Алгоритм перемножування матриць
Оскільки множення матриць є настільки центральною операцією в багатьох чисельних алгоритмах, у те, щоби зробити алгори́тми перемно́жування ма́триць ефективними, було вкладено чимало праці. Застосування множення матриць в обчислювальних задачах зустрічаються в багатьох областях, включно з науковими обчисленнями та розпізнаванням образів, і в, здавалося би, не пов'язаних задачах, таких як підрахунок шляхів графом.[1] Було розроблено багато різних алгоритмів для перемножування матриць на різних типах апаратного забезпечення, включно з паралельними та розподіленими системами, де обчислювальну працю розподілювано декількома процесорами (можливо, через мережу).
| Нерозв'язана проблема інформатики: Який алгоритм перемножування матриць є найшвидшим? (більше нерозв'язаних проблем інформатики) |
Безпосереднє застосування математичного означення множення матриць дає алгоритм, що для перемножування двох матриць n × n займає часу порядку n3 (в нотації Ландау — Θ(n3)). Кращі асимптотичні межі часу, необхідного для перемножування матриць, були відомі від часів праці Страссена 1960 року, але досі не відомо, яким є оптимальний час (тобто, якою є складність цієї задачі).
Ітеративний алгоритм
За означенням множення матриць, якщо C = AB для матриці A розміру n × m та матриці B розміру m × p, то C є матрицею розміру n × p з елементами
- .

З цього може бути побудовано простий алгоритм, який обходить циклами індекси i з 1 по n та j з 1 по p, обчислюючи наведене вище із застосуванням вкладеного циклу:
- Вхід: матриці A та B
- Нехай C буде матрицею відповідного розміру
- Для i з 1 по n:
- Для j з 1 по p:
- Нехай sum = 0
- Для k з 1 по m:
- Встановити sum ← sum + Aik × Bkj
- Встановити Cij ← sum
- Для j з 1 по p:
- Повернути C
Цей алгоритм займає час Θ(nmp) (в нотації Ландау).[1] Поширеним спрощенням для цілей аналізу алгоритмів є вважати, що всі входи є квадратними матрицями розміру n × n, в разі чого час виконання становить Θ(n3), тобто, є кубічним.[2]
Поведінка кешу
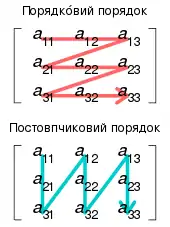
Ці три цикли в ітеративному перемножуванні матриць можливо довільно переставляти між собою без впливу на правильність чи асимптотичну тривалість виконання. Проте цей порядок може мати значний вплив на практичну продуктивність через моделі доступу до пам'яті алгоритму та використання ним кешу;[1] який порядок є кращим також залежить від того, чи зберігаються матриці в порядко́вому порядку, постовпчиковому, чи суміші обох.
Зокрема, в ідеалізованому випадку повністю асоціативного кешу, складеного з M байтів та b байтів на рядок кешу (тобто, Mb рядків кешу), наведений вище алгоритм є недооптимальним для A та B, що зберігаються в порядко́вому порядку. Коли n > Mb, кожна ітерація внутрішнього циклу (одночасного проходження рядком A та стовпчиком B) зазнає́ невлучання в кеш при отримуванні доступу до елементу B. Це означає, що цей алгоритм у найгіршому випадку зазнає Θ(n3) невлучань у кеш. Станом на 2010 рік швидкість пам'яті в порівнянні зі швидкістю процесорів є такою, що для матриць значного розміру в тривалості виконання домінують невлучання в кеш, а не фактичні обчислення.[3]
Оптимальним варіантом ітеративного алгоритму для A та B, що зберігаються в порядку рядків, є плиткова версія, в якій матрицю неявно ділять на квадратні плитки розміру √M на √M:[3][4]
- Вхід: матриці A та B
- Нехай C буде матрицею відповідного розміру
- Обрати розмір плитки T = Θ(√M)
- Для I з 1 по n кроками по T:
- Для J з 1 по p кроками по T:
- Для K з 1 по m кроками по T:
- Перемножити AI:I+T, K:K+T та BK:K+T, J:J+T до CI:I+T, J:J+T, тобто:
- Для i з I по min(I + T, n):
- Для j з J по min(J + T, p):
