Графова база даних
Графова база даних — це база даних, яка використовує структури графів для семантичних запитів з вершинами, ребрами та властивостями для представлення та зберігання даних. Ключовим поняттям системи є «граф» (або «ребро» або «відносини»), який безпосередньо пов'язує елементи даних у сховищі. Відносини дозволяють безпосередньо об'єднувати дані у сховищі, а в багатьох випадках, вибрати однією операцією.
Це відрізняється від реляційних баз даних, які за допомогою реляційних систем управління дозволяють керувати даними без накладання аспектів реалізації; наприклад, зв'язки між даними зберігаються в самій базі даних на логічному рівні, і операції реляційної алгебри (наприклад, join можуть використовуватися для маніпулювання та повернення відповідних даних у відповідний логічний формат. Виконання реляційних запитів можливе за допомогою систем управління базами даних на фізичному рівні (наприклад, за допомогою індексів), що дозволяє підвищити продуктивність без зміни логічної структури бази даних.
Графові бази даних аналогічні базам даних мережевої моделі 1970-х років, в обох представлені загальні графи, але бази даних мережевих моделей працюють на нижчому рівні абстракції[1] та їм бракує легкого проходу через ланцюг ребер.[2]
Основний механізм зберігання графових баз даних може бути різним. Деякі з них залежать від реляційного двигуна та «зберігають» дані графу у таблицях (хоча таблиця є логічним елементом, цей підхід передбачає інший рівень абстракції між графовою базою даних, системою управління бази даних та фізичними пристроями, де фактично зберігаються дані). Інші використовують тип сховища ключ-значення або документо-орієнтований тип для зберігання, що робить їх по суті NoSQL структурами. Більшість графових баз даних, заснованих на не реляційних двигунах зберігання, додають поняття теги або властивості, які, по суті, мають зв'язки з покажчиком на інший документ. Це дозволяє класифікувати елементи даних для легкого пошуку «в масовому порядку».
Отримання даних з графової бази даних вимагає мови запитів, відмінної від SQL, яка була розроблена для маніпулювання даними в реляційній системі і тому не може «елегантно» обробляти граф. Станом на 2017 жодна мова запитів не була загальноприйнятою таким же чином, як SQL для реляційних баз даних. Найпоширенішими мовами запитів є Gremlin, SPARQL та Cypher.
Опис
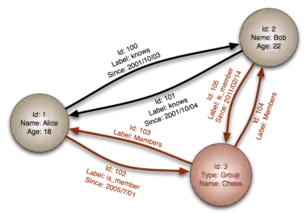
Графові бази даних базуються на теорії графів і використовують вершини, ребра та властивості.
- Вершини або вузли представляють такі об'єкти, як люди, підприємства, облікові записи або будь-який інший об'єкт, який слід відслідковувати. Вони приблизно еквівалентні «запису», «відношенню» або «рядку» в реляційній базі даних або «документу» в документо-орієнтованій базі даних.
- Ребра, також називаються графи або відносини, це лінії, що з'єднують вузли до інших вузлів; вони представляють відносини між ними. Змістовні моделі виникають при розгляді зв'язків і взаємозв'язків вузлів, властивостей і ребер. Ребра є ключовими поняттями в графовій базі даних, що представляють собою абстракцію, яка безпосередньо не реалізована в інших системах.
- Властивості це рідна інформація, яка стосується вузлів. Наприклад, якщо Вікіпедія була б одним із вузлів, вона могла б бути прив'язана до таких властивостей, як вебсайт, довідковий матеріал або слово, яке починається з букви «в», залежно на яких аспектах «Вікіпедія» знаходиться в певній базі даних.
