Онтологія гена
«Онтологія гена» (англ. Gene Ontology, или GO) — біоінформатичний проєкт, присвячений створенню уніфікованої термінології для анотації генів і генних продуктів всіх біологічних видів[1].
Метою проєкту є підтримання і поповнення певного списку атрибутів генів та їх продуктів, створення онотацій генів і продуктів, розробка інструментів для роботи з базою даних проєкту, а також для аналізу нових експериментальних даних, зокрема, аналіз представленості функціональних груп генів. Варто відзначити, що в проєкті GO було створено мову розмітки для класифікації даних (інформації про гени та їх продукти, тобто РНК і білки, а також їхні функції), яка дозволяє швидко знаходити систематизовану інформації про продукти генів[2][3][4].
«Онтологія гена» є частиною більш масштабного проєкту з класифікації — Відкриті біомедичні онтології[5].
Історія і поточний стан
Онтологія в інформатиці використовується для формалізації певних галузей знань за допомогою системи даних про об'єкти реального світу та зв'язок між ними (т. з. база знань). В біології та суміжних дисциплінах виникла проблема відсутності універсального стандарту термінології. Терміни, які мають подібні поняття, але використовуються для різних біологічних видів, різних галузей досліджень або навіть всередині різних груп учених, можуть мати принципово різне значення, що ускладнює обмін даними. В зв'язку з цим, завданням проєкту «Генна онтологія» стало створення онтології термінів, відображаючих властивості генів та їх продуктів і застосованим до будь-якого організму[2][3][4].
«Онтологія гена» була створена в 1998 році консорціумом учених, які вивчали геноми трьох модельних організмів: Drosophila melanogaster (плодова мушка), Mus musculus (миша) і Saccharomyces cerevisiae (пекарні дріжджі)[6]. Згодом багато баз даних для інших модельних організмів приєдналися до Консорціуму GO, тим самим сприяючи не тільки розширенню бази анотацій, але й створенню сервісів для перегляду і застосування даних.
Консорціум GO (GOC) — це безліч біологічних баз даних і дослідницьких груп, які активно беруть участь в проєкті «Онтологія гена»[7]. До нього відносяться декілька баз даних для різних модельних організмів, загальні білкові бази даних, групи розробників програмного забезпечення і редактори «Онтології гена».
Станом на вересень 2011 року проєкт містив понад 33 тис. термінів і близько 12 млн анотацій генних продуктів, застосованих до більш ніж 360 тис. живих організмів[2]. По закінченню 2016 року кількість термінів перевищувало 44 тис екземплярів, в той час як кількість організмів, анотованих в даній базі, перевищило позначку в 460 тис особин[3]
Протягом декількох останніх років Консорціум GO впровадив ряд змін онтології для збільшення кількості, якості та специфічності анотацій GO. До 2013 року году кількість анотацій перевищила 96 млн. Якість анотацій було покращено за допомогою автоматизованої перевірки якості. Також покращилася анотація даних, наявних в базі GO; були додані нові терміни. [4]. В 2007 році був створений новий сервіс InterMine[8], метою якого є інтеграція геномних даних із великої кількості розрізнених джерел і полегшення обчислювальних задач, таких як пошук конкретних геномних областей і здійснення статистичних тестів. В останні роки ведеться розробка сервісу LEGO (Linked Expressions using the Gene Ontology), який дозволить досліджувати взаємодію різних анотацій в базі GO, об'єднуючи їх в більш загальні моделі генів та їх функцій[3].
Структура і терміни
Потрібно розуміти , що «Онтологія гена» описує комплексні біологічні феномени, а не конкретні біологічні об'єкти. Її база даних включає три незалежних словника[1][9]:
- Молекулярні функції (англ. molecular function) — класифікація за специфічною функцією продуктів гена (білка або РНК) на молекулярному рівні, наприклад, зв'язування вуглеводів чи АТФазна активність.
- Біологічені процеси (англ. biological process) — класифікація за комплексними процесами, зазвичай необхідних для життєдіяльності організмів і які відбуваються завдяки здійсненню послідовності молекулярних реакцій, наприклад, мітоз чи біосинтез пуринів.
