Колаборативна фільтрація
Колаборативна фільтрація, спільна фільтрація (англ. collaborative filtering) (КФ) — метод, який використовується деякими рекомендаційними системами. Колаборативна фільтрація має два значення: вузьке і більш загальне. В цілому, колаборативна фільтрація — процес фільтрації інформації або зразків за допомогою методів за участю співробітництва між декількома агентами, точками зору, джерелами даних і т. д. Застосування колаборативної фільтрації, як правило, пов'язане з дуже великими наборами даних. Колаборативні методи фільтрації були застосовані до різних видів даних, зокрема до таких як зондування та моніторинг даних, які виникають при розвідці корисних копалин на великих площах; до фінансових даних, таких як установи фінансових послуг, які об'єднують багато фінансових джерел; або в електронній торгівлі та веб-додатках, що зосереджуються на даних користувача, і т. д. Решта цієї дискусії зосереджена на колаборативній фільтрації даних, призначених для користувача, хоча деякі з методів та підходів можуть застосовуватися так само і у багатьох інших випадках.

У більш новому, вужчому значенні колаборативна фільтрація — це один з методів побудови прогнозу в рекомендаційних системах, який використовує відомі уподобання (оцінки) групи користувачів для прогнозування невідомих уподобань іншого користувача.[1] Основне припущення колаборативної фільтрації полягає в наступному: ті, хто однаково оцінювали будь-які предмети в минулому, схильні давати схожі оцінки інших предметів і в майбутньому. [1] Наприклад, за допомогою колаборативної фільтрації музичний додаток здатний прогнозувати, яка музика сподобається користувачеві, маючи неповний список його уподобань (симпатій та антипатій).[2] Прогнози складаються індивідуально для кожного користувача, хоча інформація, що використовується, зібрана від багатьох учасників. Це відрізняє колаборативну фільтрацію від більш простого підходу, дає усереднену оцінку для кожного об'єкта інтересу, наприклад того, що базується на кількості поданих за нього голосів. Дослідження в даній області активно ведуться і в наш час, що зокрема обумовлюється наявністю невирішених проблем у методі колаборатівної фільтрації.
Опис
У століття інформаційного вибуху такі методи створення персоналізованих рекомендацій, як колаборативна фільтрація, дуже корисні, оскільки кількість об'єктів навіть в одній категорії (такій, як фільми, музика, книги, новини, вебсайти) стала настільки великою, що окрема людина не здатна переглянути їх всі, щоб вибрати відповідні.
Системи колаборативної фільтрації зазвичай застосовують двоступеневу схему [1]:
- Знаходять тих, хто поділяє оціночні судження «активного» (прогнозованого) користувача.
- Використовують оцінки людей,що мислять подібно, знайдених на першому кроці, для обчислення прогнозу.
Алгоритм, описаний вище, побудований відносно користувачів системи.
Існує і альтернативний алгоритм, винайдений Amazon [3], побудований відносно предметів (продуктів) у системі. Цей алгоритм включає в собі наступні кроки:
- Будуємо матрицю, яка визначає відносини між парами предметів, для знаходження подібних предметів.
- Використовуючи побудовану матрицю і інформацію про користувача, будуємо прогнози його оцінок.
Для прикладу можна подивитися сімейство алгоритмів Slope One
Також існує інша форма колаборативної фільтрації, що ґрунтується на прихованому спостереженні звичайної поведінки користувача (на протилежність явній, яка збирає оцінки). У цих системах ви спостерігаєте, як вчинив даний користувач, і як вчинили інші (яку музику вони слухали, які відео подивилися, які композиції придбали), і використовуєте отримані дані, щоб передбачити поведінку користувача в майбутньому, або передбачити, як користувач бажав би вчинити за наявності певної можливості. Ці передбачення повинні бути складені згідно з бізнес-логікою, бо марно пропонувати споживачеві придбати музичний файл, який у нього вже є.
Типи колаборативної фільтрації
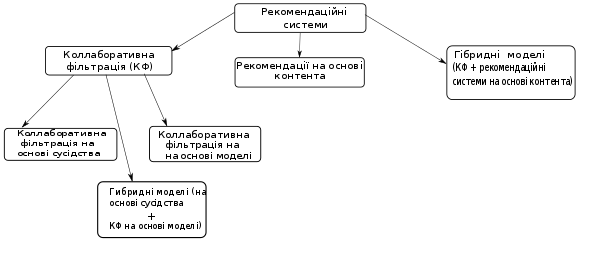
Заснований на пам'яті
Цей підхід використовує дані про рейтинг користувача для розрахунку схожості між користувачами або предметами. Він використовується для вироблення рекомендацій. Це був початковий підхід, що використовувався в багатьох торгових системах. Він ефективний і простий у реалізації. Типовими прикладами такого підходу є CF і засновані на виробі/користувачеві топ-N рекомендації. Наприклад, у підходах, заснованих на користувачеві, вартість оцінки, яку користувач u дає виробу «i» розрахована як сукупність схожих оцінок виробу іншими користувачами:

де «U» позначає сукупність N «найкращих» користувачів, які найбільш близькі до користувача u, що оцінює виріб «i». Деякі приклади функцій агрегації:



де k - нормуючий множник, визначається як і є середня оцінка користувача u для всіх виробів, оцінених ним.


