Перцептрон
Перцептро́н, або персептро́н (англ. perceptron від лат. perceptio — сприйняття; нім. perzeptron) — математична або комп'ютерна модель сприйняття інформації мозком (кібернетична модель мозку), запропонована Френком Розенблатом в 1957 році[1] й реалізована у вигляді електронної машини «Марк-1»[nb 1] у. 1960 році. Перцептрон став однією з перших моделей нейромереж, а «Марк-1» — першим у світі нейрокомп'ютером. Незважаючи на свою простоту, перцептрон здатен навчатися і розв'язувати досить складні завдання. Основна математична задача, з якою він здатний впоратися — це лінійне розділення довільних нелінійних множин, так зване забезпечення лінійної сепарабельності.
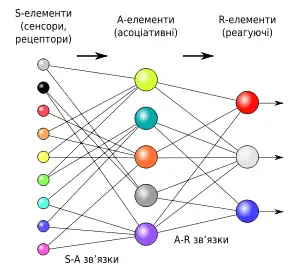
Перцептрон складається з трьох типів елементів, а саме: сигнали, що надходять від давачів, передаються до асоціативних елементів, а відтак до реагуючих. Таким чином, перцептрони дозволяють створити набір «асоціацій» між вхідними стимулами та необхідною реакцією на виході. В біологічному плані це відповідає перетворенню, наприклад, зорової інформації у фізіологічну відповідь рухових нейронів. Відповідно до сучасної термінології, перцептрони може бути класифіковано як штучні нейронні мережі:
- з одним прихованим шаром;[nb 2]
- з пороговою передавальною функцією;
- з прямим розповсюдженням сигналу.
На тлі зростання популярності нейронних мереж у 1969 році вийшла книга Марвіна Мінського та Сеймура Пейперта, що показала принципові обмеження перцептронів. Це призвело до зміщення інтересу дослідників штучного інтелекту в протилежну від нейромереж область символьних обчислень.[nb 3] Крім того, через складність математичного аналізу перцептронів, а також відсутність загальноприйнятої термінології, виникли різні неточності і помилки.
Згодом інтерес до нейромереж, і зокрема, робіт Розенблата, поновився. Так, наприклад, зараз стрімко розвивається біокомп'ютинг, що у своїй теоретичній основі обчислень, зокрема, базується на нейронних мережах, а перцептрон відтворюють на базі бактеріородопсинмісних плівок.
Поява перцептрона
У 1943 році в своїй статті «Логічне числення ідей, що стосуються нервової активності»[2] Воррен Маккалох і Волтер Піттс запропонували поняття штучної нейронної мережі. Зокрема, ними було запропоновано модель штучного нейрону. Дональд Гебб в роботі «Організація поведінки»[3] 1949 року описав основні принципи навчання нейронів.
Ці ідеї кілька років пізніше розвинув американський нейрофізіолог Френк Розенблат. Він запропонував схему пристрою, що моделює процес людського сприйняття, і назвав його «перцептроном». Перцептрон передавав сигнали від фотоелементів, що являють собою сенсорне поле, в блоки електромеханічних елементів пам'яті. Ці комірки з'єднувалися між собою випадковим чином відповідно до принципів конекціонізму. 1957 року в Корнельській лабораторії аеронавтики було успішно завершено моделювання роботи перцептрона на комп'ютері IBM 704, а двома роками пізніше, 23 червня 1960 року в Корнельському університеті, було продемонстровано перший нейрокомп'ютер — «Марк-1», що був здатен розпізнавати деякі з літер англійського алфавіту.[4][5]

Щоби «навчити» перцептрон класифікувати образи, було розроблено спеціальний ітераційний метод навчання проб і помилок, що нагадує процес навчання людини — метод корекції помилки.[6] Крім того, при розпізнанні тієї чи іншої літери перцептрон міг виділяти характерні особливості літери, що статистично зустрічаються частіше, ніж незначні відмінності в індивідуальних випадках. Таким чином, перцептрон був здатен узагальнювати літери, написані по-різному (різним почерком), в один узагальнений образ. Проте можливості перцептрона були обмеженими: машина не могла надійно розпізнавати частково закриті літери, а також літери іншого розміру, розташовані зі зсувом або поворотом відносно тих, що використовувалися на етапі її навчання.[7]
Звіт про перші результати з'явився ще 1958 року — тоді Розенблат було опубліковано статтю «Перцептрон: Ймовірна модель зберігання та організації інформації в головному мозку».[8] Але докладніше свої теорії та припущення щодо процесів сприйняття і перцептронів він описує 1962 року в книзі «Принципи нейродинаміки: Перцептрони та теорія механізмів мозку». У книзі він розглядає не лише вже готові моделі перцептрону з одним прихованим шаром, але й багатошарових перцептронів з перехресними (третій розділ) і зворотніми (четвертий розділ) зв'язками. В книзі також вводиться ряд важливих ідей та теорем, наприклад, доводиться теорема збіжності перцептрону.[9]
Опис елементарного перцептрона
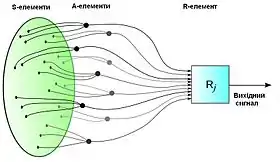
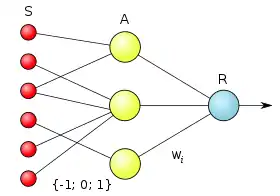
Елементарний перцептрон складається з елементів трьох типів: S-елементів, A-елементів та одного R-елементу. S-елементи — це шар сенсорів, або рецепторів. У фізичному втіленні вони відповідають, наприклад, світлочутливим клітинам сітківки ока або фоторезисторам матриці камери. Кожен рецептор може перебувати в одному з двох станів — спокою або збудження, і лише в останньому випадку він передає одиничний сигнал до наступний шару, асоціативним елементам.
A-елементи називаються асоціативними, тому що кожному такому елементові, як правило, відповідає цілий набір (асоціація) S-елементів. A-елемент активізується, щойно кількість сигналів від S-елементів на його вході перевищує певну величину θ.[nb 4]
Сигнали від збуджених A-елементів, своєю чергою, передаються до суматора R, причому сигнал від i-го асоціативного елемента передається з коефіцієнтом .[10] Цей коефіцієнт називається вагою A-R зв'язку.