- Клітинні компоненти (англ. cellular component) — класифікація за частинами клітини чи позаклітинного простору, де відбувається фунціонування продуктів гену, наприклад, ядро або рибосома.
Кожний термін в «Онтології гена» має ряд атрибутів: унікальний цифровий ідентифікатор, назву, словник, до якого термін належить, і визначення. Терміни можуть мати синоніми, які поділяються на точно відповідні значенню терміна, більш широкі, більш вузькі і ті, які мають деяке відношення до терміна. Також можуть міститися такі атрибути, як посилання на джерела, на інші бази даних і коментарі із значення та використання терміна[1][9].
Онтологія побудована за принципом спрямованого ациклічного графу: кожний термін зв'язаний з одним або декількома іншими термінами через різного типу відношення. Виділяють наступні типи відношень[1]:
- «A is a B» — A є приватним випадком B,
- «A part of B» — A є частиною B,
- «B has part A» — B включає A,
- «A regulates B» — А регулює В,
- «A positively regulates B» — А позитивно регулює В,
- «A negatively regulates B» — А негативно регулює В,
- «A occurs in B» — А зустрічається при В.
Приклад одного із термінів проєкту GO[10]:
id: GO:0043417 name: negative regulation of skeletal muscle tissue regeneration namespace: biological_process def: "Any process that stops, prevents, or reduces the frequency, rate or extent of skeletal muscle regeneration." [GOC:jl] synonym: "down regulation of skeletal muscle regeneration" EXACT [] synonym: "down-regulation of skeletal muscle regeneration" EXACT [] synonym: "downregulation of skeletal muscle regeneration" EXACT [] synonym: "inhibition of skeletal muscle regeneration" NARROW [] is_a: GO:0043416 ! regulation of skeletal muscle tissue regeneration is_a: GO:0048640 ! negative regulation of developmental growth relationship: negatively_regulates GO:0043403 ! skeletal muscle tissue regeneration
В базу даних «Онтологія гена» постійно вносяться зміни і доповнення як кураторами проєкту GO, так і іншими дослідниками. Запропоновані правки користувачів проходять провірку редакторами проєкту і застосовуються лише у випадку схвалення цих змін[9].
Файл, який містить всю базу даних[10], можна отримати в різних форматах на офіційному сайті «Онтології гена»; терміни також доступні онлайн за допомогою браузера «Генної онтології» AmiGO. Крім того, з його допомогою можливо отримати масив даних генних продуктів, які відносяться до того або іншого терміна. Також на сайті можна скачати карти відповідності термінів GO іншим системам класифікації[11].
Анотації
Анотування геномів націлено на отримання інформації про властивості гених продуктів. В анотаціях GO для цього використовуються терміни «Генної онтології». Члени Консорціуму GO викладають свої анотації на сайті «Геної онтології», де анотації доступні для прямого завантаження, або для перегляду в браузері AmiGO[12].
В анотації гена містяться наступні дані: назва та ідентифікатор генного продукту; відповідний термін GO; тип даних, на яких заснована анотація (англ. evidence code); посилання на джерело; а також автор і дата створення анотації. Для типу даних, вказуючих на достовірність анотації (evidence code), існує особлива онтологія, яка відноситься до проєкту ОВО[13]. Вона включає різні методи анотування: як виконані власноруч, так і автоматичні. Наприклад[1]:
- IDA (Inferred from Direct Assay) — експериментальні дані.
- TAS (Traceable Author Statement) — дані з наукової публікації.
- IMP (Inferred from Mutant Phenotype) — дані отримані на основі мутантного фенотипу.
- IGI (Inferred from Genetic Interaction) — на основі взаємодії генів.
- IPI (Inferred from Physical Interaction) — на основі фізичної взаємодії.
- RCA (Inferred from Reviewed Computational Analysis) — на основі достовірного вираховуючого аналізу.
- ISS (Inferred from Sequence Similarity) — на основі подібності послідовностей.