Заснований на сусідстві
Алгоритм, заснований на сусідстві, обчислює подібність двох користувачів або виробів, виробляє прогноз для користувача, приймаючи середнє зважене всіх оцінок. Обчислення схожості між виробами або користувачами є важливою частиною цього підходу. Багаторазові заходи, такі як кореляції Пірсона і схожість, заснована на скалярному добутку, використовується для цього.
Схожість двох користувачів X, Y через кореляцію Пірсона визначається як

де Ixy - це набір елементів, оцінених як користувачем х, так і користувачем у .
Підхід, заснований на скалярному добутку визначає скалярний добуток між двома користувачами х і у, як:

Заснований на користувачеві алгоритм топ-Н рекомендації використовує засновану на подібності векторну модель для визначення K — більшості подібних користувачів до активного користувача. Після того, як знайдені найбільш схожі користувачі, їх відповідні матриці агрегуються для визначення рекомендованого набору елементів. Популярний метод, знаходження схожих користувачів — Locality-sensitive hashing, який реалізує механізм пошуку найближчих сусідів у лінійному часі.
Переваги цього підходу включають в себе: очікуваність результатів, що є важливим аспектом рекомендаційних систем; просте створення і використання; просте полегшення нових даних; добра масштабованість зі співавторами рейтингових пунктів.
Є також кілька недоліків при такому підході. Його продуктивність знижується, коли дані становляться розрідженими, що трапляється часто з виробами, пов'язаними з мережею. Це ускладнює масштабованість такого підходу і створює проблеми з великими наборами даних. Хоча він може ефективно обробляти нових користувачів, тому що спирається на структури даних, додавання нових елементів стає більш складним, що, як правило, спирається уявленням про конкретну складову векторного простору. Додавання нових елементів вимагає включення нового пункту і повторного включення всіх елементів у структурі.
Заснований на моделі
Даний підхід надає рекомендації, вимірюючи параметри статистичних моделей для оцінок користувачів, побудованих за допомогою таких методів як, метод баєсовских мереж, кластеризації, латентно-семантичної моделі , такі як сингулярний розклад, імовірнісний латентно-семантичний аналіз, прихований розподіл Дирихле і марковський процес вирішування на основі моделей. [4] Моделі розробляються з використанням інтелектуального аналізу даних, алгоритмів машинного навчання, щоб знайти закономірності на основі навчальних даних. Число параметрів в моделі може бути зменшено в залежності від типу за допомогою методу головних компонент.
Цей підхід є більш комплексним і дає більш точні прогнози, оскільки допомагає розкрити латентні фактори, що пояснюють спостережувані оцінки. [5]
Даний підхід має ряд переваг. Він обробляє розріджені матриці краще, ніж підхід заснований на сусідстві, що в свою чергу допомагає з масштабністю великих наборів даних.
Недоліки цього підходу полягають в «дорогому» створенні моделі [6]. Необхідний компроміс між точністю і розміром моделі, тому що можна втратити корисну інформацію у зв'язку із скороченням моделей.
Гібридний підхід
Даний підхід об'єднує в собі підхід заснований на сусідстві і заснований на моделі. Гібридний підхід є найпоширенішим при розробці рекомендаційних систем для комерційних сайтів, так як він допомагає подолати обмеження початкового оригінального підходу (заснованого на сусідстві) і поліпшити якість прогнозів. Цей підхід також дозволяє подолати проблему розрідженості даних [⇨] і втрати інформації. Однак даний підхід складний і дорогий у реалізації та застосуванні. [7]
Проблеми
Розрідженість даних
Як правило, більшість комерційних рекомендаційних систем заснована на великій кількості даних (товарів), в той час як більшість користувачів не ставить оцінки товарам. В результаті цього матриця «предмет-користувач» виходить дуже великою і розрідженою, що представляє проблеми при обчисленні рекомендацій. Ця проблема особливо гостра для нових, щойно створених систем. [8] Також розрідженість даних підсилює проблему холодного старту.
Масштабованість
Зі збільшенням кількості користувачів в системі, з'являється проблема масштабованості. Наприклад, маючи 10 мільйонів покупців і мільйон предметів , алгоритм колаборативної фільтрації зі складністю рівній вже занадто складний для розрахунків. Також, багато систем повинні моментально реагувати на онлайн запити від всіх користувачів, незалежно від історії їх покупок і оцінок, що вимагає ще більшої масштабованості.