Так само як і A-елементи, R-елемент підраховує суму значень вхідних сигналів, помножених на ваги (лінійну форму). R-елемент, а разом з ним і елементарний перцептрон, видає «1», якщо лінійна форма перевищує поріг θ, інакше на виході буде «-1». Математично, функцію, що реалізує R-елемент, можна записати так:

Навчання елементарного перцептрона полягає у зміні вагових коефіцієнтів зв'язків A-R. Ваги зв'язків S-A (які можуть приймати значення (-1; 0; 1)) і значення порогів A-елементів вибираються випадковим чином на самому початку і потім не змінюються. (Опис алгоритму див. нижче.)
Після навчання перцептрон готовий працювати в режимі розпізнавання[11] або узагальнення.[12] У цьому режимі перцептрону пред'являються раніше невідомі йому об'єкти, й він повинен встановити, до якого класу вони належать. Робота перцептрона полягає в наступному: при пред'явленні об'єкта, збуджені A-елементи передають сигнал R-елементу, що дорівнює сумі відповідних коефіцієнтів . Якщо ця сума позитивна, то ухвалюється рішення, що даний об'єкт належить до першого класу, а якщо вона негативна — то до другого.[13]
Основні поняття теорії перцептронів
Серйозне ознайомлення з теорією перцептронів вимагає знання базових визначень і теорем, сукупність яких і являє собою базову основу для всіх наступних видів штучних нейронних мереж. Але, як мінімум, необхідно розуміння хоча б з точки зору теорії сигналів, що є оригінальним, тобто описане автором перцептрону Ф. Розенблатом.
Опис на основі сигналів
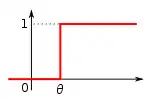
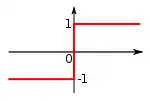
Для початку визначмо складові елементи перцептрона, які є частковими випадками штучного нейрону з пороговою функцією передачі.
- Простим S-елементом (сенсорним) є чутливий елемент, який від дії будь-якого з видів енергії (наприклад, світла, звуку, тиску, тепла тощо) виробляє сигнал. Якщо вхідний сигнал перевищує певний поріг θ, на виході елемента отримуємо +1, в іншому випадку — 0.[14]
- Простим A-елементом (асоціативним) називається логічний елемент, який дає вихідний сигнал +1, коли алгебраїчна сума його вхідних сигналів дорівнює або перевищує деяку граничну величину θ (кажуть, що елемент Активний), в іншому випадку вихід дорівнює нулю.[14]
- Простим R-елементом (таким, що реагує, тобто діє) називається елемент, який видає сигнал +1, якщо сума його вхідних сигналів є суворо додатною, і сигнал −1, якщо сума його вхідних сигналів є суворо від'ємною. Якщо сума вхідних сигналів дорівнює нулю, вихід вважається або рівним нулю, або невизначеним.[14]
Якщо на виході будь-якого елемента ми отримуємо 1, то кажуть, що елемент активний або збуджений.
Всі розглянуті елементи називаються простими, тому що вони реалізують стрибкоподібні функції. Розенблат стверджував, що для розв'язання складніших завдань можуть знадобитися інші види функцій, наприклад, лінійна.[15]
В результаті Розенблат ввів такі визначення:
- Перцептрон являє собою мережу, що складається з S-, A- та R-елементів, зі змінною матрицею взаємодії W (елементи якої — вагові коефіцієнти), що визначається послідовністю минулих станів активності мережі.[15][16]
- Перцептроном з послідовними зв'язками називається система, в якій всі зв'язки, що починаються від елементів з логічною відстанню d від найближчого S-елементу, закінчуються на елементах з логічною відстанню d+1 від найближчого S-елементу.[16]
- Простим перцептроном називається будь-яка система, що задовольняє наступні п'ять умов:

- в системі є лише один R-елемент (природно, він пов'язаний з усіма A-елементами);
- система являє собою перцептрон з послідовними зв'язками, що йдуть лише від S-елементів до A-елементів, та від A-елементів до R-елементів;
- ваги всіх зв'язків від S-елементів до A-елементів (S-A зв'язків) незмінні;
- час передачі кожного зв'язку дорівнює або нулю, або сталій величині ;
- всі функції активації S-, A-, R-елементів мають вигляд , де — алгебраїчна сума всіх сигналів, що надходять одночасно на вхід елемента [15][17]




- Елементарним перцептроном називається простий перцептрон, у якоговсі елементи — прості. У цьому випадку його функція активації має вигляд .[18]

Додатково можна вказати на такі концепції, запропоновані в книзі, та пізніше розвинені в рамках теорії нейронних мереж:
- Перцептрон із перехресними зв'язками — це система, в якій існують зв'язки між елементами одного типу (S, A або R), що знаходяться на однаковій відстані від S-елементів, причому всі інші зв'язки — послідовного типу.[16]
- Перцептрон зі зворотнім зв'язком — це система, в якій існує хоча б один зв'язок від логічно віддаленішого елемента до менш віддаленого.[16] Згідно сучасної термінології такі мережі називаються рекурентними нейронними мережами.
- Перцептрон зі змінними S-A зв'язками — це система, в якій знято обмеження на фіксованість зв'язків від S-елементів до A-елементів. Доведено, що шляхом оптимізації S-A зв'язків можна досягти значного поліпшення характеристик перцептрона.[19]
Опис на основі предикатів
Детальніші відомості з цієї теми ви можете знайти в статті Перцептрон (предикативний опис).
Марвін Мінський вивчав властивості паралельних обчислень, окремим випадком яких на той час був перцептрон. Для аналізу його властивостей йому довелося перекласти теорію перцептронів на мову предикатів. Суть підходу полягала в наступному:[nb 5][20]
- множині сигналів від S-елементів було поставлено у відповідність змінну X;
- кожному A-елементові поставлено у відповідність предикат φ(X) (фі від ікс), названий частинним предикатом;
- кожному R-елементові поставлено у відповідність предикат ψ (псі), що залежить від частинних предикатів;
- нарешті, перцептроном було названо пристрій, здатний обчислювати всі предикати типу ψ.
В «зоровому» перцептроні змінна X символізувала образ будь-якої геометричної фігури (стимул). Частинний предикат дозволяв кожному А-елементові «розпізнавати» свою фігуру. Предикат ψ означав ситуацію, коли лінійна комбінація ( — коефіцієнти передачі) перевищувала певний поріг θ.