- Нехай sum = 0
- Для k з K по min(K + T, m):
- Встановити sum ← sum + Aik × Bkj
- Встановити Cij ← Cij + sum
- Для j з J по min(J + T, p):
- Для K з 1 по m кроками по T:
- Для J з 1 по p кроками по T:
- Повернути C
В ідеалізованій моделі кешу цей алгоритм зазнає лише Θ(n3b √M) невлучань у кеш; дільник b √M становить декілька порядків на сучасних машинах, тож у тривалості виконання домінують фактичні обчислення, а не невлучання в кеш.[3]
Алгоритм «розділюй та володарюй»
Альтернативою до ітеративного алгоритму є алгоритм «розділюй та володарюй» для множення матриць. Він спирається на блокове розбиття
- ,

яке працює для всіх квадратних матриць, чиї розміри є степенями двійки, тобто, форми 2n × 2n для деякого n. Тепер добутком матриць є

що складається з восьми множень пар підматриць, з подальшим кроком додавання. Алгоритм «розділюй та володарюй» обчислює менші добутки рекурсивно, застосовуючи як основу скалярне множення c11 = a11b11.
Складність цього алгоритму як функції від n задається рекурентно як[2]
- ;
- ,


із враховуванням восьми рекурсивних викликів на матрицях розміру n/2, та Θ(n2) для поелементного підсумовування чотирьох пар отримуваних в результаті матриць. Застосування майстер-методу для рекурсій «розділюй та володарюй» показує, що ця рекурсія має розв'язок Θ(n3), такий же, як й ітеративний алгоритм.[2]
Неквадратні матриці
Варіант цього алгоритму, який працює для матриць довільних форм, і є швидшим на практиці,[3] розбиває матриці на дві замість чотирьох підматриць наступним чином.[5] Розбивання матриці тепер означає поділ її на дві частини рівного розміру, або якомога ближче до рівних розмірів у разі, якщо розміри є непарними.
- Входи: матриці A розміру n × m, B розміру m × p.
- Базовий випадок: якщо max(n, m, p) є нижчим за певний поріг, застосувати розмотану версію ітеративного алгоритму.
- Рекурсивні випадки:
- Якщо max(n, m, p) = n, розбити A горизонтально:

- Інакше, якщо max(n, m, p) = p, розбити B вертикально:

- Інакше, max(n, m, p) = m. Робити A вертикально та B горизонтально:

Поведінка кешу
Рівень невлучання в кеш в рекурсивного матричного множення є таким же, як і в плиткової ітеративної версії, але, на відміну від того алгоритму, рекурсивний алгоритм є буферо-незалежним:[5] він не має параметру налаштування, необхідного для досягнення оптимальної продуктивності кешу, і він добре поводиться в багатопрограмному середовищі, де розміри кешу є фактично динамічними через те, що інші процеси займають його простір.[3] (Простий ітеративний алгоритм також є буферо-незалежним, але набагато повільнішим на практиці, якщо компонування матриць не пристосовано до алгоритму.)
Кількість невлучань у кеш, що зазнає́ цей алгоритм на машині з M рядками ідеально кешу розміру b байтів кожен, обмежено[5]

Підкубічні алгоритми
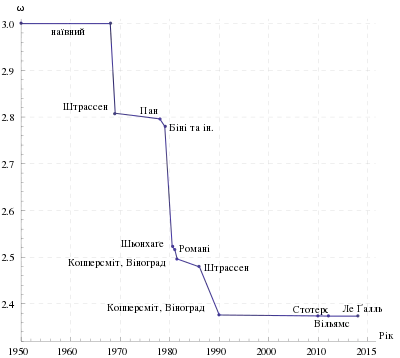
Існують алгоритми, що забезпечують кращу тривалість виконання, ніж прямолінійні. Першим було відкрито алгоритм Штрассена, винайдений Фолькером Штрассеном 1969 року, який часто називають «швидким множенням матриць» (англ. "fast matrix multiplication"). Він ґрунтується на способі множення двох матриць 2 × 2, який вимагає лише 7 множень (замість звичайних 8), ціною декількох додаткових операції додавання та віднімання. Його рекурсивне застосування дає алгоритм з витратами на множення . Алгоритм Штрассена є складнішим та має нижчу чисельну стійкість у порівнянні з наївним алгоритмом,[6] але він є швидшим у випадках, коли n > 100 або близько того,[1] і зустрічається в декількох бібліотеках, таких як BLAS.[7] Він є дуже корисним для великих матриць над точними областями, такими як скінченні поля, де чисельна стійкість не є проблемою.

