Глибинне навчання
Глиби́нне навча́ння (також відоме як глибинне структурне навчання, ієрархічне навчання, глибинне машинне навчання, англ. deep learning, deep structured learning, hierarchical learning, deep machine learning) — це галузь машинного навчання, що ґрунтується на наборі алгоритмів, які намагаються моделювати високорівневі абстракції в даних, застосовуючи глибинний граф із декількома обробними шарами, що побудовано з кількох лінійних або нелінійних перетворень.[1][2][3][4][5][6][7][8][9]
Глибинне навчання є частиною ширшого сімейства методів машинного навчання, що ґрунтуються на навчанні ознак даних. Спостереження (наприклад, зображення) може бути представлено багатьма способами, такими як вектор значень яскравості для пікселів, або абстрактнішим способом, як множина кромок, областей певної форми тощо. Деякі представлення є кращими за інші у спрощенні задачі навчання (наприклад, розпізнаванню облич, або виразів облич[10]). Однією з обіцянок глибинного навчання є заміна ознак ручної роботи дієвими алгоритмами автоматичного або напівавтоматичного навчання ознак та ієрархічного виділяння ознак.[11]
Дослідження в цій області намагаються зробити кращі представлення та створити моделі для навчання цих представлень з великомасштабних немічених даних. Деякі з цих представлень було зроблено під натхненням досягнень в нейронауці та з мотивів схем обробки та передавання інформації в нервовій системі, таких як нервове кодування, що намагається визначити зв'язок між різноманітними стимулами та пов'язаними нейронними реакціями в мозку.[12]
Різні архітектури глибинного навчання, такі як глибинні нейронні мережі, згорткові глибинні нейронні мережі, глибинні мережі переконань та рекурентні нейронні мережі застосовувалися в таких областях, як комп'ютерне бачення, автоматичне розпізнавання мовлення, обробка природної мови, розпізнавання звуків та біоінформатика, де вони, як було показано, представляють передові результати в різноманітних задачах.
Глибинне навчання характеризувалося як модне слово, або ребрендинг нейронних мереж.[13][14]
Введення
Визначення
Є кілька способів, якими характеризувалася галузь глибинного навчання. Наприклад, 1986 року Ріна Дехтер ввела поняття глибинного навчання першого порядку та глибинного навчання другого порядку в контексті задоволення обмежень.[15] Пізніше глибинне навчання було охарактеризовано як клас алгоритмів машинного навчання, які[2]
- використовують каскад багатьох шарів вузлів нелінійної обробки для виділяння ознак та перетворення. Кожен наступний шар використовує вихід із попереднього шару як вхід. Алгоритми можуть бути з керованим або спонтанним навчанням, а застосування включають розпізнавання образів (спонтанне) та класифікацію (керовану).
- ґрунтуються на навчанні (спонтанному) декількох шарів ознак або представлень даних. Ознаки вищих рівнів виводяться з ознак нижчих рівнів для формування ієрархічного представлення.
- є частиною ширшої області машинного навчання з навчання представлень даних.
- навчаються кільком рівням представлень, що відповідають різним рівням абстракції; ці рівні формують ієрархію понять.
Ці визначення мають спільними (1) декілька шарів вузлів нелінійної обробки та (2) кероване або спонтанне навчання представлень ознак у кожному з шарів, з формуванням шарами ієрархії від низькорівневих до високорівневих ознак.[2] Побудова шару вузлів нелінійної обробки, що застосовується в алгоритмі глибинного навчання, залежить від розв'язуваної задачі. Шари, що застосовувалися в глибинному навчанні, включають приховані шари штучної нейронної мережі та набори складних висловлень.[3] Вони також можуть включати латентні змінні, організовані по шарах у глибинних породжувальних моделях, такі як вузли в глибинних мережах переконань та глибинних машинах Больцмана.
Алгоритми глибинного навчання перетворюють свої входи крізь більшу кількість шарів, ніж алгоритми поверхневого навчання. На кожному шарі сигнал перетворюється блоком обробки, таким як штучний нейрон, параметри якого «навчаються» шляхом тренування.[5] Ланцюг перетворень від входу до виходу є шляхом передачі довіри (ШПД, англ. credit assignment path, CAP). ШПД описують потенційно причинні зв'язки між входом та виходом, і можуть мати змінну довжину. Для нейронної мережі прямого поширення довжина шляхів передачі довіри, і відтак глибина цієї мережі, є числом прихованих шарів плюс один (вихідний шар також параметризовано). Для рекурентних нейронних мереж, в яких сигнал може поширюватися через якийсь шар більше одного разу, ШПД має потенційно необмежену довжину. Універсально узгодженого порогу глибини, що відділяв би поверхневе навчання від глибинного, не існує, але більшість дослідників у цій галузі погоджуються, що глибинне навчання має декілька нелінійних шарів (ШПД > 2), а Шмідгубер розглядає ШПД > 10 як дуже глибинне навчання.[5]
Фундаментальні поняття
Алгоритми глибинного навчання ґрунтуються на розподілених представленнях. Припущенням, що лежить в основі розподілених представлень, є те, що спостережувані дані породжено взаємодією факторів, організованих у рівні. Глибинне навчання додає припущення, що ці рівні факторів відповідають різним рівням абстракції або побудови. Для забезпечення різних ступенів абстракції можуть застосовуватися змінні кількості та розміри шарів.[4]
Глибинне навчання використовує цю ідею ієрархічних пояснювальних факторів, де з понять нижчого рівня відбувається навчання абстрактніших понять вищого рівня. Ці архітектури часто будуються за допомогою пошарового жадібного методу. Глибинне навчання дозволяє розплутувати ці абстракції й вихоплювати ознаки, що є корисними для навчання.[4]
Для задач керованого навчання методи глибинного навчання уникають конструювання ознак, перетворюючи дані у компактні проміжні представлення на кшталт головних компонент, і виводять шаруваті структури, що усувають надмірність у представленні.[2]
Багато алгоритмів глибинного навчання застосовуються до задач спонтанного навчання. Це є важливою перевагою, оскільки немічені дані зазвичай є багатшими за мічені. Прикладами глибинних структур, які можуть тренуватися спонтанним чином, є нейронні стискачі історії[16] та глибинні мережі переконань.[17][4]
Інтерпретації
Глибинні нейронні мережі зазвичай інтерпретують у термінах теореми про універсальне наближення[18][19][20][21][22] або ймовірнісного висновування.[2][3][4][5][17][23]
Інтерпретація теореми про універсальне наближення
Теорема про універсальне наближення стосується здатності нейронних мереж прямого поширення з єдиним прихованим шаром наближувати неперервні функції.[18][19][20][21][22]
Її перше доведення було опубліковано 1989 року Джорджем Цибенком для сигмоїдних активаційних функцій,[19] і було узагальнено для багатошарових архітектур прямого поширення 1991 року Куртом Горником.[20]
Імовірнісна інтерпретація
Ймовірнісна інтерпретація[23] походить з галузі машинного навчання. Вона відводить провідне місце висновуванню,[2][3][4][5][17][23] а також таким поняттям оптимізації, як тренування та тестування, пов'язаним із узгодженням та узагальненням відповідно. Конкретніше, ймовірнісна інтерпретація розглядає нелінійність активації як кумулятивну функцію густини.[23] Див. глибинну мережу переконань. Імовірнісна інтерпретація привела до запровадження виключення (англ. dropout) як регуляризатора в нейронних мережах.[24]
Імовірнісну інтерпретацію було введено та популяризовано Джефрі Хінтоном, Джошуа Бенджо, Яном ЛеКуном та Юргеном Шмідгубером.
Історія
Перший загальний робочий алгоритм керованого навчання багаторівневоі мережі персептронів було опубліковано 1965 року Олексієм Івахненком та Валентином Лапою.[25] В праці 1971 року ними вже було описано нейронну мережу з 8 шарами, навченими методом групового урахування аргументів, який широко використовують і досі.[26][27] Ці ідеї було реалізовано в системі ідентифікації комп'ютера «Альфа», який продемонстрував сам процес навчання.[28][29] Інші архітектури глибинного навчання, зокрема побудовані зі штучних нейронних мереж (ШНМ), беруть свій початок щонайменше з неокогнітрону, запровадженого Куніхіко Фукусімою 1980 року.[30] ШНМ самі по собі беруть свій початок ще раніше. Виклик полягав у тому, як тренувати мережі з декількома шарами. 1989 року Яну ЛеКуну та ін. вдалося застосувати до глибинної нейронної мережі стандартний алгоритм зворотного поширення, що був відомим як зворотний режим автоматичного диференціювання з 1970 року,[31][32][33] з метою розпізнавання рукописних поштових індексів на поштових відправленнях. Незважаючи на успіх застосування алгоритму, тривалість тренування мережі на цьому наборі даних складала близько 3 днів, роблячи його практично недоцільним для загального використання.[34] 1993 року нейронний стискач історії Юргена Шмідгубера, реалізований як стек рекурентних нейронних мереж (РНМ), розв'язав задачу «дуже глибокого навчання»,[5] яка вимагає понад 1 000 послідовних шарів в РНМ, розгорнутій у часі.[35] 1995 року Брендан Фрей показав, що можливо натренувати мережу, що складається з шести повнозв'язних шарів та кількох сотень прихованих вузлів, застосовуючи алгоритм неспання-сну, який було розроблено спільно з Пітером Даяном та Джефрі Хінтоном.[36] Тим не менше, тренування зайняло два дні.
В низьку швидкість роблять свій внесок багато факторів, одним з яких є проблема зникання градієнту, проаналізована 1991 року Зеппом Хохрайтером.[37][38]
В той час як до 1991 року такі мережі застосовувалися для розпізнавання відокремлених двовимірних рукописних цифр, розпізнавання тривимірних об'єктів здійснювалося зіставленням двовимірних зображень із розробленою вручну тривимірною моделлю. Цзюян Вен та ін. висунули припущення, що людський мозок не використовує монолітні тривимірні моделі об'єктів, і 1992 року вони опублікували кресцептрон (англ. Cresceptron),[39][40][41] метод виконання розпізнавання тривимірних об'єктів безпосередньо із загромаджених сцен. Кресцептрон є каскадом багатьох шарів, подібних до неокогнітрону. Але, на відміну від неокогнітрону, який вимагав ручного об'єднання ознак програмістом, кресцептрон повністю автоматично навчився відкритого ряду спонтанних ознак на кожному шарі, де кожна ознака представляється ядром згортки. На додачу, кресцептрон також відділяв кожен вивчений об'єкт із загромадженої сцени шляхом зворотного аналізу через мережу. Максимізаційну підвибірку (англ. max-pooling), що нині часто запозичується глибинними нейронними мережами (наприклад, перевірками ImageNet), було вперше застосовано в кресцептроні для зменшення роздільної здатності положення на коефіцієнт (2×2) до 1 через каскад для кращого узагальнення. Незважаючи на ці переваги, популярним вибором у 1990-х та 2000-х роках були простіші моделі, що використовують розроблені вручну ознаки, орієнтовані на конкретні задачі, такі як фільтр Ґабора та методи опорних векторів (англ. support vector machines, SVM), з причини тодішніх обчислюваних витрат ШНМ, та браку розуміння того, як мозок автономно зв'язує свої біологічні мережі.
В довгій історії розпізнавання мовлення протягом багатьох років досліджувалося як поверхневе, так і глибинне навчання (наприклад, рекурентні мережі) штучних нейронних мереж.[42][43][44] Але ці методи ніколи не перемагали неоднорідну внутрішньо-ручну технологію ґаусових сумішевих моделей/прихованих марковських моделей (ҐСМ-ПММ, англ. GMM-HMM), що ґрунтується на породжувальних моделях мовлення, натренованих розрізнювально.[45] Було методично проаналізовано ряд ключових труднощів, включно зі зменшенням градієнту[37] та слабкою структурою часової кореляції в нейронних передбачувальних моделях.[46][47] Додатковими утрудненнями в ті ранні дні були брак великих тренувальних даних та слабші обчислювальні потужності. Отже, більшість дослідників розпізнавання мовлення, які розуміли такі перешкоди, відійшли від нейронних мереж, щоби займатися породжувальним моделюванням. Винятком був SRI International в кінці 1990-х років. Фінансований агенціями АНБ та DARPA уряду США, SRI здійснював дослідження з глибинних нейронних мереж у розпізнаванні мовлення та мовника. Команда розпізнавання мовника під проводом Ларрі Гека (англ. Larry Heck) досягла першого значного успіху з глибинними нейронними мережами в обробці мовлення, який було продемонстровано 1998 року на Оцінці розпізнавання мовника NIST (National Institute of Standards and Technology), і пізніше опубліковано в журналі Speech Communication.[48] І хоча SRI досяг успіху з глибинними мережами в розпізнаванні мовника, вони були безуспішними в демонстрації подібного успіху в розпізнаванні мовлення. Хінтон та ін. і Ден та ін. зробили огляд цієї нещодавньої історії про те, як їхня співпраця між собою, а потім і з колегами з-поміж чотирьох груп (Університету Торонто, Microsoft, Google та IBM), запалила відродження глибинних нейронних мереж в розпізнаванні мовлення.[49][50][51][52]
Сьогодні, проте, багато аспектів розпізнавання мовлення було перебрано методом глибинного навчання, який називається довгою короткочасною пам'яттю (ДКЧП, англ. long short-term memory, LSTM), рекурентною нейронною мережею, опублікованою Зеппом Хохрайтером та Юргеном Шмідгубером 1997 року.[53] РНМ ДКЧП уникають проблеми зникання градієнту, і можуть навчатися задач «дуже глибокого навчання»,[5] які вимагають спогадів про події, які сталися тисячі дискретних кроків часу тому, що є важливим у мовлені. 2003 року ДКЧП почала ставати конкурентноспроможною у порівнянні з традиційними розпізнавачами мовлення в деяких задачах.[54] Пізніше її було поєднано з НЧК (англ. CTC)[55] у стеках РНМ ДКЧП.[56] 2015 року в розпізнаванні мовлення Google, як повідомляється, стався різкий 49-відсотковий стрибок продуктивності завдяки НЧК-тренованій ДКЧП, яка тепер доступна через Google Voice користувачам усіх смартфонів,[57] і стала зразково-показовим прикладом глибинного навчання.
Згідно дослідження,[8] вираз «глибинне навчання» (англ. Deep Learning) було введено до спільноти машинного навчання Ріною Дехтер 1986 року,[15] і пізніше до штучних нейронних мереж — Ігорем Айзенбергом з колегами 2000 року.[58] Графік Google Ngram показує, що застосування цього терміну набрало обертів (фактично, злетіло) з 2000 року.[59] 2006 року публікація Джефрі Хінтона та Руслана Салахутдінова привернула додаткову увагу, показавши, як багатошарову нейронну мережу прямого поширення може бути попередньо натреновано шар за шаром, з розглядом кожного шару в свою чергу як спонтанної обмеженої машини Больцмана, а потім здійснено її тонке налаштування із застосуванням керованого зворотного поширення.[60] 1992 року Шмідгубер вже реалізував дуже подібну ідею для загальнішого випадку спонтанних глибинних ієрархій рекурентних нейронних мереж, і також експериментально показав її переваги для прискорення керованого навчання.[16][27]
З моменту свого відродження, глибинне навчання стало частиною багатьох передових систем у різноманітних дисциплінах, зокрема таких як комп'ютерне бачення та автоматичне розпізнавання мовлення (АРМ, англ. automatic speech recognition, ASR). Результати на широко вживаних оцінкових наборах, таких як TIMIT (АРМ) та MNIST (класифікація зображень), як і на ряді великих словникових задач розпізнавання мовлення, постійно покращуються новими застосуваннями глибинного навчання.[49][61][62] Нещодавно було показано, що архітектури глибинного навчання у вигляді згорткових нейронних мереж були чи не найефективнішими;[63][64] проте вони ширше застосовуються в комп'ютерному баченні, ніж в АРМ, і сучасне великомасштабне розпізнавання мовлення зазвичай ґрунтується на НЧК[55] для ДКЧП.[53][57][65][66][67]
Реальний вплив глибинного навчання в промисловості, мабуть, почався на початку 2000-х років, коли ЗНМ, згідно Яна ЛеКуна,[68] вже обробили оцінювані від 10 % до 20 % всіх перевірок, написаних у США на початку 2000-х років. Промислові застосування великомасштабного розпізнавання мовлення почалися близько 2010 року. Наприкінці 2009 року Лі Ден запросив Джефа Хінтона було до праці з ним та колегами в Microsoft Research для застосування глибинного навчання до розпізнавання мовлення. Вони співорганізували 2009 року Семінар NIPS з глибинного навчання для розпізнавання мовлення. Цей семінар спонукали обмеження глибинних породжувальних моделей мовлення, та можливість того, що ера великих обчислень та великих даних виправдовує серйозну спробу глибинних нейронних мереж (ГНМ, англ. deep neural net, DNN). Вважалося, що попереднє тренування ГНМ із застосуванням породжувальних моделей глибинних мереж переконань (ГМП, англ. deep belief net, DBN) подолає головні труднощі нейронних мереж, з якими зіткнулися в 1990-х роках.[51] Проте на ранніх етапах цього дослідження в Microsoft Research було виявлено, що без попереднього тренування, але при застосуванні великих кількостей тренувальних даних, і особливо ГНМ, розроблених з відповідно великими, контекстно-залежними вихідними шарами, породжувалися різко нижчі рівні похибки, ніж у тоді-передових ҐСМ-ПММ, а також у більш просунутих системах розпізнавання мовлення на базі породжувальних моделей. Це відкриття було перевірено кількома іншими головними групами дослідження розпізнавання мовлення.[49][69] Далі було встановлено, що природа похибок розпізнавання, продукованих цими двома типами систем, має характерні відмінності,[50][70] що приносить технічне розуміння того, як інтегрувати глибинне навчання до наявних високоефективних систем декодування мовлення в реальному часі, розгорнутих усіма головними гравцями в галузі розпізнавання мовлення. Історію цього знаменного розвитку в глибинному навчанні було описано та проаналізовано в нещодавніх книгах та статтях.[2][71][72]
Досягнення в апаратному забезпеченні також були важливими у поновленні зацікавлення глибинним навчанням. Зокрема, потужні графічні процесори (англ. GPU) добре підходять для того роду перемелювання чисел, матрично/векторної математики, що залучає машинне навчання.[73][74] Було показано, що графічні процесори прискорюють тренувальні алгоритми на порядки, повертаючи тривалості виконання з тижнів назад до днів.[75][76]
Штучні нейронні мережі
Деякі з найуспішніших методів глибинного навчання включають штучні нейронні мережі. Штучні нейронні мережі було розроблено під натхненням біологічної моделі 1959 року, запропонованої нобелівськими лауреатами Девідом Гантером Г'юбелем та Торстеном Візелем, які виявили два типи клітин у первинній зоровій корі: прості та складні клітини. Багато штучних нейронних мереж можуть розглядатися як каскадні моделі[39][40][41][77] типів клітин, надихнутих цими біологічними спостереженнями.
Нейрокогнітрон Фукусіми представив згорткові нейронні мережі, частково треновані спонтанним навчанням із вказаними людьми ознаками в нейронній площині. Ян ЛеКун та ін. (1989) застосували до таких архітектур контрольоване зворотне поширення.[78] Вен та ін. (1992) опублікували згорткові нейронні мережі «кресцептрон»[39][40][41] для розпізнавання тривимірних об'єктів із зображень загромаджених сцен та виділення таких об'єктів із зображень.
Очевидною потребою для розпізнавання звичайних тривимірних об'єктів є інваріантність відносно найменшого зсуву та стійкість до деформації. Підвибірка (англ. max-pooling) виявилася першою, запропонованою кресцептроном,[39][40] для надання мережі стійкості до від-малих-до-великих деформацій ієрархічним чином із застосуванням згортки. Максимізаційна підвибірка сприяє, хоча і не гарантує інваріантності відносно зсуву на рівні пікселів.[41]
З появою алгоритму зворотного поширення на основі автоматичного диференціювання[31][33][79][80][81][82][83][84][85][86] багато дослідників намагалися тренувати керовані глибинні штучні нейронні мережі з нуля, спочатку з невеликим успіхом. Дипломна праця Зеппа Хохрайтера 1991 року[37][38] формально ідентифікувала причину цієї невдачі в проблемі зникання градієнту, що впливає на багатошарові мережі прямого поширення та на рекурентні нейронні мережі. Рекурентні мережі тренуються шляхом розгортання їх у дуже глибоку мережу прямого поширення, де новий шар створюється для кожного моменту часу вхідної послідовності, оброблюваної мережею. Оскільки похибки поширюються від шару до шару, з числом шарів вони скорочуються експоненційно, перешкоджаючи налаштуванню вагових коефіцієнтів нейронів, яке ґрунтується на цих похибках.
Для подолання цієї проблеми було запропоновано декілька методів. Одним є багаторівнева ієрархія мереж Юргена Шмідгубера (1992 р.), попередньо тренована порівнево спонтанним навчанням, і тонко-налагоджувана зворотним поширенням.[16] Тут кожен рівень вчиться стисненого представлення спостережень, що подається на наступний рівень.
Іншим методом є мережа довгої короткочасної пам'яті (ДКЧП, англ. long short-term memory, LSTM) Хохрайтера та Шмідгубера (1997 р.).[53] 2009 року глибинні багатовимірні мережі ДКЧП виграли три змагання ICDAR 2009 з розпізнавання неперервного рукописного тексту без жодного попереднього знання про три мови, яких необхідно було навчитися.[87][88]
Свен Бенке 2003 року покладався лише на знак градієнту (Rprop), коли тренував свою Нейронну піраміду абстракцій (англ. Neural Abstraction Pyramid)[89] для розв'язання задач на кшталт відбудови зображень та локалізації облич.
Інші методи також застосовують спонтанне попереднє тренування для структурування нейронної мережі, даючи їй спочатку навчитися загальних корисних детекторів ознак. Потім ця мережа тренується далі керованим зворотним поширенням для класифікації мічених даних. Глибинна модель Хінтона та ін. (2006) включає навчання розподілу високорівневого представлення із застосуванням послідовних шарів двійкових або дійснозначних латентних змінних. Для моделювання кожного нового шару ознак вищого рівня вона використовує обмежену машину Больцмана (Смоленський, 1986[90]). Кожен новий шар гарантує підвищення нижньої межі логарифмічної правдоподібності даних, покращуючи таким чином модель, за правильного тренування. Щойно було навчено достатньо багато шарів, глибинну архітектуру можна застосовувати як породжувальну модель, відтворюючи дані шляхом здійснення вибірки вниз по моделі («родовий прохід», англ. "ancestral pass"), починаючи з активації ознак найвищого рівня.[91] Хінтон повідомляє, що його моделі є ефективними для виділяння ознак зі структурованих даних високої розмірності.[92]
Команда Google Brain під проводом Ендрю Ина та Джефа Діна створила[коли?] нейронну мережу, що навчилася розпізнавати високорівневі поняття, такі як коти, з самого лише перегляду немічених зображень, взятих із відеозаписів YouTube.[93][94]
Інші методи покладаються на чисту оброблювальну потужність сучасних комп'ютерів, зокрема, на графічні процесори. 2010 року Ден Чирешан з колегами[75] в групі Юргена Шмідгубера в швейцарській лабораторії штучного інтелекту IDSIA показали, що, незважаючи на вищезгадану «проблему зникання градієнту», надзвичайна обчислювальна потужність графічних процесорів робить звичайне зворотне поширення придатним для глибинних нейронних мереж прямого поширення з багатьма шарами. Цей метод перевершив усі інші методики машинного навчання на старій відомій задачі розпізнавання рукописних цифр MNIST Яна ЛеКуна та його колег з Нью-Йоркського університету.
Приблизно в цей самий час, наприкінці 2009 року, нейронні мережі прямого поширення з глибинним навчанням вчинили набіги на розпізнавання мовлення, як відмічено Семінаром NIPS з глибинного навчання для розпізнавання мовлення. Інтенсивна спільна робота дослідників з Microsoft Research та Університету Торонто продемонструвала в середині 2010 року в Редмонді, що глибинні нейронні мережі, пов'язані з прихованою марковською моделлю з контекстно-залежними станами, що визначає вихідний шар нейронної мережі, можуть різко скоротити похибки у великих задачах словникового розпізнавання мовлення, таких як голосовий пошук. Близько року по тому в Microsoft Research Asia було показано масштабування такої ж моделі глибинної нейронної мережі до задачі телефонного комутатора. Навіть раніше, 2007 року, ДКЧП,[53] тренована за допомогою НЧК,[55] почала отримувати відмінні результати в деяких застосуваннях.[56] Цей метод тепер широко застосовується, наприклад, у значно поліпшеному розпізнаванні мовлення Google для користувачів усіх смартфонів.[57]
Станом на 2011 рік передовим у нейронних мережах глибинного навчання прямого поширення є чергування згорткових (англ. convolutional) та підвибіркових (англ. max-pooling) шарів,[95][96] увінчаних декількома повнозв'язними або розріджено зв'язаними шарами, за якими слідує завершальний шар класифікації. Тренування зазвичай здійснюється без жодного спонтанного попереднього тренування. З 2011 року реалізації цього підходу на основі графічних процесорів[95] виграли багато змагань з розпізнавання образів, включно зі Змаганням з розпізнавання дорожніх знаків (англ. Traffic Sign Recognition Competition) IJCNN 2011,[97] Змаганням з сегментації нейронних структур в стеку електронної мікроскопії (англ. Segmentation of neuronal structures in EM stacks challenge) ISBI 2012,[98] Змаганням ImageNet[99] та іншими.
Такі керовані методи глибинного навчання також стали першими штучними розпізнавачами образів, що досягли в деяких задачах ефективності, порівняної з людською.[100]
Щоби подолати бар'єри слабкого штучного інтелекту, представленого глибинним навчанням, необхідно вийти за межі архітектур глибинного навчання, оскільки згідно інформації з анатомії мозку[101] біологічні мізки використовують як поверхневі так і глибинні ланцюги, демонструючи широке розмаїття інваріантності. Вен[102] стверджував, що мозок широко самоз'єднується відповідно до статистики сигналів, і отже, послідовний каскад не може вловити всі основні статистичні залежності. ШНМ виявилися здатними гарантувати інваріантність відносно зсуву, щоби мати справу з малими та великими природними об'єктами у великих загромаджених сценах, лише коли інваріантність поширилася за межі зсуву, на всі вивчені ШНМ поняття, такі як положення, тип (мітка класу об'єкту), масштаб, освітленість. Це було реалізовано в Еволюційних Мережах (ЕМ, англ. Developmental Networks, DN),[103] чиїми втіленнями є мережі де-що (англ. Where-What Networks), від WWN-1 (2008)[104] до WWN-7 (2013).[105]
Архітектури глибинних нейронних мереж
Існує величезна кількість варіантів глибинних архітектур. Більшість із них відгалужуються від деяких вихідних батьківських архітектур. Одночасне порівняння ефективності різних архітектур не завжди можливе, оскільки не всі з них оцінювалися на однакових наборах даних. Глибинне навчання є галуззю, що швидко розвивається, і нові архітектури, варіанти або алгоритми з'являються кожні кілька тижнів.
Стисле обговорення глибинних нейронних мереж
Глибинна нейронна мережа (ГНМ, англ. deep neural network, DNN) — це штучна нейронна мережа (ШНМ) з декількома прихованими шарами вузлів між вхідним та вихідним шарами.[3][5] Подібно до пласких ШНМ, ГНМ можуть моделювати складні нелінійні відношення. Архітектури ГНМ, наприклад, для виявлення об'єктів та граматичного аналізу, породжують композиційні моделі, де об'єкт виражається як шарувата композиція примітивів зображення.[106] Додаткові шари дозволяють композиції включати ознаки з нижчих шарів, забезпечуючи потенціал для моделювання складних даних меншою кількістю вузлів, ніж настільки ж ефективна пласка мережа.[3]
ГНМ зазвичай проектуються як мережі прямого поширення, але дослідження дуже успішно застосували рекурентні нейронні мережі, особливо ДКЧП,[53][107] до таких задач, як моделювання мов.[108][109][110][111][112] Згорткові глибинні нейронні мережі (ЗНМ, англ. convolutional deep neural networks, CNN) застосовуються в комп'ютерному зорі, де їхній успіх є добре задокументованим.[113] ЗНМ також було застосовано до акустичного моделювання для автоматичного розпізнавання мовлення (АРМ, англ. automatic speech recognition, ASR), де вони продемонстрували переваги над попередніми моделями.[64] Для спрощення, тут наведено погляд на тренування ГНМ.
Зворотне поширення
ГНМ може бути натреновано розрізнювально за допомогою стандартного алгоритму зворотного поширення. Згідно різних джерел,[5][8][86][114] основи безперервного зворотного поширення було виведено в контексті теорії керування Генрі Келлі[81] 1960 року та Артуром Брайсоном 1961 року,[82] із застосуванням принципів динамічного програмування. 1962 року Стюарт Дрейфус опублікував простіше виведення на основі лише ланцюгового правила.[83] Володимир Вапник цитує посилання [115] у своїй книзі про Метод опорних векторів. Артур Брайсон та Ю Ці Хо описали це як багатоетапний метод оптимізації динамічної системи 1969 року.[116][117] 1970 року Сеппо Ліннаінмаа остаточно опублікував загальний метод автоматичного диференціювання (АД, англ. AD) дискретних зв'язних мереж вкладених диференційовних функцій.[31][118] Це відповідає сучасній версії зворотного поширення, яка є дієвою навіть коли мережі є розрідженими.[5][8][32][80] 1973 року Стюарт Дрейфус застосував зворотне поширення для адаптування параметрів регуляторів у пропорції до градієнтів похибок.[84] 1974 року Пол Вербос зазначив можливість застосування цього принципу до штучних нейронних мереж,[119] а 1982 року він застосував метод АД Ліннаінмаа до нейронних мереж таким чином, яким він широко застосовується сьогодні.[8][79] 1986 року Девід Румельхарт, Джефрі Хінтон та Рональд Вільямс показали шляхом комп'ютерних експериментів, що цей метод може породжувати корисні внутрішні представлення вхідних даних у прихованих шарах нейронних мереж.[85] 1993 року Ерік Ван (англ. Eric A. Wan) став першим,[5] хто переміг у міжнародному змаганні з розпізнавання образів із зворотним поширенням.[120]
Уточнення вагових коефіцієнтів може здійснюватися стохастичним найшвидшим спуском із застосуванням наступного рівняння:

Тут є темпом навчання, а — функцією витрат. Вибір функції витрат залежить від таких факторів, як тип навчання (кероване, спонтанне, з підкріпленням тощо) та функції активації. Наприклад, при виконанні керованого навчання для задачі багатокласової класифікації звичайним вибором для функції активації та функції витрат є нормована експоненційна функція (англ. softmax) та функція перехресної ентропії відповідно. Багатозмінна логістична функція визначається як , де представляє ймовірність класу (вихід вузла ), а та представляють сумарний вхід до вузлів та на одному й тому ж рівні відповідно. Перехресна ентропія визначається як , де представляє цільову ймовірність для вихідного вузла , а є виходом ймовірності для після застосування активаційної функції.[121]










Вони можуть використовуватися для виведення описаних прямокутників об'єктів у вигляді двійкової маски. Вони також використовуються для багатомасштабної регресії для підвищення точності визначення положення. Регресія на базі ГНМ може навчатися ознак, що схоплюють геометричну інформацію, на додачу до того, що вони є добрим класифікатором. Вони усувають обмеження розробки моделі, що фіксуватиме деталі та їхні зв'язки явно. Це дозволяє навчатися широкого спектра об'єктів. Модель складається з кількох шарів, кожен з яких має ReLU для нелінійного перетворення. Деякі шари є згортковими, тоді як деякі є повноз'єднаними. Кожен згортковий рівень має додаткову підвибірку (англ. max pooling). Мережа тренується мінімізувати похибки L2 для передбачення маски на діапазоні всього тренувального набору, що містить описані прямокутники, представлені як маски.
Проблеми з глибинними нейронними мережами
Як і з ШНМ, з ГНМ може виникати багато проблем, якщо вони тренуються наївно. Двома поширеними проблемами є перенавчання та тривалість обчислення.
ГНМ схильні до перенавчання через додані шари абстракції, що дозволяють їм моделювати рідкісні залежності в тренувальних даних. Для допомоги в боротьбі з перенавчанням під час тренування можуть застосовуватися методи регуляризації, такі як відсікання вузлів Івахненка[26], зменшення вагових коефіцієнтів (-регуляризація) та розрідженість (-регуляризація).[122] Новішим методом регуляризації, що застосовується до ГНМ, є регуляризація виключенням (англ. dropout). При виключенні під час тренування деяка кількість вузлів з прихованих шарів випадково пропускається. Це допомагає зламати рідкісні залежності, що можуть траплятися в тренувальних даних.[123]