Науковці виділили 5 класів перцептронів, що володіють, на їхню думку, цікавими властивостями:
- Перцептрони, обмежені за діаметром — кожна фігура X, що розпізнається частинними предикатами, не перевищує за діаметром деяку фіксовану величину.
- Перцептрони обмеженого порядку — кожен частинний предикат залежить від обмеженої кількості точок з X.
- Перцептрони Гамба — кожен частинний предикат повинен бути лінійною пороговою функцією, тобто міні-перцептроном.
- Випадкові перцептрони — перцептрони обмеженого порядку, коли частинні предикати являють собою випадково вибрані булеві функції. В книзі зазначається, що саме цю модель найдокладніше досліджувала група Розенблата.
- Обмежені перцептрони — множина частинних предикатів нескінченна, а множина можливих значень коефіцієнтів скінченна.
Хоча такий математичний апарат дозволив застосувати цей аналіз лише до елементарного перцептрону Розенблата, він розкрив багато принципових обмежень для паралельних обчислень, які має кожен вид сучасних штучних нейронних мереж.
Історична класифікація
Поняття перцептрона має цікаву, але незавидну історію. В результаті нерозвиненої термінології нейронних мереж минулих років, різкої критики та нерозуміння завдань дослідження перцептронів, а іноді й помилкового освітлення пресою, початковий сенс цього поняття було викривлено. Порівнюючи розробки Розенблата та сучасні огляди й статті, можна виділити 4 доволі відособлених класи перцептронів:
- Перцептрон з одним прихованим шаром
- Це класичний перцептрон, що йому присвячено більшу частина книги Розенблата, і що розглядається в цій статті: у нього є по одному шару S-, A- та R-елементів.
- Одношаровий перцептрон
- Це модель, у якій вхідні елементи безпосередньо з'єднано з вихідними за допомогою системи ваг. Є найпростішою мережею прямого поширення — лінійним класифікатором, і окремим випадком класичного перцептрона, в якому кожен S-елемент однозначно відповідає одному A-елементові, S-A зв'язку мають вагу +1, і всі A-елементи мають поріг θ = 1. Одношарові перцептрони фактично є формальними нейронами, тобто пороговими елементами Мак-Каллока — Піттса. Вони мають безліч обмежень, зокрема, вони не можуть ідентифікувати ситуацію, коли на їхні входи подано різні сигнали («завдання XOR», див нижче).
- Багатошаровий перцептрон Розенблатта
- Це перцептрон, в якому присутні додаткові шари A-елементів. Його аналіз провів Розенблат у третій частині своєї книги.
- Багатошаровий перцептрон Румельхарта
- Це перцептрон, в якому присутні додаткові шари A-елементів, причому навчання такої мережі проводиться за методом зворотного поширення помилки, і навчаються всі шари перцептрону (включно з S-A). Є окремим випадком багатошарового перцептрону Розенблата.
В даний час в літературі під терміном «перцептрон» найчастіше розуміють одношаровий перцептрон (англ. single-layer_perceptron), причому існує поширена омана, що саме цей найпростіший тип моделей запропонував Розенблат. На противагу одношаровому, ставлять «багатошаровий перцептрон» (англ. multilayer perceptron), знову ж таки, найчастіше маючи на увазі багатошаровий перцептрон Румельхарта, а не Розенблата. Класичний перцептрон у такій дихотомії відносять до багатошарових.
Алгоритми навчання
Важливою властивістю будь-якої нейронної мережі є здатність до навчання. Процес навчання є процедурою налаштування ваг та порогів з метою зменшення різниці між бажаними (цільовими) та отримуваними векторами на виході. У своїй книзі Розенблат намагався класифікувати різні алгоритми навчання перцептрону, називаючи їх системами підкріплення.
- Система підкріплення — це будь-який набір правил, на підставі яких можна змінювати з плином часу матрицю взаємодії (або стан пам'яті) перцептрону.[21]
Описуючи ці системи підкріплення і уточнюючи можливі їхні види, Розенблат ґрунтувався на ідеях Д. Гебба про навчання, запропонованих ним 1949 року, які можна перефразувати в наступне правило, яке складається з двох частин:
- Якщо два нейрони з обох боків синапсу (з'єднання) активізуються одночасно (тобто синхронно), то міцність цього з'єднання зростає.
- Якщо два нейрони з обох боків синапсу активізуються асинхронно, то такий синапс послаблюється або взагалі відмирає.
Навчання з учителем
Класичний метод навчання перцептрону — це метод корекції помилки.[9] Він являє собою такий вид навчання з учителем, при якому вага зв'язку не змінюється до тих пір, поки поточна реакція перцептрона залишається правильною. При появі неправильної реакції вага змінюється на одиницю, а знак (+/-) визначається протилежним від знаку помилки.
Припустимо, ми хочемо навчити перцептрон розділяти два класи об'єктів так, щоби при пред'явленні об'єктів першого класу вихід перцептрона був позитивний (+1), а при пред'явленні об'єктів другого класу — негативним (-1). Для цього виконаємо наступний алгоритм:[6]
- Випадково вибираємо пороги для A-елементів та встановлюємо зв'язки S-A (далі вони не змінюватимуться).
- Початкові коефіцієнти вважаємо рівними нулеві.
- Пред'являємо навчальну вибірку: об'єкти (наприклад, кола або квадрати) із зазначенням класу, до якого вони належать.
- Показуємо перцептронові об'єкт першого класу. При цьому деякі A-елементи збудяться. Коефіцієнти , що відповідають цим збудженням елементів, збільшуємо на 1.
- Пред'являємо об'єкт другого класу, і коефіцієнти тих А-елементів, які збудилися при цьому показі, зменшуємо на 1.
- Обидві частини кроку 3 виконаємо для всієї навчальної вибірки. В результаті навчання сформуються значення вагів зв'язків .
Теорема збіжності перцептрону,[9] описана і доведена Ф. Розенблатом (за участю Блока, Джозефа, Кеста та інших дослідників, які працювали разом з ним), показує, що елементарний перцептрон, навчений за таким алгоритмом, незалежно від початкового стану вагових коефіцієнтів і послідовності появи стимулів завжди приведе до досягнення рішення за скінченний проміжок часу.
Навчання без учителя
Крім класичного методу навчання перцептрону, Розенблат також ввів поняття про навчання без учителя, запропонувавши наступний спосіб навчання:
- Альфа-система підкріплення — це система підкріплення, за якої ваги всіх активних зв'язків , що ведуть до елемента , змінюються на однакову величину r, а ваги неактивних зв'язків за цей час не змінюються.[22]


