F-міра
В статистичнім аналізі бінарної класифікації, F-міра (англ. F-score, F-measure) — це одна з мір точності тесту. Її обчислюють через влучність та повноту тесту, де влучність є числом правильно визначених позитивних результатів, поділеним на число всіх позитивних результатів, включно з визначеними неправильно, а повнота є числом правильно визначених позитивних результатів, поділеним на число всіх зразків, які повинно було бути визначено як позитивні.[1]
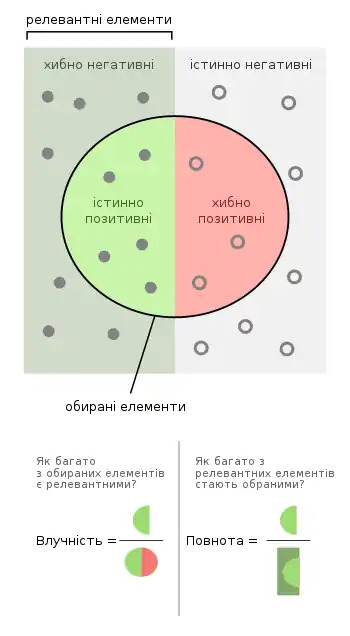
Міра F1 є середнім гармонійним цих влучності та повноти.[2] Загальніша міра Fβ застосовує додаткові ваги, оцінюючи або влучність, або повноту вище за іншу.
Найвищим можливим значенням F-міри є 1, що вказує на ідеальні влучність та повноту, а найнижчим можливим значенням є 0, якщо або влучність, або повнота є нульовими. Міра F1 є також відомою як індекс Соренсена, та коефіцієнт подібності Дайса (англ. Dice similarity coefficient, DSC).[джерело?]
Етимологія
Вважають, що назву F-міри вона отримала на честь іншої F-функції з книги ван Рійсберґена, коли її було представлено та четвертій Конференції з розуміння повідомлень (англ. Fourth Message Understanding Conference, MUC-4, 1992).[3]
Визначення
Традиційна F-міра, або збалансована F-оцінка (міра F1) є середнім гармонійним влучності та повноти:
- F1 = 2повнота-1 + влучність-1 = 2 · влучність · повнотавлучність + повнота = ІПІП + 12(ХП + ХН).
Fβ
Загальнішою F-мірою, Fβ, що використовує додатний дійснозначний коефіцієнт β, де β обирають так, що повноту вважають у β разів важливішою за влучність, є
- Fβ = (1 + β2) · влучність · повнота(β2 · влучність) + повнота
В термінах помилок першого і другого роду це стає:
- Fβ = (1 + β2) · істинно позитивні(1 + β2) · істинно позитивні + β2 · хибно негативні + хибно позитивні
Двома широко вживаними значеннями β є 2, яке надає повноті більшої ваги, ніж влучності, та 0,5, яке надає повноті меншої ваги, ніж влучності.
F-міру було виведено таким чином, що Fβ «вимірює ефективність пошуку з урахуванням користувача, який надає в β разів вищої важливості повноті, ніж влучності».[4] Вона ґрунтується на мірі ефективності ван Рійсберґена
- E = 1 − (αв + 1 − αп)−1
Вони є взаємопов'язаними як Fβ = 1 − E, де α = 11 + β2.
Діагностичне дослідження
Воно пов'язане з галуззю бінарної класифікації, де повноту часто називають «чутливістю».
| Справжній стан | ||||||
| загальна сукупність | позитивний стан | негативний стан | поширеність = Σ позитивних станівΣ загальної сукупності | точність = Σ істинно позитивних + Σ істинно негативнихΣ загальної сукупності | ||
| позитивний прогнозований стан |
істинно позитивний | хибно позитивний, помилка I роду |
прогностична значущість позитивного результату (ПЗ+), влучність = Σ істинно позитивнихΣ позитивних прогнозованих станів | рівень хибного виявляння (РХВ) = Σ хибно позитивнихΣ позитивних прогнозованих станів | ||
| негативний прогнозований стан |
хибно негативний, помилка II роду |
істинно негативний | рівень хибного пропускання (РХП) = Σ хибно негативнихΣ негативних прогнозованих станів | прогностична значущість негативного результату (ПЗ-) = Σ істинно негативнихΣ негативних прогнозованих станів | ||
| істиннопозитивний рівень (ІПР), повнота, чутливість, ймовірність виявлення, потужність = Σ істинно позитивнихΣ позитивних станів | хибнопозитивний рівень (ХПР), побічний продукт, ймовірність хибної тривоги = Σ хибно позитивнихΣ негативних станів | відношення правдоподібності позитивного результату (ВП+) = ІПРХПР | діагностичне відношення шансів (ДВШ) = ВП+ВП− | міра F1 = 2 · влучність · повнотавлучність + повнота | ||
| хибнонегативний рівень (ХНР), коефіцієнт невлучання = Σ хибно негативнихΣ позитивних станів | специфічність, вибірність, істиннонегативний рівень (ІНР) = Σ істинно негативнихΣ негативних станів | відношення правдоподібності негативного результату (ВП-) = ХНРІНР | ||||
Застосування
F-міру часто використовують в галузі інформаційного пошуку для вимірювання продуктивності пошуку, класифікації документів, та класифікації запитів.[5] Ранні праці зосереджувалися переважно на мірі F1, але з поширенням великомасштабних пошукових рушіїв цілі продуктивності змінилися на акцентування більшої уваги або на влучності, або на повноті,[6] тож Fβ помітно у широкому вжитку.