- IGC (Inferred from Genomic Context) — на основі геномного контексту.
- IEP (Inferred from Expression Pattern) — на основі характеру експресії.
- NAS (Non-traceable Author Statement) — на основі неопублікованих даних.
- IEA (Inferred from Electronic Annotation) — на основі автоматичного вилучення з інших баз анотацій.
- IC (Inferred by Curator) — дані приписані куратором.
- ND (No biological Data available) — достовірні дані відсутні.
Станом на вересень 2012 року більше 99 % всіх анотацій «Генної онтології» були отримані автоматичним шляхом[4]. Поскільки такі анотації не перевіряються вручну, то Консорціум GO розглядає їх як менш достовірні, і лише частина із них доступна в браузері AmiGO. Повну базу анотацій можна завантажити на сайті «Генної онтології».
AmiGO
AmiGO[9] — це веб-додаток (сервіс GO), який дозволяє користувачам робити запит, находити і візуалізувать терміни GO та анотації генних продуктів. Крім того, додаток містить інструмент BLAST (наявний в AmiGO 1, був видалений в AmiGO 2), сервіси, що дозволяють аналізувать великі масиви даних та інтерфейс для пошуку безпосередньо в базі даних GO[14]. AmiGO можна використовувати онлайн на сайті «Генної онтології» для доступу до даних, наданих Консорціумом GO, або можна загрузити і установити для локального використання до будь-якої бази даних, побудованої за принципом GO. AmiGO 2 є відкритим і вільним ПЗ.
Візуалізація
Візуалізація надає можливість користувачу будувати граф, характеризуючий генну онтологію для конкретного GO терміна. Існує два формати введення даних [15]:
- Стандартний формат — список id GO термінів (наприклад, GO:1234567), розділених пробілом.
- Розширений формат — опис вузлів в графі в форматі JSON (JavaScript Object Notation). Незалежно від приписаного формату може змінюватися зміст вузла (додавання додаткових анотацій, зміна кольорів, тощо)
Приклад JSON введення:
{"GO:0002244":{"title": "foo",
"body": "bar",
"fill": "#ccccff",
"font": "#0000ff",
"border":"red"},
"GO:0005575":{"title":"alone",
"body":""},
"GO:0033060":{}}
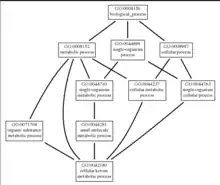
Кодування співвідношень за допомогою кольору:
| Відношення | Колір |
|---|---|
| is_a | blue |
| part_of | lightblue |
| develops_from | brown |
| regulates | black |
| negatively_regulates | red |
| positively_regulates | green |
Візуалізація терміна полягає в побудові графа з верху, від вихідного GO терміна, до корінної вершини, яка представлена назвою одного із трьох головних словників: біологічні процеси, молекулярні функції і клітинні компоненти[1][9].
Огляд даних
Крім можливості створення графів, які відображають генну онтологію GO терміна, в AmiGO також реалізовано декілька інструментів, які дають користувачам уявлення про дані проєкту GO. Серед них[14]:
- Базова статистика — інформація про дані GO у вигляді різних гістограм (наприклад, розподіл анотацій та їх характеру (експериментальні/не експериментальні) відносно різних видів живих організмів). Реалізовано за допомогою сервіса Plotly.
- Розгорнутий браузер (drill-down browser) — дозволяє досліджувати онтології та анотації, просуваючись ієрархією, починаючи від високого рівня. В даному інструменті можна використовувати різні фільтри.
- Пошукові шаблони — інтерфейс, який складається з боксів для введення даних і виконання для них типових запитів до бази GO.
GOOSE
GOOSE[16]— середовище запитів SQL, реалізоване в онлайн режимі і доступне користувачам сервісу AmiGO, для створення наборів даних. Даний сервіс використовує синтаксис SQL для складання різних запитів в базу GO. Також для зниження навантаження на систему доступні дзеркала EBI (Велика Британія, Кембридж), Berkeley BOP та Berkeley BOP (lite) (обидва знаходяться в городі Берклі, штат Каліфорнія).