Реляційна модель збирає дані разом, використовуючи інформацію в даних. Наприклад, можна шукати всіх «користувачів», чий номер телефону містить код міста «311». Це буде зроблено шляхом пошуку обраних даних, або таблиць, дивлячись у вибрані поля номера телефону для рядка «311». Це може бути тривалим процесом у великих таблицях, тому реляційні бази даних пропонують концепцію «індекс таблиці бази даних», що дозволяє зберігати дані, як ці, у меншій субтаблиці, що містить лише вибрані дані та унікальний ключ (або «первинний ключ») запису, в якій вона є частиною. Якщо номери телефонів індексуються, той же пошук буде відбуватися в меншій таблиці з індексом, збирати ключі відповідних записів, а потім переглядати основну таблицю даних для записів за допомогою цих ключів. Як правило, таблиці фізично зберігаються так, що пошук цих ключів відбувається швидко.[3]
Реляційні бази даних не містять ідеї фіксованих зв'язків між записами. Натомість дані зв'язуються один з одним, зберігаючи унікальний ключ одного запису в даних іншого запису. Наприклад, таблиця, що містить адреси електронної пошти для користувачів, може мати елемент даних, який називається userpk, який містить основний ключ запису користувача, до якого він пов'язаний. Для того, щоб пов'язати користувачів та їх електронні адреси, система спочатку шукає вибрані користувацькі записи з основними ключами, шукає ці ключі в стовпці userpk у таблиці електронної пошти (або, швидше за все, їх індекс), витягує дані електронної пошти, а потім зв'язує записи користувача та електронної пошти, щоб створити складові записи, що містять усі обрані дані. Ця операція, яка називається join, може бути обчислена за витратами. Залежно від складності запиту, кількості об'єднань та індексації різних клавіш, система, можливо, повинна буде шукати через кілька таблиць та індексів, збирати багато інформації, а потім сортувати все, щоб вони збігалися.[3]
На відміну від реляційних баз, графові бази даних безпосередньо зберігають відносини між записами. Замість того, щоб знайти адресу електронної пошти, переглянувши ключ користувача в стовпці userpk , користувацький запис має покажчик безпосередньо до адреси електронної пошти. Тобто, вибравши користувача, можна безпосередньо перейти до записів електронної пошти, немає необхідності шукати в таблиці електронної пошти, щоб знайти відповідні записи. Це може усунути дорогі операції приєднання (join). Наприклад, якщо пошук здійснюється за всіма адресами електронної пошти для користувачів з кодом області «311», то спочатку виконується звичайний пошук, щоб знайти користувачів в «311», але потім витягуються адреси електронної пошти за посиланнями, знайдені в ціх записах. Реляційна база даних спочатку знайде всіх користувачів в «311», витягне список pk's, виконає інший пошук будь-яких записів в таблиці електронної пошти з цими pk's і з'єднає відповідні записи. Для цих типів загальних операцій, графова база даних (принаймні теоретично) значно швидше.[3]
Справжнє значення графового підходу стає очевидним, коли виконуються пошуки, які глибше ніж один рівень. Наприклад, вкажіть пошук користувачів, які мають «абонентів» (таблицю, що зв'язує користувачів з іншими користувачами) в коді регіону «311». У цьому випадку реляційна база даних повинна спочатку шукати всіх користувачів з кодом міста в «311», а потім переглянути таблицю абонентів для будь-якого з цих користувачів, а потім, нарешті, переглянути таблицю користувачів, щоб отримати відповідних користувачі. На відміну від цього, графова база даних буде шукати всіх користувачів в «311», а потім слідувати зворотним посиланням через відносини з підпискою, щоб знайти користувачів-абонентів. Це дозволяє уникнути декількох запитів. Технічно такий пошук виконується за O(log(n)) + O(1) тобто приблизно логарифму. На відміну від реляційної версії де буде кілька O(log(n)) пошуку, а також треба більше часу, щоб приєднати всі дані.[3]
Відносна перевага отримання графу зростає з ускладненням запиту. Наприклад, можна було б знати «цей фільм про підводні човни з актором, який був у цьому фільмі разом з тим актором, який зіграв лідера у Gone With the Wind». Це спочатку вимагає, щоб система знайшла акторів у «Gone With the Wind», знайшла всі фільми, в яких ці актори були, знайшла їх у всіх цих фільмах, де вони не були лідерами у «Gone With the Wind», а потім знайшли всі фільми де вони були, нарешті, відфільтрувати цей список тим, де опис «підводний човен». У реляційній базі даних це вимагатиме декількох окремих пошуків через таблиці фільмів та акторів, здійснення іншого пошуку в фільмах з підводним човнем, пошуку всіх акторів у цих фільмах та порівняння (великих) зібраних результатів. На відміну від цього, графова база даних буде просто ходити від «Віднесеного вітром» до «Кларк Гейбл», збирати посилання на фільми, в яких він був, збирати посилання з цих фільмів на інших учасників, а потім слідкувати за посиланнями з цих акторів назад до списку фільмів. Отриманий список фільмів може потім шукати для «підводного човна». Все це можна зробити за допомогою одного пошуку.