Поточний алгоритм O(nk) з найнижчим відомим степенем k є узагальненнями алгоритму Копперсміта — Вінограда від Франсуа ле Ґалля, яке має асимптотичну складність O(n2.3728639).[8] Алгоритм ле Ґалля та алгоритм Копперсміта — Вінограда, на якому він ґрунтується, є подібними до алгоритму Штрассена: винайдено спосіб множення двох матриць k × k менше ніж k3 множеннями, і цю методику застосовують рекурсивно. Проте сталий коефіцієнт, прихований нотацією Ландау, є настільки великим, що ці алгоритми є доцільними лише для матриць, що є завеликими для обробки на сучасних комп'ютерах.[9][10]
Оскільки будь-який алгоритм для перемножування двох матриць n × n має обробити всі 2n2 елементів, існує асимптотична нижня межа в Ω(n2) операцій. Рац довів нижню межу в Ω(n2 log(n)) для арифметичних схем з обмеженими коефіцієнтами над дійсними або комплексними числами.[11]
Кон та ін. помістили такі методи, як алгоритми Штрассена та Копперсміта — Вінограда, до зовсім відмінного контексту теорії груп, використавши трійки підмножин скінченних груп, які задовольняють властивості неперетинності, що називають властивістю потрійного добутку (ВПД, англ. triple product property, TPP). Вони показали, що якщо сімейства вінкових добутків абелевих груп з симетричними групами втілюють сімейства трійок підмножин зі спільною версією ВПД, то існують алгоритми перемножування матриць із по суті квадратичною складністю.[12][13] Більшість дослідників вважають, що це так і є.[10] Проте Алон, Шпілка та Кріс Уманс нещодавно показали, що деякі з цих гіпотез, що передбачають швидке множення матриць, є несумісними з іншою правдоподібною гіпотезою, соняшниковою.[14]
Алгоритм Фрейвальдса є простим алгоритмом Монте-Карло, який для заданих матриць A, B та C перевіряє за час Θ(n2), чи AB = C.
Паралельні та розподілені алгоритми
Розпаралелювання зі спільною пам'яттю
Окреслений вище алгоритм «розділюй та володарюй» можливо розпаралелити для багатопроцесорності зі спільною пам'яттю двома способами. Вони ґрунтуються на тім факті, що вісім рекурсивних перемножувань матриць у

можливо виконувати незалежно одне від одного, як і чотири підсумовування (хоча алгоритмові потрібно «об'єднати» перемножування перед виконанням додавань). Використовуючи повну паралельність задачі, отримують алгоритм, який може бути виражено псевдокодом стилю відгалужування-об'єднування:[15]
Процедура перемножити(C, A, B):
- Базовий випадок: якщо n = 1, встановити c11 ← a11 × b11 (або перемножити маленьку блокову матрицю).
- Інакше, виділити простір для нової матриці T форми n × n, а тоді:
- Розбити A на A11, A12, A21, A22.
- Розбити B на B11, B12, B21, B22.
- Розбити C на C11, C12, C21, C22.
- Розбити T на T11, T12, T21, T22.
- Паралельне виконання:
- Відгалузити перемножити(C11, A11, B11).
- Відгалузити перемножити(C12, A11, B12).
- Відгалузити перемножити(C21, A21, B11).
- Відгалузити перемножити(C22, A21, B12).
- Відгалузити перемножити(T11, A12, B21).
- Відгалузити перемножити(T12, A12, B22).
- Відгалузити перемножити(T21, A22, B21).