Панівним методом для тренування цих структур було тренування з коригуванням похибок (таке як зворотне поширення з градієнтним спуском), завдяки простоті його реалізації та його схильності до кращих локальних оптимумів, ніж інші методи тренування. Проте ці методи можуть бути обчислювально витратними, особливо для ГНМ. Є багато параметрів, які потрібно розглядати при ГНМ, такі як розмір (кількість шарів та кількість вузлів на шар), темп навчання та початкові вагові коефіцієнти. Прочісування простору параметрів у пошуку оптимальних може не бути придатним з причини витрат часу та обчислювальних ресурсів. Було показано, що різні «хитрощі», такі як міні-групування (англ. mini-batching, обчислення градієнту на кількох тренувальних прикладах одночасно, а не на окремих прикладах),[124] можуть пришвидшувати обчислення. Велика обробна пропускна спроможність графічних процесорів спричинила значне прискорення тренувань, оскільки потрібні матричні та векторні обчислення добре підходять для графічних процесорів.[5] Увагу привернули докорінні альтернативи зворотному поширенню, такі як машини екстремального навчання (англ. Extreme Learning Machines, ELM),[125] «безпоширні» (англ. «No-prop») мережі,[126] тренування без пошуку з вертанням[127] та «безвагові» нейронні мережі (англ. Weightless neural networks, WNN)[128] та не-зв'язницькі нейронні мережі (англ. non-connectionist neural networks).
Перші мережі глибинного навчання 1965 року: МГУА
Згідно історичного дослідження,[5] перші працездатні мережі глибинного навчання з багатьма шарами було опубліковано Олексієм Григоровичем Івахненком та Валентином Григоровичем Лапою 1965 року.[25][129] Цей алгоритм навчання було названо методом групового урахування аргументів, або МГУА (англ. Group Method of Data Handling, GMDH).[130] МГУА пропонує повністю повністю автоматичну структурну та параметричну оптимізацію моделей. Функції активації вузлів мережі є поліномами Колмогорова — Габора, які дозволяють додавання та множення. Праця Івахненка 1971 року[26] описує навчання глибинного багатошарового перцептрону прямого поширення з вісьмома шарами, вже набагато глибшого за багато пізніших мереж. Мережа керованого навчання нарощується шар за шаром, кожен шар тренується регресійним аналізом. Час від часу непотрібні нейрони виявляються за допомогою набору перевірок, і відсікаються через регуляризацію. Розмір та глибина отримуваної в результаті мережі залежать від задачі. Варіації цього методу застосовуються й досі.[131]
Згорткові нейронні мережі
ЗНМ стали методом, який вибирають для обробки візуальних та інших двовимірних даних.[34][68] ЗНМ складається з одного або більше згорткових шарів із повноз'єднаними шарами (що відповідають таким у типовій штучній нейронній мережі) нагорі. Вона також застосовує зв'язані вагові коефіцієнти та агрегувальні шари. Зокрема, у згортковій архітектурі Фукусіми часто застосовується максимізаційна підвибірка.[40][30] Ця архітектура дозволяє ЗНМ отримувати переваги від двовимірної структури вхідних даних. У порівнянні з іншими глибинними архітектурами, згорткові нейронні мережі показали чудові результати в застосуваннях як до зображень, так і до мовлення. Їх також може бути треновано стандартним зворотним поширенням. ЗНМ є простішими для тренування від інших звичайних, глибинних, нейронних мереж прямого поширення, і мають набагато менше параметрів для оцінки, що робить їх дуже привабливою архітектурою для застосування.[132] Приклади застосування в комп'ютерному баченні включають DeepDream.[133] Численні додаткові посилання див. у статті про згорткові нейронні мережі.
Нейронний стискач історії
Проблему зникання градієнту[37] автоматичного диференціювання та зворотного поширення в нейронних мережах було частково подолано 1992 року ранішою породжувальною моделлю, яка називається нейронним стискачем історії, реалізованою як некерований стек рекурентних нейронних мереж (РНМ).[16] РНМ на вхідному рівні навчається передбаченню свого наступного входу з історії попередніх входів. Лише непередбачувані входи деяких РНМ в ієрархії стають входами до наступних РНМ вищого рівня, які відтак переобчислюють свій внутрішній стан лише зрідка. Кожна РНМ вищого рівня таким чином навчається стисненого представлення інформації в нижчій РНМ. Це робиться таким чином, що вхідну послідовність може бути точно відбудовано з представлення послідовності на найвищому рівні. Система дієво мінімізує довжину опису, або від'ємний логарифм імовірності даних.[8] Якщо в послідовності вхідних даних є багато навчаної передбачуваності, то РНМ найвищого рівня може використовувати кероване навчання, щоби легко класифікувати навіть глибокі послідовності з дуже тривалими проміжками часу між важливими подіями. 1993 року така система вже розв'язала задачу «дуже глибокого навчання», яка вимагає понад 1 000 послідовних шарів в РНМ, розгорнутій у часі.[35]
Також є можливим переганяти всю ієрархію РНМ в лише дві РНМ, які називають «свідомим» фрагментувальником (вищий рівень) та «підсвідомим» автоматизатором (нижчий рівень).[16] Щойно фрагментувальник навчився передбачувати та стискати входи, що є все ще непередбачуваними для автоматизатора, як автоматизатор змушується на наступній фазі навчання передбачувати або імітувати через особливі додаткові вузли приховані вузли фрагментувальника, який змінюється повільніше. Це полегшує автоматизаторові навчання відповідних, рідко змінюваних спогадів протягом дуже тривалих проміжків часу. Це, в свою чергу, допомагає автоматизаторові робити багато з його раніше непередбачуваних входів передбачуваними, так що фрагментувальник може зосереджуватися на подіях, які все ще лишаються непередбачуваними, щоби стискати дані ще далі.[16]
Рекурсивні нейронні мережі
Рекурсивна нейронна мережа (англ. recursive neural network)[134] створюється шляхом рекурсивного застосування одного й того ж набору вагових коефіцієнтів над диференційовною графоподібною структурою, шляхом обходу цієї структури в топологічному порядку. Такі мережі зазвичай також тренуються оберненим режимом автоматичного диференціювання.[31][80] Їх було запропоновано для навчання розподілених представлень структури, таких як логічні терми. Окремим випадком рекурсивних нейронних мереж є власне РНМ, чия структура відповідає лінійному ланцюгові. Рекурсивні нейронні мережі застосовувалися до обробки природної мови.[135] Рекурсивна нейронна тензорна мережа (англ. Recursive Neural Tensor Network) використовує для всіх вузлів у дереві композиційну функцію на основі тензора.[136]
Довга короткочасна пам'ять
Численні дослідники нині застосовують варіанти РНМ глибинного навчання, яка називається мережею довгої короткочасної пам'яті (ДКЧП, англ. Long short-term memory, LSTM), опублікованої Хохрайтером та Шмідгубером 1997 року.[53] Вона є системою, яка, на відміну від традиційних РНМ, не має проблеми зникання градієнту. ДКЧП зазвичай доповнюються рекурентними вентилями, які називаються забувальними (англ. forget gates).[107] РНМ ДКЧП попереджають зворотнє поширення похибок від зникання градієнту або вибуху значень вагових коефіцієнтів.[37] Замість цього похибки можуть текти назад крізь необмежені кількості віртуальних шарів розгорнутих у просторі РНМ ДКЧП. Тобто, ДКЧП може навчатися завдань «дуже глибокого навчання»,[5] які вимагають спогадів про події, що сталися тисячі або навіть мільйони дискретних кроків часу тому. Може бути розвинено проблемно-орієнтовані ДКЧП-подібні топології.[137] ДКЧП працює навіть за наявності дуже тривалих затримок, і може обробляти сигнали, які містять суміш низько- та високочастотних складових.
Сьогодні багато застосувань використовують стеки РНМ ДКЧП,[138] і тренують їх нейромережевою часовою класифікацією (НЧК, англ. Connectionist Temporal Classification, CTC)[55] для знаходження вагової матриці РНМ, яка максимізує ймовірність послідовностей міток у тренувальному наборі для заданих відповідних вхідних послідовностей. НЧК досягає як вирівнювання, так і розпізнавання. 2009 року ДКЧП, тренована НЧК, стала першою РНМ, яка перемогла в змаганнях із розпізнавання образів, коли вона виграла кілька змагань із неперервного рукописного розпізнавання.[5][87] Вже 2003 року ДКЧП почала ставати конкурентноспроможною у порівнянні з традиційними розпізнавачами мовлення в деяких задачах.[54] 2007 року поєднання з НЧК отримало перші добрі результати на даних мовлення.[56] Відтоді цей підхід революціював розпізнавання мовлення. 2014 року китайський пошуковий гігант Baidu застосував РНМ, треновані НЧК, щоби перевершити еталон розпізнавання мовлення Switchboard Hub5'00, без застосування будь-яких традиційних методів обробки мовлення.[139] ДКЧП також поліпшила велико-словникове розпізнавання мовлення,[65][66] синтез мовлення з тексту,[140] також і для Google Android,[8][67] і фото-реалістичні голови, що розмовляють.[141] 2015 року в розпізнаванні мовлення Google, як повідомляється, стався різкий 49-відсотковий стрибок продуктивності завдяки НЧК-тренованій ДКЧП, яка тепер доступна через Google Voice мільярдам користувачам смартфонів.[57]
ДКЧП також стала дуже популярною в галузі обробки природної мови. На відміну від попередніх моделей на основі ПММ та подібних понять, ДКЧП може вчитися розпізнавати контекстно-чутливі мови.[108] ДКЧП поліпшила машинний переклад,[109] моделювання мов[110] та багатомовну обробку мов.[111] ДКЧП у поєднанні зі згортковими нейронними мережами (ЗНМ) також поліпшила автоматичний опис зображень[142] і безліч інших застосувань.
Глибинні мережі переконань
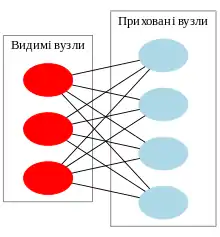
Глибинна мережа переконань (ГМП, англ. deep belief network, DBN) є ймовірнісною породжувальною моделлю, зробленою з кількох шарів прихованих вузлів. Її можна розглядати як композицію простіших модулів навчання, що утворюють кожен із шарів.[17]
ГМП можуть застосовуватися для породжувального попереднього тренування ГНМ шляхом застосування навчених вагових коефіцієнтів ГМП як початкових вагових коефіцієнтів ГНМ. Для точного налаштування цих вагових коефіцієнтів можуть застосовуватися зворотне поширення або інші розрізнювальні алгоритми. Це особливо корисно тоді, коли доступні тренувальні дані є обмеженими, оскільки вагові коефіцієнти з погано заданими початковими значеннями можуть значно заважати ефективності навченої моделі. Ці попередньо натреновані вагові коефіцієнти знаходяться в області простору вагових коефіцієнтів, що є ближчою до оптимальних вагових коефіцієнтів, ніж випадково вибрані початкові значення. Це передбачає як поліпшення моделювання, так і швидшу збіжність фази тонкого налаштування.[143]
ГМП можуть ефективно тренуватися спонтанним пошаровим чином, де кожен шар, як правило, зроблено з обмеженої машини Больцмана (ОМБ, англ. restricted Boltzmann machine, RBM). ОМБ є неорієнтованою породжувальною моделлю на основі енергії, з «видимим» вхідним шаром та прихованим шаром, і з'єднаннями між шарами, але не в межах шарів. Метод тренування ОМБ, запропонований Джефрі Хінтоном для застосування при тренуванні моделей «добутку експертів» (англ. "Product of Expert" models), називається порівняльною розбіжністю (ПР, англ. contrastive divergence, CD).[144] ПР забезпечує наближення методу максимальної правдоподібності, який було би ідеально застосовувати при навчанні вагових коефіцієнтів ОМБ.[124][145] При навчанні однієї ОМБ уточнення вагових коефіцієнтів виконуються градієнтним підйомом за наступним рівнянням:
- .

Тут є ймовірністю видимого вектора, що задається як . є статистичною сумою (що застосовується для нормалізації), а є функцією енергії, призначеної станові мережі. Нижча енергія показує, що мережа знаходиться в „бажанішій“ конфігурації. Градієнт має простий вигляд , де представляє середні значення по відношенню до розподілу . Проблема виникає у вибірці , оскільки це вимагає виконання поперемінних вибірок за Ґіббсом протягом тривалого часу. ПР замінює цей крок виконанням поперемінних вибірок Ґіббса для кроків (було емпірично показано, що значення працює добре). Після кроків робиться вибірка з даних, і ця вибірка застосовується замість . Процедура ПР працює наступним чином:[124]











- Встановити видимим вузлам значення тренувального вектора.
- Паралельно уточнити приховані вузли для даних видимих вузлів: . є сигмоїдною функцією, а є зсувом .
- Паралельно уточнити видимі вузли для даних прихованих вузлів: . є зсувом . Це називається кроком „відбудови“.
- Повторно паралельно уточнити приховані вузли для даних відбудованих видимих вузлів із застосуванням такого ж рівняння, як у кроці 2.
- Виконати уточнення вагових коефіцієнтів: .








Щойно ОМБ натреновано, поверх неї „накладається“ інша ОМБ, беручи свої входи із завершального вже натренованого рівня. Значенням нового вхідного видимого шару встановлюється тренувальний вектор, а значення вузлів уже натренованих шарів встановлюються із застосуванням поточних вагових коефіцієнтів та зсувів. Потім нова ОМБ тренується за наведеною вище процедурою. Весь цей процес повторюється до досягнення бажаного критерію зупинки.[3]
Хоча наближення ПР до максимальної правдоподібності і є дуже грубим (було показано, що ПР не слідує градієнтові будь-якої функції), було емпірично показано, що вона є ефективною в тренуванні глибинних архітектур.[124]
Згорткові глибинні мережі переконань
Нещодавнім досягненням у глибинному навчанні є застосування згорткових глибинних мереж переконань (ЗГМП, англ. convolutional deep belief networks, CDBN). ЗГМП мають структуру, дуже подібну до згорткових нейронних мереж, і тренуються подібно до глибинних мереж переконань. Таким чином, вони використовують двовимірну структуру зображень, як це роблять ЗНМ, і використовують попереднє тренування, як глибинні мережі переконань. Вони пропонують загальну структуру, що може застосовуватися в багатьох задачах обробки зображень та сигналів. Останнім часом багато еталонних результатів на стандартних наборах зображень, таких як CIFAR,[146] було отримано із застосуванням ЗГМП.[147]
Нейронні мережі зберігання та вибірки великої пам'яті
Нейронні мережі зберігання та вибірки великої пам'яті (англ. large memory storage and retrieval, LAMSTAR)[148][149] є швидкими нейронними мережами глибинного навчання з багатьма шарами, які можуть використовувати багато фільтрів одночасно. Ці фільтри можуть бути нелінійними, стохастичними, логічними, не стаціонарними та навіть не аналітичними. Вони є біологічно натхненними, і мають неперервне навчання.
Нейронна мережа LAMSTAR може слугувати динамічною нейронною мережею в просторовій, часовій області визначення, та в обох. Її швидкість забезпечується геббовими ваговими коефіцієнтами з'єднань,[150] що слугують об'єднанню різних і, як правило, несхожих фільтрів (функцій попередньої обробки) у її численні шари, і для динамічного ранжування значимості різних шарів та функцій по відношенню до заданої задачі для глибинного навчання. Це грубо імітує біологічне навчання, що об'єднує виходи різних препроцесорів (зави́тки, сітківки тощо), кори (слухової, зорової тощо) та різних її областей. Її здатність до глибинного навчання додатково підсилюється використанням пригнічування, кореляції та її здатністю впоруватися з неповними даними, або „втраченими“ нейронами чи шарами навіть посеред завдання. Крім того, вона є повністю прозорою завдяки своїм ваговим коефіцієнтам з'єднань. Ці ваги з'єднань також уможливлюють нововведення, надмірність, і слугують ранжуванню по відношенню до завдання шарів, фільтрів та окремих нейронів.
LAMSTAR застосовували в багатьох медичних[151][152][153] та фінансових прогнозах,[154] адаптивному фільтруванні зашумленого мовлення в невідомому шумі,[155] розпізнаванні нерухомих зображень,[156][157] відео,[158] безпеці програмного забезпечення,[159] адаптивному керуванні нелінійними системами[160] та ін. У порівняльному дослідженні з розпізнавання символів LAMSTAR мала значно вищу швидкість обчислення і дещо нижчі похибки, ніж згорткова нейронна мережа на основі фільтрування функціями ReLU та максимізаційної підвибірки.[161]
Ці застосування показують занурення в аспекти даних, що є прихованими від мереж поверхневого навчання, та навіть від людських чуттів (ока, вуха), як у випадках передбачення настання подій апное уві сні,[152] електрокардіограми плоду при записі з електродів на поверхні шкіри живота матері в ранній період вагітності,[153] фінансового прогнозування[148] та сліпого фільтрування зашумленого мовлення.[155]
LAMSTAR було запропоновано 1996 року (A U.S. Patent 5 920 852 A), і розвинуто далі Даніелем Ґраупе (англ. Daniel Graupe) та Губертом Кордилевським (англ. Hubert Kordylewski) у 1997—2002 роках.[162][163][164] Видозмінену версію, відому як LAMSTAR 2, було розроблено Натаном Шнайдером (англ. Nathan C. Schneider) та Даніелем Ґраупе 2008 року.[165][166]
Глибинні машини Больцмана
Глибинна машина Больцмана (ГМБ, англ. Deep Boltzmann Machine, DBM) — це тип двійкового парного марковського випадкового поля (неорієнтованої імовірнісної графової моделі) з кількома шарами прихованих випадкових змінних. Вона є мережею симетрично спарованих випадкових двійкових вузлів. Вона складається з набору видимих вузлів та ряду шарів прихованих вузлів . З'єднань між вузлами одного й того ж рівня не існує (як і в ОМБ). Для ГМБ ймовірністю, що приписується векторові ν, є



де є наборами прихованих вузлів, а є параметрами моделі, що представляють взаємодії видимі-приховані та приховані-видимі. Якщо та , то ця мережа є добре відомою обмеженою машиною Больцмана.[167] Взаємодії є симетричними, оскільки зв'язки є неорієнтованими. На противагу, в глибинній мережі переконань (ГМП) лише верхні два шари утворюють обмежену машину Больцмана (що є неорієнтованою графовою моделлю), але нижчі шари утворюють орієнтовану породжувальну модель.




Як і ГМП, ГМБ можуть навчатися складних та абстрактних внутрішніх представлень входу в таких задачах, як розпізнавання об'єктів та мовлення, використовуючи обмежені мічені дані для тонкого налаштування представлення, побудованого з використанням великої поставки немічених вхідних сенсорних даних. Одначе, на відміну від ГМП та глибинних згорткових нейронних мереж, вони приймають на озброєння висновування та процедуру тренування в обох напрямках, на спадному та висхідному проходах, що дозволяє ГМБ краще розкривати представлення неоднозначних та складних вхідних структур.[168][169]
Проте швидкість ГМБ обмежує їхню продуктивність та функційність. Оскільки навчання точної максимальної правдоподібності є для ГМБ непіддатливим, ми можемо виконувати навчання наближеної максимальної правдоподібності. Іншим варіантом є застосовування висновування осередненого поля (англ. mean-field inference) для оцінки залежних від даних очікувань, і наближення очікуваної достатньої статистики моделі застосуванням методів Монте-Карло марковських ланцюгів (МКМЛ).[167] Це наближене висновування, що мусить бути здійснено для кожного перевірного входу, є у від 25 до 50 разів повільнішим за єдиний висхідний прохід у ГМП. Це робить спільну оптимізацію вельми непрактичною для великих наборів даних, і серйозно обмежує застосування ГМБ в таких задачах як представлення ознак.[170]
Складені (знешумлювальні) автокодувальники
Ідею автокодувальника продиктовано поняттям доброго представлення. Наприклад, для класифікатора добре представлення може бути визначено як таке, що дасть ефективніший класифікатор.
Кодувальник (англ. encoder) — це детерміністське відображення , що перетворює вхідний вектор x на приховане представлення y, де , є ваговою матрицею, а b є вектором зсуву. Декодувальник (англ. decoder) відображає назад приховане представлення y на відтворений вхід z через . Весь процес автокодування є порівнянням цього відтвореного входу з оригінальним, і намаганням мінімізувати цю похибку, щоби зробити відтворене значення якомога ближчим до оригінального.




В складених знешумлювальних автокодувальниках (англ. stacked denoising auto encoders) частково спотворений вихід очищується (знешумлюється, англ. denoised). Цю ідею було представлено 2010 року Венсаном та ін.[171] разом з особливим підходом до доброго представлення, добре представлення є таким, що може бути надійно отримано зі спотвореного входу, і буде корисним для відновлення відповідного чистого входу. Неявними в цьому визначенні є наступні ідеї:
- Представлення вищого рівня є відносно стабільними й стійкими до спотворень входу;
- Необхідно виділяти ознаки, що є корисними для представлення розподілу входу.
Алгоритм складається з кількох кроків: починається з імовірнісного відображення на через , це є спотворювальним кроком. Потім спотворений вхід проходить основним процесом автокодування, і відображується на приховане представлення . З цього прихованого представлення ми можемо відтворити . На останній стадії з метою отримання z якомога ближче до неспотвореного входу виконується алгоритм мінімізації. Похибка відтворення може бути або перехресно-ентропійною втратою з афінно-сигмоїдним декодувальником, або квадратично-похибковою втратою з афінним декодувальником.[171]






Для отримання глибинної архітектури автокодувальники накладають один поверх іншого.[172] Щойно кодувальну функцію першого знешумлювального автокодувальника навчено і використано для знеспотворення входу (спотвореного входу), ми можемо тренувати наступний рівень.[171]
Щойно складений автокодувальник натреновано, його вихід може бути використано як вхід до алгоритму керованого навчання, такого як класифікатор методом опорних векторів або багатокласова логістична регресія.[171]
Глибинні складальні мережі
Однією з глибинних архітектур, що ґрунтуються на ієрархії блоків спрощених модулів нейронних мереж, є глибинна опукла мережа, представлена 2011 року.[173] Тут задача навчання вагових коефіцієнтів формулюється як задача опуклої оптимізації із розв'язком замкненого вигляду. Цю архітектуру також називають глибинною складальною мережею (ГСМ, англ. deep stacking network, DSN),[174] підкреслюючи схожість цього механізму на складене узагальнення (англ. stacked generalization).[175] Кожен блок ГСМ є простим модулем, який легко навчати сам по собі керованим чином без зворотного поширення для цілих блоків.[176]
Згідно розробки Дена та Дона,[173] кожен блок складається зі спрощеного багатошарового перцептрону (БШП) з єдиним прихованим шаром. Прихований шар h має логістичні сигмоїдальні вузли, а вихідний шар має лінійні вузли. З'єднання між цими шарами представляються ваговою матрицею U; з'єднання з вхідного до прихованого шару мають вагову матрицю W. Цільові вектори t формують стовпчики матриці T, а вектори вхідних даних x формують стовпчики матриці X. Матрицею прихованих вузлів є . Модулі тренуються по черзі, отже вагові коефіцієнти нижчого рівня W на кожному етапі є відомими. Функція виконує поелементну логістичну сигмоїдну дію. Кожен із блоків оцінює один і той самий клас кінцевих міток y, і його оцінка поєднується із первинним входом X, формуючи розширений вхід для наступного блоку. Таким чином, вхід до першого блоку містить лише первинні дані, тоді як входи блоків нижче за течією мають також і виходи попередніх блоків. Тоді навчання вагової матриці U вищого рівня при заданих вагових коефіцієнтах в мережі може бути сформульовано як задачу опуклої оптимізації:


що має розв'язок замкненого вигляду.
На відміну від інших глибинних архітектур, таких як ГМП, метою є не відкриття перетворених представлень ознак. Структура ієрархії цього типу архітектури робить паралельне тренування прямолінійним, як задачу оптимізації в пакетному режимі. В чисто розрізнювальних задачах ГСМ працюють краще за звичайні ГМП.[174]
Тензорні глибинні складальні мережі
Ця архітектура є розширенням глибинних складальних мереж (ГСМ). Вона покращує ГСМ двома важливими шляхами: вона використовує інформацію вищого порядку з коваріаційних статистик, і перетворює неопуклу задачу нижчого рівня на опуклу підзадачу вищого рівня.[177] ТГСМ використовують коваріаційні статистики даних за допомогою білінійного відображення з обох із двох окремих наборів прихованих вузлів одного й того ж рівня на передбачення, через тензор третього порядку.
Хоча розпаралелювання та масштабованість і не розглядаються серйозно в звичайних ГНМ,[178][179][180] все навчання ГСМ і ТГСМ здійснюється в пакетному режимі, уможливлюючи розпаралелювання на кластерах вузлів центральних та графічних процесорів.[173][174] Розпаралелювання дозволяє масштабувати цю конструкцію на більші (глибші) архітектури та набори даних.
Основна архітектура є придатною для різнопланових задач, таких як класифікація та регресія.
Піково-пластинні обмежені машини Больцмана
Потреба в глибинному навчанні із дійснозначними входами, як у ґаусових обмежених машинах Больцмана, вмотивовує піково-пластинні ОМБ (ппОМБ, англ. spike and slab Restricted Boltzmann machine, ssRBM), які моделюють безперервнозначні входи зі строго двійковими латентними змінними.[181] Подібно до базової ОМБ та її варіантів, піково-пластинна ОМБ є двочастковим графом, але як у ҐОМБ, видимі вузли (входи) є дійснозначними. Відмінність є в прихованому шарі, де кожен прихований вузол має змінну двійкового піку та змінну дійснозначної пластини. Пік є дискретною масою ймовірності на нулі, тоді як пластина є густиною ймовірності над безперервною областю визначення;[182] їхня суміш формує апріорне. Ці терміни походять зі статистичної літератури.[183]
Розширення ппОМБ, що називається µ-ппОМБ, забезпечує додаткові моделювальні потужності, використовуючи додаткові члени в енергетичній функції. Один із цих членів дає моделі можливість формувати умовний розподіл пікових змінних знеособленням пластинних змінних при заданому спостереженні.
Змішані ієрархічно-глибинні моделі
Змішані ієрархічно-глибинні моделі (англ. compound hierarchical-deep models, compound HD models) складають глибинні мережі з непараметричних баєсових моделей. Ознаки можуть навчатися із застосуванням таких глибинних архітектур як ГМП,[91] ГМБ,[168] глибинні автокодувальники,[184] згорткові варіанти,[185][186] ппОМБ,[182] мережі глибинного кодування,[187] ГМБ з розрідженим навчанням ознак,[188] рекурентні нейронні мережі,[189] умовні ГМП,[190] знешумлювальні автокодувальники.[191] Це забезпечує краще представлення, уможливлюючи швидше навчання та точнішу класифікацію із даними високої розмірності. Проте ці архітектури є слабкими в навчанні нововведених класів на кількох прикладах, оскільки всі вузли мережі залучено до представлення входу (розподілені представлення), і мусить бути кориговано разом (високий ступінь свободи). Обмеження ступеню свободи знижує кількість параметрів для навчання, допомагаючи навчанню нових класів з кількох прикладів. Ієрархічні баєсові (ІБ) моделі (англ. Hierarchical Bayesian (HB) models) забезпечують навчання з кількох прикладів, наприклад,[192][193][194][195][196] для комп'ютерного бачення, статистики та когнітивної науки.
Змішані ІГ-архітектури мають на меті поєднання характеристик як ІБ, так і глибинних мереж. Змішана архітектура ІПД-ГМБ, ієрархічний процес Діріхле (ІПД) як ієрархічна модель, об'єднана з архітектурою ГМБ. Вона є повністю породжувальною моделлю, узагальненою з абстрактних понять, що течуть крізь шари моделі, яка є здатною синтезувати нові приклади нововведених класів, що виглядають досить природними. Всі рівні навчаються спільно, шляхом максимізації функції внеску логарифмічної ймовірності.[197]
У ГМБ з трьома прихованими шарами ймовірністю видимого входу ν є

де є набором прихованих вузлів, а є параметрами моделі, що представляють умови симетричної взаємодії видимі-приховані та приховані-приховані.

Після того, як модель ГМБ навчено, ми маємо неорієнтовану модель, що визначає спільний розподіл . Одним із шляхів вираження того, що було навчено, є умовна модель та апріорний член .



Тут представляє умовну модель ГМБ, що може розглядатися як двошарова ГМБ, але з умовами зсуву, що задаються станами :


Глибинні кодувальні мережі
Існують переваги моделі, яка може активно уточнювати себе з контексту в даних. Глибинна кодувальна мережа (ГПКМ, англ. deep coding network, DPCN) є передбачувальною схемою кодування, в якій спадна інформація використовується для емпіричного підлаштовування апріорних, необхідних для процедури висхідного висновування засобами глибинної локально з'єднаної породжувальної моделі. Це працює шляхом виділяння розріджених ознак зі спостережень, що змінюються в часі, із застосуванням лінійної динамічної моделі. Потім для навчання інваріантних представлень ознак застосовується стратегія агрегування (англ. pooling). Ці блоки складаються разом, щоби сформувати глибинну архітектуру, і тренуються жадібним пошаровим спонтанним навчанням. Шари утворюють щось на зразок марковського ланцюга, такого, що стани на будь-якому шарі залежать лише від наступного та попереднього шарів.
Глибинна передбачувальна кодувальна мережа (ГПКМ, англ. Deep predictive coding network, DPCN)[198] передбачує представлення шару, використовуючи спадний підхід із застосуванням інформації з верхнього шару та тимчасових залежностей з попередніх станів.
ГПКМ можливо розширити таким чином, щоби утворити згорткову мережу.[198]
Глибинні Q-мережі
Глибинна Q-мережа (англ. deep Q-network, DQN) — це тип моделі глибинного навчання, розроблений в Google DeepMind, який поєднує глибинну згорткову нейронну мережу з Q-навчанням, різновидом навчання з підкріпленням. На відміну від раніших агентів навчання з підкріпленням, глибинні Q-мережі можуть навчатися безпосередньо з сенсо́рних входів високої розмірності. Попередні результати було представлено 2014 року, а саму працю опубліковано 2015 року в Nature.[199] Обговорюване в цій праці застосування обмежувалося грою в ігри Atari 2600, але значення для інших потенційних застосувань є глибоким.
Мережі з пам'яттю
Поєднання зовнішньої пам'яті зі штучними нейронними мережами бере свій початок у ранніх дослідженнях розподілених представлень[200] та самоорганізаційних відображень. Наприклад, у розрідженій розподіленій пам'яті та ієрархічній часовій пам'яті зразки, закодовані нейронними мережами, використовуються як адреси для асоціативної пам'яті, з «нейронами», що по суті слугують шифраторами та дешифраторами адреси.
Диференційовні структури пам'яті, пов'язані з ДКЧП
Окрім довгої короткочасної пам'яті (ДКЧП), диференційовну пам'ять до рекурентних функцій також додали й інші підходи 1990-х та 2000-х років. Наприклад:
- Диференційовні дії проштовхування та виштовхування для мереж альтернативної пам'яті, що називаються нейронними стековими машинами (англ. neural stack machines)[201][202]
- Мережі пам'яті, в яких зовнішнє диференційовне сховище керівної мережі знаходиться у швидких вагових коефіцієнтах іншої мережі[203]
- «Забувальні вентилі» ДКЧП[204]
- Автореферентні рекурентні нейронні мережі (РНМ) з особливими вихідними вузлами для адресування та швидкого маніпулювання кожним із власних вагових коефіцієнтів РНМ на диференційовний манір (внутрішнє сховище)[205][206]
- Навчання перетворення з необмеженою пам'яттю[207]
Семантичне хешування
Підходи, які представляють попередній досвід безпосередньо, і використовують схожий досвід для формування локальної моделі, часто називають методами найближчого сусіда або k найближчих сусідів.[208] Зовсім недавно було показано, що глибинне навчання є корисним у семантичному хешуванні (англ. semantic hashing),[209] де з великого набору документів отримується глибинна графова модель векторів кількостей слів.[210] Документи відображуються на комірки пам'яті таким чином, що семантично схожі документи розташовуються за близькими адресами. Потім документи, схожі на документ із запиту, можна знаходити шляхом простого доступу до всіх адрес, що відрізняються від адреси документа із запиту лише кількома бітами. На відміну від розрідженої розподіленої пам'яті, що оперує 1000-бітними адресами, семантичне хешування працює на 32- або 64-бітних адресах, на яких ґрунтується традиційна комп'ютерна архітектура.
Нейронні машини Тюрінга
Нейронні машини Тюрінга (англ. Neural Turing machines),[211] розроблені в Google DeepMind, спаровують мережі ДКЧП із зовнішніми ресурсами пам'яті, з якими вони можуть взаємодіяти за допомогою процесів уваги (англ. attentional processes). Ця зв'язана система є аналогічною машині Тюрінга, але є диференційовною з краю в край, що дозволяє їй дієво навчатися градієнтним спуском. Попередні результати показують, що нейронні машини Тюрінга можуть виводити з прикладів входу та виходу прості алгоритми, такі як копіювання, впорядкування та асоціативне пригадування.
Мережі з пам'яттю
Мережі з пам'яттю (англ. memory networks)[212][213] є іншим розширенням нейронних мереж, що включає довготривалу пам'ять, розроблену командою дослідників Facebook. Довготривала пам'ять може читатися або записуватися з метою використання її для передбачення. Ці моделі застосовувалися в контексті питально-відповідальних систем (англ. question answering, QA), де довготривала пам'ять ефективно діє як (динамічна) база знань, а вихід є текстовою відповіддю.[214]
Вказівникові мережі
Глибинні мережі може бути потенційно поліпшено, якщо вони стануть глибшими та матимуть менше параметрів, зберігаючи здатність до навчання. В той час як тренування надзвичайно глибоких (наприклад, завглибшки в мільйон шарів) нейронних мереж може бути практично нездійсненним, ЦП-подібні архітектури, такі як вказівникові мережі (англ. pointer networks)[215] та нейронні машини з довільним доступом (англ. neural random-access machines),[216] розроблені дослідниками з Google Brain, долають це обмеження завдяки застосуванню зовнішньої пам'яті з довільним доступом, а також додаванню інших складових, що зазвичай належать до комп'ютерної архітектури, таких як регістри, АЛП та вказівники. Такі системи працюють на векторах розподілів імовірностей, що зберігаються в комірках пам'яті та регістрах. Таким чином, ця модель є повністю диференційовною, й тренується з краю в край. Ключовою характеристикою цих моделей є те, що їхня глибина, розмір їхньої короткочасної пам'яті та їхня кількість параметрів можуть змінюватися незалежно — на відміну від моделей на кшталт ДКЧП, чия кількість параметрів зростає квадратично з розміром пам'яті.
Кодувально-декодувальні мережі
Кодувально-декодувальна схема (англ. encoder–decoder framework) є схемою на основі нейронних мереж, спрямованою на відображення високоструктурованого входу на високоструктурований вихід. Її було запропоновано нещодавно в контексті машинного перекладу,[217][218][219] де вхід та вихід є писаними реченнями двома природними мовами. В тій праці рекурентна нейронна мережа] (РНМ) або згорткова нейронна мережа (ЗНМ) з ДКЧП використовувалася як кодувальник для отримання зведення про вхідне речення, і це зведення декодувалося умовною РНМ-моделлю мови (англ. recurrent neural network language model, RNN-LM) для продукування перекладу.[220] Всі ці системи мають однакові будівельні блоки: вентильні (англ. gated) РНМ та ЗНМ, і треновані механізми уваги.
Інші архітектури
Багатошарова ядрова машина
Багатошарові ядрові машини (БЯМ, англ. Multilayer Kernel Machine, MKM), як представлено в [221], є способом навчання високо нелінійних функцій за допомогою ітеративного застосування слабко нелінійних ядер. Вони використовують ядровий метод головних компонент (ЯМГК, англ. kernel principal component analysis, KPCA), у [222], як метод для спонтанного жадібного пошарового передтренувального кроку архітектури глибинного навчання.
-й шар навчається представлення попереднього шару , виділяючи головних компонент (ГК, англ. principal component, PC) проекції в область визначення ознак шару , виведеної ядром. Заради зниження в кожному шарі розмірності уточненого представлення пропонується керована стратегія для вибору найінформативніших ознак серед виділених ЯМГК. Цей процес є таким:



- вишикувати ознаки відповідно до їхньої взаємної інформації з мітками класів;
- для різних значень K та обчислити похибку класифікації методом K найближчих сусідів, використовуючи лише найінформативніших ознак на затверджувальному наборі;
- значення , з яким класифікатор досяг найнижчого рівня похибки, визначає кількість ознак для збереження.