Реляційні бази даних дуже добре підходять для плоских макетів даних, де взаємозв'язок між даними є глибиною одного або двох рівнів. Наприклад, для бухгалтерської бази даних, можливо, доведеться шукати всі позиції для всіх рахунків-фактур для даного клієнта, запит з трьох приєднань. Бази даних діаграм націлені на набори даних, які містять багато інших посилань. Вони особливо добре підходять для систем соціальна мережа, де відносини «друзів» є суто необмеженими. Ці властивості створюють графові бази даних, які, природно, підходять для типів пошуків, які все частіше зустрічаються в онлайнових системах та у середовищах «великі дані». З цієї причини графові бази даних стають дуже популярними для великих онлайнових систем, таких як Facebook, Google, Twitter та подібних систем із глибокими зв'язками між записами.
Історія
В середині 1960-х років навігаційні бази даних, такі як IMS, підтримували деревоподібні структури у своїй ієрархічній моделі, але жорстку структуру дерева можна було обійти з віртуальними записами.[4][5]
Графові структури можуть бути представлені в мережевих моделях баз даних з кінця 1960-х років. CODASYL, яка визначила COBOL у 1959 році, також визначила мову мережевої бази даних в 1969 році.
Позначені графи можуть бути представлені у графових базах даних з середини 1980-х років, наприклад модель логічних даних.[1][6]
Кілька покращень у графових базах даних з'явилися на початку 1990-х років, прискорюючи наприкінці 1990-х років зусилля для індексування веб-сторінок.
У середині кінця 2000-х років стали доступними комерційні (ACID) графові бази даних, такі як Neo4j та Oracle Spatial and Graph.
В 2010-х, комерційні ACID графові бази даних, що можуть бути розширені по горизонталі стали доступними. Крім того, SAP HANA представила технології in-memory і CODB для графових баз даних.[7] Також у 2010-х роках стали доступними багатопрофільні бази даних, які підтримували графові моделі (та інші моделі, такі як реляційна база даних або документ-орієнтована база даних), такі як OrientDB, ArangoDB та MarkLogic (починаючи з версії 7.0). За цей час графові бази даних різних типів стали особливо популярними в аналізі соціальних мереж з появою соціальних медіа компаній.
