spaCy
spaCy ([speɪˈsiː] spay-SEE) — бібліотека програмного забезпечення з відкритим вихідним кодом для обробки природної мови, написана на мовах програмування Python і Cython[4][5]. Бібліотека розповсюджується під ліцензією MIT, а її основними розробниками є Метью Хоннібал та Інес Монтані, засновники компанії Explosion з розробки програмного забезпечення.
|
| |
| Тип | вільне та відкрите програмне забезпечення і natural language processing softwared |
|---|---|
| Розробник | Matt Honnibald[1] |
| Версії | 3.2.1 (8 грудня 2021)[2] |
| Репозиторій | github.com/explosion/spaCy |
| Мова програмування | Python[3] |
| Ліцензія | MIT |
| Вебсайт | spacy.io |
На відміну від NLTK, який широко використовується для навчання та досліджень, spaCy зосереджується на наданні програмного забезпечення для виробничого використання[6][7]. spaCy також підтримує робочі процеси глибинного навчання, які дозволяють підключати статистичні моделі, навчені популярними бібліотеками машинного навчання, такими як TensorFlow, PyTorch або MXNet, через власну бібліотеку машинного навчання Thinc[8][9]. Використовуючи Thinc як бекенд, spaCy пропонує моделі згорткових нейронних мереж для розмічування частин мови, розбору залежностей, категоризації тексту та розпізнавання іменованих сутностей (РІС). Попередньо створені моделі нейронних мереж для виконання цього завдання доступні для 17 мов, серед яких українська поки відсутня, хоча є багатомовна модель РІС. Додаткова підтримка токенізації для більш ніж 65 мов дозволяє користувачам також навчати власні моделі на власних наборах даних[10].
Історія
- Версія 1.0 була випущена 19 жовтня 2016 року і мала попередню підтримку робочих процесів глибинного навчання за допомогою підтримки конвеєрів обробки налаштувань[11]. Крім того, містився узгоджувач правил, який підтримував анотацію об'єктів, та офіційно задокументований навчальний API.
- Версія 2.0 була випущена 7 листопада 2017 року та представила моделі згорткових нейронних мереж для 7 різних мов[12]. Також підтримувалися спеціальні компоненти конвеєру обробки та атрибути розширення, а також мав вбудований компонент для класифікації тексту, який можна навчати.
- Версія 3.0 була випущена 1 лютого 2021 року та представила найсучасніші конвеєри на основі трансформерів[13]. Також було запроваджено нову систему конфігурації та робочий процес навчання, а також підказки для типів і шаблони проектів. У цій версії була припинена підтримка Python 2.
Основні властивості
- Неруйнівна токенізація
- Підтримка «альфа-токенізації» для понад 65 мов[14]
- Вбудована підтримка компонентів конвеєра, які можна навчати, таких як розпізнавання іменованих об'єктів, тегування частин мови, розбір залежностей, класифікація тексту, зв’язування об’єктів тощо.
- Статистичні моделі для 19 мов[15]
- Багатозадачне навчання з попередньо підготовленими трансформерами, такими як BERT
- Підтримка користувацьких моделей у PyTorch, TensorFlow та інших фреймворках
- Швидкість і точність сучасного рівня[16]
- Готова до виробництва система навчання
- Вбудовані візуалізатори для синтаксису та іменованих сутностей
- Просте пакування моделі, розгортання та керування робочим процесом
Розширення та інструменти для візуалізації
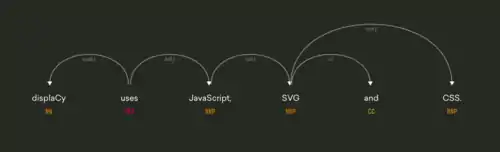
spaCy поставляється з кількома розширеннями та візуалізаціями, які доступні як безплатні бібліотеки з відкритим вихідним кодом:
- Thinc: Бібліотека машинного навчання оптимізована для використання центрального процесора та глибинного навчання, коли входом є текст.
- sense2vec: Бібліотека для обчислення подібності слів заснована на Word2vec[17].
- displaCy: Візуалізатор синтаксичного дерева залежностей з відкритим вихідним кодом, створений за допомогою JavaScript, CSS та SVG.
- displaCyENT: візуалізатор іменованих сутностей з відкритим кодом, створений за допомогою JavaScript та CSS.
Примітки
- A short introduction to NLP in Python with spaCy — 2017.
- Release 3.2.1 — 2021.
- The spacy Open Source Project on Open Hub: Languages Page — 2006.
- Choi et al. (2015).
- Google's new artificial intelligence can't understand these sentences. Can you?. Washington Post. Процитовано 18 грудня 2016.
- Facts & Figures - spaCy. spacy.io (англ.). Процитовано 4 квітня 2020.
- Bird, Steven; Klein, Ewan; Loper, Edward; Baldridge, Jason (2008). Multidisciplinary instruction with the Natural Language Toolkit. Proceedings of the Third Workshop on Issues in Teaching Computational Linguistics, ACL: 62. ISBN 9781932432145. doi:10.3115/1627306.1627317. Проігноровано невідомий параметр
|doi-access=(довідка) - PyTorch, TensorFlow & MXNet. thinc.ai. Процитовано 4 квітня 2020.
- explosion/thinc. GitHub. Процитовано 30 грудня 2016.
- Models & Languages | spaCy Usage Documentation. spacy.io. Процитовано 10 березня 2020.
- explosion/spaCy. GitHub. Процитовано 8 лютого 2021.
- explosion/spaCy. GitHub. Процитовано 8 лютого 2021.
- explosion/spaCy. GitHub. Процитовано 8 лютого 2021.
- Models & Languages - spaCy. spacy.io (англ.). Процитовано 8 лютого 2021.
- Models & Languages | spaCy Usage Documentation. spacy.io (англ.). Процитовано 8 лютого 2021.
- Benchmarks | spaCy Usage Documentation. spacy.io (англ.). Процитовано 8 лютого 2021.
- Trask et al. (2015). sense2vec - A Fast and Accurate Method for Word Sense Disambiguation In Neural Word Embeddings.