Метод зворотного поширення помилки
Метод зворотного поширення помилки (англ. backpropagation) — метод навчання багатошарового перцептрону. Це ітеративний градієнтний алгоритм, який використовується з метою мінімізації помилки роботи багатошарового перцептрону та отримання бажаного виходу. Основна ідея цього методу полягає в поширенні сигналів помилки від виходів мережі до її входів, в напрямку, зворотному прямому поширенню сигналів у звичайному режимі роботи. Барц і Охонін запропонували відразу загальний метод («принцип подвійності»), який можна застосувати до ширшого класу систем, включаючи системи з запізненням, розподілені системи, тощо [1]. Для можливості застосування методу зворотного поширення помилки функція активації нейронів повинна бути диференційовною.
Функція оцінки роботи мережі
Навчання нейронних мереж можна представити як задачу оптимізації. Оцінити — означає вказати кількісно, добре чи погано мережа вирішує поставлені їй завдання. Для цього будується функція оцінки. Вона, як правило, явно залежить від вихідних сигналів мережі і неявно (через функціонування) — від всіх її параметрів. Найпростіший і найпоширеніший приклад оцінки — сума квадратів відстаней від вихідних сигналів мережі до їх необхідних значень: , де — необхідне значення вихідного сигналу.


Метод найменших квадратів далеко не завжди є найкращим вибором оцінки. Ретельне конструювання функції оцінки дозволяє на порядок підвищити ефективність навчання мережі, а також одержувати додаткову інформацію — «рівень впевненості» мережі у відповіді [2]
Опис алгоритму
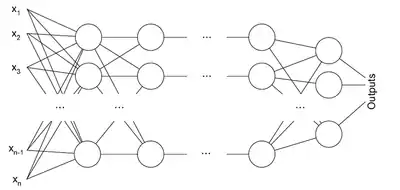
Алгоритм зворотного поширення помилки застосовується для багатошарового перцептрону. У мережі є множина входів , множина виходів Outputs і безліч внутрішніх вузлів. Перенумеруємо всі вузли (включаючи входи і виходи) числами від 1 до N (наскрізна нумерація, незалежно від топології шарів). Позначимо через вагу зв'язку, що з'єднує i-й і j-й вузли, а через — вихід i-го вузла. Якщо нам відомий навчальний приклад (правильні відповіді мережі , ), то функція помилки, отримана за методом найменших квадратів, виглядає так:






Як модифікувати ваги? Ми будемо реалізовувати стохастичний градієнтний спуск, тобто будемо підправляти ваги після кожного навчального прикладу і, таким чином, «рухатися» в багатовимірному просторі ваг. Щоб «добратися» до мінімуму помилки, нам потрібно «рухатися» в сторону, протилежну градієнту, тобто, на підставі кожної групи правильних відповідей, додавати до кожної ваги
- ,

де — множник, що задає швидкість «руху».

Похідна розраховується таким чином. Нехай спочатку , тобто вага, яка нас цікавить, входить в нейрон останнього рівня. Спочатку зазначимо, що впливає на вихід мережі лише як частина суми , де сума береться по входах j-го вузла. Тому



Аналогічно, впливає на загальну помилку тільки в рамках виходу j-го вузла (нагадуємо, що це вихід всієї мережі). Тому



де — це функція активації, у даному випадку (стосовно обчислення похідної) являє собою Експоненційну сигмоїду (функцію Фермі) розглянуту вище

Якщо ж j-й вузол — не на останньому рівні, то у нього є виходи; позначимо їх через Children (j). У цьому випадку
- ,

і
- .

А — це аналогічна поправка, але обчислена для вузла наступного рівня (будемо позначати її через — від вона відрізняється відсутністю множника . Оскільки ми навчилися обчислювати поправку для вузлів останнього рівня і виражати поправку для вузла нижчого рівня через поправки більш високого, можна вже створювати алгоритм навчання. Саме через цю особливість обчислення поправок цей алгоритм називається алгоритмом зворотного поширення помилки (англ. backpropagation).