Перелік графових баз даних
Нижче наведено список відомих графових баз даних:
| Назва | Версія | Ліцензія | Мова | Опис |
|---|---|---|---|---|
| AllegroGraph | 5.1 (Травень 2015) | власницька, клієнти: Eclipse Public License v1 | C#, C, Common Lisp, Java, Python | Середовище опису ресурсів (RDF) та графова база даних |
| ArangoDB | 3.2.0 (Липень 2017) | вільна, Apache 2 | C++, JavaScript | Найпопулярніша (станом на 2015) NoSQL база даних доступна під ліцензією із відкритим вихідним кодом, і яка забезпечує як зберігання документів, так і можливості потрійного магазину[8] |
| Blazegraph | 2.1 (Квітень 2016) | комерційна, або GPLv2 для оцінки | Java | RDF-графова база даних, здатна до кластерізованого розгортання та графічного процесора (GPU), у комерційній версії; підтримує режим високої доступності (HA), вбудований режим, режим одного сервера. Підтримує креслення та SPARQL.[9][10] |
| Cayley | 0.6.1 (Квітень 2017) | вільна, Apache 2 | Go | Графова база даних[11] |
| Dgraph | 0.9.4 (Грудень 3, 2017) | вільна, AGPLv3 для сервера, Apache 2 для клієнта | Go | Графова база даних з відкритим вихідним кодом, масштабована, розподілена, високо доступна та швидка, розроблена з нуля, для запуску в веб-масштабах.[12][13] |
| DataStax Enterprise Graph | v5.0.2 (Серпень 2016) | власницька | Java | Розподілена в режимі реального часу масштабована база даних, натхненна Титаном; підтримує Tinkerpop і інтегрується з Cassandra[14] |
| Sparksee[15] | 5.2.0 (2015) | власницька, комерційна, безплатна для оцінки, дослідження, розробки | C++ | Високопродуктивна масштабована система управління базами даних від Sparsity Technologies; Основною рисою є продуктивність запиту для вилучення та дослідження великих мереж; має прив'язки для Java, C++, C#, Python, та Objective-C; |
| GraphBase[16] | 1.0.03b | власницька, комерційна | Java | Кастомізіруеме, розподілене графове сховище малого розміру з багатим набором інструментів із FactNexus. |
| gStore[17] | 0.4.1 (Березень 2017) | BSD-3 | C++ | Двигун для керування великими графово структурованими даними; open-source для операційних систем Linux; повністю написаний на C ++, з деякими бібліотеками, такими як readline, antlr тощо; режими використання: рідний, сервер-клієнт або розподілений.[18] |
| InfiniteGraph | 3.0 (Січень 2013) | власницька, комерційна | Java | Розповсюджений, має хмарну підтримку |
| JanusGraph | 0.6.1 (Січнь 2022) | вільна, Apache 2 | Java | Масштабована, розподілена графова база даних під Linux Foundation; Може працювати на різних базах данних (Apache Cassandra, Apache HBase, Google Cloud Bigtable, Oracle BerkeleyDB); підтримує глобальну графову аналітику даних, звітування, та ETL за рахунок інтеграції з платформами великих даних (Apache Spark, Apache Giraph, Apache Hadoop); підтримує географічний, числовий діапазон та повнотекстовий пошук за допомогою зовнішніх сховищ індексів (Elasticsearch, Apache Solr, Apache Lucene).[19] Була вилучена з Titan у кінці 2016 року. [20] |
| MarkLogic | 8.0.4 (2015) | власницька, безплатна версія розробника | Java | База даних NoSQL, яка зберігає документи (JSON і XML) та дані семантичного графу RDF втричі); також має вбудовану пошукову систему та повний перелік функцій підприємства, таких як ACID транзакції, висока доступність і аварійне відновлення, сертифікована безпека, масштабовність та еластичність |
| Neo4j | 3.1.1 (Січень 2017)[21] | GPLv3 Community Edition, комерційна & AGPLv3 варіанти для підприємства та розширені видання | Java, .NET, JavaScript, Python, Ruby | Висока масштабованість з відкритим вихідним кодом, підтримує ACID, має кластери високої доступності для розгортання підприємств, а також оснащений веб-інструментом адміністрування, який включає в себе повну підтримку транзакцій та візуальний графічний дослідницький вузол; доступний з більшості мов програмування за допомогою вбудованого інтерфейсу REST web API та власного протоколу Bolt з офіційними драйверами; найпопулярніша графова база даних у використанні станом на січня 2017[22] |