- Відгалузити перемножити(T22, A22, B22).
- Об'єднати (дочекатися завершення паралельних відгалужень).
- додати(C, T).
- Звільнити T.
Процедура додати(C, T) додає T до C, поелементно:
- Базовий випадок: якщо n = 1, встановити c11 ← c11 + t11 (або виконати короткий цикл, можливо, розмотаний).
- Інакше:
- Розбити C на C11, C12, C21, C22.
- Розбити T на T11, T12, T21, T22.
- Паралельно:
- Відгалузити додати(C11, T11).
- Відгалузити додати(C12, T12).
- Відгалузити додати(C21, T21).
- Відгалузити додати(C22, T22).
- Об'єднати.
Тут відгалузити є ключовим словом, яке сигналізує, що обчислення може бути виконувано паралельно до решти виклику функції, тоді як об'єднати чекає на завершення всіх попередньо «відгалужених» обчислень. Розбити досягає своєї мети лише маніпулюванням вказівниками.
Цей алгоритм має критичною довжиною шляху Θ(log2 n) кроків, що означає, що йому потрібно стільки часу на ідеальній машині з нескінченним числом процесорів. Отже, на будь-якому реальному комп'ютері він має максимальне можливе прискорення Θ(n3/log2 n). Цей алгоритм не є практичним через витрати на передавання, властиві переміщуванню даних до та з тимчасової матриці T, але практичніший варіант досягає прискорення Θ(n2) без використання тимчасової матриці.[15]
Алгоритми з униканням передавання, та розподілені алгоритми
На сучасних архітектурах з ієрархічною пам'яттю вартість завантажування та зберігання елементів матриць входу має схильність переважати над вартістю арифметики. На одній машині це — кількість даних, передаваних між оперативною пам'яттю та кешем, тоді як на багатовузловій машині з розподіленою пам'яттю це — кількість, що передається між вузлами. В кожному з випадків її називають пропускною здатністю обміну (англ. communication bandwidth). Наївний алгоритм із використанням трьох вкладених циклів використовує пропускну здатністю обміну Ω(n3).
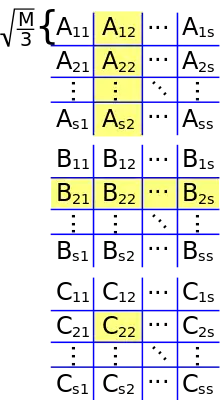
Алгоритм Кеннона, відомий також як двовимірний алгоритм (англ. 2D algorithm), є алгоритмом з униканням обміну, який розбиває кожну з матриць входу на блокову матрицю, чиї елементи є підматрицями розміру √M/3 на √M/3, де M є розміром швидкої пам'яті.[16] Потім застосовують наївний алгоритм над блоковими матрицями, обчислюючи добутки підматриць цілком у швидкій пам'яті. Це знижує пропускну здатність обміну до O(n3/√M), яка є асимптотично оптимальною (для алгоритмів, що виконують обчислення Ω(n3)).[17][18]
У розподіленій постановці з p процесорами, розставленими у двовимірній сітці √p на √p, кожному з процесорів можливо призначувати по одній з підматриць результату, і добуток буде обчислювано з передаванням кожним з процесорів O(n2/√p) слів, що є асимптотично оптимальним, виходячи з того, що кожен з вузлів зберігає щонайменше O(n2/p) елементів.[18] Це може бути вдосконалено тривимірним алгоритмом (англ. 3D algorithm), який впорядковує процесори у тривимірну кубічну сітку, призначуючи кожен добуток двох підматриць входу одному процесорові. Підматриці результату потім породжують виконанням зведення над кожним з рядків.[19] Цей алгоритм передає O(n2/p2/3) слів на процесор, що є асимптотично оптимальним.[18] Проте, це вимагає повторювання кожного з елементів матриць входу p1/3 разів, і відтак вимагає в p1/3 разів більше пам'яті, ніж необхідно для зберігання входів. Для подальшого зниження тривалості виконання цей алгоритм може бути поєднувано з алгоритмом Штрассена.[19] «2,5-вимірні» алгоритми (англ. "2.5D" algorithms) забезпечують безперервний компроміс між використанням пам'яті та пропускною здатністю передавання.[20] На сучасних розподілених обчислювальних середовищах, таких як MapReduce, було розроблено спеціалізовані алгоритми перемножування.[21]
Алгоритми для сіток
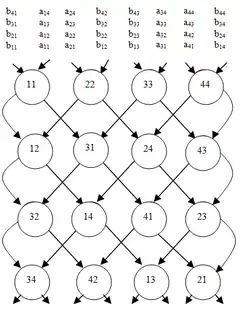
Існує низка алгоритмів для перемножування на сітках. Для перемножування двох n×n на стандартній двовимірній сітці із застосуванням двовимірного алгоритму Кеннона обчислюють перемножування в 3n-2 кроків, хоча це знижується до половини цього числа для повторюваних обчислень.[22] Стандартний масив є неефективним, оскільки дані з двох матриць не надходять одночасно, і його має бути доповнювано нулями.
