PageRank
PageRank — сімейство алгоритмів оцінки важливості веб-сторінок за допомогою розв'язання систем лінійних рівнянь. Для кожної сторінки обчислює дійсне число, чим більше число — тим «важливіша» сторінка[1].
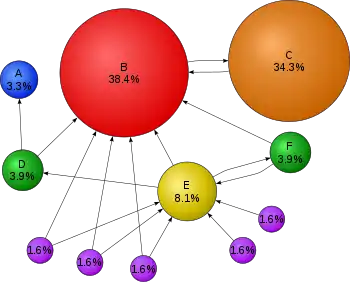
Замість прямого підрахунку кількості посилань PageRank інтерпретує посилання сторінки A на сторінку Б як голос сторінки A на користь сторінки Б. Після цього PageRank оцінює рейтинг сторінки відповідно до кількості отриманих голосів.
PageRank також враховує значимість кожної сторінки, що отримала голос, адже голоси деяких сторінок є важливішими, і відповідно до цього підвищується значущість сторінки, посилання на яку вони містять. Важливі сторінки отримують більш високу оцінку PageRank і відображаються на перших позиціях результатів пошуку. Для визначення значущості сторінки технологія Google використовує колективний інтелект всесвітньої мережі. Людина не бере участі в обробці результатів. Пошукова система Google не спотворює інформацію про позиції платою за результати пошуку.
Найбільший пейджранк серед українських ресурсів має Українська Вікіпедія, у якої він дорівнює 8, а також Українська правда та Газета День — по 7.[джерело?]
За основу PageRank був обраний академічний підхід оцінки важливості публікації автора по числу її згадок в бібліографічних посиланнях інших авторів. Для адаптації до застосування в Інтернет в алгоритм були внесені наступні зміни: вага кожного посилання враховується індивідуально і нормується за кількістю посилань на сторінці. Крім того, PageRank може бути інтерпретовано в термінах випадкового блукання.
Історія
Ідея розв'язання проблеми аналізу зв'язних даних шляхом обчислення власного вектора була запропонована в 1976 році Габріелем Пінскі та Френсіс Нарина, які працювали над складанням наукометричних рейтингів наукових журналів[2]. та в 1977 році Томасом Сааті в його концепції методу аналізу ієрархій, який зважував альтернативні варіанти.[3]
PageRank був створений в Стенфордському університеті Ларрі Пейджем і Сергієм Бріном в 1996 році[4] в рамках науково-дослідного проекту про новий вид інформаційно-пошукової системи.[5] Сергій Брін висловив ідею, що інформацію в Інтернеті можна впорядкувати в ієрархію за «популярністю посилань»: чим більше посилань на сторінку, тим вищий у неї ранг[6]. У створення нового алгоритму також зробили внесок Раджив Мотвані і Террі Виноград. Перша стаття, в якій описано PageRank і початковий прототип інформаційно-пошукової системи Google, була надрукована в 1998 році:[7] Трохи згодом Пейдж і Брін заснували Google Inc., компанію, що стоїть за інформаційно-пошуковою системою Google. Хоча PageRank є лише одним з чинників, що впливають на результати пошуку, цей алгоритм досі забезпечує основу для всіх інструментів веб-пошуку компанії Google[8].
Назва «PageRank» поєднала прізвище одного з винахідників, Ларрі Пейджа (англ. Page), а також концепцію веб-сторінки[9]. PageRank — зареєстрована торговельна марка компанії Google, а алгоритм було запатентовано U.S. Patent 6 285 999. Однак, цей патент належить Стенфордському університету, а не компанії Google. Google має ексклюзивні права на ліцензійне використання патенту Стенфордського університету. Натомість, університет отримав 1,8 млн акцій Google за дозвіл використання патенту; акції були продані в 2005 році за $336 млн[10][11].
PageRank був створений під впливом алгоритму аналізу цитованості, роботу над яким Євген Гарфілд розпочав у 1950-ті в університеті Пенсільванії, та Hyper Search розроблений Массімо Мархіорі в університеті Падуї. Того ж року, коли був оприлюднений алгоритм PageRank (1998), Джон Клейнберг опублікував свою роботу про алгоритм HITS. Засновники компанії Google посилаються на роботи Гарфілда, Мархіорі та Клейнберга у власних публікаціях[7][12].
