ETL
Extract, Transform, Load (ETL) або Витяг, Перетворення та Завантаження — процес, який використовується в базах даних та, особливо, у сховищах даних та у засобах Business Intelligence для забезпечення їх роботи для підтримки прийняття рішень. ETL-процес, як концепція, набув поширення у 1970-х роках[2][3]. Він охоплює наступні етапи обробки даних:
- Виймання даних із зовнішніх джерел,
- Перетворення даних, для зберігання даних у відповідній структурі або форматі, з метою подальшого аналізу.
- Завантаження даних у кінцеву базу даних. Більш точно, це може бути вітрина даних або сховище даних.
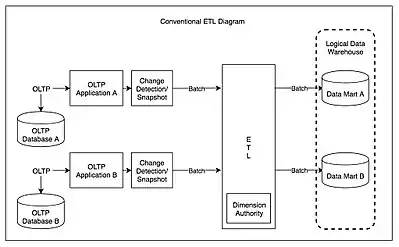
Поняття ETL може стосуватися процесу завантаження будь-якої бази даних. Оскільки виймання даних займає багато часу, то для скорочення загального часу обробки, поширеним є одночасна робота всіх трьох етапів ETL. Поки дані виймаються, процес перетворення отримує інші дані і готує їх для завантаження, щоб уникнути очікування виконання попередніх етапів.
Зазвичай ETL системи об'єднують дані з численних застосунків (систем), які створені та підтримуються різними вендорами та розміщені на різному апаратному забезпеченні. Розрізнені системи, які містять первісні дані, нерідко підтримуються та використовуються різними співробітниками. Для прикладу, система обліку витрат може об'єднувати дані по фонду заробітної платні, продажам та придбанням.
Виймання
Перша частина процесу ETL передбачає виймання даних з джерельних (або вихідних) систем. У багатьох випадках це є найважливішим аспектом ETL, оскільки правильне виймання даних необхідне для успішного функціонування наступних процесів. Більшість сховищ даних об'єднують дані з різних джерельних систем. Кожна окрема система може також використовувати іншу організацію даних та/або формат файлів. Загальні джерела даних форматів включають реляційні бази даних, XML, JSON і плоскі бази даних, але можуть також включати структури не реляційної бази даних, такі, як Information Management System або інші структури даних, такі, як метод доступу до віртуального сховища (VSAM) або індексований послідовний метод доступу (ISAM), або навіть формати, отримані з зовнішніх джерел за допомогою таких засобів, як пошуковий робот або витягування даних. Потокове відтворення вихідного джерела даних та завантаження на льоту в цільову базу даних є ще одним способом здійснення ETL, коли не вимагається проміжного зберігання даних. Загалом, фаза виймання спрямована на перетворення даних в єдиний формат, який потрібен на наступному кроці перетворення інформації.
Внутрішня частина виймання передбачає перевірку даних, щоб підтвердити, чи дані, отримані з джерел, мають правильні/очікувані значення в певному домені (наприклад, шаблонні/за умовчанням дані або список значень). Якщо дані не відповідають правилам перевірки, вони повністю або частково відхиляються. Відкинуті дані в ідеальному варіанті відправляються назад у джерельну систему для подальшого аналізу для виявлення та виправлення невірних записів. У деяких випадках сам процес виймання може мати правило перевірки даних, щоб прийняти дані та перейти на наступний етап.
Перетворення
На етапі перетворення даних застосовується серія правил або функцій до здобутих даних для підготовки цих даних до досягнення кінцевої цілі. Деякі дані взагалі не потребують перетворення; такі дані як «пряме переміщення» або «проходження крізь» дані.
Важливою функцією перетворення є очищення даних, яке має на меті передавати лише «правильні» дані. Виклик при взаємодії різних систем полягає у взаємодії відповідних систем. Набори символів, які можуть бути доступними в одній системі, можуть бути недоступними у інших системах.
В інших випадках, для задоволення бізнес та технічних потреб сервера або сховища даних може знадобитися одне або декілька наступних типів перетворень:
- Вибір лише певних стовпців для завантаження: (або вибір null (недійсних) стовпчиків для завантаження). Наприклад, якщо вихідні дані мають три стовпці (наприклад, «attributes»), roll_no, вік та зарплата, то вибір може мати лише roll_no та зарплату. Або механізм вибору може ігнорувати всі ті записи, де немає зарплати (salary = null).