Застосування ЯМГК як будівельних блоків для БЯМ має деякі недоліки.
Дослідниками Microsoft для застосувань у розумінні усного мовлення було розроблено простіший спосіб застосування ядрових машин до глибинної архітектури.[223] Головна ідея полягає у використанні ядрової машини для наближення поверхневої нейронної мережі з нескінченною кількістю прихованих вузлів, і подальшому застосуванні складання для зрощування виходу ядрової машини та сирого входу при побудові наступного, вищого рівня ядрової машини. Кількість рівнів у цій глибинній опуклій мережі є гіперпараметром системи в цілому, який повинен визначатися перехресною перевіркою.
Застосування
Автоматичне розпізнавання мовлення
В розпізнаванні мовлення було вчинено революцію глибинним навчанням, особливо довгою короткочасною пам'яттю (ДКЧП), рекурентною нейронною мережею, опублікованою Зеппом Хохрайтером та Юргеном Шмідгубером 1997 року.[53] РНМ ДКЧП обходить проблему зникання градієнту, і може навчатися задач «дуже глибокого навчання»,[5] які включають події мовлення, розділені тисячами дискретних кроків часу, коли один крок часу відповідає близько 10 мс. 2003 року ДКЧП із забувальними вентилями (англ. forget gates)[107] в деяких задачах стала конкурентоспроможною в порівнянні з традиційними розпізнавачами мовлення.[54] 2007 року ДКЧП, тренована нейромережевою часовою класифікацією (НЧК, англ. Connectionist Temporal Classification, CTC),[55] досягла відмінних результатів у деяких застосуваннях,[56] хоча комп'ютери тоді були значно повільнішими за сьогоднішні. 2015 року велике розпізнавання мовлення Google раптом майже подвоїло свою продуктивність через ДКЧП, треновані НЧК, і тепер є доступною користувачам усіх смартфонів.[57]
В таблиці нижче наведено результати автоматичного розпізнавання мовлення на популярному англомовному наборі даних TIMIT. Він є звичайним набором даних, що застосовується для початкових оцінок архітектур глибинного навчання. Набір у цілому включає 630 мовців з восьми основних діалектів американської англійської, де кожен мовець читає 10 різних речень.[224] Його невеликий розмір дозволяє ефективно випробовувати багато конфігурацій. Що ще важливіше, задача TIMIT розглядає розпізнавання фональних послідовностей, що, на відміну від розпізнавання словесних послідовностей, дозволяє дуже слабкі «мовні моделі», і відтак спрощує аналіз слабкостей аспектів акустичного моделювання розпізнавання мовлення. Такий аналіз на TIMIT Лі Дена зі співробітниками близько 2009—2010 років, протиставляючи моделі ҐСМ (та інших породжувальних моделей мовлення) з ГНМ, стимулював ранні промислові інвестиції в глибинне навчання для розпізнавання мовлення від малих до великих масштабів,[50][70] зрештою привівши до поширеного та домінантного застосування в цій галузі. Цей аналіз було здійснено з порівнянною ефективністю (менше 1.5 % в рівні похибок) між розрізнювальними ГНМ та породжувальними моделями. Перелічені нижче рівні похибок, включно з цими ранніми результатами, виміряні як рівень фональних похибок (РФП, англ. phone error rates, PER), було узагальнено за проміжок часу крайніх 20 років:
| Метод | РФП (%) |
|---|---|
| РНМ з випадковими початковими значеннями | 26.1 |
| Баєсова трифональна ҐСМ-ПММ | 25.6 |
| Модель прихованої траєкторії (породжувальна) | 24.8 |
| Монофональна ГНМ з випадковими початковими значеннями | 23.4 |
| Монофональна ГМП-ГНМ | 22.4 |
| Трифональна ҐСМ-ПММ з тренуванням ПМВІ | 21.7 |
| Монофональна ГМП-ГНМ на блоці фільтрів | 20.7 |
| Згорткова ГНМ[225] | 20.0 |
| Згорткова ГНМ з різнорідним агрегуванням | 18.7 |
| Ансамблева ГНМ/ЗНМ/РНМ[226] | 18.2 |
| Двоспрямована ДКЧП | 17.9 |
2010 року промислові дослідники розширили глибинне навчання з TIMIT до великого словникового розпізнавання мовлення, пристосувавши великі вихідні шари ГНМ на основі станів контекстно-залежних ПММ, побудованих деревами рішень.[227][228] Усебічні огляди цієї розробки та положення справ станом на жовтень 2014 року подано в недавній книзі видавництва Springer від Microsoft Research.[71] У ранішій статті [229] було зроблено огляд обстановки в автоматичному розпізнаванні мовлення та впливі різних парадигм машинного навчання, включно із глибинним навчанням.
Одним із основоположних принципів глибинного навчання є покінчити з ручним конструюванням ознак, і використовувати сирі ознаки. Цей принцип було вперше успішно досліджено в архітектурі глибинного автокодувальника на «сирій» спектрограмі або ознаках лінійного блока фільтрів,[230] що показало його перевагу над мел-кепстровими ознаками, які містять мало етапів незмінного перетворення зі спектрограм. Зовсім недавно було показано, що «справжні» ознаки мовлення, хвилеформи, дають відмінні результати результати у великомасштабному розпізнаванні мовлення.[231]
З моменту початкового успішного дебюту ГНМ у розпізнаванні мовлення близько 2009—2011 років та ДКЧП близько 2003—2007 років, було здійснено величезні нові зрушення. Прогрес (та майбутні напрямки) може бути зведено у вісім основних областей:[2][52][71]
- Масштабування вгору/назовні та прискорення тренування ГНМ та декодування;
- Послідовнісно розрізнювальне тренування ГНМ;
- Обробка ознак глибинними моделями з цілісним розумінням механізмів, що лежать в їх основі;
- Пристосування ГНМ та споріднених глибинних моделей;
- Багатозадачне навчання та передавальне навчання ГНМ і спорідненими глибинними моделями;
- Згорткові нейронні мережі, та як проектувати їх для найкращого використання знань про область мовлення;
- Рекурентна нейронна мережа та її цінні ДКЧП-варіанти;
- Інші типи глибинних моделей, включно з моделями на основі тензорів та комбінованими породжувально/розрізнювальними моделями.
Великомасштабне автоматичне розпізнавання мовлення є першим і найпереконливішим прикладом застосування глибинного навчання в недавній історії, що використовується як в промисловості, так і в науці, в усіх напрямках. Між 2010 та 2014 роками дві важливі конференції з обробки сигналів та розпізнавання мовлення, IEEE-ICASSP та Interspeech, побачили значне збільшення кількостей прийнятих праць серед усіх праць на цих конференціях за рік на тему глибинного навчання для розпізнавання мовлення. Що ще важливіше, всі важливі комерційні системи розпізнавання мовлення (наприклад, Microsoft Cortana, Xbox, Перекладач Skype, Amazon Alexa, Google Now, Apple Siri, голосовий пошук Baidu та iFlyTek та ряд мовленневих продуктів Nuance тощо) ґрунтуються на моделях глибинного навчання.[2][232][233][234] Див. також нещодавнє інтерв'ю ЗМІ з технічним директором Nuance Communications.[235]
Розпізнавання зображень
Звичайним набором для оцінки класифікації зображення є набір даних MNIST. Він складається з рукописних цифр, і включає 60 000 тренувальних зразків та 10 000 перевіркових зразків. Як і в TIMIT, його малий розмір дозволяє перевіряти кілька конфігурацій. Повний перелік результатів на цьому наборі можна знайти в [236]. Поточним найкращим результатом на MNIST є рівень похибки 0.23 %, досягнений Чирешаном та ін. 2012 року.[237]
Згідно ЛеКуна,[68] на початку 2000-х років у промисловому застосуванні ЗНМ вже обробляли приблизно від 10 % до 20 % усіх перевірок, написаних у США на початку 2000-х років. Значний додатковий вплив глибинного навчання в розпізнаванні зображень або об'єктів відчувся в 2011—2012 роках. І хоча ЗНМ, треновані зворотним поширенням, займали помітне місце десятиріччями,[34] а реалізації НМ, включно із ЗНМ,[74] на ГП — роками, знадобилися швидкі реалізації на ГП ЗНМ з максимізаційними підвибірками в стилі Дена Чирешана з колегами,[95] щоби зробити зарубку на комп'ютерному баченні.[5] 2011 року цей підхід вперше досяг надлюдської продуктивності у змаганні з розпізнавання візуальних образів.[97] Також 2011 року він переміг у змаганні ICDAR з розпізнавання китайського рукописного тексту, а в травні 2012 року переміг у змаганні ISBI з сегментування зображень.[98] До 2011 року ЗНМ не відігравали провідної ролі на конференціях із комп'ютерного бачення, але в червні 2012 року праця Дена Чирешана та ін. на провідній конференції CVPR[100] показала, як різко максимізаційно-підвибіркові ЗНМ на ГП можуть покращити багато еталонних рекордів бачення, іноді з порівняною з людською, або навіть із надлюдською продуктивністю. В жовтні 2012 року подібна система Алекса Крижевського в команді Джефа Хінтона[99] виграла великомасштабне змагання ImageNet зі значним відривом від методів поверхневого машинного навчання. В листопаді 2012 року система Чирешана та ін. також виграла змагання ICPR з аналізу великих медичних зображень для виявлення раку, а наступного року також і MICCAI Grand Challenge з цього ж предмету.[238] В 2013 та 2014 роках рівень похибки на задачі ImageNet із застосуванням глибинного навчання було швидко додатково скорочено, слідом за подібною тенденцією у великомасштабному розпізнаванні мовлення.
Як і в амбітному русі від автоматичного розпізнавання мовлення до його автоматичного перекладу та розуміння, класифікацію зображень нещодавно було розширено до складнішої задачі опису зображень, в якій глибинне навчання (часто як поєднання ЗНМ та ДКЧП) є важливою підлеглою технологією.[239][240][241][242]
Одним із прикладів застосування є автомобільний комп'ютер, нібито натренований глибинним навчанням, який може дозволити автомобілям інтерпретувати зображення з 360-градусних камер.[243] Іншим прикладом є технологія, відома як новітній аналіз у лицевій дисморфології (англ. Facial Dysmorphology Novel Analysis, FDNA), що застосовується для аналізу випадків пороків розвитку в людей, пов'язаного з великою базою даних генетичних синдромів.
Обробка природної мови
Нейронні мережі застосовуються для реалізації моделей мов з початку 2000-х років.[108][244] Рекурентні нейронні мережі, особливо ДКЧП,[53] підходять найкраще для послідовних даних, таких як мова. ДКЧП допомогла поліпшити машинний переклад[109] та моделювання мов.[110][111] ДКЧП у поєднанні з ЗНМ також поліпшили автоматичний опис зображень[142] та безліч інших застосувань.[5]
Іншими ключовими методиками в цій області є негативна вибірка[245] та векторне представлення слів. Векторне представлення слів, таке як word2vec, може розглядатися як шар представлення в архітектурі глибинного навчання, що перетворює атомарне слово в представлення розташування слова відносно інших слів у наборі даних; це положення представляється точкою в векторному просторі. Використання векторного представлення слів як вхідного шару для рекурентної нейронної мережі (РНМ) уможливлює навчання цієї мережі розбору речень та фраз із застосуванням ефективної композиційної векторної граматики. Композиційна векторна граматика може розглядатися як імовірнісна контекстно-вільна граматика (ІКВГ, англ. probabilistic context free grammar, PCFG), реалізована рекурентною нейронною мережею.[246] Рекурентні автокодувальники, побудовані поверх векторного представлення слів, було натреновано для оцінки схожості речень та виявлення перефразувань.[246] Глибинні нейронні архітектури досягли передових результатів у багатьох задачах обробки природної мови, таких як розбір складників,[247] аналіз тональності,[248] отримання інформації,[249][250] розуміння усного мовлення,[251] машинний переклад,[109][252] контекстне зв'язування об'єктів[253] та інших.[254]
Пошук нових ліків та токсикологія
Фармацевтична промисловість стикається з проблемою, що великому відсоткові ліків-кандидатів не вдається вийти на ринок. Ці невдачі хімічних сполук спричинено недостатньою дієвістю на біомолекулярну ціль (цільовий вплив), невиявленою та небажаною взаємодією з іншими біомолекулами (позацільові впливи) або непередбаченими токсичними впливами.[255][256] 2012 року команда під проводом Джорджа Даля виграла «Merck Molecular Activity Challenge», використовуючи багатозадачні глибинні нейронні мережі для передбачення біомолекулярної цілі сполуки.[257][258] 2014 року група Зеппа Хохрайтера використала глибинне навчання для виявлення позацільових та токсичних впливів хімікатів навколишнього середовища в поживних речовинах, побутових виробах та ліках, і виграла «Tox21 Data Challenge» Національного інституту охорони здоров'я США, FDA та NCATS.[259][260] Ці вражаючі успіхи показують, що глибинне навчання може бути кращим за інші методи віртуального скринінгу[261][262]. Дослідники з Google та Стенфорда посилили глибинне навчання для пошуку нових ліків шляхом об'єднання даних з різних джерел.[263] 2015 року Atomwise представила AtomNet, перші нейронні мережі глибинного навчання для раціональної розробки ліків на основі структури.[264] Згодом AtomNet було використано для передбачення новітніх кандидатур біомолекул для цілей деяких хвороб, передусім для лікування вірусу Ебола та розсіяного склерозу.[265][266]
Управління відносинами з клієнтами
Нещодавно було повідомлено про успіх застосування глибинного навчання з підкріпленням в середовищі прямого маркетингу, що ілюструє придатність цього методу для автоматизації CRM (управління відносинами з клієнтами, англ. customer relationship management). Нейронна мережа використовувалася для наближення цінності можливих дій прямого маркетингу над простором станів клієнтів, визначеного в термінах змінних RFM (свіжість-частота-грошова цінність, англ. recency-frequency-monetary value). Було показано, що функція оціненого значення має природну інтерпретацію як пожиттєва цінність клієнта (англ. customer lifetime value, CLV).[267]
Рекомендаційні системи
Рекомендаційні системи використовували глибинне навчання для виділяння значущих глибинних ознак для моделі латентних факторів для рекомендування музики на основі вмісту.[268] Нещодавно було представлено загальніший підхід для навчання уподобань користувача з кількох областей із застосуванням багатовиглядового глибинного навчання (англ. mulitview deep learning).[269] Ця модель застосовує гібридний спільний та оснований на вмісті підхід, і покращує рекомендації в багатьох задачах.
Біоінформатика
Нещодавно підхід глибинного навчання на основі автокодувальної штучної нейронної мережі було застосовано в контексті біоінформатики для передбачення анотацій онтології гена та співвідношень ген-функція.[270]
Теорії людського мозку
Обчислювальне глибинне навчання тісно пов'язане з класом теорій розвитку мозку (особливо розвитку нової кори), запропонованих когнітивними нейробіологами на початку 1990-х років.[271] Доступним зведенням цієї праці є книга 1996 року Ельмана та ін. «Rethinking Innateness»[272] (див. також Шрагера та Джонсона,[273] Кварца та Сейновського[274]). Оскільки ці теорії розвитку також ілюструвалися обчислювальними моделями, вони є технічними попередниками чисто обчислювально обґрунтованих моделей глибинного навчання. Ці розвиткові моделі мають таку цікаву спільну властивість, що різні запропоновані динаміки навчання в мозку (наприклад, хвиля чинника росту нервів) ніби влаштовують змову слугувати доказом способу самоорганізації якогось виду споріднених з ними штучних нейронних мереж, які знайшли застосування пізніше, чисто обчислювальних моделей глибинного навчання; і такі обчислювальні нейронні мережі здаються аналогічними поглядові на нову кору мозку як на ієрархію фільтрів, у якій кожен шар схоплює частину інформації робочого середовища, а потім передає залишок, як і видозмінений основний сигнал, іншим шарам далі вище за ієрархією. Цей процес породжує самоорганізовувану стопку вимірювальних перетворювачів, добре підлаштованих до їхнього робочого середовища. Як описано в Нью-Йорк Таймс 1995 року, «… мозок немовляти, здається, самоорганізовує себе під впливом хвиль так званих чинників росту … різні області мозку стають з'єднаними послідовно, з дозріванням одного шару тканини перед іншим, і так далі, поки не стане дозрілим увесь мозок.»[275]
Важливість глибинного навчання по відношенню до еволюції та розвитку людського пізнання не вислизнула від уваги цих дослідників. Одним із аспектів людського розвитку, що відрізняє нас від наших найближчих сусідів-приматів, можуть бути зміни в хронометражі розвитку.[276] Серед приматів людський мозок залишається відносно пластичним аж до пізнього післяпологового періоду, в той час як мізки наших найближчих родичів є повніше сформованими за народження. Таким чином, люди мають ширший доступ до складних переживань, уможливлених знаходженням назовні в світі під час найформувальнішого періоду розвитку мозку. Це може дозволяти нам «налаштовуватися» на швидко змінювані ознаки середовища, які інші тварини, більш обмежені еволюційним структуруванням їхніх мізків, враховувати не в змозі. В тій мірі, в якій ці зміни відображаються в змінах подібних етапів хронометражу гіпотетичної хвилі розвитку пізнання, вони можуть призводити і до змін у виділянні інформації з простору збудників під час ранньої самоорганізації мозку. Звісно, разом із цією гнучкістю йде й подовжений період незрілості, протягом якого ми залежимо від наших опікунів та нашої спільноти як у плані підтримки, так і в плані навчання. Тому теорія глибинного навчання розглядає співеволюцію культури та пізнання як фундаментальну умову еволюції людини.[277]
Комерційна діяльність
Глибинне навчання часто представляють як крок назустріч реалізації сильного штучного інтелекту,[278] і відтак багато організацій стали зацікавленими в його практичному застосуванні. В грудні 2013 року компанія Facebook найняла Яна ЛеКуна, щоби він очолив її нову лабораторію штучного інтелекту (ШІ, англ. artificial intelligence, AI), яка мала діяти в Каліфорнії, Лондоні та Нью-Йорку. Лабораторія ШІ розроблятиме методики глибинного навчання, щоби допомогти Facebook виконувати такі задачі як автоматичне мічення завантажених зображень іменами людей на них.[279] Наприкінці 2014 року Facebook також найняла Володимира Вапника, головного розробника теорії статистичного навчання Вапника — Червоненкіса та співавтора методу опорних векторів.[280]
В березні 2013 року компанія Google найняла Джефрі Хінтона та двох його аспірантів, Алекса Крижевського та Іллю Суцкевера. Їхня праця мала зосереджуватися на вдосконаленні наявних продуктів машинного навчання в Google та на допомозі впоратися з наростаючою кількістю даних, що має Google. Google також придбала компанію Хінтона, DNNresearch.
2014 року Google також придбала DeepMind Technologies, британський стартап, що розробив систему, здатну навчатися грати у відеоігри Atari, використовуючи як вхідні дані лише сирі пікселі. 2015 року вони продемонстрували систему AlphaGo, яка успішно виконала один із давніх «великих викликів» ШІ, навчившись грі в Ґо достатньо добре, щоби бити професійного людського гравця.[281][282][283]