Коротке викладення вищесказаного:
- Для вузла останнього рівня

- Для внутрішнього вузла мережі

- Для всіх вузлів

Отриманий алгоритм представлений нижче. На вхід алгоритму, крім зазначених параметрів, потрібно також подавати в якому-небудь форматі структуру мережі. На практиці дуже гарні результати показують мережі досить простої структури, що складаються з двох рівнів нейронів — прихованого рівня (hidden units) і нейронів-виходів (output units), кожен вхід мережі з'єднаний з усіма прихованими нейронами, а результат роботи кожного прихованого нейрона подається на вхід кожному з нейронів-виходів. У такому випадку досить подавати на вхід кількість нейронів прихованого рівня.
Алгоритм
Алгоритм: BackPropagation

- Ініціалізувати маленькими випадковими значеннями,
- Повторити NUMBER_OF_STEPS раз:
- Для всіх d від 1 до m:
- Подати на вхід сітки і підрахувати виходи кожного вузла.
- Для всіх
- .
- Для кожного рівня l, починаючи з останнього:
- Для кожного вузла j рівня l порахувати
- .
- Для кожного ребра сітки {i, j}
- .
- .
- Видати значення .








Математична інтерпретація навчання нейронної мережі
На кожній ітерації алгоритму зворотного поширення вагові коефіцієнти нейронної мережі модифікуються так, щоб поліпшити рішення одного прикладу. Таким чином, у процесі навчання циклічно вирішуються однокритеріальні задачі оптимізації.
Навчання нейронної мережі характеризується чотирма специфічними обмеженнями, що виділяють навчання нейромереж із загальних задач оптимізації: астрономічне число параметрів, необхідність високого паралелізму при навчанні, багато критеріально вирішуваних завдань, необхідність знайти досить широку область, в якій значення всіх функцій, що мінімізуються близькі до мінімальних. Стосовно решти проблему навчання можна, як правило, сформулювати як завдання мінімізації оцінки. Обережність попередньої фрази («як правило») пов'язана з тим, що насправді нам невідомі і ніколи не будуть відомі всі можливі завдання для нейронних мереж, і, може, десь в невідомості є завдання, які не зводяться до мінімізації оцінки. Мінімізація оцінки — складна проблема: параметрів астрономічно багато (для стандартних прикладів, що реалізуються на РС — від 100 до 1000000), адаптивний рельєф (графік оцінки як функції від підлаштовуваних параметрів) складний, може містити багато локальних мінімумів.
Недоліки алгоритму
Незважаючи на численні успішні застосування алгоритму зворотного поширення помилки, він не є панацеєю. Найбільше неприємностей приносить невизначено довгий процес навчання. У складних завданнях для навчання мережі можуть знадобитися дні або навіть тижні, вона може і взагалі не навчитися. Причиною може бути одна з описаних нижче.
Параліч мережі
У процесі навчання мережі значення ваг можуть в результаті корекції стати дуже великими величинами. Це може призвести до того, що всі або більшість нейронів будуть функціонувати при дуже великих значеннях OUT, в області, де похідна стискаючої функції дуже мала. Так як помилка, що посилається назад у процесі навчання, пропорційна цій похідній, то процес навчання може практично завмерти. У теоретичному відношенні ця проблема погано вивчена. Зазвичай цього уникають зменшенням розміру кроку η, але це збільшує час навчання. Різні евристики використовувалися для запобігання від паралічу або для відновлення після нього, але поки що вони можуть розглядатися лише як експериментальні.
Локальні мінімуми
Зворотне поширення використовує різновид градієнтного спуску, тобто здійснює спуск вниз по поверхні помилки, безперервно підлаштовуючи ваги в напрямку до мінімуму. Поверхня помилки складної мережі сильно порізана і складається з пагорбів, долин, складок і ярів в просторі високої розмірності. Мережа може потрапити в локальний мінімум (неглибоку долину), коли поруч є набагато більш глибоких мінімумів. В точці локального мінімуму всі напрямки ведуть вгору, і мережа нездатна з нього вибратися. Статистичні методи навчання можуть допомогти уникнути цієї пастки, але вони повільні.