- Переклад закодованих значень: (наприклад, якщо вихідна система кодів чоловіків помічається як «1» та жінок — як «2», але warehouse коди чоловіків як «Ч» і жінок як «Ж»)
- Значення вільної форми кодування: (наприклад, відображення «Чоловік» для «Ч»)
- Виведення нової розрахункової вартості: (наприклад, sale_amount = qty * unit_price)
- Сортування даних на основі списку стовпців для покращення ефективності пошуку
- Об'єднання даних із кількох джерел (наприклад, пошуку, злиття) та викладення даних
- Агрегація (наприклад, rollup — узагальнення кількох рядків даних — загальний обсяг продажів для кожного магазину, і для кожного регіону тощо)
- Створення значень сурогатних ключів
- Транспонування або поворот (перетворення кількох стовпців на кілька рядків або навпаки)
- Розбиття стовпця на кілька стовпців (наприклад, перетворення CSV списку розділеного комами, вказаного як рядок в одному стовпчику, в окремі значення в різних стовпцях).
- Розбиття повторюваних стовпців
- Пошук та перевірка відповідних даних з таблиць або реферованих файлів
- Застосування будь-якої форми перевірки даних; невдала перевірка може призвести до повного відхилення даних, часткового відхилення або відсутності відмови взагалі, і таким чином ніякі, деякі або всі дані не передаються на наступний крок залежно від розробки правил та обробки винятків; багато з перерахованих вище перетворень можуть призвести до винятків, наприклад, коли кодовий переклад аналізує невідомий код у розширеному вигляді
Завантаження
Фаза завантаження завантажує дані в кінцеву ціль, яка може бути простим обмеженим плоским файлом або сховищем даних. Залежно від потреб організації, цей процес дуже різниться. Деякі сховища даних можуть перезаписувати існуючу інформацію з сукупною інформацією; оновлення витягнутих даних часто проводиться щоденно, щотижнево або щомісячно. Інші сховища даних (або навіть інші частини одного і того ж сховища даних) можуть додавати нові дані в історичну форму через регулярні інтервали, наприклад, щогодини. Щоб зрозуміти це, розгляньте сховище даних, необхідне для ведення обліку продажів минулого року. Це сховище даних перезаписує будь-які дані старше року новими даними. Проте введення даних для будь-якого вікна на один рік здійснюється історично. Час і обсяг заміни чи додавання — це вибір стратегічного дизайну залежно від наявного часу та потреб бізнесу. Більш складні системи можуть підтримувати історію та аудит усіх змін у даних, завантажених у сховище даних.
Оскільки фаза завантаження взаємодіє з базою даних, застосовуються обмеження, визначені в схемі бази даних, також як тригери активовані під час завантаження даних (наприклад, унікальність, посилальна цілісність, обов'язкові поля), що також сприяють загальній якості даних процесу ETL.
- Наприклад, фінансова установа може мати інформацію про клієнта в декількох відділах, і кожен відділ може мати інформацію про цього клієнта різним чином. Відділ членства може вказати клієнта за ім'ям, тоді як бухгалтерія може вказати клієнта за номером. ETL може поєднувати всі ці елементи даних та об'єднувати їх у єдину презентацію, наприклад, для зберігання в базі даних або сховищі даних.
- Інший спосіб, коли компанія використовує ETL, — це постійне переміщення інформації до іншої програми. Наприклад, нова програма може використовувати інший постачальник бази даних і, найімовірніше, зовсім іншу схему бази даних. ETL може бути використаний для перетворення даних у формат, придатний для використання новою програмою.
- Прикладом може бути система відшкодування витрат (ECRS), яка використовується бухгалтерським обліком, консультантами та юридичними фірмами. Дані, як правило, потрапляють у систему часу та білінгу, хоча деякі підприємства також можуть використовувати вихідні дані для звітів про продуктивність працівників для управління людськими ресурсами (відділом персоналу) або звітів про використання обладнання.
Реальний цикл ETL
Типовий цикл реального життя ETL складається з наступних кроків виконання:
- Початок циклу
- Створення довідкових даних
- Витяг (з джерел)
- Перевірка
- Трансформування (очищення даних, застосування бізнес-правил, перевірка цілісності інформації, створення агрегатів або дезагрегації)
- Стадія (завантаження в таблиці постановок, якщо використовуються)
- Аудиторські звіти (наприклад, про дотримання ділових правил, а також у випадку несправності, допомагає діагностувати / відновлювати)
- Опублікування (для цільових таблиць)
- Архівування
Виклики
Процеси ETL можуть задіяти значну складність, і можуть виникнути серйозні проблеми завдяки системам ETL, що було розроблено неналежним чином.