Крім безпосереднього написання запитів власноруч можливе використання шаблонів для часткового полегшення цєї задачі. Типовий запит в базу даних показаний нижче (пошук максимальної глибини дерева для кліткової компоненти)[16]:
SELECT distance as max from graph_path, term WHERE graph_path.term2_id =term.id and term.term_type = 'cellular_component' ORDER BY distance desc limit 1;
База даних в GO має складну структуру і складається із багатьох таблиць. Основні бази даних[16] :
- termdb — база даних з інформацією про GO терміни та відношення між ними.
- assocdb — база даних з GO лексикою та анотаціями між GO термінами і генними продуктами. Дана БД знаходиться в залежності віт termdb.
- seqdb — база даних, яка містить GO терміни, генні продукти і послідовності, які анотовані з цими генними продуктами. Знаходиться в залежності від termdb і assocdb. Крім того, реалізована БД seqbdlite, в якій відсутні IEA анотації.
Можливі наступні формати експорту даних в результаті запиту[16]:
- .rdf — xml
- .obo — xml
- .owl — OWL
- .tables
- .sql
PANTHER
PANTHER (англ. Protein Analysis THrough Evolutionary Relationships) — це велика база даних генів/білкових родин і функціонально подібних на них підродин, які можуть бути використані для класифікації функціонального спектру генних продуктів[17]. PANTHER — це частина проєкту GO, головною ціллю якої є класифікація білків та їх генів.
В PANTHER база даних редагується не тільки персоналом проєкту, але також і за рахунок класифікаційних алгоритмів. Протеїни класифікуються в відповідності з їх приналежності до родин (підродин), молекулярної функції або біологічного процесу[17].
Головне використання PANTHER полягає у з'ясуванні функцій непояснених генів будь-якого організму, заснованому на їх еволюційних взаємовідносинах з генами, про функції яких є інформація в БД. Використовуючи генні функції, онтологію і статистико-аналітичні методи, PANTHER дозволяє біологам аналізувати великі дані, цілі геноми, отримані за допомогою секвенірування або дослідження експресії генів[18].
Основні інструменти, доступні на вебсайті PANTHER[18]:
- Аналіз списку генів:
- Функціональний аналіз генів і їх класифікація — включає інформацію про родини і підродини генів, їх молекулярну функцію, біологічні процеси, в які вони залучені, про клітинні компоненти, де їх можна знайти. Ці дані можуть бути представлені як у вигляді списку, так і у вигляді кругової діаграми.
- Статистичні тести (Overrepresentation test і enrichment test) призначені для знаходження загальних біологічних функцій генів, поданих на вхід користувачем.
- Дослідження онтології даних, анотацій між термінами і родинами, підродинами PANTHER.
- Пошук білкових послідовностей в бібліотеках PANTHER
- Аналіз однонуклеотидних поліморфізмів (cSNP) — оцінка ймовірності несинонімічної однонуклеотидної мутації до зміни функціональної діяльності гена.
GO Slimmer
GO Slimmer[19] — інструмент, який дозволяє співставляють детальні анотації набору генів з одним або декількома батьківськими термінами більш високого рівня (GO slim термінами). GO slim термін — це урізана версія GO онтології, яка містить підмножину термінів всього GO без детального опису специфічних низькорівневих термінів.
Використання GO Slimmer дозволяє представляти анотації GO генома, аналізувати результати мікромасивів експресій або колекцій комплементарних ДНК, коли необхідна найповніша класифікація функцій генних продуктів[19].
Результат роботи цього алгоритму представлений трьома колонками[19]:
- GO Slim термін
- Кількість знайдених генних продуктів в запиті, відповідних заданому slim терміну.
- Розташування терміну в трьох основних частинах GO онтології: біологічний процес (P), клітинний компонент (C) і молекулярна функція (F).
AmiGO версія даного інструменту написана на Perl скрипті map2slim[19]. Куратори проєкту відмічають, що в даний час GO slimmer сервіс загружений, і вхідні дані значних розмірів можуть негативно позначитися на його роботі. Час роботи сервісу для обробки вхідних послідовностей обмежено.
