Залишкова нейронна мережа
За́лишкова нейро́нна мере́жа (англ. residual neural network, ResNet) — це штучна нейронна мережа (ШНМ), яка будується на структурах, відомих за пірамідними нейронами кори головного мозку. Залишкові нейронні мережі роблять це, використовуючи про́пускові з'є́днання (англ. skip connections) або зрізання (англ. shortcuts) для перескакування через деякі шари. Типові моделі ResNet втілюють із подвійними або потрійними пропусканнями шарів, з нелінійностями (ReLU) чи пакетним унормовуванням посередині.[1] Для навчання пропускових ваг можуть використовувати додаткову матрицю ваг; ці моделі відомі як HighwayNet. Моделі з кількома паралельними пропусками називають DenseNet.[2] У контексті залишкових нейронних мереж незалишкову мережу можуть описувати як просту мережу (англ. plain network).
Існує дві основні причини для додавання пропускових з'єднань: задля уникання проблеми зникання градієнтів, та задля пом'якшення проблеми виродження (англ. degradation problem, насичення точності, англ. accuracy saturation), за якої додавання додаткових шарів до належно глибокої моделі призводить до більшої тренувальної похибки.[3] Під час тренування ваги пристосовуються приглушувати вищий за течією шар[прояснити: ком.] та підсилювати попередньо пропущений шар. У найпростішому випадку пристосовуються лише ваги для з'єднання сусіднього шару, без жодних явних ваг для вищого шару. Це працює найкраще, коли пропускають один нелінійний шар, або коли всі проміжні шари є лінійними. Якщо ні, то слід навчатися явної матриці ваг для пропускового з'єднання (слід використовувати HighwayNet).
Пропускання дієво спрощує мережу, використовуючи меншу кількість шарів на початкових етапах тренування[прояснити: ком.]. Це прискорює навчання, зменшуючи вплив зникання градієнтів, оскільки існує менше шарів для поширення. Потім мережа поступово відновлює пропущені шари під час навчання простору ознак. Під кінець навчання, коли всі шари розгортаються, вона залишається ближчою до магістралі[прояснити: ком.], й відтак навчається швидше. Нейронна мережа без залишкових частин досліджує більше простору ознак. Це робить її вразливішою до збурень, які змушують її зіскакувати з магістралі, й вимагає додаткових тренувальних даних для надолужування.
Біологічний аналог
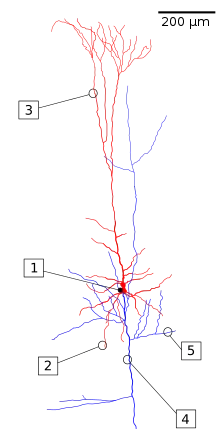
Мозок має структури, подібні до залишкових мереж, оскільки нейрони шостого шару кори отримують вхід із першого шару, пропускаючи проміжні шари.[4] На рисунку це зіставлено з сигналами від апікального дендриту (3), що оминають шари, тоді як базальний дендрит (2) збирає сигнали з попереднього та/або того ж шару.[lower-alpha 1][5] Подібні структури існують і для інших шарів.[6] Скільки шарів у корі головного мозку є подібними до шарів у штучній нейронній мережі, не зрозуміло, як і не зрозуміло, чи всі області кори головного мозку мають однакову структуру, але на великих площах вони виглядають подібними.
Пряме поширення
Для одиночних пропусків шари може бути індексовано або як з до , або як з до . (Шрифт використано для наочності, зазвичай його пишуть як просте l.) Ці дві системи індексування є зручними при описуванні пропусків як таких, що йдуть назад, та вперед. Оскільки сигнал проходить мережею вперед, простіше описувати пропуск як із заданого рівня, але як правило навчання (зворотне поширення) простіше описувати, який шар збудження ви використовуєте повторно, як , де є числом пропуску.






Для заданої вагової матриці для ваг з'єднань з шару до та вагової матриці для ваг з'єднань з шару до прямим поширенням через передавальну функцію буде (відома як HighwayNet)




де
- — збудження (виходи) нейронів у шарі ,
- — передавальна функція шару ,
- — вагова матриця для нейронів між шарами та , а



За відсутності явної матриці (що є відомим як ResNet) пряме поширення крізь передавальну функцію спрощується до

Інший спосіб сформулювати це — підставити одиничну матрицю замість , але це є справедливим лише коли розміри збігаються. Це дещо заплутано називають одиничним блоком (англ. identity block), що означає, що збудження з шару передаються до шару без зважування.
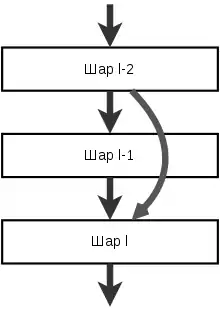
У корі головного мозку такі пропуски вперед здійснюються для декількох шарів. Зазвичай усі пропуски вперед починаються з одного й того ж шару, і послідовно з'єднуються з пізнішими шарами. У загальному випадку це буде виражено як (відоме як DenseNet)
- .

Зворотне поширення
Під час навчання зворотним поширенням для нормального шляху

і для шляхів пропусків (майже ідентично)
- .

В обох випадках
- є темпом навчання ( ,
- є сигналом похибки нейронів на шарі , а
- є збудженням нейронів на шарі .




Якщо шлях пропуску має незмінні ваги (наприклад, одиничну матрицю, як вище), то вони не уточнюються. Якщо їх можливо уточнювати, то це правило є звичайним правилом уточнювання зворотного поширення.
У загальному випадку може бути вагових матриць шляхів пропуску, тож


Оскільки правила навчання є однаковими, вагові матриці можливо об'єднувати та навчати за один крок.
Виноски
- Деякі дослідження показують, що тут є додаткові структури, тож це пояснення є дещо спрощеним.
Примітки
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2016). Deep Residual Learning for Image Recognition. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE. Процитовано 23 квітня 2020. (англ.)
- Huang, Gao; Liu, Zhuang; Weinberger, Kilian Q.; van der Maaten, Laurens (2017). Densely Connected Convolutional Networks. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE. Процитовано 23 квітня 2020. (англ.)
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2015-12-10). «Deep Residual Learning for Image Recognition». arXiv:1512.03385 [cs.CV].He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2015-12-10). "Deep Residual Learning for Image Recognition". arXiv:1512.03385 [cs.CV]. (англ.)
- Thomson, AM (2010). Neocortical layer 6, a review.. Frontiers in Neuroanatomy 4: 13. PMC 2885865. PMID 20556241. doi:10.3389/fnana.2010.00013. (англ.)
- Winterer, Jochen; Maier, Nikolaus; Wozny, Christian; Beed, Prateep; Breustedt, Jörg; Evangelista, Roberta; Peng, Yangfan; D’Albis, Tiziano та ін. (2017). Excitatory Microcircuits within Superficial Layers of the Medial Entorhinal Cortex. Cell Reports 19 (6): 1110–1116. PMID 28494861. doi:10.1016/j.celrep.2017.04.041. Проігноровано невідомий параметр
|doi-access=(довідка); (англ.) - Fitzpatrick, David (1 травня 1996). The Functional Organization of Local Circuits in Visual Cortex: Insights from the Study of Tree Shrew Striate Cortex. Cerebral Cortex (англ.) 6 (3): 329–341. ISSN 1047-3211. PMID 8670661. doi:10.1093/cercor/6.3.329. Проігноровано невідомий параметр
|doi-access=(довідка) (англ.)