Також 2014 року Microsoft заснувала Центр технологій глибинного навчання (англ. The Deep Learning Technology Center) у своєму підрозділі MSR, накопичуючи фахівців з глибинного навчання для діяльності, зосередженої на застосуваннях.
Baidu найняла Ендрю Ина, щоби він очолив її нову дослідницьку лабораторію в Кремнієвій долині, зосереджену на глибинному навчанні.
2015 року Blippar продемонструвала новий мобільний додаток доповненої реальності, який застосовує глибинне навчання для розпізнавання об'єктів у реальному часі.[284]
Критика та коментарі
Враховуючи далекосяжні наслідки штучного інтелекту в поєднанні з усвідомленням того, що глибинне навчання стає однією з його найпотужніших методик, цей предмет зрозуміло притягує як критику, так і коментарі, й у деяких випадках з-поза меж області самої інформатики.
Основна критика глибинного навчання полягає у відсутності теорії навколо багатьох із його методів. Навчання в найпоширеніших глибинних архітектурах реалізовано із застосуванням градієнтного спуску. В той час як найшвидший спуск був зрозумілим протягом якогось часу й раніше, теорія, що оточує інші алгоритми, такі як порівняльна розбіжність, є менш ясною (тобто, Чи він сходиться? Якщо так, то як швидко? Що він наближує?). Методи глибинного навчання часто розглядаються як чорна скринька, при цьому більшість підтверджень здійснюються емпірично, а не теоретично.
Інші вказують на те, що глибинне навчання слід розглядати як крок до реалізації сильного штучного інтелекту, а не як всеохоплювальне рішення. Незважаючи на потужність методів глибинного навчання, їм все ще бракує більшості функціональності, необхідної для повної реалізації цієї мети. Дослідний психолог Ґері Маркус зазначив, що
| Правдоподібно, що глибинне навчання є лише частиною масштабнішого завдання побудови розумних машин. Таким методикам бракує способів представлення причинних зв'язків (…) вони не мають очевидних способів здійснення логічних висновків, і вони також все ще далекі від поєднання абстрактних знань, таких як інформація про те, чим об'єкти є, для чого вони є, і як вони зазвичай використовуються. Найпотужніші системи ШІ, такі як Watson (…) використовують такі методики як глибинне навчання лише як один з елементів у дуже складному ансамблі методик, починаючи зі статистичної методики баєсового висновування, і аж до дедуктивного міркування.[285]
Оригінальний текст (англ.) Realistically, deep learning is only part of the larger challenge of building intelligent machines. Such techniques lack ways of representing causal relationships (…) have no obvious ways of performing logical inferences, and they are also still a long way from integrating abstract knowledge, such as information about what objects are, what they are for, and how they are typically used. The most powerful A.I. systems, like Watson (…) use techniques like deep learning as just one element in a very complicated ensemble of techniques, ranging from the statistical technique of Bayesian inference to deductive reasoning. |
В тій мірі, в якій така точка зору ненавмисно припускає, що глибинне навчання в кінцевому підсумку становитиме не щось більше за примітивні описові рівні майбутнього всеосяжного машинного інтелекту, нещодавня пара міркувань стосовно мистецтва та штучного інтелекту[286] пропонує альтернативне та ширше бачення. Перше таке міркування полягає в тім, що може бути можливим натренувати стек машинного бачення для виконання витонченого завдання розрізнювання між картинами «великого майстра» та аматора; а друге — в тім, що така чутливість може фактично представляти рудименти нетривіальної машинної емпатії. Більше того, висунуто припущення, що така гіпотетична подія відповідатиме антропології, яка визначає питання естетики ключовим елементом поведінкової сучасності (наприклад, у [287]).
Серед подальших відсилань до тієї ідеї, що значна міра художньої чутливості може належати відносно низьким рівням ієрархії пізнання, чи то біологічним, чи то цифровим, схоже, що опублікований ряд графічних представлень внутрішніх станів глибинних (20-30 шарів) нейронних мереж, які намагаються розгледіти серед по суті випадкових даних зображення, на яких їх було треновано,[288] демонструє дивовижну візуальну привабливість, у світлі видатного рівня суспільної уваги, привернутого цією працею; первинне повідомлення про це дослідження отримало набагато більше за тисячу коментарів, а репортаж Гардіан[289] протягом певного часу був найвідвідуванішою статтею на сайті цієї газети.
Деякі наразі популярні та успішні архітектури глибинного навчання демонструють певні поведінкові проблеми,[290] такі як впевнена класифікація невпізна́нних зображень як належних до знайомої категорії звичайних зображень[291] та неправильна класифікація маленьких збурювань правильно класифікованих зображень.[292] Творець OpenCog, Бен Ґьорцель, висунув гіпотезу, що таку поведінку спричинено обмеженнями внутрішніх представлень, яких навчаються ці архітектури, і що ці обмеження перешкоджатимуть інтеграції цих архітектур до гетерогенних багатоскладових архітектур СШІ. Він припустив, що ці питання можна обійти шляхом розробки архітектур глибинного навчання, які формують всередині стани, гомологічні розкладам спостережуваних сутностей та подій граматиками зображень.[293][290] Навчання граматики (візуальної або мовної) з тренувальних даних буде рівноцінним обмеженню системи міркуваннями на основі здорового глузду, що оперує поняттями в термінах правил породження цієї граматики, і є основною метою як опанування людської мови,[294] так і ШІ. (Див. також виведення граматик.[295])
Програмні бібліотеки
- Caffe — Каркас глибинного навчання, який спеціалізується на розпізнаванні зображень.
- CNTK — відкритий[296] Інструментарій Обчислювальних Мереж (англ. Computational Network Toolkit) глибинного навчання від Microsoft Research.
- ConvNetJS — Бібліотека Javascript для тренування моделей глибинного навчання. Містить інтерактивні демонстрації.
- Deeplearning4j — Відкрита[297] бібліотека глибинного навчання, написана для Java, з ДКЧП та згортковими мережами, і Skymind. Забезпечує розпаралелювання із ЦП та ГП.
- Gensim — Інструментарій для обробки природної мови, реалізований мовою програмування Python.
- Keras — система глибинного навчання, здатна працювати над TensorFlow або Theano.
- neon — Neon є відкритою мовою на основі Python, створеною компанією Nervana
- NVIDIA cuDNN — Бібліотека примітивів для глибинних нейронних мереж із прискоренням на ГП.
- OpenNN — Відкрита бібліотека C++, яка реалізує глибинні нейронні мережі, та забезпечує розпаралелювання з ЦП.
- TensorFlow — Відкрита бібліотека машинного навчання Google на C++ та Python з ППІ для обох. Забезпечує розпаралелювання з ЦП та ГП.[298]
- Theano — Відкрита бібліотека машинного навчання для Python.
- Torch — Відкрита програмна бібліотека для машинного навчання на основі мови програмування Lua.
- Apache Singa — Загальна платформа розподіленого глибинного навчання (англ. General Distributed Deep Learning Platform).[299][300][301]
Графічні інструменти
- Neural Designer — застосунок з графічним інтерфейсом для глибинних нейронних мереж, що забезпечує розпаралелювання на центральному процесорі.
Див. також
- Розріджене кодування
- Стиснене сприйняття
- Конекціонізм
- Застосування штучного інтелекту
- Список проектів штучного інтелекту
- Резервуарне обчислення
- Рідкий скінченний автомат
- Мережа з відлунням стану
- Перелік наборів даних для досліджень у галузі машинного навчання
- Порівняння програмного забезпечення глибинного навчання
Примітки
- Ian Goodfellow, Yoshua Bengio, and Aaron Courville (2016). Deep Learning. MIT Press. Online (англ.)
- Deng, L.; Yu, D. (2014). Deep Learning: Methods and Applications. Foundations and Trends in Signal Processing 7 (3-4): 1–199. doi:10.1561/2000000039. (англ.)
- Bengio, Yoshua (2009). Learning Deep Architectures for AI. Foundations and Trends in Machine Learning 2 (1): 1–127. doi:10.1561/2200000006. Архів оригіналу за 4 березня 2016. Процитовано 12 грудня 2015. (англ.)
- Bengio, Y.; Courville, A.; Vincent, P. (2013). Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8): 1798–1828. arXiv:1206.5538. doi:10.1109/tpami.2013.50. (англ.)
- Schmidhuber, J. (2015). Deep Learning in Neural Networks: An Overview. Neural Networks 61: 85–117. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. (англ.)
- Bengio, Yoshua; LeCun, Yann; Hinton, Geoffrey (2015). Deep Learning. Nature 521: 436–444. doi:10.1038/nature14539. (англ.)
- Deep Machine Learning — A New Frontier in Artificial Intelligence Research — a survey paper by Itamar Arel, Derek C. Rose, and Thomas P. Karnowski. IEEE Computational Intelligence Magazine, 2013 (англ.)
- Schmidhuber, Jürgen (2015). Deep Learning. Scholarpedia 10 (11): 32832. doi:10.4249/scholarpedia.32832. (англ.)
- Carlos E. Perez. A Pattern Language for Deep Learning. (англ.)
- Glauner, P. (2015). Deep Convolutional Neural Networks for Smile Recognition (MSc Thesis). Imperial College London, Department of Computing. arXiv:1508.06535. (англ.)
- Song, H.A.; Lee, S. Y. (2013). Hierarchical Representation Using NMF. Neural Information Processing. Lectures Notes in Computer Sciences 8226. Springer Berlin Heidelberg. с. 466–473. ISBN 978-3-642-42053-5. doi:10.1007/978-3-642-42054-2_58. (англ.)
- Olshausen, B. A. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 381 (6583): 607–609. doi:10.1038/381607a0. (англ.)
- Deep Learning for Efficient Discriminative Parsing. Подія відбулася 7min 45s. (англ.)
- Gomes, L. (20 жовтня 2014). Machine-Learning Maestro Michael Jordan on the Delusions of Big Data and Other Huge Engineering Efforts. IEEE Spectrum. (англ.)
- Rina Dechter (1986). Learning while searching in constraint-satisfaction problems. University of California, Computer Science Department, Cognitive Systems Laboratory.Online (англ.)
- J. Schmidhuber., "Learning complex, extended sequences using the principle of history compression, " Neural Computation, 4, pp. 234—242, 1992. (англ.)
- Hinton, G.E. Deep belief networks. Scholarpedia 4 (5): 5947. doi:10.4249/scholarpedia.5947. (англ.)
- Balázs Csanád Csáji. Approximation with Artificial Neural Networks; Faculty of Sciences; Eötvös Loránd University, Hungary (англ.)
- Cybenko (1989). Approximations by superpositions of sigmoidal functions (PDF). Mathematics of Control, Signals, and Systems 2 (4): 303—314. doi:10.1007/bf02551274. Архів оригіналу за 10 жовтня 2015. Процитовано 14 грудня 2015. (англ.)
- Hornik, Kurt (1991). Approximation Capabilities of Multilayer Feedforward Networks. Neural Networks 4 (2): 251–257. doi:10.1016/0893-6080(91)90009-t. (англ.)
- Haykin, Simon (1998). Neural Networks: A Comprehensive Foundation, Volume 2, Prentice Hall. ISBN 0-13-273350-1. (англ.)
- Hassoun, M. (1995) Fundamentals of Artificial Neural Networks MIT Press, p. 48 (англ.)
- Murphy, K.P. (2012) Machine learning: a probabilistic perspective MIT Press (англ.)
- Hinton, G. E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. (2012). «Improving neural networks by preventing co-adaptation of feature detectors». arXiv:1207.0580 [math.LG]. (англ.)
- Ивахненко, А.Г.; Лапа, В.Г. (1965). Кибернетические предсказывающие устройства. Киев: Наукова думка. (рос.)
- Ivakhnenko, Alexey (1971). Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics (4): 364–378. (англ.)
- Jürgen Schmidhuber. My First Deep Learning System of 1991.+ Deep Learning Timeline 1960-2013. arXiv:1312.5548v1. (англ.)
- Біографія О. Г. Івахненка. Відділ інформаційних технологій індуктивного моделювання. Процитовано 30 березня 2016.
- Олексій Григорович Івахненко: Життєвий і творчий шлях ученого. До 90-річного ювілею.. Метод Групового Урахування Аргументів. Національний Інститут Стратегічних Досліджень НАН України. Процитовано 30 березня 2016. «За виданням: Олексій Григорович Івахненко: Життєвий і творчий шлях ученого / Під ред. В.С. Степашка. — Київ: МННЦ ІТС НАН України та МОНУ. — 2003. — 29 с.»
- Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 36: 193–202. doi:10.1007/bf00344251. (англ.)
- Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 6-7. (фін.)
- Griewank, Andreas (2012). Who Invented the Reverse Mode of Differentiation?. Optimization Stories, Documenta Matematica, Extra Volume ISMP (2012), 389—400. (англ.)
- P. Werbos., "Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences, " PhD thesis, Harvard University, 1974. (англ.)
- LeCun et al., "Backpropagation Applied to Handwritten Zip Code Recognition, " Neural Computation, 1, pp. 541—551, 1989. (англ.)
- Jürgen Schmidhuber (1993). Habilitation thesis, TUM, 1993. Page 150 ff demonstrates credit assignment across the equivalent of 1,200 layers in an unfolded RNN. Online
- Hinton, Geoffrey E.; Dayan, Peter; Frey, Brendan J.; Neal, Radford (26 травня 1995). The wake-sleep algorithm for unsupervised neural networks. Science 268 (5214): 1158–1161. doi:10.1126/science.7761831. (англ.)
- S. Hochreiter., "Untersuchungen zu dynamischen neuronalen Netzen, " Diploma thesis. Institut f. Informatik, Technische Univ. Munich. Advisor: J. Schmidhuber, 1991. (нім.)
- S. Hochreiter et al., "Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, " In S. C. Kremer and J. F. Kolen, editors, A Field Guide to Dynamical Recurrent Neural Networks. IEEE Press, 2001. (англ.)
- J. Weng, N. Ahuja and T. S. Huang, "Cresceptron: a self-organizing neural network which grows adaptively, " Proc. International Joint Conference on Neural Networks, Baltimore, Maryland, vol I, pp. 576—581, June, 1992. (англ.)
- J. Weng, N. Ahuja and T. S. Huang, "Learning recognition and segmentation of 3-D objects from 2-D images, " Proc. 4th International Conf. Computer Vision, Berlin, Germany, pp. 121—128, May, 1993. (англ.)
- J. Weng, N. Ahuja and T. S. Huang, "Learning recognition and segmentation using the Cresceptron, " International Journal of Computer Vision, vol. 25, no. 2, pp. 105—139, Nov. 1997. (англ.)
- Morgan, Bourlard, Renals, Cohen, Franco (1993) «Hybrid neural network/hidden Markov model systems for continuous speech recognition. ICASSP/IJPRAI» (англ.)
- T. Robinson. (1992) A real-time recurrent error propagation network word recognition system, ICASSP. (англ.)
- Waibel, Hanazawa, Hinton, Shikano, Lang. (1989) «Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech and Signal Processing.» (англ.)
- Baker, J.; Deng, Li; Glass, Jim; Khudanpur, S.; Lee, C.-H.; Morgan, N.; O'Shaughnessy, D. (2009). Research Developments and Directions in Speech Recognition and Understanding, Part 1. IEEE Signal Processing Magazine 26 (3): 75–80. doi:10.1109/msp.2009.932166. (англ.)
- Y. Bengio (1991). "Artificial Neural Networks and their Application to Speech/Sequence Recognition, " Ph.D. thesis, McGill University, Canada.(англ.)
- Deng, L.; Hassanein, K.; Elmasry, M. (1994). Analysis of correlation structure for a neural predictive model with applications to speech recognition. Neural Networks 7 (2): 331–339. doi:10.1016/0893-6080(94)90027-2. (англ.)
- Heck, L.; Konig, Y.; Sonmez, M.; Weintraub, M. (2000). Robustness to Telephone Handset Distortion in Speaker Recognition by Discriminative Feature Design. Speech Communication 31 (2): 181–192. doi:10.1016/s0167-6393(99)00077-1. (англ.)
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; Kingsbury, B. (2012). Deep Neural Networks for Acoustic Modeling in Speech Recognition — The shared views of four research groups. IEEE Signal Processing Magazine 29 (6): 82–97. doi:10.1109/msp.2012.2205597. (англ.)
- Deng, L.; Hinton, G.; Kingsbury, B. (2013). New types of deep neural network learning for speech recognition and related applications: An overview (ICASSP). (англ.)
- Keynote talk: Recent Developments in Deep Neural Networks. ICASSP, 2013 (by Geoff Hinton). (англ.)
- Keynote talk: "Achievements and Challenges of Deep Learning — From Speech Analysis and Recognition To Language and Multimodal Processing, " Interspeech, September 2014. (англ.)
- Hochreiter, Sepp; and Schmidhuber, Jürgen; Long Short-Term Memory, Neural Computation, 9(8):1735–1780, 1997 (англ.)
- Alex Graves, Douglas Eck, Nicole Beringer, and Jürgen Schmidhuber (2003). Biologically Plausible Speech Recognition with LSTM Neural Nets. 1st Intl. Workshop on Biologically Inspired Approaches to Advanced Information Technology, Bio-ADIT 2004, Lausanne, Switzerland, p. 175—184, 2004. Online (англ.)
- Alex Graves, Santiago Fernandez, Faustino Gomez, and Jürgen Schmidhuber (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural nets. Proceedings of ICML'06, pp. 369—376. (англ.)
- Santiago Fernandez, Alex Graves, and Jürgen Schmidhuber (2007). An application of recurrent neural networks to discriminative keyword spotting. Proceedings of ICANN (2), pp. 220—229. (англ.)
- Haşim Sak, Andrew Senior, Kanishka Rao, Françoise Beaufays and Johan Schalkwyk (September 2015): Google voice search: faster and more accurate. (англ.)
- Igor Aizenberg, Naum N. Aizenberg, Joos P.L. Vandewalle (2000). Multi-Valued and Universal Binary Neurons: Theory, Learning and Applications. Springer Science & Business Media. (англ.)
- Графік Google Ngram застосування виразу «deep learning», опублікований Юргеном Шмідгубером (2015) Online
- G. E. Hinton., "Learning multiple layers of representation, " Trends in Cognitive Sciences, 11, pp. 428—434, 2007. (англ.)
- http://research.microsoft.com/apps/pubs/default.aspx?id=189004 (англ.)
- L. Deng et al. Recent Advances in Deep Learning for Speech Research at Microsoft, ICASSP, 2013. (англ.)
- L. Deng, O. Abdel-Hamid, and D. Yu, A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion, ICASSP, 2013. (англ.)
- T. Sainath et al., "Convolutional neural networks for LVCSR, " ICASSP, 2013. (англ.)
- Hasim Sak and Andrew Senior and Francoise Beaufays (2014). Long Short-Term Memory recurrent neural network architectures for large scale acoustic modeling. Proceedings of Interspeech 2014. (англ.)
- Xiangang Li, Xihong Wu (2015). Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition arXiv:1410.4281 (англ.)
- Heiga Zen and Hasim Sak (2015). Unidirectional Long Short-Term Memory Recurrent Neural Network with Recurrent Output Layer for Low-Latency Speech Synthesis. In Proceedings of ICASSP, pp. 4470-4474. (англ.)
- Yann LeCun (2016). Slides on Deep Learning Online (англ.)
- D. Yu, L. Deng, G. Li, and F. Seide (2011). "Discriminative pretraining of deep neural networks, " U.S. Patent Filing. (англ.)
- NIPS Workshop: Deep Learning for Speech Recognition and Related Applications, Whistler, BC, Canada, Dec. 2009 (Organizers: Li Deng, Geoff Hinton, D. Yu). (англ.)