Порівняно невелика інформаційно-пошукова система розробки Робіна Лі, «RankDex», що належала компанії IDD Information Services, вже в 1996 році використовувала схожий алгоритм для ранжування сайтів та сторінок[13]. Використаний в RankDex алгоритм був запатентований в 1999 році U.S. Patent 5 920 859 і згодом був використаний у заснованій в Китаїі Лі пошуковій системі Baidu[14][15]. Ларрі Пейдж посилався на роботу Лі в деяких патентах в США[16].
Обчислення PageRank
Огляд
Основною метою нового алгоритму було поліпшити якість відповідей на пошукові запити. Пошукові системи того часу значною мірою покладались на індексування сторінок за ключовими словами. Цим скористались зловмисники для маніпуляції результатами пошуку методом пошукового спаму. Розробники PageRank зазначили, що станом на листопад 1997 року, лише одна із найпоширеніших пошукових систем була здатна вказати власну сторінку в перших 10 результатах при запиті на власну назву (була здатна знайти сама себе)[7].
Запропонований алгоритм, натомість, брав до уваги структуру і текст гіперпосилань. При цьому:[1]
- Алгоритм PageRank моделював випадкову подорож користувача інтернет починаючи з випадкової сторінки. Чим більше випадкових відвідувачів діставались сторінки, тим вище її рейтинг. Розробники припустили, що в такий спосіб вдасться уникнути проблем зі спамом за ключовими словами.
- Вміст сторінки оцінювали не лише за ключовими словами в ній, а й в сторінках, що на неї посилаються. Розробники припустили, що зловмисникові буде важче спотворити вміст сторінок, що посилаються на його сторінку, тільки якщо він не контролює інші сторінки.
Значення PageRank для сторінки A обчислюється за такими правилами: нехай — сторінки, що посилаються (цитують) сторінку A. Алгоритм також використовує коефіцієнт демпінгу d, значенням якого знаходяться в проміжку між 0 та 1, та зазвичай має значення 0.85. Функція C(T) дорівнює кількості посилань, що виходять зі сторінки T. Тоді значення PageRank сторінки A, PR(A), дорівнює:[7]


При цьому, значення PageRank — це випадкові величини сума яких для всіх сторінок дорівнюватиме 1.
Випадкові подорожі
Для обчислення PageRank Веб представляється у вигляді орієнтованого графу, вершини якого відповідають сторінкам, а ребра — гіперпосиланням між ними. Нехай до пошукового індексу внесено n сторінок. Тоді для моделювання випадкової подорожі створюється матриця переходів M розміру . Елемент цієї матриці , що знаходиться в рядку i та стовпчику j має значення якщо сторінка з номером j має k вихідних посилань, серед яких є одне на сторінку з номером i. Якщо такого посилання нема, то елемент має значення 0[1].



Розподіл ймовірностей знаходження випадкового мандрівника може бути описано вектор-стовпчиком, рядок j якого дорівнюватиме ймовірності перебування на сторінці j[17]. Цей вектор відповідатиме найпростішому, ідеалізованому варіанту PageRank.
Припустімо, що мандрівник може розпочати блукання з будь-якої із n індексованих сторінок з однаковою ймовірністю. Тоді значення елементів початкового вектора дорівнюватимуть 1/n. Ймовірність знаходження на будь-якій зі сторінок на наступному кроці його блукання можна визначити обчисленням . Іще через крок — , і так далі. Таким чином, процес випадкового блукання є Марковським, а вектор розподілів v — власним для матриці M.


За умови, якщо:
- граф гіперпосилань зв'язний — тобто, з кожної вершини існує шлях до будь-якої іншої;
- в графі відсутні тупикові вершини — тобто, з кожної вершини є бодай одне вихідне гіперпосилання, то з часом розподіл ймовірностей знаходження мандрівника сягне границі: .

