Intel P6
P6 — суперскалярна суперконвеєрна мікроархітектура процесорів, яка розроблена компанією Intel і лежить в основі мікропроцесорів Pentium Pro, Pentium II, Pentium III, Celeron і Xeon. На відміну від x86-сумісних процесорів попередніх поколінь з CISC-ядром, процесори архітектури P6 мають RISC-ядро, що виконує складні інструкції x86 не безпосередньо, а попередньо декодуючи їх в прості внутрішні мікрооперації.
|
| |
| Роки виробництва: | з 1 листопада 1995 по 2003 |
|---|---|
| Розробник: | Intel |
| Макс. частота CPU: | 150 МГц – 1,4 ГГц |
| Частота FSB: | 60 МГц – 133 МГц |
| Техпроцес: | 500 нм – 130 нм |
| Набір команд: | x86 |
| Мікроархітектура: | P6 |
| Ядра: | 1 |
| Кеш L1: | 16 — 32 КБ |
| Кеш L2: | 128 KБ — 2048 KБ |
| Попередник: | Pentium |
| Наступник: | NetBurst, Pentium M |
| Роз'єм(и): | |
| Розширення | |
Першим процесором архітектури P6 став анонсований 1 листопада 1995 процесор Pentium Pro, націлений на ринок робочих станцій і серверів. Процесори Pentium Pro випускалися паралельно з процесорами архітектури P5 (Pentium і Pentium MMX), призначеними для персональних комп'ютерів. 7 травня 1997 компанією Intel був анонсований процесор Pentium II, що прийшов на зміну процесорам архітектури P5.
У 2000 році на зміну архітектурі P6 на ринку настільних і серверних процесорів прийшла архітектура NetBurst, однак архітектура P6 отримала свій розвиток в мобільних процесорах Pentium M і Core. У 2006 році на зміну процесорам архітектури NetBurst прийшли процесори сімейства Core 2 Duo, архітектура яких також являє собою розвиток архітектури P6.
Функціональна схема
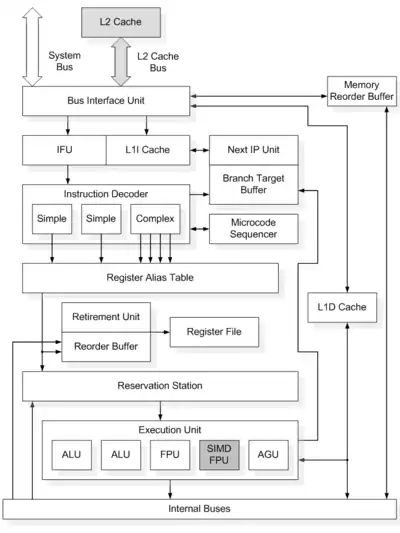
Процесори архітектури P6 складаються з чотирьох основних підсистем:
- Підсистема впорядкованої попередньої обробки (англ. In-Order Front End, IOFE) — відповідає за вибірку і декодування інструкцій в порядку, передбаченому програмою, і передбачує переходи.
- Ядро виконання зі зміною послідовності (англ. Out-of-Order Core, O2C) — відповідає за виконання мікрооперацій в оптимальному порядку і організовує взаємодію виконавчих пристроїв.
- Підсистема упорядкованого завершення (англ. In-Order Retirement, IOR) — видає результати виконання в порядку, передбаченому програмою.
- Підсистема пам'яті (англ. memory subsystem) — забезпечує взаємодію процесора з оперативною пам'яттю.
- Підсистема впорядкованої попередньої обробки
До пристроїв цієї підсистеми відносяться:
- Модуль і буфер передбачення переходів (Branch Target Buffer, BTB) — передбачають переходи і зберігають таблицю історії переходів. Для передбачення використовуються як динамічний, так і статичний методи. Останній використовується в тому випадку, якщо динамічне передбачення неможливе (у таблиці переходів відсутня необхідна інформація).