- Yu, D.; Deng, L. (2014). Automatic Speech Recognition: A Deep Learning Approach (Publisher: Springer). (англ.)
- IEEE (2015)http://blogs.technet.com/b/inside_microsoft_research/archive/2015/12/03/deng-receives-prestigious-ieee-technical-achievement-award.aspx (англ.)
- Oh, K.-S.; Jung, K. (2004). GPU implementation of neural networks. Pattern Recognition 37 (6): 1311–1314. doi:10.1016/j.patcog.2004.01.013. (англ.)
- Chellapilla, K., Puri, S., and Simard, P. (2006). High performance convolutional neural networks for document processing. International Workshop on Frontiers in Handwriting Recognition. (англ.)
- D. C. Ciresan et al., "Deep Big Simple Neural Nets for Handwritten Digit Recognition, " Neural Computation, 22, pp. 3207–3220, 2010. (англ.)
- R. Raina, A. Madhavan, A. Ng., "Large-scale Deep Unsupervised Learning using Graphics Processors, " Proc. 26th Int. Conf. on Machine Learning, 2009. (англ.)
- Riesenhuber, M; Poggio, T (1999). Hierarchical models of object recognition in cortex. Nature Neuroscience 2 (11): 1019–1025. doi:10.1038/14819. (англ.)
- Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel. 1989 Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation, 1(4):541–551. (англ.)
- Paul Werbos (1982). Applications of advances in nonlinear sensitivity analysis. In System modeling and optimization (pp. 762—770). Springer Berlin Heidelberg. Online (англ.)
- Griewank, Andreas and Walther, A.. Principles and Techniques of Algorithmic Differentiation, Second Edition. SIAM, 2008. (англ.)
- Henry J. Kelley (1960). Gradient theory of optimal flight paths. Ars Journal, 30(10), 947—954. Online (англ.)
- Arthur E. Bryson (1961, April). A gradient method for optimizing multi-stage allocation processes. In Proceedings of the Harvard Univ. Symposium on digital computers and their applications. (англ.)
- Stuart Dreyfus (1962). The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1), 30-45. Online (англ.)
- Stuart Dreyfus (1973). The computational solution of optimal control problems with time lag. IEEE Transactions on Automatic Control, 18(4):383–385. (англ.)
- Rumelhart, D. E., Hinton, G. E. & Williams, R. J. , «Learning representations by back-propagating errors» nature, 1974. (англ.)
- Stuart Dreyfus (1990). Artificial Neural Networks, Back Propagation and the Kelley-Bryson Gradient Procedure. J. Guidance, Control and Dynamics, 1990. (англ.)
- Graves, Alex; and Schmidhuber, Jürgen; Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks, in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.; and Culotta, Aron (eds.), Advances in Neural Information Processing Systems 22 (NIPS'22), December 7th–10th, 2009, Vancouver, BC, Neural Information Processing Systems (NIPS) Foundation, 2009, pp. 545—552 (англ.)
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. (2009). A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 31 (5): 855–868. doi:10.1109/tpami.2008.137. (англ.)
- Sven Behnke (2003). Hierarchical Neural Networks for Image Interpretation.. Lecture Notes in Computer Science 2766. Springer. (англ.)
- Smolensky, P. (1986). Information processing in dynamical systems: Foundations of harmony theory.. У D. E. Rumelhart, J. L. McClelland, & the PDP Research Group. Parallel Distributed Processing: Explorations in the Microstructure of Cognition 1. с. 194–281. (англ.)
- Hinton, G. E.; Osindero, S.; Teh, Y. (2006). A fast learning algorithm for deep belief nets. Neural Computation 18 (7): 1527–1554. PMID 16764513. doi:10.1162/neco.2006.18.7.1527. (англ.)
- Hinton, G. (2009). Deep belief networks. Scholarpedia 4 (5): 5947. doi:10.4249/scholarpedia.5947. (англ.)
- John Markoff (25 червня 2012). How Many Computers to Identify a Cat? 16,000.. New York Times. (англ.)
- Ng, Andrew; Dean, Jeff (2012). «Building High-level Features Using Large Scale Unsupervised Learning». arXiv:1112.6209. (англ.)
- D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber. Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011. (англ.)
- Martines, H.; Bengio, Y.; Yannakakis, G. N. (2013). Learning Deep Physiological Models of Affect. IEEE Computational Intelligence 8 (2): 20–33. doi:10.1109/mci.2013.2247823. (англ.)
- D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks, 2012. (англ.)
- D. Ciresan, A. Giusti, L. Gambardella, J. Schmidhuber. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. In Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe, 2012. (англ.)
- Krizhevsky, A., Sutskever, I. and Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012: Neural Information Processing Systems, Lake Tahoe, Nevada (англ.)
- D. C. Ciresan, U. Meier, J. Schmidhuber. Multi-column Deep Neural Networks for Image Classification. IEEE Conf. on Computer Vision and Pattern Recognition CVPR 2012. (англ.)
- D. J. Felleman and D. C. Van Essen, "Distributed hierarchical processing in the primate cerebral cortex, " Cerebral Cortex, 1, pp. 1-47, 1991. (англ.)
- J. Weng, "Natural and Artificial Intelligence: Introduction to Computational Brain-Mind, " BMI Press, ISBN 978-0985875725, 2012. (англ.)
- J. Weng, "Why Have We Passed `Neural Networks Do not Abstract Well'?, " Natural Intelligence: the INNS Magazine, vol. 1, no.1, pp. 13-22, 2011. (англ.)
- Z. Ji, J. Weng, and D. Prokhorov, "Where-What Network 1: Where and What Assist Each Other Through Top-down Connections, " Proc. 7th International Conference on Development and Learning (ICDL'08), Monterey, CA, Aug. 9-12, pp. 1-6, 2008. (англ.)
- X. Wu, G. Guo, and J. Weng, "Skull-closed Autonomous Development: WWN-7 Dealing with Scales, " Proc. International Conference on Brain-Mind, July 27–28, East Lansing, Michigan, pp. +1-9, 2013. (англ.)
- Szegedy, Christian, Alexander Toshev, and Dumitru Erhan. «Deep neural networks for object detection.» Advances in Neural Information Processing Systems. 2013. (англ.)
- Felix Gers, Nicholas Schraudolph, and Jürgen Schmidhuber (2002). Learning precise timing with LSTM recurrent networks. Journal of Machine Learning Research 3:115–143. (англ.)
- Felix A. Gers and Jürgen Schmidhuber. LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages. IEEE TNN 12(6):1333–1340, 2001.
- I. Sutskever, O. Vinyals, Q. Le (2014) "Sequence to Sequence Learning with Neural Networks, " Proc. NIPS. (англ.)
- Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, Yonghui Wu (2016). Exploring the Limits of Language Modeling. arXiv (англ.)
- Dan Gillick, Cliff Brunk, Oriol Vinyals, Amarnag Subramanya (2015). Multilingual Language Processing From Bytes. arXiv (англ.)
- T. Mikolov et al., "Recurrent neural network based language model, " Interspeech, 2010. (англ.)
- LeCun, Y. Gradient-based learning applied to document recognition. Proceedings of the IEEE 86 (11): 2278–2324. doi:10.1109/5.726791. (англ.)
- Eiji Mizutani, Stuart Dreyfus, Kenichi Nishio (2000). On derivation of MLP backpropagation from the Kelley-Bryson optimal-control gradient formula and its application. Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN 2000), Como Italy, July 2000. Online[недоступне посилання з травня 2019] (англ.)
- Bryson, A.E.; W.F. Denham; S.E. Dreyfus. Optimal programming problems with inequality constraints. I: Necessary conditions for extremal solutions. AIAA J. 1, 11 (1963) 2544—2550 (англ.)
- Stuart Russell; Peter Norvig. Artificial Intelligence A Modern Approach. с. 578. «The most popular method for learning in multilayer networks is called Back-propagation.» (англ.)
- Arthur Earl Bryson, Yu-Chi Ho (1969). Applied optimal control: optimization, estimation, and control. Blaisdell Publishing Company or Xerox College Publishing. с. 481. (англ.)
- Seppo Linnainmaa (1976). Taylor expansion of the accumulated rounding error. BIT Numerical Mathematics, 16(2), 146—160. (англ.)
- Paul Werbos (1974). Beyond regression: New tools for prediction and analysis in the behavioral sciences. PhD thesis, Harvard University. (англ.)
- Eric A. Wan (1993). Time series prediction by using a connectionist network with internal delay lines. In SANTA FE INSTITUTE STUDIES IN THE SCIENCES OF COMPLEXITY-PROCEEDINGS (Vol. 15, pp. 195—195). Addison-Wesley Publishing Co. (англ.)
- G. E. Hinton et al.., "Deep Neural Networks for Acoustic Modeling in Speech Recognition: The shared views of four research groups, " IEEE Signal Processing Magazine, pp. 82–97, November 2012.(англ.)
- Y. Bengio et al.., "Advances in optimizing recurrent networks, " ICASSP, 2013. (англ.)
- G. Dahl et al.., "Improving DNNs for LVCSR using rectified linear units and dropout, " ICASSP, 2013. (англ.)
- G. E. Hinton., "A Practical Guide to Training Restricted Boltzmann Machines, " Tech. Rep. UTML TR 2010—003, Dept. CS., Univ. of Toronto, 2010. (англ.)
- Huang, Guang-Bin; Zhu, Qin-Yu; Siew, Chee-Kheong (2006). Extreme learning machine: theory and applications. Neurocomputing 70 (1): 489–501. doi:10.1016/j.neucom.2005.12.126. (англ.)
- Widrow, Bernard (2013). The no-prop algorithm: A new learning algorithm for multilayer neural networks. Neural Networks 37: 182–188. doi:10.1016/j.neunet.2012.09.020.
- Ollivier, Yann; Charpiat, Guillaume (2015). «Training recurrent networks without backtracking». arXiv:1507.07680. (англ.)
- Aleksander, Igor, et al. «A brief introduction to Weightless Neural Systems.» Архівовано 7 січня 2016 у Wayback Machine. ESANN. 2009. (англ.)
- Alexey Grigorevich Ivakhnenko and V. G. Lapa and R. N. McDonough (1967). Cybernetics and forecasting techniques. American Elsevier, NY. (англ.)
- Alexey Grigorevich Ivakhnenko (1968). The group method of data handling — a rival of the method of stochastic approximation. Soviet Automatic Control, 13(3):43–55. (англ.)
- T. Kondo and J. Ueno (2008). Multi-layered GMDH-type neural network self-selecting optimum neural network architecture and its application to 3-dimensional medical image recognition of blood vessels. International Journal of Innovative Computing, Information and Control, 4(1):175–187. (англ.)
- http://ufldl.stanford.edu/tutorial/supervised/ConvolutionalNeuralNetwork/ (англ.)
- Szegedy, Christian; Liu, Wei; Jia, Yangqing; Sermanet, Pierre; Reed, Scott; Anguelov, Dragomir; Erhan, Dumitru; Vanhoucke, Vincent та ін. (2014). Going Deeper with Convolutions. Computing Research Repository. arXiv:1409.4842. (англ.)
- Goller, C.; Küchler, A. Learning task-dependent distributed representations by backpropagation through structure. Neural Networks, 1996., IEEE. doi:10.1109/ICNN.1996.548916. (англ.)
- Socher, Richard; Lin, Cliff; Ng, Andrew Y.; Manning, Christopher D. Parsing Natural Scenes and Natural Language with Recursive Neural Networks. The 28th International Conference on Machine Learning (ICML 2011). (англ.)
- Socher, Richard; Perelygin, Alex; Y. Wu, Jean; Chuang, Jason; D. Manning, Christopher; Y. Ng, Andrew; Potts, Christopher. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. EMNLP 2013. (англ.)
- Justin Bayer, Daan Wierstra, Julian Togelius, and Jürgen Schmidhuber (2009). Evolving memory cell structures for sequence learning. Proceedings of ICANN (2), pp. 755—764. (англ.)
- Santiago Fernandez, Alex Graves, and Jürgen Schmidhuber (2007). Sequence labelling in structured domains with hierarchical recurrent neural networks. Proceedings of IJCAI. (англ.)
- Awni Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, Andrew Ng (2014). Deep Speech: Scaling up end-to-end speech recognition. arXiv:1412.5567 (англ.)
- Fan, Y., Qian, Y., Xie, F., and Soong, F. K. (2014). TTS synthesis with bidirectional LSTM based recurrent neural networks. In Proceedings of Interspeech. (англ.)
- Bo Fan, Lijuan Wang, Frank K. Soong, and Lei Xie (2015). Photo-Real Talking Head with Deep Bidirectional LSTM. In Proceedings of ICASSP 2015. (англ.)
- Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan (2015). Show and Tell: A Neural Image Caption Generator. arXiv (англ.)
- Larochelle, H. An empirical evaluation of deep architectures on problems with many factors of variation. Proc. 24th Int. Conf. Machine Learning 2007: 473–480. (англ.)
- G. E. Hinton., "Training Product of Experts by Minimizing Contrastive Divergence, « Neural Computation, 14, pp. 1771—1800, 2002. (англ.)
- Fischer, A.; Igel, C. (2014). Training Restricted Boltzmann Machines: An Introduction (PDF). Pattern Recognition 47: 25–39. doi:10.1016/j.patcog.2013.05.025. Архів оригіналу за 10 червня 2015. Процитовано 20 грудня 2015. (англ.)
- Convolutional Deep Belief Networks on CIFAR-10 (англ.)
- Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations (англ.)
- D. Graupe, „Principles of Artificial Neural Networks.3rd Edition“, World Scientific Publishers, 2013. (англ.)
- D. Graupe, „ Large memory storage and retrieval (LAMSTAR) network, US Patent 5920852 A“, April 1996. (англ.)
- D. Graupe, „Principles of Artificial Neural Networks.3rd Edition“, World Scientific Publishers, 2013, pp.203-274. (англ.)
- V. P. Nigam, D. Graupe, (2004), „A neural-network-based detection of epilepsy“, „Neurological Research“, 26(1): 55-60. (англ.)
- Waxman, J.; Graupe, D.; Carley, C W. (2010). Automated prediction of apnea and hypopnea, using a LAMSTAR artificial neural network. American Journal of Respiratory and Critical Care Medicine 171 (7): 727–733. (англ.)
- Graupe, D.; Graupe, M. H.; Zhong, Y.; Jackson, R. K. (2008). Blind adaptive filtering for non-invasive extraction of the fetal electrocardiogram and its non-stationarities. Proc. Inst. Mech Eng., UK, Part H: Journal of Engineering in Medicine 222 (8): 1221–1234. doi:10.1243/09544119jeim417. (англ.)
- D. Graupe, „Principles of Artificial Neural Networks.3rd Edition“, World Scientific Publishers, 2013, pp.240-253. (англ.)
- Graupe, D.; Abon, J. (2002). A Neural Network for Blind Adaptive Filtering of Unknown Noise from Speech. Intelligent Engineering Systems Through Artificial Neural Networks 12: 683–688. (англ.)
- Homayon, S. (2015). Iris Recognition for Personal Identification Using LAMSTAR Neural Network. International Journal of Computer Science and Information Technology 7 (1). (англ.)
- D. Graupe, „Principles of Artificial Neural Networks.3rd Edition“, World Scientific Publishers», 2013, pp.253-274. (англ.)
- Girado, J. I.; Sandin, D. J.; DeFanti, T. A. (2003). Real-time camera-based face detection using amodified LAMSTAR neural network system. Proc. SPIE 5015, Applications of Artificial Neural Networks in Image Processing VIII. doi:10.1117/12.477405. (англ.)
- Venkatachalam, V; Selvan, S. (2007). Intrusion Detection using an Improved Competitive Learning Lamstar Network. International Journal of Computer Science and Network Security 7 (2): 255–263. (англ.)
- D. Graupe, M. Smollack, (2007), «Control of unstable nonlinear and nonstationary systems using LAMSTAR neural networks», Proceedings of 10th IASTED on Intelligent Control, Sect.592, 141—144. (англ.)
- D. Graupe, C. Contaldi, A. Sattiraju, (2015) «Comparison of Lamstar NN & Convolutional NN — Character Recognition». (англ.)
- Graupe, H. Kordylewski (1996). Network based on SOM (self-organizing-map) modules combined with statistical decision tools. Proc. IEEE 39th Midwest Conf. on Circuits and Systems 1: 471–475. (англ.)
- D, Graupe, H. Kordylewski, (1998), «A large memory storage and retrieval neural network for adaptive retrieval and diagnosis», International Journal of Software Engineering and Knowledge Engineering, 1998. (англ.)
- Kordylewski, H.; Graupe, D; Liu, K. A novel large-memory neural network as an aid in medical diagnosis applications. IEEE Transactions on Information Technology in Biomedicine 5 (3): 202–209. doi:10.1109/4233.945291. (англ.)
- Schneider, N.C.; Graupe (2008). A modified LAMSTAR neural network and its applications. International journal of neural systems 18 (4): 331–337. doi:10.1142/s0129065708001634. (англ.)
- D. Graupe, «Principles of Artificial Neural Networks.3rd Edition», World Scientific Publishers, 2013, p.217. (англ.)
- Hinton, Geoffrey; Salakhutdinov, Ruslan (2012). A better way to pretrain deep Boltzmann machines. Advances in Neural 3: 1–9. Архів оригіналу за 13 серпня 2017. Процитовано 24 грудня 2015. (англ.)
- Hinton, Geoffrey; Salakhutdinov, Ruslan (2009). Efficient Learning of Deep Boltzmann Machines 3. с. 448–455. Архів оригіналу за 6 листопада 2015. Процитовано 24 грудня 2015. (англ.)
- Bengio, Yoshua; LeCun, Yann (2007). Scaling Learning Algorithms towards AI 1. с. 1–41. (англ.)
- Larochelle, Hugo; Salakhutdinov, Ruslan (2010). Efficient Learning of Deep Boltzmann Machines. с. 693–700. Архів оригіналу за 14 серпня 2017. Процитовано 24 грудня 2015. (англ.)
- Vincent, Pascal; Larochelle, Hugo; Lajoie, Isabelle; Bengio, Yoshua; Manzagol, Pierre-Antoine (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. The Journal of Machine Learning Research 11: 3371–3408. (англ.)
- Dana H. Ballard (1987). Modular learning in neural networks. Proceedings of AAAI, pages 279—284. (англ.)
- Deng, Li; Yu, Dong (2011). Deep Convex Net: A Scalable Architecture for Speech Pattern Classification. Proceedings of the Interspeech: 2285–2288. (англ.)
- Deng, Li; Yu, Dong; Platt, John (2012). Scalable stacking and learning for building deep architectures. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP): 2133–2136. Архів оригіналу за 4 березня 2016. Процитовано 25 грудня 2015. (англ.)
- David, Wolpert (1992). Stacked generalization. Neural Networks 5 (2): 241–259. doi:10.1016/S0893-6080(05)80023-1. (англ.)
- Bengio, Yoshua (2009). Learning deep architectures for AI. Foundations and Trends in Machine Learning 2 (1): 1–127. doi:10.1561/2200000006. (англ.)
- Hutchinson, Brian; Deng, Li; Yu, Dong (2012). Tensor deep stacking networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 1–15: 1944–1957. doi:10.1109/tpami.2012.268. (англ.)
- Hinton, Geoffrey; Salakhutdinov, Ruslan (2006). Reducing the Dimensionality of Data with Neural Networks. Science 313: 504–507. PMID 16873662. doi:10.1126/science.1127647. (англ.)
- Dahl, G.; Yu, D.; Deng, L.; Acero, A. (2012). Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. IEEE Transactions on Audio, Speech, and Language Processing 20 (1): 30–42. doi:10.1109/tasl.2011.2134090. (англ.)
- Mohamed, Abdel-rahman; Dahl, George; Hinton, Geoffrey (2012). Acoustic Modeling Using Deep Belief Networks. IEEE Transactions on Audio, Speech, and Language Processing 20 (1): 14–22. doi:10.1109/tasl.2011.2109382. (англ.)
- Courville, Aaron; Bergstra, James; Bengio, Yoshua (2011). A Spike and Slab Restricted Boltzmann Machine. JMLR: Workshop and Conference Proceeding 15: 233–241. Архів оригіналу за 4 березня 2016. Процитовано 29 грудня 2015. (англ.)