Проте, через те, що граф гіперпосилань реальної мережі Веб не завжди зв'язний та має тупикові вершини, у формулу випадкового блукання доводиться запровадити можливість випадкового «стрибка» на іншу вершину. Таким чином, формула обчислення розподілів знаходження матиме вигляд:[18]

- ,

де:
- β — константа, що зазвичай має значення в проміжку 0.8…0.9;
- e — одиничний вектор (розміром n, всі елементи якого дорівнюють 1);
- n — кількість індексованих сторінок, відповідно — кількість вершин графу;
- βM v — моделює випадок, коли з ймовірністю β мандрівник вирішує обрати вихідне посилання з поточної сторінки;
- (1 − β)e/n — вектор, кожен елемент якого дорівнює (1 − β)/n і який моделює появу мандрівника на будь-якій сторінці з ймовірністю (1 − β).
Уявіть собі ідеального веб-серфера, який переміщається по всесвітній павутині. Нехай серфер відвідує сторінку p, випадкове блукання при цьому знаходиться в стані p. На кожному кроці, веб-серфер або перестрибує на іншу сторінку в мережі, обрану псевдо-випадковим чином, або він слід за посиланням на поточній сторінці, при цьому не повертаючись і не відвідуючи одну і ту ж сторінку двічі. Імовірність випадкового стрибка позначимо як d тоді ймовірність переходу за посиланням буде 1-d. Таким чином, вірогідність знаходження користувача на сторінці p можна обчислити за такою формулою: де R (p) — PageRank сторінки, С (p) — число посилань на сторінці, к — число посилаються на p сторінок, d-коефіцієнт загасання (damping factor), зазвичай 0.1.
Якщо масштабувати PageRank таким чином, що де N — число всіх сторінок, для яких проводиться розрахунок PageRank, то R (p) можна розглядати як розподіл ймовірності по всіх сторінках. Для обчислення PageRank складається матриця M розміром NxN, де кожному елементу mij матриці присвоюється значення R0 (p) = 1 / C (p) в тому випадку, якщо з i-ї сторінки є посилання на j-ую, що все залишилися елементи матриці заповнюються нулями . Таким чином, обчислення PageRank зводиться до відшукання власного вектора матриці M що досягається множенням матриці M на вектор Rj на кожному кроці ітерації. Введення коефіцієнта загасання гарантує, що процес сходиться. Підвищуємо значимість сайту Усвідомивши переможну ходу PageRank, не можна не задуматися про його збільшення для своєї сторінки. Інтуїтивно зрозуміло, що чим авторитетніший ресурс, на якому розміщено посилання тим більше вона збільшує PageRank сторінки, на яку посилається. І навпаки, чим більше посилань на сторінці, тим менше буде її внесок у підвищення PageRank вашої сторінки — ще один доказ марності участі в FFA (Free For All — сайти, що містять набір посилань з вільним додаванням). Менш очевидна оптимальна топологія взаємно ссилающихся сторінок. Наприклад, сторінки організовані в «кільце» (коли кожна сторінка посилається на сусіда зліва і справа, остання посилається на першу, а перша на останню) будуть мати один і той же PageRank не залежно від кількості сторінок в кільці (якщо не проводити масштабування по сумі, то PageRank у всіх буде дорівнює 1).
Те ж справедливо для «зірок» або випадку, коли всі посилаються на всіх, і, ймовірно, це твердження справедливо взагалі для всіх симетричних топологій. Набагато більш перспективні з точки зору збільшення PageRank асиметричні топології. Твердження про марність створення «порожніх» (але посилаються один на одного) сайтів у безкоштовних хостерів не настільки очевидно. Наприклад, можна організувати обмін посиланнями на 5 сайтах таким чином, що в одного з них PageRank буде в 15 разів більше, ніж мінімальний не нульовий PageRank. У цьому нескладно переконатися, написавши невелику програмку. Деякі поширені помилки пов'язані з PageRank. Проаналізувавши повідомлення в форумах, присвячених позиціонуванню в пошукових системах, можна виділити цілий ряд тверджень про PageRank, як мінімум спірних, а часто просто невірних.
Застосування Page Rank в пошуковиках
Традиційні способи знаходження релевантних сторінок, у разі односкладових запитів не дають задовільних результатів, тому що попопулярних тем (наприклад «реферати», «робота») завжди знайдеться велика кількість сторінок з однаковою релевантністю. Для того, щоб якось впорядкувати такі сторінки, пошуковики вдаються до застосування різних інструментів[19].