Пізніше, з розробкою поняття багатошарового перцептрону, альфа-систему було модифіковано, і її стали називати дельта-правилом. Модифікацію було проведено з метою зробити функцію навчання диференційовною (наприклад, сигмоїдною), що в свою чергу потрібно для застосування методу градієнтного спуску, завдяки якому можливе навчання більше ніж одного шару.
Метод зворотного поширення помилки
Для навчання багатошарових мереж ряд учених, у тому числі Д. Румельхартом, було запропоновано градієнтний алгоритм навчання з учителем, що проводить сигнал помилки, обчислений виходами перцептрона, до його входів, шар за шаром. Зараз це є найпопулярніший метод навчання багатошарових перцептронів. Його перевага в тому, що він може навчити всі шари нейронної мережі, і його легко прорахувати локально. Однак цей метод є дуже довгим, до того ж, для його застосування потрібно, щоб передавальна функція нейронів була диференційовною. При цьому в перцептронах довелося відмовитися від бінарного сигналу, і користуватися на вході неперервними значеннями.[23]
Традиційні помилки
В результаті популяризації штучних нейронних мереж журналістами та маркетологами було допущено ряд неточностей, які, при недостатньому вивченні оригінальних робіт з цієї тематики, неправильно тлумачилися молодими (на той час) науковцями. В результаті до сьогодні можна зустрітися з недостатньо глибоким трактуванням функціональних можливостей перцептрона у порівнянні з іншими нейронними мережами, розробленими в наступні роки.
Термінологічні неточності
Найпоширенішою помилкою, пов'язаною з термінологією, є визначення перцептрона як нейронної мережі без прихованих шарів (одношарового перцептрона, див. вище). Ця помилка пов'язана з недостатньо проробленою термінологією в галузі нейромереж на ранньому етапі їхньої розробки. Ф.&nsp;Уоссерменом було зроблено спробу певним чином класифікувати різні види нейронних мереж:
Як видно з публікацій, немає загальноприйнятого способу підрахунку кількості шарів в мережі. Багатошарова мережа складається з множин нейронів і ваг, що чергуються. Вхідний шар не виконує підсумовування. Ці нейрони слугують лише як розгалуження для першої множини ваг, і не впливають на обчислювальні можливості мережі. З цієї причини перший шар не беруть до уваги при підрахунку шарів, і мережа вважається двошаровою, оскільки лише два шари виконують обчислення. Далі, ваги шару вважаються пов'язаними з наступними за ними нейронами. Отже, шар складається з множини ваг з наступними за ними нейронами, що підсумовують зважені сигнали.[24]
В результаті такого подання перцептрон потрапив під визначення «одношарова нейронна мережа». Частково це вірно, тому що в нього немає прихованих шарів нейронів, які навчаються (ваги яких адаптуються до задачі). І тому всю сукупність фіксованих зв'язків системи з S- до A-елементів, можна логічно замінити набором (модифікованих за жорстким правилом) нових вхідних сигналів, що надходять відразу на А-елементи (усунувши тим самим взагалі перший шар зв'язків). Але тут як раз не враховують те, що така модифікація перетворює нелінійне подання завдання в лінійне.
Тому просте ігнорування шарів із фіксованими зв'язками що не навчаються (в елементарному перцептроні це S-A зв'язки) призводить до неправильних висновків про можливості нейромережі. Так, Мінський вчинив дуже коректно, переформулювавши А-елемент як предикат (тобто функцію); навпаки, Уоссермен вже втратив таке подання і у нього А-елемент — просто вхід (майже еквівалентний S-елементу). За такої термінологічної плутанини не береться до уваги той факт, що в перцептроні відбувається відображення рецепторного поля S-елементів на асоціативне поле А-елементів, в результаті чого й відбувається перетворення будь-якої лінійно нероздільної задачі на лінійно роздільну.
Функціональні помилки
Більшість функціональних помилок зводяться до нібито неможливості вирішення перцептроном нелінійно роздільної задачі. Але варіацій на цю тему досить багато, нижче розглянуто головні з них.
Завдання XOR
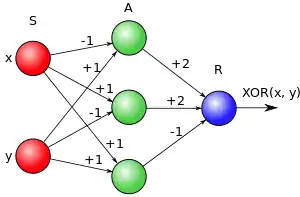
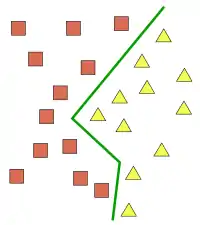
Перцептрон не здатен розв'язати «задачу XOR».
- Дуже поширена й найнесерйозніша заява. На ілюстрації праворуч зображено розв'язання цієї задачі перцептроном. Ця помилка виникає, по-перше, через те, що неправильно інтерпретують визначення перцептрона, даного Мінським (див. вище), а саме, предикати відразу прирівнюють до входів, хоча предикат у Мінського — це функція, що ідентифікує цілий набір вхідних значень.[nb 6] По-друге, через те, що класичний перцептрон Розенблата плутають з одношаровим перцептроном (через термінологічні неточності, описані вище).
Слід звернути увагу на те, що «одношаровий перцептрон» у сучасній термінології та «одношаровий перцептрон» в термінології Уоссермена є різними об'єктами. І об'єкт, що зображено на ілюстрації, в термінології Уоссермена є двошаровим перцептроном.
Доцільно зазначити, що при реалізації одношарового персептрону можна використати нелінійні функції класифікації. Це розширює його функціональні можливості, не змінюючи структуру. Такий підхід дозволяє зняти частину функціональних обмежень, зокрема, реалізувати логічну функцію XOR.[25]
Здатність до навчання розв'язання лінійно нероздільних задач
Вибором випадкових вагів можна досягти навчання розв'язання лінійно нероздільних (взагалі, будь-яких) задач, але тільки якщо пощастить, і в нових змінних (виходах A-нейронів) задача виявиться лінійно роздільною. Проте може й не пощастити.
- Теорема збіжності перцептрону[9] доводить, що немає і не може бути ніякого «може і не пощастити»; при рівності А-елементів кількості стимулів і не особливій G-матриці — імовірність рішення дорівнює 100 %. Тобто при відображенні рецепторного поля на асоціативне поле, розмірності більшої на одну, випадковим (нелінійним) оператором, нелінійна задача перетворюється на лінійно роздільну. А наступний шар, що навчається, вже знаходить лінійний розв'язок в іншому просторі входів.
- Наприклад, навчання перцептрона для розв'язання «задачі XOR» (див. ілюстрацію) проводиться наступними етапами:
| Ваги | Ітерації | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||||
| w1 | 0 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
| w2 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 |
| w3 | −1 | 0 | 1 | 0 | −1 | 0 | −1 | 0 | −1 |
| Вхідні сигнали (x, y) | 1, 1 | 0, 1 | 1, 0 | 1, 1 | 1, 1 | 0, 1 | 1, 1 | 1, 0 | 1, 1 |
Здатність до навчання на малій кількості прикладів
Якщо в задачі розмірність входів досить висока, а навчальних прикладів мало, то в такому «слабо заповненому» просторі кількість успіхів може і не виявитися малою. Це свідчить лише про часткову придатність перцептрону, а не про його універсальність.
- Цей аргумент легко перевірити на тестовій задачі під назвою «шахівниця» або «губка з водою»:[26][nb 7]
Дано ланцюжок з 2·Nодиниць або нулів, що паралельно надходять на входи перцептрону. Якщо цей ланцюжок є дзеркально симетричним відносно центру, то на виході буде 1, інакше — 0. Навчальні приклади — всі (це важливо) ланцюжків.

