Лінійний класифікатор
У галузі машинного навчання метою статистичної класифікації є використання характеристик об'єкту для ідентифікації класу (або групи), до якої він належить. Ліні́йний класифіка́тор (англ. linear classifier) досягає цього ухваленням рішення про класифікацію на основі значення лінійної комбінації цих характеристик. Характеристики об'єкту відомі також як значення ознак, і зазвичай представляються машині у векторі, що називається вектором ознак. Такі класифікатори добре працюють для таких практичних задач, як класифікація документів, і, загальніше, для задач із багатьма змінними (ознаками), досягаючи рівнів точності, порівнянних з нелінійними класифікаторами, у той же час беручи менше часу на тренування та застосування.[1]
Визначення
Якщо вектор ознак на вході класифікатора є дійсним вектором , то вихідною оцінкою є


де є дійсним вектором вагових коефіцієнтів, а f — функцією, яка перетворює скалярний добуток двох векторів на бажаний вихід. (Іншими словами, є 1-формою, або лінійним функціоналом, що відображує на R.) Ве́ктора вагових коефіцієнтів навчаються з набору мічених тренувальних зразків. Часто f є простою функцією, яка відображує всі значення понад певний поріг до першого класу, а всі інші — до другого. Складніша f може давати ймовірність приналежності елемента до певного класу.

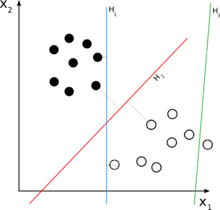
Для двокласової задачі класифікації роботу лінійного класифікатора можна візуалізувати розділенням вхідного простору високої вимірності гіперплощиною: всі точки по один бік від гіперплощини класифікуються як «так», а всі інші — як «ні».
Лінійний класифікатор часто застосовується в ситуаціях, коли швидкість класифікації є проблемою, оскільки часто він є найшвидшим класифікатором, особливо коли є розрідженим. Лінійний класифікатор також часто дуже добре працює тоді, коли число вимірів є великим, як у класифікації документів, де кожен з елементів зазвичай є кількістю траплянь якогось слова в документі (див. документно-термінну матрицю). У таких випадках класифікатор повинен бути добре регуляризованим.
Породжувальні та розрізнювальні моделі
Є два широкі класи методів визначення параметрів лінійного класифікатора . Вони можуть бути породжувальними та розрізнювальними моделями.[2][3] Методи першого класу моделюють функції умовної густини . До прикладів таких алгоритмів належать:

- Лінійний дискримінантний аналіз (або лінійний дискримінант Фішера) (ЛДА, англ. LDA) — передбачає ґаусові моделі умовної густини.
- Наївний баєсів класифікатор з поліноміальними або багатовимірними моделями подій Бернуллі.
Другий набір методів включає розрізнювальні моделі, які намагаються максимізувати якість виходу на тренувальному наборі. Додаткові члени в тренувальній функції витрат можуть легко виконувати регуляризацію кінцевої моделі. До прикладів розрізнювального тренування лінійних класифікаторів належать:
- Логістична регресія — оцінка максимальної правдоподібності , виходячи з того, що спостережуваний тренувальний набір було породжено біноміальною моделлю, яка залежить від виходу класифікатора.
- Перцептрон — алгоритм, який намагається виправити всі помилки, що зустрілися в тренувальному наборі.
- Опорно-векторна машина — алгоритм, який максимізує розділення між гіперплощиною рішення та зразками тренувального набору.
Зауваження: Незважаючи на свою назву, ЛДА в цій систематиці не належить до класу розрізнювальних моделей. Проте його назва має сенс, коли ми порівнюємо ЛДА з іншим основним алгоритмом зниження розмірності, методом головних компонент (МГК, англ. principal components analysis, PCA). ЛДА є алгоритмом керованого навчання, який використовує мітки даних, тоді як МГК є алгоритмом спонтанного навчання, який мітки ігнорує. У підсумку, ця назва є історичним артефактом.[4]
Розрізнювальне тренування часто видає вищу точність, ніж моделювання функцій умовної густини. Проте робота з пропущеними даними часто є простішою з моделями умовної густини.
Всі перелічені вище алгоритми лінійної класифікації може бути перетворено на нелінійні алгоритми, що діють на відмінному вхідному просторі , за допомогою ядрового трюку.

Розрізнювальне тренування
Розрізнювальне тренування лінійних класифікаторів, як правило, здійснюється керованим чином, за допомогою алгоритму оптимізації, якому надається тренувальний набір із бажаними виходами, та функція втрат, яка задає міру невідповідності між виходами класифікатора, та бажаними. Таким чином, алгоритм навчання розв'язує задачу оптимізації наступного вигляду:[1]

де
- w — вектор параметрів класифікатора,
- L(yi, wTxi) — функція втрат, яка задає міру невідповідності між передбаченням класифікатора та справжнім виходом yi для i-того тренувального зразка,
- R(w) — функція регуляризації, яка запобігає завеликим значенням параметрів (що спричиняє перенавчання), і
- C — скалярна стала (встановлена користувачем алгоритму навчання), яка контролює баланс між регуляризацією та функцією втрат.
До популярних функцій втрат належать заві́сні втрати (для лінійних ОВМ) та лог-втрати (для лінійної логістичної регресії). Якщо функція регуляризації R є опуклою, то наведене вище є опуклою задачею.[1] Існує багато алгоритмів розв'язання таких задач; до популярних для лінійної класифікації належать (стохастичний) градієнтний спуск, L-BFGS, координатний спуск та методи Ньютона.
Див. також
- Зворотне поширення
- Лінійна регресія
- Перцептрон
- Квадратичний класифікатор
- Опорно-векторні машини
- Winnow (алгоритм)
Примітки
- Guo-Xun Yuan; Chia-Hua Ho; Chih-Jen Lin (2012). Recent Advances of Large-Scale Linear Classification. Proc. IEEE 100 (9). (англ.)
- T. Mitchell, Generative and Discriminative Classifiers: Naive Bayes and Logistic Regression. Draft Version, 2005 (англ.)
- A. Y. Ng and M. I. Jordan. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and Naive Bayes. in NIPS 14, 2002. (англ.)
- R.O. Duda, P.E. Hart, D.G. Stork, «Pattern Classification», Wiley, (2001). ISBN 0-471-05669-3 (англ.)
Література
- Y. Yang, X. Liu, "A re-examination of text categorization", Proc. ACM SIGIR Conference, pp. 42–49, (1999). paper @ citeseer (англ.)
- R. Herbrich, "Learning Kernel Classifiers: Theory and Algorithms," MIT Press, (2001). ISBN 0-262-08306-X (англ.)