BLAST
BLAST (англ. Basic Local Alignment Search Tool) — родина комп'ютерних програм, які служать для пошуку гомологів білків або нуклеїнових кислот, для яких відома послідовність, за допомогою вирівнювання. Використовуючи BLAST, дослідник може порівняти свою послідовність яка у нього є з послідовностями із бази даних і знайти найбільш подібні з даною, які будуть допустимими гомологами.
Реалізація даного інструмента в AmiGO 1 представлена у вигляді пакета WU-BLAST, розробленого Вашингтонським університетом в Сент-Луїсі (Washington University in St. Louis).[20]
В AmiGO 2 даний інструмент (GO BLAST) був видалений, однак можна скористатися пошуком в AmiGO 1. Інструмент дозволяє фільтрувати результати пошуку за генним продуктом, базою даних, таксономічною приналежністю, словником GO, OBO анотаціями.
Term Matrix
Term Matrix [21](матриця термінів) — інструмент AmiGO для вивчення інформації про подібність генної продукції термінів. Результатом його роботи є матриця, елементами якої є кількість генних продуктів, анотованих для конкретної пари GO термінів. Для використання функції [21]необхідно ввести список ідентифікаторів GO, щоб побачити спільні анотації - кількість загальних генних продуктів, анотованих за парами термінів. Є можливіть задавати конкретні види або таксони. Підсвічування теплової карти може бути здійснена у вигляді градації від чорного до білого, або використовуючи стандартну палітру карти.
OBO-Edit
OBO-Edit[22] — це редактор онтологій у відкритому доступі, розроблений і підтриманий Консорціумом GO. Він реалізований на мові Java і використовує підхід, оснований на роботі з графами, для візуалізації і редагування онтологій. OBO-Edit має зручний інтерфейс пошуку і фільтрації, що дозволяє візуалізувати і розділяти підмножини термінів GO. Інтерфейс можна налаштовувати у відповідності до потреб користувача. Також OBO-Edit дозволяє автоматично створювати нові зв'язки на основі існуючих відношень та їх властивостей. Не дивлячись на те, що OBO-Edit був розроблений для біомедичних онтологій, його можна використовувати для перегляду і редагування будь-якої онтології.
PAINT
PAINT[23] (англ. Phylogenetic Annotation and INference Tool) — Java-додаток, який є частиною проєкту анотації геномів (Reference Genome Annotation Project), що базується на принципі «транзитивної анотації». Поняття транзитивної анотації полягає в присвоєнні експериментально установленої функції одного гена другому, у вигляді подібності їх нуклеотидних послідовностей.
За допомогою PAINT користувач може досліджувати експериментальні анотації для генів із окремої родини і використовувати дану інформацію для складання нових анотацій для членів родини генів, які ще не були достатньо вивчені[3]. Інструменти PAINT дозволяють будувати модель, яка пояснювала би наслідування або втрату тієї чи іншої функціональності гена в межах окремих гілок філогенетичних дерев. Нові анотації, отримані за допомогою даної моделі, позначаються як анотації на основі біологічного родича (IBA — Inferred from Biological Ancestry)[1].
Цей додаток безкоштовно доступний для завантаження на Github.
Примітки
- du Plessis L, Skunca N, Dessimoz C (November 2011). The what, where, how and why of gene ontology — a primer for bioinformaticians. Brief Bioinform. 12 (6): 723–35. PMC 3220872. PMID 21330331. doi:10.1093/bib/bbr002.
- The Gene Ontology Consortium (January 2012). The Gene Ontology: enhancements for 2011.. Nucleic Acids Res. 40 (Database issue): D559–64. PMC 3245151. PMID 22102568. doi:10.1093/nar/gkr1028.
- The Gene Ontology Consortium (January 2017). Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Res. 45 (D1): D331–D338. doi:10.1093/nar/gkw1108.
- The Gene Ontology Consortium (January 2013). Gene Ontology annotations and resources. Nucleic Acids Res. 41 (Database issue): D530–5. PMC 3531070. PMID 23161678. doi:10.1093/nar/gks1050.