| OpenLink Software Virtuoso | 8.0 (Вересень 2017) | Open Source Edition - GPLv2, Enterprise Edition - власницька | C, C++ | Гібридний сервер баз даних, що обробляє RDF та інші дані графу, дані RDB-SQL, дані XML, файлові системи документів-об'єктів, а також вільний текст; може бути розгорнута як місцевий вбудований примірник (як це використовується в NEPOMUK семантичний робочий стіл), як одноразовий мережевий сервер або мережевий сервер з декількома екземплярами, що не використовують жодного еластичного кластера[23] |
| Oracle Spatial and Graph; part of Oracle Database | 12.1.0.2 (2014) | власницька | Java, PL/SQL | 1) RDF Semantic Graph: комплексне керування графом RDF W3C в базі даних Oracle з власними міркуваннями та тривимірною захищеною міткою. 2) Граф властивостей моделі даних мережі: для фізичних / логічних мереж з постійним сховищем та Java API для аналізу графів в пам'яті. |
| OrientDB | 2.2.24 (Липень 2017) | Community Edition - Apache 2, Enterprise Edition - комерційна | Java | Друге покоління розподіленої графової бази даних з гнучкістю документів в одному продукті (тобто, вона одночасно як графова база даних, так і база даних NoSQL); вона має комерційну дружню (Apache 2) ліцензію з відкритим вихідним кодом; є масштабованою з повною підтримкою ACID; має багатокористувацьку реплікацію та осідання; підтримує режим без схем, повний та змішаний режими; має потужну систему профілювання безпеки, засновану на користуванні та ролях; підтримує мову запитів. Вона має HTTP REST + JSON API. |
| SAP HANA | SPS12 Revision 120 | власницька | C, C++, Java, JavaScript & SQL-like language | ACID транзакція в оперативній пам'яті, підтримує граф властивостей[24] |
| Sqrrl Enterprise | 2.0 (Лютий 2015) | власницька | Java | Розповсюджена, «real-time» графова база даних що забезпечує безпеку на рівні клітин та масову масштабованість[25] |
| Teradata Aster | 7 (2016) | власницька | Java, SQL, Python, C++, R | База даних високої продуктивності, багатоцільової, масштабованої та розширюваної MPP, що включає в себе запатентовані движки, що підтримують збереження та маніпулювання даними SQL, MapReduce та Graph; надає широкий набір аналітичних бібліотек функцій та можливостей візуалізації даних[26] |
| TigerGraph[27] | 1.0 (2017) | власницька | C++ | Висока продуктивна паралельно-графова база даних, що підтримує GSQL, RESTful API та візуалізацію GraphStudio SDK. |
| Microsoft SQL Server 2017[28] | RC1 | власницька | SQL/T-SQL, R, Python | Надає можливості графової бази даних, щоб змоделювати «many-to-many» відносини. Графові відносини інтегровані в Transact-SQL і отримують переваги використання SQL Server як основної системи управління базами даних. |
API та графові мови-запитів
- AQL (ArangoDB Query Language) — SQL-подібна мова, яка використовується у ArangoDB для документів і для графів
- Cypher Query Language (Cypher) — графова мова декларативного програмування для Neo4j, яка дає спеціальний і програмний (SQL-подібний) доступ до графу.[29]
- GraphQL — мова запитів Facebook для служб бекенда
- Gremlin — графова мова програмування, яка працює над різними системами графових баз даних; частина Apache TinkerPop проекта з відкритим кодом[30]
- GSQL — TigerGraph декларативна мова для аналітики графів.[31]
- SPARQL — мова запитів для баз даних, може отримувати та обробляти дані, що зберігаються у форматі RDF
- V1 — візуальна мова запитів для графів властивостей[32][33]
Див. також
- Structured storage
- Об'єктно-орієнтована база даних
- Перетворення графів
- RDF Database
Примітки
- Angles, Renzo; Gutierrez, Claudio (1 лютого 2008). Survey of graph database models. ACM Computing Surveys (Association for Computing Machinery) 40 (1). doi:10.1145/1322432.1322433. Архів оригіналу за 15 серпня 2017. Процитовано 28 травня 2016. «network models [...] lack a good abstraction level: it is difficult to separate the db-model from the actual implementation»
- Silberschatz, Avi (28 січня 2010). Database System Concepts, Sixth Edition. McGraw-Hill. с. D-29. ISBN 0-07-352332-1.
- From Relational to Graph Databases. Neo4j.
- Silberschatz, Avi (28 січня 2010). Database System Concepts, Sixth Edition. McGraw-Hill. с. E-20. ISBN 0-07-352332-1.
- Parker, Lorraine. IMS Notes. vcu.edu. Процитовано 31 травня 2016.