- Можуть бути варіації даної задачі, наприклад:
Візьмімо чорно-біле зображення розміром 256 × 256 елементів (пікселів). Вхідними даними для перцептрона будуть координати точки (8 біт + 8 біт, разом потрібно 16 S-елементів), на виході вимагатимемо отримати колір точки. Навчаємо перцептрон усім точкам (всьому зображенню). В результаті маємо 65 536 різних пар «стимул-реакція». Навчити без помилок.
- Якщо цей аргумент справедливий, то перцептрон не зможе ні за яких умов навчитися, не роблячи жодної помилки. Інакше перцептрон не помилиться жодного разу.
- На практиці виявляється, що дана задача є дуже простою для перцептрону: щоб її розв'язати, перцептронові достатньо 1 500 А-елементів (замість повних 65 536, необхідних для будь-якої задачі). При цьому кількість ітерацій є порядку 1 000. При 1 000 А-елементах перцептрон не сходиться за 10 000 ітерацій. Якщо ж збільшити кількість А-елементів до 40 000, то сходження можна чекати за 30-80 ітерацій.
- Такий аргумент з'являється через те, що дану задачу плутають із задачею Мінського «про предикат „парність“».[27]
Стабілізація ваг та збіжність
У перцептроні Розенблата стільки А-елементів, скільки входів. І збіжність за Розенблатом — це стабілізація ваг.
- У Розенблата читаємо:
Якщо кількість стимулів у просторі W дорівнює n > N (тобто більше кількості А-елементів елементарного перцептрону), то існує деяка класифікація С(W), для якої розв'язку не існує.[28]
- Звідси випливає, що:
- у Розенблата кількість А-елементів дорівнює кількості стимулів (навчальних прикладів), а не кількості входів;
- збіжність за Розенблатом — це не стабілізація ваг, а наявність всіх необхідних класифікацій, тобто по суті відсутність помилок.
Експоненційне зростання кількості прихованих елементів
Якщо вагові коефіцієнти до елементів прихованого шару (А-елементів) фіксовано, то необхідно, щоби кількість елементів прихованого шару (або їхня складність) експоненційно зростала зі зростанням розмірності задачі (кількості рецепторів). Відтак, втрачається їхня основна перевага — здатність розв'язувати задачі довільної складності за допомогою простих елементів.
- Розенблатом було показано, що кількість А-елементів залежить лише від кількості стимулів, які треба розпізнати (див. попередній пункт або теорему збіжності перцептрону). Таким чином, якщо кількість А-елементів є фіксованою, то можливість перцептрону до розв'язання задач довільної складності безпосередньо не залежить від зростання кількості рецепторів.
- Така помилка походить від наступної фрази Мінського:
При дослідженні предикату «парність» ми бачили, що коефіцієнти можуть зростати зі зростанням |R| (кількості точок на зображенні) експоненційно.[29]
- Крім того, Мінський досліджував і інші предикати, наприклад, «рівність». Але всі ці предикати є достатньо специфічними задачами на узагальнення, а не на розпізнавання або прогнозування. Так, наприклад, щоби перцептрон міг виконувати предикат «парність» — він повинен сказати, парна чи ні кількість чорних точок на чорно-білому зображенні, а для виконання предикату «рівність» — сказати, рівна чи ні права частина зображення лівій. Ясно, що такі задачі виходять за рамки задач розпізнавання та прогнозування, і являють собою задачі на узагальнення або просто на підрахунок певних характеристик. Це і було переконливо показано Мінським, і є обмеженням не лише перцептронів, але й усіх паралельних алгоритмів, які не здатні швидше за послідовні алгоритми обчислити такі предикати.
- Тому такі завдання обмежують можливості всіх нейронних мереж і перцептронів зокрема, але це ніяк не пов'язано з фіксованими зв'язками першого шару; тому що, по-перше, мова йшла про величину коефіцієнтів зв'язків другого шару, а по-друге, питання лише в ефективності, а не в принциповій можливості. Тобто, перцептрон можна навчити і цієї задачі, але обсяг пам'яті та швидкість навчання будуть більшими, ніж при застосуванні простого послідовного алгоритму. Введення ж у першому шарі вагових коефіцієнтів, що навчаються, лише погіршить стан справ, бо вимагатиме більшого часу навчання, оскільки перемінні зв'язки між S та A швидше перешкоджають, ніж сприяють процесові навчання.[30] Причому, при підготовці перцептрону до задачі розпізнавання стимулів особливого типу, для збереження ефективності знадобляться особливі умови стохастичного навчання,[31] що було показано Розенблатом в експериментах із перцептроном зі змінними S-A зв'язками.
Можливості та обмеження моделі
Детальніші відомості з цієї теми ви можете знайти в статті Можливості та обмеження перцептронів.
Можливості моделі
Сам Розенблат розглядав перцептрон перш за все як наступний важливий крок у дослідженні та використанні нейронних мереж, а не як завершений варіант «машини, здатної мислити».[nb 8] Ще в передмові до своєї книги він, відповідаючи на критику, відзначав, що «програма з дослідження перцептрона пов'язана головним чином не з винаходом пристроїв, що володіють „штучним інтелектом“, а з вивченням фізичних структур і нейродинамічних принципів».[32]