- Декодер інструкцій (Instruction Decoder) — перетворює CISC-інструкції x86 в послідовність RISC-мікрооперацій, виконуваних процесором. Включає два декодера простих інструкцій (Simple), що обробляють команди, які можуть бути виконані однією мікрооперацією, і декодер складних інструкцій (Complex), який обробляє команди, для яких потрібно кілька (до чотирьох) мікрооперацій.
- Планувальник послідовностей мікрооперацій (Microcode sequencer) — зберігає послідовності мікрооперацій, використовуваних при декодуванні складних інструкцій x86, що вимагають більше чотирьох мікрооперацій.
- Блок обчислення адреси наступної інструкції (Next IP Unit) — обчислює адресу інструкції (англ. instruction pointer, IP), яка повинна бути оброблена наступною, на підставі інформації про переривання і таблиці переходів.
- Блок вибірки інструкцій (Instruction Fetch Unit, IFU) — здійснює вибірку інструкцій з пам'яті за адресами, підготовленим блоком обчислення адреси наступної інструкції.
Процесори на ядрі Tualatin додатково містять блок передвибірки інструкцій (Prefetcher), який здійснює попередню вибірку інструкцій на підставі таблиці переходів.
- Ядро виконання зі зміною послідовності
Виконання зі зміною послідовності, при якому змінюється черговість виконання інструкцій, так, щоб це не призводило до зміни результату, дозволяє прискорити роботу за рахунок більш оптимального розподілу запитів до допоміжних блоків і мінімізації їх простоїв. До пристроїв організації виконання зі зміною послідовності відносяться:
- Таблиця призначення регістрів (Register Alias Table) — задає відповідність між регістрами архітектури x86/IA32 (Intel Architecture 32-bit) і внутрішніми регістрами, використовуваними при виконанні мікрооперацій.
- Буфер переупорядкування мікрооперацій (Reorder Buffer) — забезпечує виконання мікрооперацій в оптимальною з точки зору продуктивності послідовності.
- Станція-резервуар (Reservation Station) — містить інструкції, що відправляються на виконавчі пристрої.
До виконавчих пристроїв ядра відносяться:
- Арифметично-логічні пристрої, ALU (Arithmetic Logic Unit, ALU) — виконують цілочисельні операції.
- Блок арифметики з рухомою комою (Floating Point Unit, FPU) — виконує операції над числами з рухомою комою. Процесори Pentium III і вище мають також блок, який здійснює виконання інструкцій SSE (SIMD FPU).
- Блок генерації адрес (Address Generation Unit, AGU) — обчислює адреси даних, використовуваних інструкціями, і формує запити до кешу для завантаження/розвантаження цих даних.
- Підсистема упорядкованого завершення
- Регістровий файл (Register File) — зберігає результати операцій (стан регістрів IA32 для виконуваних інструкцій).
- Буфер переупорядкування пам'яті (Memory Reorder Buffer) — керує порядком запису даних в пам'ять для запобігання запису невірних даних через зміну порядку виконання інструкцій.
- Блок завершення (Retirement Unit) — видає результати виконання інструкцій в тій послідовності, в якій вони надійшли на виконання.
- Підсистема пам'яті
| Об'єм (Кб) | Процесори |
|---|---|
| 0 | Celeron Covington |
| 128 | Celeron (Mendocino, Coppermine-128), Pentium III (Coppermine для консолі Xbox[1]) |
| 256 | Pentium Pro, Pentium III (Coppermine, Tualatin-256), Xeon (Cascades) |
| 512 | Pentium Pro, Pentium II, Pentium III (Katmai, Tualatin), Xeon (Drake, Tanner) |
| 1024 | Pentium Pro, Xeon (Drake, Tanner) |
| 2048 | Xeon (Drake, Tanner, Cascades 2MB) |
Підсистема пам'яті здійснює взаємодію з оперативною пам'яттю. До цієї підсистеми відносяться:
- Кеш першого рівня для даних (Level 1 Data Cache, L1D) — пам'ять з малим часом доступу об'ємом 8 (для Pentium Pro) або 16 (для більш нових процесорів) кілобайт, призначена для зберігання даних.