- Kuper, Gabriel M (1985). The Logical Data Model: A New Approach to Database Logic (Ph.D.). STAN-CS-85-1069. Процитовано 31 травня 2016.
- SAP Announces New Capabilities in the Cloud with HANA (амер.). 22 жовтня 2014. Процитовано 7 липня 2016.
- Fowler, Adam (24 лютого 2015). NoSQL for Dummies. John Wiley & Sons. с. 298–. ISBN 978-1-118-90574-6.
- Vaughan, Jack (25 січня 2016). Beyond gaming, GPU technology takes on graphs, machine learning. TechTarget. Процитовано 9 травня 2017.
- Yegulalp, Serdar (26 вересня 2016). Faster with GPUs: 5 turbocharged databases. InfoWorld. Процитовано 9 травня 2017.
- Google Releases Cayley Open-Source Graph Database. eWeek. 13 листопада 2014. Процитовано 9 травня 2017.
- Ex-Googler startup DGraph Labs raises US$1.1 million in seed funding round to build industry’s first open source, native and distributed graph database. Globenewswire. 17 травня 2016. Процитовано 31 липня 2017.
- Bailey, Michael (18 травня 2016). Cannon-Brookes, Blackbird, Bain back new migrant's graph start-up. afr.com. The Australian Financial Review. Процитовано 31 липня 2017.
- Woodie, Alex (21 червня 2016). Beyond Titan: The Evolution of DataStax’s New Graph Database. Datanami. Процитовано 9 травня 2017.
- Sparksee high-performance graph database. Sparsity-technologies. Процитовано 9 травня 2017.
- Longbottom, Clive (1 травня 2016). Graph databases: What are the benefits for CIOs?. Computer Weekly. Процитовано 9 травня 2017.
- gStore Graph Database Engine. Архів оригіналу за 31 серпня 2017. Процитовано 27 грудня 2017.
- Zou, Lei; Özsu, M. Tamer; Chen, Lei; Shen, Xuchuan; Huang, Ruizhe; Zhao, Dongyan (August 2014). gStore: a graph-based SPARQL query engine.
- JanusGraph introduction. Процитовано 8 вересня 2021.
- Woodie, Alex (13 січня 2017). JanusGraph Picks Up Where TitanDB Left Off. Datanami. Процитовано 9 травня 2017.
- Release Notes: Neo4j 3.1.1. Neo4j. Процитовано 9 травня 2017.
- Ranking of Graph DBMS. DB-Engines. Процитовано 9 травня 2017.
- Clustering Deployment Architecture Diagrams for Virtuoso. Virtuoso Open-Source Wiki. OpenLink Softwar]. Процитовано 9 травня 2017.
- Rudolf, Michael; Paradies, Marcus; Bornhövd, Christof; Lehner, Wolfgang. The Graph Story of the SAP HANA Database (PDF) Lecture Notes in Informatics.
- Vanian, Jonathan (18 лютого 2015). NSA-linked Sqrrl eyes cyber security and lands $7M in funding. Gigaom. Процитовано 9 травня 2017.
- Woodie, Alex (23 жовтня 2015). The Art of Analytics, Or What the Green-Haired People Can Teach Us. Datanami. Процитовано 9 травня 2017.
- Introducing TigerGraph, a Native Parallel Graph Database (амер.). 19 вересня 2017. Процитовано 19 вересня 2017.
- What's New in SQL Server 2017. Microsoft Docs. 19 квітня 2017. Процитовано 9 травня 2017.
- Svensson, Johan (5 липня 2016). Guest View: Relational vs. graph databases: Which to use and when?. sdtimes.com. BZ Media. Процитовано 30 серпня 2016.
- TinkerPop, Apache. Apache TinkerPop. tinkerpop.apache.org. Процитовано 2 листопада 2016.
- GSQL. doc.tigergraph.com/dev/. Процитовано 1 жовтня 2017.
- Kogan, Lior (2017). «V1: A Visual Query Language for Property Graphs». arXiv:1710.04470.
- V1: A Visual Query Language for Property Graphs. github.com. Процитовано 1 листопада 2017.