Розенблат запропонував ряд психологічних тестів для визначення можливостей нейромереж: експерименти з розрізнення, узагальнення, розпізнавання послідовностей, утворення абстрактних понять, формування та властивостей «самосвідомості», творчості, уяви та інші.[33] Деякі з цих експериментів далекі від сучасних можливостей перцептронів, тому їхній розвиток відбувається більше філософськи, в межах напряму конекціонізму. Тим не менше, для перцептронів встановлено два важливих факти, що знаходять застосування у практичних задачах: можливість класифікації (об'єктів) і можливість апроксимації (класів і функцій).[34]
Важливою властивістю перцептроів є їхня здатність до навчання, причому за рахунок досить простого й ефективного алгоритму (див. вище). Останнім часом дослідники починають звертати увагу саме на оригінальну версію перцептрона, оскільки навчання багатошарового перцептрона за допомогою методу зворотного поширення помилки виявило істотні обмеження на швидкість навчання. Спроби навчати багатошаровий перцептрон методом зворотного поширення помилок призводять до експоненційного зростання обчислювальних витрат. Якщо ж користуватися методом прямого поширення,[35] то обчислювальна складність алгоритму навчання стає лінійною. Це дозволяє зняти проблему навчання нейронних мереж із дуже великою кількістю входів та виходів, а також мати довільну кількість шарів мережі перцептронів. Поняття про зняття прокляття розмірності можна прочитати у праці Іванова А. І «Підсвідомість штучного інтелекту: програмування автоматів нейромережевої біометрії мовою їх навчання».[36]
Обмеження моделі
Детальніші відомості з цієї теми ви можете знайти в статті Перцептрони (книга).
Сам Розенблат виділив два фундаментальні обмеження для тришарових перцептронів (що складаються з одного S-шару, одного A-шару та R-шару): відсутність у них здатності до узагальнення своїх характеристик на нові стимули або нові ситуації, а також нездатність аналізувати складні ситуації у зовнішньому середовищі шляхом розчленування їх на простіші.[18]
В 1969 році Марвін Мінський та Сеймур Пейперт опублікували книгу «Перцептрони»,[37] де математично показали, що перцептрони, подібні до розенблатівських, принципово не в змозі виконувати багато з тих функцій, які хотіли б отримати від перцептронів. До того ж, у той час теорія паралельних обчислень була слабко розвиненою, а перцептрон повністю відповідав принципам таких обчислень. За великим рахунком, Мінський показав перевагу послідовних обчислень перед паралельними в певних класах задач, пов'язаних з інваріантні представленням. Його критику можна розділити на три теми:
- Перцептрони мають обмеження в задачах, пов'язаних з інваріантним представленням образів, тобто незалежним від їхнього положення на сенсорному полі та положення щодо інших фігур. Такі задачі виникають, наприклад, якщо нам потрібно побудувати машину для читання друкованих літер або цифр так, щоб ця машина могла розпізнавати їх незалежно від положення на сторінці (тобто щоб на рішення машини не впливали перенесення, обертання, розтяг-стиск символів);[7] або якщо нам потрібно визначити зі скількох частин складається фігура;[38] або чи знаходяться дві фігури поруч чи ні.[39] Мінським було доведено, що цей тип задач неможливо повноцінно розв'язати за допомогою паралельних обчислень, у тому числі — перцептрону.
- Перцептрони не мають функціонального переваги над аналітичними методами (наприклад, статистичними) в задачах, пов'язаних із прогнозуванням.[40] Тим не менше, в деяких випадках вони представляють простіший і продуктивніший метод аналізу даних.
- Було показано, що деякі задачі в принципі може бути розв'язано перцептроном, але вони можуть вимагати нереально великого часу[41] або нереально великої оперативної пам'яті.[42]
Книга Мінського і Паперті істотно вплинула на розвиток науки про штучний інтелект, тому що змістила науковий інтерес та субсидії урядових організацій США на інший напрямок досліджень — символьний підхід у ШІ.
Застосування перцептронів
Перцептрон може бути використано, наприклад, для апроксимації функцій, для задачі прогнозування (й еквівалентної їй задачі розпізнавання образів), що вимагає високої точності, та задачі керування агентами, що вимагає високої швидкості навчання.
У практичних задачах від перцептрона вимагатиметься можливість вибору більш ніж з двох варіантів, а отже, на виході в нього має бути більше одного R-елемента. Як показано Розенблатом, характеристики таких систем не відрізняються суттєво від характеристик елементарного перцептрона.[43]
Апроксимація функцій
Теорема Цибенка, доведена Джорджем Цибенком 1989 року, стверджує, що штучна нейронна мережа прямого поширення з одним прихованим шаром може апроксимувати будь-яку неперервну функцію багатьох змінних з будь-якою точністю. Умовами є достатня кількість нейронів прихованого шару, вдалий підбір і , де