Діапазон значень даних або якість даних в операційній системі може перевищувати очікування дизайнерів у процесі перевірки правильності та виконанні правил перетворення. Профілювання даних джерелом під час аналізу даних може визначати умови даних, які повинні управляти специфікаціями правил перетворення, що призводить до внесення поправок до правил валідації, явно та неявно впроваджених у процесі ETL.
Сховища даних зазвичай збираються з різних джерел даних з різними форматами та цілями. Таким чином, ETL є ключовим процесом для об'єднання всіх даних у стандартному, однорідному середовищі.
Аналіз дизайну повинен визначати масштабованість системи ETL протягом усього терміну її використання, включаючи розуміння обсягів даних, які повинні оброблятися в рамках угод про рівень послуг. Час, доступний для витягування із вихідних систем, може змінюватися, що може означати, що однакова кількість даних може бути оброблена за менший час. Деякі системи ETL повинні масштабувати настільки, щоб обробляти терабайти даних для оновлення сховищ даних з десятками терабайтів даних. Збільшуючи обсяги даних, може знадобитися конструкція, яка може масштабуватись від щоденної партії до багатоденної мікро-партії до інтеграції з черги повідомлень або захопленням змін даних у режимі реального часу для постійного перетворення та оновлення.
Продуктивність
Продуктивність ETL-постачальники порівнюють свої реєстрові системи з кількома ТБ (в терабайтах) на годину (або ~ 1 Гб в секунду) за допомогою потужних серверів з декількома процесорами, кількома жорсткими дисками, декількома гігабітними мережевими з'єднаннями та великою кількістю пам'яті.
У реальному житті найнижча частина процесу ETL зазвичай відбувається у фазі завантаження бази даних. Бази даних можуть виконуватися повільно, оскільки вони повинні дбати про паралелі, підтримці цілісності та індексах. Таким чином, для підвищення продуктивності, може бути сенс використовувати:
- Пряме виймання або метод розвантаження, коли це можливо (замість запитів до бази даних), щоб зменшити навантаження на вихідну систему при отриманні високошвидкісного виймання
- Більшість обробки перетворень поза межами бази даних
- Обмеження навантаження, коли це можливо
Тим не менше, навіть за допомогою масових операцій, доступ до бази даних зазвичай є вузьким місцем у процесі ETL. Деякі загальні методи, які використовуються для підвищення продуктивності, є:
- Таблиці розділів (та індекси): спробуйте зберегти подібні розміри розділів (дивіться нульові значення, які можуть перекосити розділи).
- Проведіть всю перевірку в шасі ETL перед завантаженням: вимкніть перевірку цілісності (вимкніть обмеження) у таблицях цільових баз під час завантаження
- Відключити тригери (вимкнути тригер) у таблицях цільових баз під час завантаження: імітувати їх ефект як окремий крок
- Створення ідентифікаторів на рівні ETL (не в базі даних)
- Видалити індекси (у таблиці або розділі) перед завантаженням — і відтворити їх після завантаження (SQL: drop index; create index)
- Використовуйте паралельний об'ємне навантаження, коли можливо — добре працює, коли таблиця розділена або немає індексів (Примітка: спроба здійснення паралельних навантажень в одну таблицю (розділ) зазвичай призводить до блокування — якщо не на рядках даних, то на показники)
- Якщо існує вимога виконувати вставки, оновлення або видалення, дізнайтеся, які рядки слід обробляти таким чином у ETL, а потім обробляти ці три операції в базі даних окремо; ви часто можете робити масове завантаження для вставок, але оновлення та видалення зазвичай проходять через API (за допомогою SQL)
Незалежно від того, виконувати певні операції в базі даних або за межами зовнішньої сторони, це може призвести до компромісу. Наприклад, видалення дублікатів з використанням різних може бути повільним у базі даних; таким чином, має сенс робити це за межами. З іншого боку, якщо використання значних значень (x100) зменшує кількість рядків, які слід видобути, то має сенс якнайшвидше видалити дублікацію в базі даних, перш ніж вивантажувати дані.
Спільним джерелом проблем в ETL є велика кількість залежностей між роботами ETL. Наприклад, робота «B» не може розпочатися, поки робота «A» не закінчена. Як правило, можна досягти кращої продуктивності, візуалізувати всі процеси на графіку та намагатися зменшити графік, що робить максимальне використання паралелізму, і зробити «ланцюжки» послідовної обробки якомога коротшими. Знову ж таки, розбиття великих таблиць та їх показників дійсно може допомогти.