Результат є ще швидшим на двошаровій перехрещуваній сітці, де потрібно лише 2n-1 кроків.[23] Продуктивність додатково покращується для повторюваних обчислень, ведучи до стовідсоткової ефективності.[24] Перехрещуваний сітковий масив можна розглядати як особливий випадок не планарної (тобто, багатошарової) оброблювальної структури.[25]
Див. також
- Обчислювальна складність математичних операцій
- Алгоритм КЯК, § Алгоритм Велієнта
- Задача про порядок перемножування матриць
- Розріджене матрично-векторне множення
Примітки
- Skiena, Steven (2008). Sorting and Searching. The Algorithm Design Manual. Springer. с. 45–46, 401–403. ISBN 978-1-84800-069-8. doi:10.1007/978-1-84800-070-4_4. (англ.)
- Томас Кормен; Чарльз Лейзерсон, Рональд Рівест, Кліфорд Стайн (2009) [1990]. Вступ до алгоритмів (вид. 3rd). MIT Press і McGraw-Hill. с. 75–79. ISBN 0-262-03384-4.
- Amarasinghe, Saman; Leiserson, Charles (2010). 6.172 Performance Engineering of Software Systems, Lecture 8. MIT OpenCourseWare. Massachusetts Institute of Technology. Процитовано 27 січня 2015. (англ.)
- Lam, Monica S.; Rothberg, Edward E.; Wolf, Michael E. (1991). The Cache Performance and Optimizations of Blocked Algorithms Int'l Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS). (англ.)
- Prokop, Harald (1999). Cache-Oblivious Algorithms (Master's). MIT. (англ.)
- Miller, Webb (1975). Computational complexity and numerical stability. SIAM News 4: 97–107. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Press, William H.; Flannery, Brian P.; Teukolsky, Saul A.; Vetterling, William T. (2007). Numerical Recipes: The Art of Scientific Computing (вид. 3rd). Cambridge University Press. с. 108. ISBN 978-0-521-88068-8. Проігноровано невідомий параметр
|title-link=(довідка) (англ.) - Le Gall, François (2014). Powers of tensors and fast matrix multiplication. Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation (ISSAC 2014). Bibcode:2014arXiv1401.7714L. arXiv:1401.7714. (англ.). Первинний алгоритм, представлений Доном Копперсмітом та Шмуелем Віноградом 1990 року, має асимптотичну складність O(n2.376). Його було поліпшено 2013 року до O(n2.3729) Вірджинією Василевською-Вільямс, що дало тривалість лише трошки гіршу, ніж у вдосконалення ле Ґалля: Williams, Virginia Vassilevska. Multiplying matrices faster than Coppersmith-Winograd. (англ.)
- Iliopoulos, Costas S. (1989). Worst-case complexity bounds on algorithms for computing the canonical structure of finite abelian groups and the Hermite and Smith normal forms of an integer matrix. SIAM Journal on Computing 18 (4): 658–669. MR 1004789. doi:10.1137/0218045. Архів оригіналу за 5 березня 2014. Процитовано 15 грудня 2019. «The Coppersmith–Winograd algorithm is not practical, due to the very large hidden constant in the upper bound on the number of multiplications required.» Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Robinson, Sara (2005). Toward an Optimal Algorithm for Matrix Multiplication. SIAM News 38 (9). (англ.)