- Courville, Aaron; Bergstra, James; Bengio, Yoshua (2011). Unsupervised Models of Images by Spike-and-Slab RBMs. Proceedings of the 28th International Conference on Machine Learning 10. с. 1–8. Архів оригіналу за 4 березня 2016. Процитовано 29 грудня 2015. (англ.)
- Mitchell, T; Beauchamp, J (1988). Bayesian Variable Selection in Linear Regression. Journal of the American Statistical Association 83 (404): 1023–1032. doi:10.1080/01621459.1988.10478694. (англ.)
- Larochelle, Hugo; Bengio, Yoshua; Louradour, Jerdme; Lamblin, Pascal (2009). Exploring Strategies for Training Deep Neural Networks. The Journal of Machine Learning Research 10: 1–40. (англ.)
- Coates, Adam; Carpenter, Blake (2011). Text Detection and Character Recognition in Scene Images with Unsupervised Feature Learning. с. 440–445. (англ.)
- Lee, Honglak; Grosse, Roger (2009). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. Proceedings of the 26th Annual International Conference on Machine Learning: 1–8. (англ.)
- Lin, Yuanqing; Zhang, Tong (2010). Deep Coding Network. Advances in Neural . . .: 1–9. Архів оригіналу за 1 серпня 2016. Процитовано 1 січня 2016. (англ.)
- Ranzato, Marc Aurelio; Boureau, Y-Lan (2007). Sparse Feature Learning for Deep Belief Networks. Advances in Neural Information Processing Systems 23: 1–8. Архів оригіналу за 4 березня 2016. Процитовано 1 січня 2016. (англ.)
- Socher, Richard; Lin, Clif (2011). Parsing Natural Scenes and Natural Language with Recursive Neural Networks. Proceedings of the 26th International Conference on Machine Learning. Архів оригіналу за 4 березня 2016. Процитовано 1 січня 2016. (англ.)
- Taylor, Graham; Hinton, Geoffrey (2006). Modeling Human Motion Using Binary Latent Variables. Advances in Neural Information Processing Systems. Архів оригіналу за 4 березня 2016. Процитовано 1 січня 2016. (англ.)
- Vincent, Pascal; Larochelle, Hugo (2008). Extracting and composing robust features with denoising autoencoders. Proceedings of the 25th international conference on Machine learning - ICML '08: 1096–1103. (англ.)
- Kemp, Charles; Perfors, Amy; Tenenbaum, Joshua (2007). Learning overhypotheses with hierarchical Bayesian models. Developmental Science 10 (3): 307–21. PMID 17444972. doi:10.1111/j.1467-7687.2007.00585.x. (англ.)
- Xu, Fei; Tenenbaum, Joshua (2007). Word learning as Bayesian inference. Psychol. Rev. 114 (2): 245–72. PMID 17500627. doi:10.1037/0033-295X.114.2.245. (англ.)
- Chen, Bo; Polatkan, Gungor (2011). The Hierarchical Beta Process for Convolutional Factor Analysis and Deep Learning. Machine Learning . . . Архів оригіналу за 22 лютого 2016. Процитовано 1 січня 2016. (англ.)
- Fei-Fei, Li; Fergus, Rob (2006). One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence 28 (4): 594–611. PMID 16566508. doi:10.1109/TPAMI.2006.79. (англ.)
- Rodriguez, Abel; Dunson, David (2008). The Nested Dirichlet Process. Journal of the American Statistical Association 103 (483): 1131–1154. doi:10.1198/016214508000000553. (англ.)
- Ruslan, Salakhutdinov; Joshua, Tenenbaum (2012). Learning with Hierarchical-Deep Models. IEEE Transactions on Pattern Analysis and Machine Intelligence 35: 1958–71. doi:10.1109/TPAMI.2012.269. (англ.)
- Chalasani, Rakesh; Principe, Jose (2013). Deep Predictive Coding Networks. с. 1–13. arXiv:1301.3541. (англ.)
- Mnih, Volodymyr (2015). Human-level control through deep reinforcement learning. Nature 518: 529–533. PMID 25719670. doi:10.1038/nature14236. (англ.)
- Hinton, Geoffrey E. «Distributed representations.» (1984) (англ.)
- S. Das, C.L. Giles, G.Z. Sun, "Learning Context Free Grammars: Limitations of a Recurrent Neural Network with an External Stack Memory, " Proc. 14th Annual Conf. of the Cog. Sci. Soc., p. 79, 1992. (англ.)
- Mozer, M. C., & Das, S. (1993). A connectionist symbol manipulator that discovers the structure of context-free languages. NIPS 5 (pp. 863—870). (англ.)
- Schmidhuber, J. (1992). Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation 4 (1): 131–139. doi:10.1162/neco.1992.4.1.131. (англ.)
- Gers, F.; Schraudolph, N.; Schmidhuber, J. (2002). Learning precise timing with LSTM recurrent networks. JMLR 3: 115–143. (англ.)
- Jürgen Schmidhuber (1993). An introspective network that can learn to run its own weight change algorithm. In Proc. of the Intl. Conf. on Artificial Neural Networks, Brighton. IEE. с. 191—195. (англ.)
- Hochreiter, Sepp; Younger, A. Steven; Conwell, Peter R. (2001). Learning to Learn Using Gradient Descent. ICANN 2130: 87–94. (англ.)
- Grefenstette, Edward, et al. «Learning to Transduce with Unbounded Memory.» arXiv:1506.02516 (2015). (англ.)
- Atkeson, Christopher G., and Stefan Schaal. «Memory-based neural networks for robot learning.» Neurocomputing 9.3 (1995): 243—269. (англ.)
- Salakhutdinov, Ruslan, and Geoffrey Hinton. «Semantic hashing.» International Journal of Approximate Reasoning 50.7 (2009): 969—978. (англ.)
- Le, Quoc V.; Mikolov, Tomas (2014). «Distributed representations of sentences and documents». arXiv:1405.4053. (англ.)
- Graves, Alex, Greg Wayne, and Ivo Danihelka. «Neural Turing Machines.» arXiv:1410.5401 (2014). (англ.)
- Weston, Jason, Sumit Chopra, and Antoine Bordes. «Memory networks.» arXiv:1410.3916 (2014). (англ.)
- Sukhbaatar, Sainbayar, et al. «End-To-End Memory Networks.» arXiv:1503.08895 (2015). (англ.)
- Bordes, Antoine, et al. «Large-scale Simple Question Answering with Memory Networks.» arXiv:1506.02075 (2015). (англ.)
- Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. «Pointer networks.» arXiv:1506.03134 (2015). (англ.)
- Kurach, Karol, Andrychowicz, Marcin and Sutskever, Ilya. «Neural Random-Access Machines.» arXiv:1511.06392 (2015). (англ.)
- N. Kalchbrenner and P. Blunsom, "Recurrent continuous translation models, " in EMNLP'2013, 2013. (англ.)
- I. Sutskever, O. Vinyals, and Q. V. Le, "Sequence to sequence learning with neural networks, " in NIPS'2014, 2014. (англ.)
- K. Cho, B. van Merrienboer, C. Gulcehre, F. Bougares, H. Schwenk, and Y. Bengio, "Learning phrase representations using RNN encoder-decoder for statistical machine translation, " in Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), Oct. 2014 (англ.)
- Cho, Kyunghyun, Aaron Courville, and Yoshua Bengio. «Describing Multimedia Content using Attention-based Encoder--Decoder Networks.» arXiv:1507.01053 (2015). (англ.)
- Cho, Youngmin (2012). Kernel Methods for Deep Learning. с. 1–9. (англ.)
- Scholkopf, B; Smola, Alexander (1998). Nonlinear component analysis as a kernel eigenvalue problem. Neural computation (44): 1299–1319. doi:10.1162/089976698300017467. (англ.)
- L. Deng, G. Tur, X. He, and D. Hakkani-Tur. "Use of Kernel Deep Convex Networks and End-To-End Learning for Spoken Language Understanding, " Proc. IEEE Workshop on Spoken Language Technologies, 2012 (англ.)
- TIMIT Acoustic-Phonetic Continuous Speech Corpus Linguistic Data Consortium, Philadelphia. (англ.)
- Abdel-Hamid, O. (2014). Convolutional Neural Networks for Speech Recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing 22 (10): 1533–1545. doi:10.1109/taslp.2014.2339736. (англ.)
- Deng, L.; Platt, J. (2014). Ensemble Deep Learning for Speech Recognition. Proc. Interspeech. (англ.)
- Yu, D.; Deng, L. (2010). Roles of Pre-Training and Fine-Tuning in Context-Dependent DBN-HMMs for Real-World Speech Recognition. NIPS Workshop on Deep Learning and Unsupervised Feature Learning. (англ.)
- Deng L., Li, J., Huang, J., Yao, K., Yu, D., Seide, F. et al. Recent Advances in Deep Learning for Speech Research at Microsoft. ICASSP, 2013. (англ.)
- Deng, L.; Li, Xiao (2013). Machine Learning Paradigms for Speech Recognition: An Overview. IEEE Transactions on Audio, Speech, and Language Processing 21: 1060–1089. doi:10.1109/tasl.2013.2244083. (англ.)
- L. Deng, M. Seltzer, D. Yu, A. Acero, A. Mohamed, and G. Hinton (2010) Binary Coding of Speech Spectrograms Using a Deep Auto-encoder. Interspeech. (англ.)
- Z. Tuske, P. Golik, R. Schlüter and H. Ney (2014). Acoustic Modeling with Deep Neural Networks Using Raw Time Signal for LVCSR. Interspeech. (англ.)
- McMillan, R. «How Skype Used AI to Build Its Amazing New Language Translator», Wire, Dec. 2014. (англ.)
- Hannun et al. (2014) «Deep Speech: Scaling up end-to-end speech recognition», arXiv:1412.5567. (англ.)
- Plenary presentation at ICASSP-2016. (англ.)
- Ron Schneiderman (2015) «Accuracy, Apps Advance Speech Recognition — Interviews with Vlad Sejnoha and Li Deng», IEEE Signal Processing Magazine, Jan, 2015. (англ.)
- http://yann.lecun.com/exdb/mnist/ (англ.)
- D. Ciresan, U. Meier, J. Schmidhuber., "Multi-column Deep Neural Networks for Image Classification, " Technical Report No. IDSIA-04-12', 2012. (англ.)
- D. Ciresan, A. Giusti, L.M. Gambardella, J. Schmidhuber (2013). Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. Proceedings MICCAI, 2013. (англ.)
- Vinyals et al. (2014)."Show and Tell: A Neural Image Caption Generator, " arXiv:1411.4555. (англ.)
- Fang et al. (2014)."From Captions to Visual Concepts and Back, " arXiv:1411.4952. (англ.)
- Kiros et al. (2014). "Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models, " arXiv:1411.2539. (англ.)
- Zhong, S.; Liu, Y.; Liu, Y. Bilinear Deep Learning for Image Classification. Proceedings of the 19th ACM International Conference on Multimedia 11: 343–352. (англ.)
- Nvidia Demos a Car Computer Trained with «Deep Learning» (2015-01-06), David Talbot, MIT Technology Review (англ.)
- Y. Bengio, R. Ducharme, P. Vincent, C. Jauvin., "A Neural Probabilistic Language Model, " Journal of Machine Learning Research 3 (2003) 1137—1155', 2003.
- Goldberg, Yoav; Levy, Omar. word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method. Arxiv. Процитовано 26 жовтня 2014. (англ.)
- Socher, Richard; Manning, Christopher. Deep Learning for NLP. Процитовано 26 жовтня 2014. (англ.)
- Socher, Richard; Bauer, John; Manning, Christopher; Ng, Andrew (2013). Parsing With Compositional Vector Grammars. Proceedings of the ACL 2013 conference. (англ.)
- Socher, Richard (2013). Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. EMNLP 2013. (англ.)
- Y. Shen, X. He, J. Gao, L. Deng, and G. Mesnil (2014) " A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval, " Proc. CIKM. (англ.)
- P. Huang, X. He, J. Gao, L. Deng, A. Acero, and L. Heck (2013) "Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, " Proc. CIKM. (англ.)
- Mesnil, G., Dauphin, Y., Yao, K., Bengio, Y., Deng, L., Hakkani-Tur, D., He, X., Heck, L., Tur, G., Yu, D. and Zweig, G., 2015. Using recurrent neural networks for slot filling in spoken language understanding. IEEE Transactions on Audio, Speech, and Language Processing, 23(3), pp.530-539. (англ.)
- J. Gao, X. He, W. Yih, and L. Deng(2014) "Learning Continuous Phrase Representations for Translation Modeling, " Proc. ACL. (англ.)
- J. Gao, P. Pantel, M. Gamon, X. He, L. Deng (2014) "Modeling Interestingness with Deep Neural Networks, " Proc. EMNLP. (англ.)
- J. Gao, X. He, L. Deng (2014) "Deep Learning for Natural Language Processing: Theory and Practice (Tutorial), " CIKM. (англ.)
- Arrowsmith, J; Miller, P (2013). Trial watch: Phase II and phase III attrition rates 2011-2012. Nature Reviews Drug Discovery 12 (8): 569. PMID 23903212. doi:10.1038/nrd4090. (англ.)
- Verbist, B; Klambauer, G; Vervoort, L; Talloen, W; The Qstar, Consortium; Shkedy, Z; Thas, O; Bender, A; Göhlmann, H. W.; Hochreiter, S (2015). Using transcriptomics to guide lead optimization in drug discovery projects: Lessons learned from the QSTAR project. Drug Discovery Today 20: 505–513. PMID 25582842. doi:10.1016/j.drudis.2014.12.014. (англ.)
- «Announcement of the winners of the Merck Molecular Activity Challenge» https://www.kaggle.com/c/MerckActivity/details/winners. (англ.)
- Dahl, G. E.; Jaitly, N.; & Salakhutdinov, R. (2014) "Multi-task Neural Networks for QSAR Predictions, " ArXiv, 2014. (англ.)
- «Toxicology in the 21st century Data Challenge» https://tripod.nih.gov/tox21/challenge/leaderboard.jsp (англ.)
- «NCATS Announces Tox21 Data Challenge Winners» http://www.ncats.nih.gov/news-and-events/features/tox21-challenge-winners.html Архівовано 28 лютого 2015 у Wayback Machine. (англ.)
- Unterthiner, T.; Mayr, A.; Klambauer, G.; Steijaert, M.; Ceulemans, H.; Wegner, J. K.; & Hochreiter, S. (2014) «Deep Learning as an Opportunity in Virtual Screening». Workshop on Deep Learning and Representation Learning (NIPS2014). (англ.)
- Unterthiner, T.; Mayr, A.; Klambauer, G.; & Hochreiter, S. (2015) «Toxicity Prediction using Deep Learning». ArXiv, 2015. (англ.)
- Ramsundar, B.; Kearnes, S.; Riley, P.; Webster, D.; Konerding, D.;& Pande, V. (2015) «Massively Multitask Networks for Drug Discovery». ArXiv, 2015. (англ.)
- Wallach, Izhar; Dzamba, Michael; Heifets, Abraham (2015-10-09). «AtomNet: A Deep Convolutional Neural Network for Bioactivity Prediction in Structure-based Drug Discovery». arXiv:1510.02855. (англ.)
- Toronto startup has a faster way to discover effective medicines. The Globe and Mail. Процитовано 9 листопада 2015. (англ.)
- Startup Harnesses Supercomputers to Seek Cures. KQED Future of You (en-us). Процитовано 9 листопада 2015. (англ.)
- Tkachenko, Yegor. Autonomous CRM Control via CLV Approximation with Deep Reinforcement Learning in Discrete and Continuous Action Space. (April 8, 2015). arXiv.org: http://arxiv.org/abs/1504.01840 (англ.)
- Van den Oord, Aaron, Sander Dieleman, and Benjamin Schrauwen. «Deep content-based music recommendation.» Advances in Neural Information Processing Systems. 2013. (англ.)
- Elkahky, Ali Mamdouh, Yang Song, and Xiaodong He. «A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems.» Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2015. (англ.)
- Davide Chicco, Peter Sadowski, and Pierre Baldi, «Deep autoencoder neural networks for gene ontology annotation predictions». Proceedings of the 5th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics. ACM, 2014. (англ.)
- Utgoff, P. E.; Stracuzzi, D. J. (2002). Many-layered learning. Neural Computation 14: 2497–2529. doi:10.1162/08997660260293319. (англ.)
- J. Elman et al., "Rethinking Innateness, " 1996. (англ.)
- Shrager, J.; Johnson, MH (1996). Dynamic plasticity influences the emergence of function in a simple cortical array. Neural Networks 9 (7): 1119–1129. doi:10.1016/0893-6080(96)00033-0. (англ.)
- Quartz, SR; Sejnowski, TJ (1997). The neural basis of cognitive development: A constructivist manifesto. Behavioral and Brain Sciences 20 (4): 537–556. doi:10.1017/s0140525x97001581. (англ.)
- S. Blakeslee., "In brain's early growth, timetable may be critical, " The New York Times, Science Section, pp. B5–B6, 1995. (англ.)
- {BUFILL} E. Bufill, J. Agusti, R. Blesa., "Human neoteny revisited: The case of synaptic plasticity, " American Journal of Human Biology, 23 (6), pp. 729—739, 2011. (англ.)
- J. Shrager and M. H. Johnson., "Timing in the development of cortical function: A computational approach, " In B. Julesz and I. Kovacs (Eds.), Maturational windows and adult cortical plasticity, 1995. (англ.)
- D. Hernandez., "The Man Behind the Google Brain: Andrew Ng and the Quest for the New AI, " http://www.wired.com/wiredenterprise/2013/05/neuro-artificial-intelligence/all/. Wired, 10 May 2013. (англ.)
- C. Metz., "Facebook's 'Deep Learning' Guru Reveals the Future of AI, " http://www.wired.com/wiredenterprise/2013/12/facebook-yann-lecun-qa/. Wired, 12 December 2013. (англ.)
- V. Vapnik., «research.facebook.com» Архівовано 23 липня 2015 у Wayback Machine.. (англ.)
- Google AI algorithm masters ancient game of Go. Nature News & Comment. Процитовано 30 січня 2016. (англ.)
- Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; van den Driessche, George; Schrittwieser, Julian; Antonoglou, Ioannis та ін. (28 січня 2016). Mastering the game of Go with deep neural networks and tree search. Nature (англ.) 529 (7587): 484–489. ISSN 0028-0836. doi:10.1038/nature16961. (англ.)
- A Google DeepMind Algorithm Uses Deep Learning and More to Master the Game of Go | MIT Technology Review. MIT Technology Review. Процитовано 30 січня 2016. (англ.)
- Blippar Demonstrates New Real-Time Augmented Reality App. TechCrunch. (англ.)
- G. Marcus., "Is "Deep Learning" a Revolution in Artificial Intelligence?" The New Yorker, 25 November 2012. (англ.)
- Smith, G. W. (27 березня 2015). Art and Artificial Intelligence. ArtEnt. Архів оригіналу за червень 25, 2017. Процитовано 27 березня 2015. (англ.)
- Knight, Will (7 листопада 2001). Tools point to African origin for human behaviour. New Scientist. Процитовано 7 жовтня 2015. (англ.)
- Alexander Mordvintsev; Christopher Olah; Mike Tyka (17 червня 2015). Inceptionism: Going Deeper into Neural Networks. Google Research Blog. Процитовано 20 червня 2015. (англ.)
- Alex Hern (18 червня 2015). Yes, androids do dream of electric sheep. The Guardian. Процитовано 20 червня 2015. (англ.)
- Ben Goertzel. Are there Deep Reasons Underlying the Pathologies of Today's Deep Learning Algorithms? (2015) Url: http://goertzel.org/DeepLearning_v1.pdf (англ.)
- Nguyen, Anh, Jason Yosinski, and Jeff Clune. «Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images.» arXiv:1412.1897 (2014). (англ.)
- Szegedy, Christian, et al. «Intriguing properties of neural networks.» arXiv:1312.6199 (2013). (англ.)
- Zhu, S.C.; Mumford, D. A stochastic grammar of images. Found. Trends Comput. Graph. Vis. 2 (4): 259–362. doi:10.1561/0600000018. (англ.)
- Miller, G. A., and N. Chomsky. «Pattern conception.» Paper for Conference on pattern detection, University of Michigan. 1957. (англ.)
- Jason Eisner, Deep Learning of Recursive Structure: Grammar Induction, http://techtalks.tv/talks/deep-learning-of-recursive-structure-grammar-induction/58089/ (англ.)
- CNTK on Github (англ.)
- Deeplearning4j на Github
- [[Джеф Дін|Dean, Jeff]]; Monga, Rajat (9 листопада 2015). TensorFlow: Large-scale machine learning on heterogeneous systems. TensorFlow.org. Google Research. Процитовано 10 листопада 2015. (англ.)
- Apache SINGA Website (англ.)
- B. C. Ooi, K.-L. Tan, S. Wang, W. Wang, G. Chen, J. Gao, Z. Luo, A.K.H. Tung, Y. Wang, Z. Xie, M. Zhang, K. Zheng. "SINGA: A Distributed Deep Learning Platform, " ACM Multimedia (Open Source Software Competition). 2015. (англ.)
- W. Wang, G. Chen, T. T. A. Dinh, J. Gao, B. C. Ooi, K.-L.Tan, S. Wang. "SINGA: Putting Deep Learning in the Hands of Multimedia Users, " ACM Multimedia. 2015. (англ.)