- Кеш першого рівня для інструкцій (Level 1 Instruction Cache, L1I) — пам'ять з малим часом доступу об'ємом 8 (Pentium Pro) або 16 кілобайт, призначена для зберігання інструкцій.
- Кеш другого рівня (Level 2 Cache, L2). Пам'ять з малим часом доступу об'ємом 128, 256, 512, 1024 або 2048 кілобайт. Ширина шини L2 становить 64 або 256 (для процесорів на ядрі Coppermine і вище) біт. Процесори Celeron на ядрі Covington кешу другого рівня не мають.
- Блок шинного інтерфейсу (Bus Interface Unit) — керує системною шиною.
Виконання інструкції
Конвеєр складається з 12 стадій[2]:
- IOFE (1-4) — визначення адреси інструкції та її вибірка.
- IOFE (4-6) — декодування.
- IOFE7 — перейменування регістрів.
- IOFE8 — запис мікрооперацій в станцію-резервуар.
- O2C1 — передача мікрооперацій зі станції-резервуара до виконавчих блоків.
- O2C2 — виконання мікрооперацій (один або кілька тактів).
- IOR (1-2) — завершення інструкції: запис результатів в регістри.
Виконання інструкції починається з її вибірки і декодування. Для цього з кеш-пам'яті інструкцій першого рівня за адресою з буфера передбачення переходів вибирається 64 байти (два рядки). З них 16 байт, починаючи із адреси з блоку обчислення адреси наступної інструкції, вирівнюються і передаються в декодер інструкцій, що перетворює інструкції x86 в мікрооперації. Якщо інструкції відповідає одна мікрооперація, декодування проводить один з декодерів простих інструкцій. Якщо інструкції відповідає дві, три або чотири мікрооперації, декодування проводить декодер складних інструкцій. Якщо ж інструкції відповідає більше число мікрооперацій, то вони формуються планувальником послідовностей мікрооперацій.
Після декодування інструкцій виконується перейменування регістрів, а мікрооперації і дані поміщаються в буфер — станцію резервування, звідки відповідно до оптимального порядку виконання і за умови визначеності необхідних для їх виконання операндів направляються на виконавчі блоки (максимум 5 інструкцій за такт). Статус виконання мікрооперацій і його результати зберігаються в буфері переупорядкування мікрооперацій, а так як результати виконання одних мікрооперацій можуть слугувати операндами інших, вони також поміщаються і в станцію резервування.
За результатами виконання мікрооперацій визначається їх готовність до відставки (англ. retirement). У разі готовності відбувається їх відставка в порядку, передбаченому програмою, під час якої здійснюється оновлення стану логічних регістрів, а також відкладене збереження результатів в пам'яті (управління порядком запису даних здійснює буфер переупорядкування пам'яті)[3].
Особливості архітектури
Перші процесори архітектури P6 в момент виходу значно відрізнялися від існуючих процесорів. Процесор Pentium Pro відрізняло застосування технології динамічного виконання (зміни порядку виконання інструкцій), а також архітектура подвійної незалежної шини (англ. Dual Independent Bus), завдяки чому було знято багато обмежень на пропускну здатність пам'яті, характерні для попередників і конкурентів. Тактова частота першого процесора архітектури P6 становила 150 МГц, а останні представники цієї архітектури мали тактову частоту 1,4 ГГц. Процесори архітектури P6 мали 36-розрядну шину адреси, що дозволило їм адресувати до 64 ГБ пам'яті (при цьому лінійний адресний простір процесу обмежено 4 ГБ, див. PAE).