Інша поширеною проблема виникає, коли дані поширюються між декількома базами даних, а обробка даних здійснюється в цих базах даних послідовно. Іноді реплікація бази даних може бути задіяна як метод копіювання даних між базами даних — це може значно уповільнити весь процес. Загальне рішення — зменшити графік обробки лише на три шари:
- Джерела
- Центральний ETL шар
- Цілі
Цей підхід дозволяє обробці максимально використовувати паралелізм. Наприклад, якщо вам потрібно завантажити дані в дві бази даних, ви можете запускати завантаження паралельно (замість завантаження вперше, а потім — вдруге).
Іноді обробка повинна відбуватися послідовно. Наприклад, необхідні вимірювальні (довідкові) дані, перш ніж можна отримати та перевірити рядки для основних таблиць фактів.
Паралельне обчислення
Останні розробки в програмному забезпеченні ETL — це реалізація паралельних обчислень. Вона дозволила здійснити ряд методів для покращення загальної ефективності ETL при роботі з великими обсягами даних.
Програми ETL реалізують три основні типи паралелізму:
- Дані: розбиваючи один послідовний файл на менші файли даних для забезпечення паралельного доступу
- Pipeline: дозволяє одночасно виконувати декілька компонентів в одному потоці даних, наприклад, шукаючи значення запису 1 одночасно з додаванням двох полів у запису 2
- Компонент: одночасне проходження кількохпроцесів на різні потоки даних у тій самій джобі, наприклад, сортування одного вхідного файлу при видаленні дублікатів в іншому файлі
Всі три типи паралелізму, зазвичай, працюють в єдиній джобі.
Додаткова складність полягає в перевірці того, щоб завантажувані дані були відносно послідовними. Оскільки бази даних з кількома джерелами можуть мати різні цикли оновлення (деякі можуть бути оновлені кожні кілька хвилин, тоді як інші можуть займати кілька днів або тижнів), система ETL, можливо, буде вимагати затримувати певні дані, доки всі джерела не стануть синхронізованими. Точно так само, коли ссховище даних, можливо, доведеться узгодити з вмістом у вихідній системі або з головним бухгалтерським обліком, стає необхідним створення точок синхронізації та узгодження.
Перезавантаження, відновлюваність
Процедури сховища даних зазвичай підрозділяють великий процес ETL на менші частини, що працюють послідовно або паралельно. Щоб стежити за потоками даних, має сенс позначати кожен рядок даних за допомогою «row_id» і тегувати кожну частину процесу за допомогою «run_id». У випадку невдачі, наявність цих ідентифікаторів допоможе відмовитися і перезапустити невдалу частину.
Найкраща практика також вимагає контрольних пунктів, які є станом, коли завершуються певні етапи процесу. Хороша ідея писати все на диск один раз на контрольний пункт, очищати деякі тимчасові файли, вводити стан тощо.
Віртуальний ETL
З 2010 року віртуалізація даних почала просувати обробку ETL. Застосування віртуалізації даних до ETL дозволило вирішити найбільш поширені завдання ETL з міграції даних та інтеграції додатків для декількох розподільних джерел даних. Віртуальний ETL працює з абстрактним представленням об'єктів або об'єктів, зібраних з різноманітних реляційних, напівструктурованих та неструктурованих джерел даних. Інструменти ETL можуть використовувати об'єктно-орієнтоване моделювання та працювати з представленнями підприємств, постійно зберігаються в центрально розташованій хаб-архітектурі. Така колекція, яка містить уявлення про об'єкти або об'єкти, зібрані з джерел даних для обробки ETL, називається сховищем метаданих, і він може перебувати в пам'яті[4] або бути стійким. Використовуючи постійне сховище метаданих, інструменти ETL можуть переходити від одноразових проектів до постійного проміжного програмного забезпечення, виконуючи гармонізацію даних та профілювання даних послідовно та в режимі реального часу
Робота з ключами
Унікальні ключі відіграють важливу роль у всіх реляційних базах даних, оскільки вони взаємоз'єднують все. Унікальний ключ — це стовпчик, який ідентифікує даний об'єкт, тоді як зовнішній ключ — це стовпчик в іншій таблиці, що відноситься до первинного ключа. Ключі можуть складатися з декількох стовпчиків, у цьому випадку вони є складовими ключами. У багатьох випадках первинний ключ — це автоматично створене ціле число, яке не має сенсу для представлення суб'єкта господарювання, але є єдиним для цілей реляційної бази даних, який зазвичай називають сурогатним ключем.