- Ран Рац. On the complexity of matrix product. In Proceedings of the thirty-fourth annual ACM symposium on Theory of computing. ACM Press, 2002. DOI:10.1145/509907.509932. (англ.)
- Henry Cohn, Robert Kleinberg, Balázs Szegedy, and Chris Umans. Group-theoretic Algorithms for Matrix Multiplication. arXiv:math.GR/0511460. Proceedings of the 46th Annual Symposium on Foundations of Computer Science, 23–25 October 2005, Pittsburgh, PA, IEEE Computer Society, pp. 379–388. (англ.)
- Henry Cohn, Chris Umans. A Group-theoretic Approach to Fast Matrix Multiplication. arXiv:math.GR/0307321. Proceedings of the 44th Annual IEEE Symposium on Foundations of Computer Science, 11–14 October 2003, Cambridge, MA, IEEE Computer Society, pp. 438–449. (англ.)
- Alon, Shpilka, Umans, On Sunflowers and Matrix Multiplication (англ.)
- Randall, Keith H. (1998). Cilk: Efficient Multithreaded Computing (Ph.D.). Massachusetts Institute of Technology. с. 54–57. (англ.)
- Lynn Elliot Cannon, A cellular computer to implement the Kalman Filter Algorithm, Technical report, Ph.D. Thesis, Montana State University, 14 July 1969. (англ.)
- Hong, J. W.; Kung, H. T. (1981). I/O complexity: The red-blue pebble game. STOC '81: Proceedings of the Thirteenth Annual ACM Symposium on Theory of Computing: 326–333. (англ.)
- Irony, Dror; Toledo, Sivan; Tiskin, Alexander (September 2004). Communication lower bounds for distributed-memory matrix multiplication. J. Parallel Distrib. Comput. 64 (9): 1017–1026. doi:10.1016/j.jpdc.2004.03.021. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Agarwal, R.C.; Balle, S. M.; Gustavson, F. G.; Joshi, M.; Palkar, P. (September 1995). A three-dimensional approach to parallel matrix multiplication. IBM J. Res. Dev. 39 (5): 575–582. doi:10.1147/rd.395.0575. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Solomonik, Edgar; Demmel, James (2011). Communication-optimal parallel 2.5D matrix multiplication and LU factorization algorithms. Proceedings of the 17th International Conference on Parallel Processing. Part II: 90–109. (англ.)
- Bosagh Zadeh, Reza; Carlsson, Gunnar. Dimension Independent Matrix Square Using MapReduce. Процитовано 12 липня 2014. (англ.)
- Bae, S.E., T.-W. Shinn, T. Takaoka (2014) A faster parallel algorithm for matrix multiplication on a mesh array. Procedia Computer Science 29: 2230-2240 (англ.)
- Kak, S. (1988) A two-layered mesh array for matrix multiplication. Parallel Computing 6: 383-385 (англ.)
- Kak, S. (2014) Efficiency of matrix multiplication on the cross-wired mesh array. https://arxiv.org/abs/1411.3273 (англ.)
- Kak, S. (1988) Multilayered array computing. Information Sciences 45: 347-365 (англ.)
Література
- Buttari, Alfredo; Langou, Julien; Kurzak, Jakub; Dongarra, Jack (2009). A class of parallel tiled linear algebra algorithms for multicore architectures. Parallel Computing 35: 38–53. arXiv:0709.1272. doi:10.1016/j.parco.2008.10.002. (англ.)
- Goto, Kazushige; van de Geijn, Robert A. (2008). Anatomy of high-performance matrix multiplication. ACM Transactions on Mathematical Software 34 (3): 1–25. doi:10.1145/1356052.1356053. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Van Zee, Field G.; van de Geijn, Robert A. (2015). BLIS: A Framework for Rapidly Instantiating BLAS Functionality. ACM Transactions on Mathematical Software 41 (3): 1–33. doi:10.1145/2764454. (англ.)
- How To Optimize GEMM (англ.)