Суперскалярний механізм виконання інструкцій зі зміною їх послідовності
Принциповою відмінністю архітектури P6 від попередників є RISC-ядро, яке працює не з інструкціями x86, а з простими внутрішніми мікроопераціями. Це дозволяє зняти безліч обмежень набору команд x86, таких як нерегулярне кодування команд, змінна довжина операндів і операції цілочислових пересилань регістр-пам'ять[3]. Крім того, мікрооперації виконуються не в тій послідовності, яка передбачена програмою, а в оптимальною з точки зору продуктивності, а застосування триконвеєрної обробки дозволяє виконувати декілька інструкцій за один такт[4].
'Суперконвейерізація'
Процесори архітектури P6 мають конвеєр глибиною 12 стадій. Це дозволяє досягати вищих тактових частот в порівнянні з процесорами, що мають більш короткий конвеєр при однаковій технології виробництва. Так, наприклад, максимальна тактова частота процесорів AMD K6 на ядрі (глибина конвеєра — 6 стадій, 180 нм. Технологія) становить 550 МГц, а процесори Pentium III на ядрі Coppermine здатні працювати на частоті, що перевищує 1000 МГц.
Для того, щоб запобігти ситуації очікування виконання інструкції (і, отже, простою конвеєра), від результатів якого залежить виконання або невиконання умовного переходу, в процесорах архітектури P6 використовується передбачення розгалужень. Для цього в процесорах архітектури P6 використовується поєднання статичного і динамічного передбачення: дворівневий адаптивний історичний алгоритм (англ. Bimodal branch prediction) застосовується в тому випадку, якщо буфер передбачення розгалужень містить історію переходів, в іншому випадку застосовується статичний алгоритм[4]
Подвійна незалежна шина
З метою збільшення пропускної спроможності підсистеми пам'яті, в процесорах архітектури P6 застосовується подвійна незалежна шина. На відміну від попередніх процесорів, системна шина яких була спільною для декількох пристроїв, процесори архітектури P6 мають дві роздільні шини: Back-side bus, що сполучає процесор з кеш-пам'яттю другого рівня, і Front side bus, що сполучає процесор з північним мостом набору мікросхем[4].
Переваги
Процесори архітектури P6 мали конвеєризований математичний співпроцесор (FPU), що дозволив досягти переваги над попередниками і конкурентами у швидкості дійсночисельних обчислень[5]. FPU процесорів архітектури P6 залишався найкращим серед конкурентів до появи в 1999 році процесора AMD Athlon[6].
Крім того, процесори архітектури P6 мали перевагу над конкурентами і в швидкості роботи з кеш-пам'яттю другого рівня. Pentium Pro і Pentium II мали подвійну незалежну шину, в той час як конкуруючі процесори (AMD K5, K6, Cyrix 6x86, M-II) — традиційну системну шину до якої підключався, в тому числі, і кеш другого рівня[7]. З появою процесорів Athlon, які також використовують архітектуру з подвійною незалежною шиною, розрив у продуктивності скоротився, але 256-розрядна BSB процесорів Pentium III (починаючи з ядра Coppermine) дозволяла утримувати перевагу у швидкості роботи з кеш-пам'яттю другого рівня над процесорами архітектури K7, що мали 64-розрядну BSB. Однак, застаріла на той момент системна шина процесорів архітектури P6 у поєднанні з великим об'ємом кеш-пам'яті першого рівня у процесорів архітектури K7 не дозволяла отримати перевагу в пропускній здатності пам'яті[8].
Недоліки
Основним недоліком перших процесорів архітектури P6 (Pentium Pro) була низька продуктивність при роботі з широко поширеним в той час 16-розрядним програмним забезпеченням. Це було пов'язано з тим, що при роботі з такими додатками позачергове виконання інструкцій було ускладнено (так, наприклад, процесор Pentium Pro не міг виконати читання з 32-бітного регістра, якщо до цього був виконаний запис у його 16-бітну молодшу частину, а команда, що виконала запис, не була відставлена [9]). У процесорі Pentium II цей недолік був виправлений, що призвело до збільшення продуктивності при роботі з 16-розрядними програмами більш ніж на третину[10].