Оскільки, як правило, більше ніж одне джерело даних завантажується у сховище даних, ключовими є важливі питання, які необхідно вирішити. Наприклад: клієнти можуть бути представлені в декількох джерелах даних із зазначенням номера соціального забезпечення як основного ключа в одному джерелі, їх номером телефону в іншому і сурогату — у третьому. Однак для сховища даних може знадобитися консолідація всієї інформації клієнта в одному вимірі.
Рекомендований спосіб вирішення проблеми полягає у додаванні сурогатного ключа зі сховища даних, який використовується як зовнішній ключ із результуючої таблиці[5].
Як правило, оновлення відбуваються з вихідними даними, що, має відображатися в сховищі даних.
Якщо для звітування потрібен первинний ключ вихідних даних, розмірність вже містить цей фрагмент інформації для кожного рядка. Якщо вихідні дані використовують сурогатний ключ, сховище даних повинно стежити за ним, навіть якщо його не використовують у запитах чи звітах; це робиться шляхом створення таблиці пошуку, яка містить сурогатний ключ сховища даних та первиний ключ[6]. Таким чином, розмірність не забруднена сурогатами з різних вихідних систем, а можливість оновлення зберігається.
Таблиця пошуку використовується різними способами залежно від характеру вихідних даних. Існує 5 типів, на які слід враховувати[6]; три наступні:
- Тип 1
- Рядок розмірів просто оновлюється, щоб відповідати поточному стану вихідної системи; сховище даних не фіксує історію; таблиця пошуку використовується для ідентифікації рядка розмірів для оновлення або перезапису
- Тип 2
- Новий рядок розмірів додано з новим станом вихідної системи; призначений новий сурогатний ключ; вихідний ключ більше не є унікальним у таблиці пошуку
- Повністю зареєстрований
- Новий рядок вимірювання додається з новим станом вихідної системи, тоді як рядок попереднього вимірювання оновлюється, щоб відобразити, що він більше не активний та час деактивації.
Інструменти
Використовуючи встановлену ETL-схему, можна збільшити шанси досягнення кращого підключення та масштабованості. Хороший інструмент ETL повинен мати можливість спілкуватися з багатьма різнимиреляційними базами даних і прочитати різні формати файлів, які використовуються в організації. Інструменти ETL почали мігрувати в Інтеграцію корпоративних програм або навіть в Інтеграційну шину даних, які зараз охоплюють значно більше, ніж просто виймання, перетворення та завантаження даних. Багато постачальників ETL тепер мають профілі даних, якість даних та можливості метаданих. Звичайне використання для інструментів ETL включає перетворення файлів CSV у формат, який можна зчитувати реляційними базами даних. Типовий переклад мільйонів записів полегшує ETL інструменти, які дозволяють користувачам вводити канали / файли даних csv і імпортувати їх у базу даних з якнайменш можливою кількістю коду.[джерело?]
Інструменти ETL, як правило, використовуються широким колом професіоналів — від студентів, що вивчають інформатику, які бажають швидко імпортувати великі обсяги даних до архітекторів баз даних, відповідальних за управління обліковими записами компанії, ETL інструменти стали зручним інструментом, на який можна покластися, щоб отримати максимальну ефективність. Інструменти ETL в більшості випадків містять графічний інтерфейс, який допомагає користувачам зручно перетворювати дані, використовуючи маппер візуальних даних, на відміну від написання великих програм для аналізу файлів та модифікації типів даних.
Хоча інструменти ETL традиційно були для розробників та І. Т. персоналу, нова тенденція полягає в тому, щоб забезпечити ці можливості діловим користувачам, щоб вони могли самостійно створювати зв'язки та інтеграцію даних, коли це потрібно, а не йти до І. Т. персоналу[7]. Гартнер називає цих нетехнічних користувачів громадянськими інтеграторами[8].
Див. також
Примітки
- Ralph., Kimball, (2004). The data warehouse ETL toolkit : practical techniques for extracting, cleaning, conforming, and delivering data. Caserta, Joe, 1965-. Indianapolis, IN: Wiley. ISBN 0764579231. OCLC 57301227.
- ETL What it is and why it matters
- Gallas, Susan. Kimball vs. Inmon, September 1999, dmDirect [Електронний ресурс] — 12.09.2007 -Режим доступу: http://www.dmreview.com/editorial/dmdirect/ dmdirect_article.cfm?EdID=1400&issue.
- Virtual ETL
- Kimball, The Data Warehouse Lifecycle Toolkit, p 332
- Golfarelli/Rizzi, Data Warehouse Design, p 291
- The Inexorable Rise of Self Service Data Integration. Процитовано 31 січня 2016.
- Embrace the Citizen Integrator.