F-міру також використовують у машиннім навчанні.[7] Проте, F-міри не беруть до уваги істинно негативних, тож для оцінювання продуктивності бінарного класифікатора можуть віддавати перевагу коефіцієнтові кореляції Меттьюза чи каппі Коена.[8]
F-міра знайшла широкий вжиток в літературі з обробки природних мов,[9] наприклад, при оцінюванні розпізнавання іменованих сутностей та поділу на слова.
Критика
Девід Генд та інші критикують широке використання міри F1, оскільки вона надає однакової важливості влучності та повноті. На практиці, різні типи помилкової класифікації призводять до різних втрат. Іншими словами, відносна важливість влучності та повноти є одним із аспектів задачі.[10]
Згідно Давіде Чікко та Джузеппе Журмана, міра F1 є менш правдивою та інформативною для класифікації бінарного оцінювання, ніж коефіцієнт кореляції Меттьюза (ККМ, англ. Matthews correlation coefficient, MCC).[11]
Девід Пауерс вказав, що F1 ігнорує істинно негативні, й відтак є оманливою для незбалансованих класів, тоді як міри каппа та кореляції є симетричними, й оцінюють обидва напрямки передбачуваності — класифікатор, що передбачує істинний клас, та істинний клас, що передбачує передбачення класифікатора, пропонуючи окремі багатокласові міри поінформованості та маркованості для цих двох напрямків, зазначаючи, що їхнє середнє геометричне є кореляцією.[12]
Відмінність від індексу Фаулкса — Меттьюза
В той час як F-міра є середнім гармонійним повноти та влучності, індекс Фаулкса — Меттьюза є їхнім середнім геометричним.[13]
Розширення до багатокласової класифікації
F-міру також використовують для оцінювання задач із понад двома класами (багатокласова класифікація). В цій постановці остаточну міру отримують мікроусереднюванням (з упередженням за частотою класів) або макроусереднюванням (беручи всі класи однаково важливими). Для макроусереднювання застосовувачі використовувати дві різні формули: F-міру (арифметичних) середніх влучності та повноти по всіх класах, та арифметичне середнє F-мір по всіх класах, серед яких крайня виявляє бажаніші властивості.[14]
Див. також
- Матриця невідповідностей
- METEOR
- BLEU
- NIST (метрика)
- Робоча характеристика приймача
- ROUGE (метрика)
- Коефіцієнт невизначеності, відомий також як вправність (англ. proficiency)
- Частота помилкових слів
Примітки
- Гущин, І. В.; Сич, Д. О. (жовтень 2018). Аналіз впливу попередньої обробки тексту на результати текстової класифікації. Молодий вчений (Харківський національний університет імені В.Н. Каразіна) 10 (62): 264–266.
- Alguliyev, R. M.; Aliguliyev, R. M.; Imamverdiyev, Y. N.; Sukhostat, L. V. (2018). An improved ensemble approach for dos attacks detection. Радіоелектроніка, інформатика, управління 2: 73–82.
- Sasaki, Y. (2007). The truth of the F-measure. (англ.)
- Van Rijsbergen, C. J. (1979). Information Retrieval (вид. 2nd). Butterworth-Heinemann. (англ.)
- Beitzel., Steven M. (2006). On Understanding and Classifying Web Queries. IIT. Проігноровано невідомий параметр
|citeseerx=(довідка); Проігноровано невідомий параметр|degree=(довідка) (англ.) - X. Li; Y.-Y. Wang; A. Acero (July 2008). Learning query intent from regularized click graphs. Proceedings of the 31st SIGIR Conference. doi:10.1145/1390334.1390393. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Див., наприклад, оцінку . (англ.)
- Powers, David M. W (2015). «What the F-measure doesn't measure». arXiv:1503.06410 [cs.IR]. (англ.)
- Derczynski, L. (2016). Complementarity, F-score, and NLP Evaluation. Proceedings of the International Conference on Language Resources and Evaluation. (англ.)
- Hand, David. A note on using the F-measure for evaluating record linkage algorithms - Dimensions. app.dimensions.ai (англ.). doi:10.1007/s11222-017-9746-6. Процитовано 8 грудня 2018. Проігноровано невідомий параметр
|s2cid=(довідка); Проігноровано невідомий параметр|hdl-access=(довідка); Проігноровано невідомий параметр|hdl=(довідка) (англ.) - The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genomics 21 (6): 6. January 2020. PMC 6941312. PMID 31898477. doi:10.1186/s12864-019-6413-7. Проігноровано невідомий параметр
|vauthors=(довідка) (англ.) - Powers, David M W (2011). Evaluation: From Precision, Recall and F-Score to ROC, Informedness, Markedness & Correlation. Journal of Machine Learning Technologies 2 (1): 37–63. Проігноровано невідомий параметр
|hdl=(довідка) (англ.) -
Classification assessment methods. Applied Computing and Informatics (ahead-of-print). August 2018. doi:10.1016/j.aci.2018.08.003. Проігноровано невідомий параметр
|doi-access=(довідка); Проігноровано невідомий параметр|vauthors=(довідка) (англ.) - J. Opitz; S. Burst (2019). «Macro F1 and Macro F1». arXiv:1911.03347 [stat.ML]. (англ.)