- — ваги між вхідними нейронами і нейронами прихованого шару
- — ваги між зв'язками від нейронів прихованого шару і вихідним нейроном
- — коефіцієнт «упередженості» для нейронів прихованого шару.


Прогнозування та розпізнавання образів
У цих завданнях перцептронові потрібно встановити приналежність об'єкта до якогось класу за його параметрами (наприклад, за зовнішнім виглядом, формою, силуету). Причому точність розпізнавання багато в чому залежатиме від представлення вихідних реакцій перцептрону. Тут можливі три типи кодування: конфігураційне, позиційне та гібридне. Позиційне кодування, за якого кожному класові відповідає свій R-елемент, дає точніші результати, ніж інші види. Такий тип використано, наприклад, у праці Е. Куссуль та ін. «Перцептрони Розенблата для розпізнавання рукописних цифр». Однак воно є незастосовним у тих випадках, коли кількість класів є значною, наприклад, кілька сотень. У таких випадках можна застосовувати гібридне конфігураційно-позиційне кодування, як це було зроблено у праці Яковлева «Система розпізнавання рухомих об'єктів на базі штучних нейронних мереж».
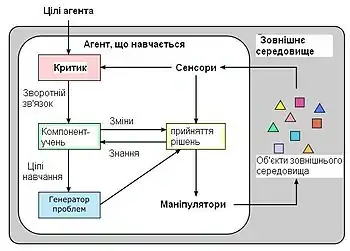
Керування агентами
У теорії штучного інтелекту часто розглядають агентів, що навчаються (адаптуються до довкілля). При цьому в умовах невизначеності стає важливим аналізувати не лише поточну інформацію, а й загальний контекст ситуації, в яку потрапив агент, тому тут застосовують перцептрони зі зворотним зв'язком.[44] Крім того, в деяких задачах стає важливим підвищення швидкості навчання перцептрона, наприклад, за допомогою моделювання рефрактерності.[45]
Після періоду, відомого як «Зима штучного інтелекту», інтерес до кібернетичним моделей відродився в 1980-х роках, оскільки прихильники символьного підходу в ШІ так і не змогли підібратися до вирішення питань про «Розуміння» і «Значення», через що машинний переклад і технічне розпізнавання образів досі володіють неусувними недоліками. Сам Мінський публічно висловив жаль, що його виступ завдав шкоди концепції перцептронів, хоча книга лише показувала недоліки окремо взятого пристрою та деяких його варіацій. Але в основному ШІ став синонімом символьного підходу, що виражався у складанні все складніших програм для комп'ютерів, що моделюють складну діяльність мозку людини.
Багатокласовий перцептрон
Як і більшість інших методик для тренування лінійних класифікаторів, перцептрон природно узагальнюється до багатокласової класифікації. Тут вхід та вихід витягуються з довільних множин. Функція представлення ознак відображує кожну можливу пару входів/виходів на скінченновимірний дійснозначний вектор ознак. Як і раніше, вектор ознак множиться на ваговий вектор , але тепер отримуваний бал використовується для вибору серед багатьох можливих виходів:





Навчання, знов-таки, проходить зразками, передбачуючи вихід для кожного, залишаючи ваги незмінними коли передбачений вихід відповідає цільовому, і змінюючи їх, коли ні. Уточненням стає:

Це формулювання багатокласового зворотного зв'язку зводиться до оригінального перцептрону, коли є дійснозначним вектором, обирається з , а .


Для деяких задач можливо обирати представлення входів/виходів та ознаки таким чином, що буде можливо знаходити ефективно, навіть якщо вибирається з дуже великої, або навіть нескінченної множини.