Наприклад, видають першими ті сторінки, які мають велику відвідуваність (Rambler) або які присутні в каталозі (Yandex, Aport). В Google для цих цілей застосовують, зокрема, PageRank, що дає приголомшливі результати, і за короткий час Google став займати лідируючі позиції не тільки за обсягом бази, але і за якістю пошуку.
В березні 2016 року Google заявила, що усуне останню публічно доступну можливість дізнаватись PageRank сторінок — буде припинена робота модулів для веб-браузерів (Toolbar PageRank). Однак, алгоритм PageRank й надалі буде використаний в пошуковій системі для оцінки якості сторінок[20].
Публічний доступ до оцінок PageRank було піддано критиці, оскільки це начебто сприяло поширенню пошукової оптимізації з її негативними наслідками[21].
Примітки
- Jure Leskovec, Anand Rajaraman, Jeffrey D. Ullman (2014). 5.1 PageRank. Mining of Massive Datasets.
- Gabriel Pinski and Francis Narin. Citation influence for journal aggregates of scientific publications: Theory, with application to the literature of physics. Information Processing & Management 12 (5): 297–312. doi:10.1016/0306-4573(76)90048-0.
- Thomas Saaty (1977). A scaling method for priorities in hierarchical structures. Journal of Mathematical Psychology 15 (3): 234–281. doi:10.1016/0022-2496(77)90033-5.
- Raphael Phan Chung Wei (16 травня 2002). New Straits Times (вид. Computimes; 2).
- сторінку, Ларрі, Архівована копія. Архів оригіналу за 6 травня 2002. Процитовано 16 лютого 2019. Стенфордський проект електронної бібліотеки, говорити. 18 серпня 1997 (архів 2002)
- 187-сторінкове дослідження з університеті Граца, Австрія, включає в себе також увагу, що людський мозок використовуються при визначенні рангу сторінки в Google
- Brin, S.; Page, L. (1998). The anatomy of a large-scale hypertextual Web search engine. Computer Networks and ISDN Systems 30: 107–117. ISSN 0169-7552. doi:10.1016/S0169-7552(98)00110-X.
- Google Technology. Google.com. Процитовано 27 травня 2011.
- David Vise and Mark Malseed (2005). The Google Story. с. 37. ISBN 0-553-80457-X.
- Lisa M. Krieger (1 December 2005). Stanford Earns $336 Million Off Google Stock. San Jose Mercury News, cited by redOrbit. Процитовано 25 лютого 2009.
- Richard Brandt. Starting Up. How Google got its groove. Stanford magazine. Архів оригіналу за 10 березня 2009. Процитовано 25 лютого 2009.
- Page, Lawrence; Brin, Sergey; Motwani, Rajeev and Winograd, Terry (1999). The PageRank citation ranking: Bringing order to the Web. опублікованій в технічному звіті 29 січня 1998 у форматі PDF
- Li, Yanhong (August 6, 2002). Toward a qualitative search engine. Internet Computing, IEEE (IEEE Computer Society) 2 (4): 24–29. doi:10.1109/4236.707687.
- Andy Greenberg (5 жовтня 2009). The Man Who's Beating Google. Forbes.
- «About RankDex», rankdex.com
- Див особливо Лоуренс Пейдж, патенти США U.S. Patent 6 799 176 (2004) «Метод для озвучування документів у пов'язаної бази даних», U.S. Patent 7 058 628 (2006) «Метод для вузла рейтингу в пов'язаної бази даних», і U.S. Patent 7 269 587 (2007) «Залікові документи у зв'язаному базі даних» +2011
- (Mining of Massive Datasets, стор. 167)
- (Mining of Massive Datasets, стор. 174)
- Архівована копія. Архів оригіналу за 2 грудня 2013. Процитовано 2 грудня 2013.
- Barry Schwartz (8 березня 2016). Google has confirmed it is removing Toolbar PageRank. Search Engine Land.
- Danny Sullivan (9 березня 2016). RIP Google PageRank score: A retrospective on how it ruined the web. Search Engine Land.