Процесори архітектури P6 підтримували роботу в багатопроцесорних системах, однак при цьому використовувалася колективна системна шина, що дозволяло спростити трасування системних плат, однак негативно позначалося на продуктивності підсистеми процесор-пам'ять і обмежувало максимальну кількість процесорів в системі[6][11].
Процесори архітектури P6
| Процесор | Ядро | Технологія виготовлення | Роки випуску |
|---|---|---|---|
| Pentium Pro | P6 | КМОН/BiCMOS, 500—350 нм | 1995—1998 |
| Pentium II | Klamath, Deschutes | КМОН, 350—250 нм | 1997—1999 |
| Pentium III | Katmai, Coppermine, Tualatin-256 | КМОН, 250—130 нм | 1999—2002 |
| Pentium III-S | Tualatin | КМОН, 130 нм | 2001—2002 |
| Celeron | Covington, Mendocino, Coppermine-128, Tualatin-256 | КМОН, 250—130 нм | 1998—2002 |
| Pentium II Xeon | Drake | КМОН, 250 нм | 1998—1999 |
| Pentium III Xeon | Tanner, Cascades, Cascades 2MB | КМОН, 250—180 нм | 1999—2001 |
 |
 |
 |
 |
|---|---|---|---|
| Pentium Pro (P6) | Pentium II (Deschutes) | Pentium III (Coppermine) | Pentium IIIS (Tualatin) |
 |
 |
 |
 |
| Pentium III Mobile | Celeron (Mendocino) | Celeron (Mendocino) | Celeron (Coppermine-128) |
Схема розвитку архітектур Intel

Посилання
Офіційна інформація
- = Офіційна база даних по процесорах Pentium II (англ.)
- Документація по процесорах Pentium II (англ.)
- Документація по процесорах Mobile Pentium II
- = Офіційна база даних по процесорах Pentium III (англ.)
- Документація по процесорах Pentium III (англ.)
- Документація по процесорах Mobile Pentium III (англ.)
Характеристики процесорів архітектури P6
- Характеристики процесорів Pentium Pro (англ.)
- Характеристики процесорів Pentium II OverDrive (англ.)
- Характеристики процесорів Pentium II (англ.)
- Характеристики процесорів Pentium III (англ.)
Огляди процесорів
Примітки
- На відміну від процесора Celeron на ядрі Coppermine-128, який має 4-канальний асоціативний кеш другого рівня, у цього процесора кеш 8-канальний. Див.: «Світ ігрових консолей. Частина п'ята», журнал Upgrade, 2007, № 28 (325), стр. 24
- Jon Stokes (11 липня 2004). The Pentium: An Architectural History of the World's Most Famous Desktop Processor (Part I) (англ.). Ars Technica. Архів оригіналу за 28 січня 2012. Процитовано 19 серпня 2008.
- В очікуванні Willamette — історія архітектури IA-32 і як працюють процесори сімейства P6
- X86 архітектури бувають різні …
- Порівняння систем на базі Super Socket-7 і Slot-1
- Огляд процесора AMD Athlon 600 МГц
- Шина PCI (Peripheral Component Interconnect bus) — див. схему
- com/cpu/1000-p3-vs-tb.html Процесори з частотою 1000 МГц[недоступне посилання з червня 2019]
- Максим Лінь: «АРХІТЕКТУРА Р6: СПАДЩИНА ПОКОЛІНЬ» (опублікована на сайті fcenter.ru 22 листопада 2000) — збережена копія[недоступне посилання з лютого 2019]
- історія продовжується
- Двопроцесорні Socket A системи на базі чипсету AMD 760MP