресурсу в набір результатів пошуку. В цьому правило класифікації це релевантність пошуковому запиту або корисність для користувача.
Важливим моментом бінарної класифікації є те, що два класи звичайно не симетричні як за обсягом відмінних наборів даних з кожного класу, так і за наслідками помилкової класифікації. Наприклад, у медичному тестуванні варіативність даних про кров'яний тиск є значно меншою, ніж варіативність цих даних для хворих, а наслідком помилки класифікації стане призначення лікування здоровій людині або непризначення хворій.
Статистична бінарна класифікація
Задача класифікації є предметом розгляду в машинному навчанні. Це задача навчання з учителем — метод в якому категорії відомі, і задача полягає у визначенні цих категорій для нових спостережень. Коли таких категорій всього дві, то це статистична бінарна класифікація.
Для автоматизованого вирішення задач бінарної класифікації часто застосовують методи, як
- дерево рішень
- random forest
- баєсова мережа
- опорні вектори
- штучна нейронна мережа
- логістична регресія
- пробіт регресія
Якість класифікатора залежить від предметної області та від кількості спостережень, розмірності вектора ознак, шуму в даних та багатьох інших факторів. Наприклад, random forest на хмарах 3D-точок працює краще, ніж метод опорних векторів.[1][2]
Оцінки бінарних класифікацій
Існує багато метрик, які можна використовувати для вимірювання продуктивності класифікатора або якості прогнозу. Різні поля мають різні переваги для конкретних метрик, які відповідають різним цілям. Наприклад, в медицині часто використовуються чутливість і специфічність, в той час як при добуванні інформації вважають за краще влучність і повноту. Важливою відмінністю в метриках полягає в тому, чи є вона незалежної від поширеності (як часто кожна категорія зустрічається в популяції, англ. prevalence) і метрики, які залежать від поширеності обох типів також корисні, але вони дуже відрізняються властивостями.
Примітки
- Zhang & Zakhor, Richard & Avideh (2014). Automatic Identification of Window Regions on Indoor Point Clouds Using LiDAR and Cameras. VIP Lab Publications.
- Y. Lu and C. Rasmussen (2012). Simplified markov random fields for efficient semantic labeling of 3D point clouds. IROS.
Література
- Nello Cristianini and John Shawe-Taylor. An Introduction to Support Vector Machines and other kernel-based learning methods. Cambridge University Press, 2000. ISBN 0-521-78019-5 ( SVM Book)
- John Shawe-Taylor and Nello Cristianini. Kernel Methods for Pattern Analysis. Cambridge University Press, 2004. ISBN 0-521-81397-2 ( Kernel Methods Book)
- Bernhard Schölkopf and A. J. Smola: Learning with Kernels. MIT Press, Cambridge, Massachusetts, 2002. (Partly available on line: .) ISBN 0-262-19475-9