Проблема холодного старту
Нові предмети або користувачі представляють велику проблему для рекомендаційних систем. Частково проблему допомагає вирішити підхід, заснований на аналізі вмісту, так як він покладається не на оцінки, а на атрибути, що допомагає включати нові предмети в рекомендації для користувачів. Однак проблему з наданням рекомендації для нового користувача вирішити складніше. [8]
Синонімія
Синонімією називається тенденція схожих і однакових предметів мати різні імена. Більшість рекомендаційних систем не здатні виявити ці приховані зв'язки і тому відносяться до цих предметів як до різних. Наприклад, «фільми для дітей» та «дитячий фільм» відносяться до одного жанру, але система сприймає їх як різні. [4]
Шахрайство
У рекомендаційних системах, де кожен може ставити оцінки, люди можуть давати позитивні оцінки своїм предметам і погані своїм конкурентам. Також, рекомендаційні системи стали сильно впливати на продажі та прибуток, з тих пір як отримали широке застосування в комерційних сайтах. Це призводить до того, що недобросовісні постачальники намагаються шахрайським чином піднімати рейтинг своїх продуктів і знижувати рейтинг свої конкурентів. [8]
Різноманітність
Колаборативна фільтрація спочатку визнана збільшити різноманітність, щоб дозволяти відкривати користувачам нові продукти з незліченної множини. Однак деякі алгоритми, зокрема основні на продажах і рейтингах, створюють дуже складні умови для просування нових і маловідомих продуктів, так як їх заміщають популярні продукти, які давно перебувають на ринку. Це в свою чергу тільки збільшує ефект «багаті стають ще багатшими» і приводить до меншої різноманітності. [9]
Білі ворони
До «білих ворон» відносяться користувачі, чия думка постійно не збігається з більшістю інших. Через унікальність смаку їм неможливо щось рекомендувати. Однак, такі люди мають проблеми з отриманням рекомендацій і в реальному житті, тому пошуки вирішення даної проблеми в даний час не ведуться. [4]
Застосування в соціальних мережах
Колаборативна фільтрація широко використовується в комерційних сервісах і соціальних мережах. Перший сценарій використання — це створення рекомендації щодо цікавої і популярної інформації на основі врахування «голосів» спільноти. Такі сервіси, як Reddit, Digg або DiCASTA — це типові приклади систем, що використовують алгоритми колаборативної фільтрації.
Інша сфера використання полягає у створенні персоналізованих рекомендацій для користувача, на основі його попередньої активності і даних про переваги інших, схожих з ним користувачів. Даний спосіб реалізації можна знайти на таких сайтах, як YouTube, Last.fm і Amazon [3], а також в таких геосоціальних сервісах, як Gvidi і Foursquare.
Див. також
- Холодний запуск
- Колаборативний пошуковий рушій
- Колаборативна модель
- Репутаційна система
- Метод k найближчих сусідів
- Соціальний граф
- Колективний розум
Примітки
- A Survey of Collaborative Filtering Techniques, 2009, с. 1.
- An integrated approach to TV Recommendations by TV Genius. Архів оригіналу за 6 червня 2012. Процитовано 15 квітня 2015.
- Amazon, 2003, с. 1.
- A Survey of Collaborative Filtering Techniques, 2009, с. 3.
- Масштабована і точна колаборативна фільтрація, 2009.
- A Survey of Collaborative Filtering Techniques, 2009, с. 3-4.
- Проблеми в рекомендаційних системах, 2010, с. 6.
- Проблеми в рекомендаційних системах, 2010, с. 7.
- Проблема різноманітності, 2009, с. 23.
Література
- Fleder D., Hosanagar K. Blockbuster Culture's Next Rise or Fall: The Impact of Recommender Systems on Sales Diversity (журнал) // Management Science, Vol. 55, No. 5, May 2009, pp. 697-712. — 2009. — P. 1 - 49.
- Xiaoyuan Su and Taghi M. Khoshgoftaar. A Survey of Collaborative Filtering Techniques A Survey of Collaborative Filtering Techniques (журнал) // Hindawi Publishing Corporation, Advances in Artificial Intelligence archive, USA. — 2009. — P. 1 - 19.
- Yehuda Koren. Factor in the Neighbors: Scalable and Accurate Collaborative Filtering (журнал) // Yahoo! Research, Haifa. — 2009. — P. 1 - 11.
- Linden G., Smith B., and York J. Item-to-Item Collaborative Filtering (журнал) // IEEE Internet Computing, Los Alamitos, CA USA. — 2003. — P. 76 - 80.
- Sarwar B., Karypis G., Konstan J., and Riedl J. Item-Based Collaborative Filtering Recommendation Algorithms (Материалы конф. / WWW10, Hong Kong, May 1-5, 2001) // University of Minnesota, Minneapolis. — 2001. — P. 285 - 295.
- Melville P.,Mooney R., Nagarajan R. Content-Boosted Collaborative Filtering for Improved Recommendations // University of Texas, USA. — 2002. — P. 187-192.
- Zan Huang, Xin Li, Hsinchun Chen. Link Prediction Approach to Collaborative Filtering (Материалы конф. / JCDL’05, Denver, Colorado, USA, June 7–11, 2005) // University of Arizona, USA. — 2005.
- Понизовкин Д.М. Построение оптимального графа связей в системах коллаборативной фильтрации (журнал) // «Программные системы: теория и приложения». — 2011. — № 4(8). — С. 107-114. — ISSN 2079-3316.
- Sammut C., Webb J. (Eds.). Encyclopedia of Machine Learning. — NY, USA : IBM T. J.Watson Research Center, 2010. — Т. 1. — С. 829-838. — ISBN 978-0-387-30768-8.