Останніми роками перцептронове тренування стало популярним в галузі обробки природної мови для таких задач як розмічування частин мови та синтаксичний аналіз.[46]
Примітки
- «Марк-1», зокрема, був системою, що імітує людське око та його взаємодію з мозком.
- «Тришарові» за класифікацією, прийнятою у Розенблата, і «двошарові» за сучасною системою позначень — з тією особливістю, що перший шар не навчається.
- В межах символьного підходу працюють над створенням експертних систем, організацією баз знань, аналізом текстів.
- Формально A-елементи, як і R-елементи, являють собою суматори з порогом, тобто поодинокі нейрони.
- Викладення в цьому розділі спрощено з причини складності аналізу на основі предикатів.
- Предикат є еквівалентним входові лише в окремому випадку — лише коли він залежить від одного аргументу.
- М. М. Бонгард вважає цю задачу найскладнішою для проведення гіперплощини у просторі рецепторів.
- На перших етапах розвитку науки про штучний інтелект її задача розглядалася в абстрактному сенсі — створення систем, що нагадують за розумом людину (див. Штучний загальний інтелект). Сучасні формулювання задач в ШІ є, як правило, точнішими.
Джерела
- Rosenblatt, Frank (1958), The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, v65, No. 6, pp. 386—408. (англ.)
- Warren S. McCulloch and Walter Pitts, A logical calculus of the ideas immanent in nervous activity[недоступне посилання з листопадаа 2019] (англ.)
- Donald Olding Hebb The Organization of Behavior: A Neuropsychological Theory (англ.)
- Perceptrons.Estebon.html Perceptrons: An Associative Learning Network[недоступне посилання з липня 2019] (англ.)
- Поява перцептрону[недоступне посилання з квітня 2019] (рос.)
- Системи розпізнавання образів Архівовано 26 січня 2010 у Wayback Machine. (рос.)
- Минский М., Пейперт С., с. 50.
- The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain Архівовано 18 лютого 2008 у Wayback Machine. (англ.)
- Розенблатт Ф., с. 102.
- Фомин, С. В., Беркинблит, М. Б. Математические проблемы в биологии (рос.)
- Розенблатт, Ф., с. 158—162.
- Розенблатт, Ф., с. 162—163.
- Брюхомицкий Ю. А. Нейросетевые модели для систем информационной безопасности, 2005. (рос.)
- Розенблатт Ф., с. 81.
- Розенблатт, Ф., с. 200.
- Розенблатт Ф., с. 82.
- Розенблатт Ф., с. 83.
- Розенблатт Ф., с. 93.
- Розенблатт, Ф., с. 230.
- Минский, Пейперт, с. 11—18.
- Розенблатт, Ф., с. 85—88.
- Розенблатт, Ф., с. 86.
- Хайкин С., 2006, с. 225—243, 304—316.
- Уоссермен, Ф.Нейрокомпьютерная техника: Теория и практика, 1992. (рос.)
- Melnychuk S., Yakovyn S., Kuz M. Emulation of logical functions NOT, AND, OR, and XOR with a perceptron implemented using an information entropy function // 2018 14th International Conference on Advanced Trends in Radioelecrtronics, Telecommunications and Computer Engineering (TCSET). - 2018. - P.878-882 (англ.)
- Бонгард М. М. Проблема узнавания М.: Физматгиз, 1967. (рос.)
- Минский М., Пейперт С., с. 59.
- Розенблатт, Ф., с. 101.
- Минский, Пейперт, с. 155, 189 (не дослівно, спрощено для виразності).
- Розенблатт, стр. 239
- Розенблатт, стр. 242
- Розенблатт, Ф., с. 18.
- Розенблатт, Ф., с. 70—77.
- Лекція 3: Навчання з учителем: Розпізнавання образів (рос.)
- ГОСТ Р 52633.5-2011 «Защита информации. Техника защиты информации. Автоматическое обучение нейросетевых преобразователей биометрия-код доступа» (рос.)
- Иванов А. И. «Подсознание искусственного интеллекта: программирование автоматов нейросетевой биометрии языком их обучения» Архівовано 4 серпня 2016 у Wayback Machine. (рос.)
- Minsky M L and Papert S A 1969 Perceptrons (Cambridge, MA: MIT Press) (англ.)
- Минский М., Пейперт С., с. 76—98.
- Минский М., Пейперт С., с. 113—116.
- Минский М., Пейперт С., с. 192—214.
- Минский, Пейперт, с. 163—187
- Минский, Пейперт, с. 153—162
- Розенблатт, Ф., с. 219—224.
- Яковлев С. С. Использование принципа рекуррентности Джордана в перцептроне Розенблатта, Журнал «АВТОМАТИКА И ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА», Рига, 2009. Virtual Laboratory Wiki. (рос.)
- Яковлев С. С., Investigation of Refractoriness principle in Recurrent Neural Networks, Scientific proceedings of Riga Technical University, Issue 5, Vol.36, RTU, Riga, 2008, P. 41-48. Читати (рос.)
- Collins, M. 2002. Discriminative training methods for hidden Markov models: Theory and experiments with the perceptron algorithm in Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP '02). (англ.)
Література
- Бонгард М. М.. Проблема узнавания. — М. : Наука, 1967. — 320 с. (рос.)
- Брюхомицкий, Ю. А. Нейросетевые модели для систем информационной безопасности: Учебное пособие. — Таганрог : Изд-во ТРТУ, 2005. — 160 с. (рос.)
- Мак-Каллок, У. С., Питтс, В.. Логическое исчисление идей, относящихся к нервной активности // Автоматы : сб.. — М., 1956. — С. 363—384. (рос.)
- Минский, М., Пейперт, С. Персептроны = Perceptrons. — М. : Мир, 1971. — 261 с. (рос.)
- Розенблатт, Ф. Принципы нейродинамики: Перцептроны и теория механизмов мозга = Principles of Neurodynamic: Perceptrons and the Theory of Brain Mechanisms. — М. : Мир, 1965. — 480 с. (рос.)
- Уоссермен, Ф. Нейрокомпьютерная техника: Теория и практика = Neural Computing. Theory and Practice. — М. : Мир, 1992. — 240 с. — ISBN 5-03-002115-9. (рос.)
- Хайкин, С. Нейронные сети: Полный курс = Neural Networks: A Comprehensive Foundation. — 2-е изд. — М. : «Вильямс», 2006. — 1104 с. — ISBN 0-13-273350-1. (рос.)
- Яковлев С. С. Система распознавания движущихся объектов на базе искусственных нейронных сетей // ИТК НАНБ. — Минск, 2004. — С. 230—234. (рос.)
- Kussul E., Baidyk T., Kasatkina L., Lukovich V. Перцептроны Розенблатта для распознавания рукописных цифр // IEEE. — 2001. — С. 1516—1520. (англ.)
- Stormo G. D., Schneider T. D., Gold L., Ehrenfeucht A. Использование перцептрона для выделения сайтов инициации в E. coli // Nucleic Acids Research. — 1982. — С. P. 2997–3011. (англ.)
Посилання
- Перцептрон. Virtual Laboratory Wiki. Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (рос.)
- Появление перцептрона. Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (рос.)
- Ежов А. А., Шумский С. А. (2006). Нейрокомпьютинг и его применения в экономике и бизнесе. ИНТУИТ. Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (рос.)
- Редько В. Г. (1999). Искусственные нейронные сети. Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (рос.)
- Яковлев С. С. (2006). Линейность и инвариантность в искусственных нейронных сетях (pdf). Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (рос.)
- Estebon, M. D.; Tech, V. (1997). Perceptrons: An Associative Learning Network (англ.). Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (англ.)
- Беркинблит М. Б. (1993). Нейронные сети. Глава "Перцептроны и другие обучающиеся классификационные системы". Архів оригіналу за 19 серпня 2011. Процитовано 17 січня 2009. (рос.)
- SergeiAlderman-ANN.rtf
- Flood: An Open Source Neural Networks C++ Library
- Chapter 3 Weighted networks - the perceptron and Chapter 4 Perceptron learning of Neural Networks - A Systematic Introduction by Raúl Rojas (ISBN 978-3-540-60505-8) (англ.)
- Pithy explanation of the update rule[недоступне посилання з липня 2019] by Charles Elkan (англ.)
- C# implementation of a perceptron
- History of perceptrons (англ.)
- Mathematics of perceptrons (англ.)
- Perceptron demo applet and an introduction by examples (англ.)