Розмір кроку
Уважний розбір доведення збіжності [3] показує, що корекції ваг передбачаються нескінченно малими. Ясно, що це нездійсненно на практиці, тому що веде до безкінечного часу навчання. Розмір кроку повинен братися скінченним. Якщо розмір кроку фіксований і дуже малий, то збіжність надто повільна, якщо ж він фіксований і занадто великий, то може виникнути параліч або постійна нестійкість. Ефективно збільшувати крок до тих пір, поки не припиниться поліпшення оцінки в даному напрямку антиградієнта і зменшувати, якщо такого покращення не відбувається. П. Д. Вассерман [4] описав адаптивний алгоритм вибору кроку, який автоматично коректує розмір кроку в процесі навчання. В книзі А. Н. Горбаня [5] запропонована розгалужена технологія оптимізації навчання. Слід також відмітити можливість перенавчання мережі, що є скоріше результатом помилкового проектування її топології. При дуже великій кількості нейронів втрачається властивість мережі узагальнювати інформацію. Весь набір образів, наданих до навчання, буде вивчений мережею, але будь-які інші образи, навіть дуже схожі, можуть бути класифіковані невірно.
Історія
Вперше метод був описаний в 1974 р. А. І. Галушкіним [6], а також незалежно і одночасно Полом Дж. Вербосом [7]. Далі істотно розвинений в 1986 р. Девідом І. Румельгартом, Джефрі Е. Хінтоном і Рональдом Дж. Вільямсом [3] і незалежно й одночасно С. І. Барцом та В. А. Охоніним [8].
Література
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. — М.: «Мир», 1992.
- Хайкин С. Нейронные сети: Полный курс. Пер. с англ. Н. Н. Куссуль, А. Ю. Шелестова. 2-е изд., испр. — М.: Издательский дом Вильямс, 2008, 1103 с.
Зноски
- Барцев С. И., Гилев С. Е., Охонин В. А., Принцип двойственности в организации адаптивных сетей обработки информации, В кн.: Динамика химических и биологических систем. — Новосибирск: Наука, 1989. — С. 6-55.
- Миркес Е. М., Нейрокомпьютер. Проект стандарта. — Новосибирск: Наука, Сибирская издательская фирма РАН, 1999. — 337 с. ISBN 5-02-031409-9 Інші копії онлайн: , Архівовано 3 липня 2009 у Wayback Machine..
- Rumelhart, David E.; Williams, Ronald J. (1986). Learning Internal Representations by Error Propagation. In: Parallel Distributed Processing (англ.) (Cambridge, MA: MIT Press) 1: 318—362.
- Wasserman P. D. Experiments in translating Chinese characters using backpropagation. Proceedings of the Thirty-Third IEEE Computer Society International Conference.. — Washington: D. C.: Computer Society Press of the IEEE, 1988.
- Горбань А. Н. Обучение нейронных сетей. — Москва: СП ПараГраф, 1990.
- Галушкин А. И. Синтез многослойных систем распознавания образов. — М.: «Энергия», 1974.
- Werbos P. J., Beyond regression: New tools for prediction and analysis in the behavioral sciences. Ph.D. thesis, Harvard University, Cambridge, MA, 1974.
- Барцев С. И., Охонин В. А. Адаптивные сети обработки информации. Красноярск : Ин-т физики СО АН СССР, 1986. Препринт N 59Б. — 20 с.
Див. також
Посилання
- Olah, Christopher. Calculus on Computational Graphs: Backpropagation -- colah's blog. Процитовано 5 лютого 2019.
- С++ код простої нейромережі, що навчається за алгоритмом зворотного поширення помилки
- Терехов С. А., Лекции по теории и приложениям искусственных нейронных сетей.
- Миркес Е. М., Нейроинформатика: Учеб. пособие для студентов с программами для выполнения лабораторных работ. Красноярск: ИПЦ КГТУ, 2002, 347 с. ISBN 5-7636-0477-6.