- Smith B, Ashburner M, Rosse C, Bard J, Bug W, Ceusters W, Goldberg LJ, Eilbeck K, Ireland A, Mungall CJ, Leontis N, Rocca-Serra P, Ruttenberg A, Sansone SA, Scheuermann RH, Shah N, Whetzel PL, Lewis S (November 2007). The OBO Foundry: coordinated evolution of ontologies to support biomedical data integration. Nat. Biotechnol. 25 (11): 1251–5. PMC 2814061. PMID 17989687. doi:10.1038/nbt1346.
- Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K, Dwight SS, Eppig JT, Harris MA, Hill DP, Issel-Tarver L, Kasarskis A, Lewis S, Matese JC, Richardson JE, Ringwald M, Rubin GM, Sherlock G (May 2000). Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 25 (1): 25–9. PMC 3037419. PMID 10802651. doi:10.1038/75556.
- The GO Consortium.
- Richard N. Smith, Jelena Aleksic, Daniela Butano, Adrian Carr, Sergio Contrino. InterMine: a flexible data warehouse system for the integration and analysis of heterogeneous biological data // Bioinformatics. — 2012-12-01. — Vol. 28, no. 23. — С. 3163–3165. — ISSN 1367-4803. — DOI:10.1093/bioinformatics/bts577.
- Carbon S, Ireland A, Mungall CJ, Shu S, Marshall B, Lewis S; AmiGO Hub; Web Presence Working Group (January 2008). AmiGO: Online access to ontology and annotation data.. Bioinformatics 25 (2): 288–289. PMC 2639003. PMID 19033274. doi:10.1093/bioinformatics/btn615.
- The GO Consortium. База данных «Генной онтологии» в формате .obo (OBO 1.2 flat file).
- The GO Consortium. Mappings of External Classification Systems to GO. Архів оригіналу за 25 червня 2014. Процитовано 11 листопада 2018.
- The GO Consortium. Search annotations.
- The Open Biological and Biomedical Ontologies: Evidence Codes. Архів оригіналу за 26 листопада 2009.
- Руководство по работе с AmiGO.
- The GO Consortium. Manual Visualization.
- The GO Consortium. Manual GOOSE.
- Huaiyu Mi, Xiaosong Huang, Anushya Muruganujan, Haiming Tang, Caitlin Mills, Diane Kang, and Paul D. Thomas (28 листопада 2016). PANTHER version 11: expanded annotation data from Gene Ontology and Reactome pathways, and data analysis tool enhancements. Nucleic Acids Research 45 (Database): D183–D189. PMC PMC5210595. doi:10.1093/nar/gkw1138.
- The GO Consortium. Manual PANTHER.
- The GO Consortium. Manual GO Slimmer.
- The GO Consortium. Manual GO BLAST.
- Gene Ontology Consortium. AmiGO 2: Matrix (англ.). amigo2.berkeleybop.org. Процитовано 4 квітня 2018.
- Day-Richter J, Harris MA, Haendel M, Gene Ontology OBO-Edit Working Group, Lewis S (August 2007). OBO-Edit – an ontology editor for biologists.. Bioinformatics 23 (16): 2198–2200. PMID 17545183. doi:10.1093/bioinformatics/btm112.
- The GO Consortium. Manual PAINT.
Посилання
- The Gene Ontology — офіційний сайт проєкту.(англ.)
- AmiGO — браузер «Онтології гена».(англ.)
- PAINT — безкоштовний додаток на Github.(англ.)
- Term Matrix — інструмент AmiGO.(англ.)
- BLAST — інструмент AmiGO.(англ.)
- GO slimmer — інструмент AmiGO.(англ.)
- map2slim — скрипт GO slimmer.(англ.)
- GO data scheme — схема бази даних GO.(англ.)
- Plotly — сервіс інфорграфіки.(англ.)
- Visualization — інструмент AmiGO.(англ.)
- Annotation Database — повна база даних анотацій.(англ.)
{kind=link}