Ієрархічна часова пам'ять
Ієрархі́чна часова́ па́м'ять (ІЧП, англ. Hierarchical temporal memory, HTM) — це продиктована біологією технологія машинного інтелекту, розроблювана компанією Numenta. Первинно описану Джеффом Гокінсом з Сандрою Блейкслі в книзі 2004 року «Про інтелект», ІЧП натепер переважно використовують для виявляння аномалій у потокових даних. Ця технологія ґрунтується на нейронауці та фізіології та взаємодії пірамідних нейронів у новій корі ссавцевого (зокрема, людського) головного мозку.
В основі ІЧП лежать алгоритми навчання, які можуть зберігати високопорядкові послідовності, навчатися їх, робити висновки стосовно них, та згадувати їх. На відміну від більшості інших алгоритмів машинного навчання, ІЧП безперервно навчається (спонтанним чином) часових образів у немічених даних. ІЧП є стійкою до шуму, і має високу ємність (вона може навчатися декількох образів одночасно). При застосуванні до комп'ютерів ІЧП є добре пристосованою для передбачування,[1] виявляння аномалій,[2] класифікування, та, зрештою, сенсо́рно-моторних застосувань.[3]
ІЧП було перевірено та втілено у програмному забезпеченні через приклади застосунків від Numenta, і декілька комерційних застосунків від партнерів Numenta.
Структура та алгоритми
Типова мережа ІЧП є деревною ієрархією рівнів (англ. levels, які не слід плутати з «шарами», англ. layers, нової кори, які описано нижче). Ці рівні складаються з менших елементів, званих областями (англ. regions, або вузлами, англ. nodes). Один рівень в цій ієрархії може містити декілька областей. Вищі рівні ієрархії часто мають менше областей. Вищі рівні ієрархії можуть перевикористовувати образи, навчені на нижчих рівнях, поєднуючи їх для запам'ятовування складніших образів.
Усі області ІЧП мають однакову елементарну функцію. В режимах навчання та висновування сенсо́рні дані (наприклад, дані від очей) надходять до областей найнижчого рівня. У породжувальному режимі області найнижчого рівня виводять породжений образ заданої категорії. Найвищий рівень зазвичай має єдину область, яка зберігає найзагальніші та найсталіші категорії (поняття); вони визначають, або визначаються меншими поняттями на нижчих рівнях — поняттями, які є обмеженішими в часі та просторі[прояснити]. В режимі висновування область (на будь-якому рівні) інтерпретує інформацію, що надходить знизу з її «дочірніх» областей, як імовірності тих категорій, які вона має в пам'яті.
Кожна з областей ІЧП навчається, ідентифікуючи та запам'ятовуючи просторові образи — поєднання бітів входу, що часто трапляються в один і той же час. Потім вона визначає часові послідовності просторових образів, для яких є правдоподібним траплятися один після одного.
Як модель, що розвивається
ІЧП є алгоритмовою складовою Теорії інтелекту тисячі мізків (англ. Thousand Brains Theory of Intelligence) Джеффа Гокінса. Тож нові відкриття про нову кору поступально включають до моделі ІЧП, яка змінюється з часом у відповідь. Нові відкриття не обов'язково роблять нечинними попередні частини цієї моделі, тож ідеї з одного покоління не обов'язково виключають в наступнім. Через еволюційну природу цієї теорії існувало декілька поколінь алгоритмів ІЧП,[4] які стисло описано нижче.
Перше покоління: зета 1
Перше покоління алгоритмів ІЧП іноді називають зета 1 (англ. zeta 1).
Тренування
Під час тренування вузол (або область) отримує на вході часову послідовність просторових образів. Процес навчання складається з двох етапів:
- Просторове агрегування (англ. spatial pooling) ідентифікує (у вході) часто спостережувані образи, та запам'ятовує їх як «збіги» (англ. "coincidences"). Образи, які є значно подібними один до одного, трактуються як один і той же збіг. Велике число входових образів звужується до піддатливого числа відомих збігів.
- Часове агрегування (англ. temporal pooling) розбиває збіги, для яких є правдоподібним траплятися в тренувальній послідовності один за одним, на часові групи. Кожна з груп образів представляє «причину» (англ. "cause") входового образу (або «ім'я», англ. "name", в книзі «Про інтелект»).
Поняття просторового агрегування та часового агрегування залишаються вельми важливими і для поточних алгоритмів ІЧП. Часове агрегування є ще не дуже добре зрозумілим, і його зміст змінювався протягом часу (з розвитком алгоритмів ІЧП).
Висновування
Під час висно́вування (англ. inference) вузол обчислює набір імовірностей належності образу до кожного з відомих збігів. Потім він обчислює ймовірності подання входом кожної з часових груп. Набір імовірностей, призначених групам, називають «переконанням» (англ. "belief") вузла про входовий образ. (У спрощеному втіленні переконання вузла складається лише з однієї групи — переможниці). Це переконання є результатом висновування, який передається одному або більше «батьківському» вузлові в наступному рівні ієрархії.
Образи, які для вузла є «несподіваними», не мають домінантної ймовірності належності до жодної з часових груп, але мають майже рівні ймовірності належності до декількох із цих груп. Якщо послідовності образів є подібними до тренувальних послідовностей, то призначувані групам імовірності не змінюватимуться так часто, як отримуються образи. Вихід вузла змінюватиметься не сильно, і часова роздільна здатність[прояснити: ком.] втрачатиметься.
У загальнішій схемі переконання вузла може надсилатися до входів будь-якого вузла (вузлів) на будь-якому рівні (рівнях), але ці з'єднання між вузлами все одно залишаються незмінними. Вузол вищого рівня поєднує цей вихід з виходом з інших дочірніх вузлів, формуючи таким чином свій власний входовий образ.
Оскільки просторова та часова роздільна здатність втрачаються на кожному вузлі, як описано вище, то переконання, що формуються вузлами вищих рівнів, представляють ще більші проміжки простору й часу. Це покликано відображати будову фізичного світу, як її сприймає людський мозок. Більші поняття (наприклад, причини, дії чи об'єкти) сприймаються як такі, що змінюються повільніше, і складаються з менших понять, як змінюються частіше. Джефф Гокінс постулює, що мозок виробив цю ієрархію для співставляння, передбачування та впливу на будову зовнішнього світу.
Більше подробиць про функціювання ІЧП Зета 1 можливо знайти в старій документації Numenta.[5]
Друге покоління: кортикальні алгоритми навчання
Друге покоління алгоритмів навчання ІЧП, які часто називають кортика́льними алгори́тмами навча́ння (КАН, англ. cortical learning algorithms, CLA), разюче відрізнялося від зета 1. Для подання активності мозку воно покладається на структуру даних, звану розрідженими розподіленими поданнями (англ. sparse distributed representations, тобто, на структуру даних, чиї елементи є двійковими, 1 чи 0, і чиє число 1-чних бітів є малим у порівнянні з числом 0-вих бітів), і на реалістичнішу з погляду біології модель нейрону (який в контексті ІЧП часто називають клітиною, англ. cell).[6] У цьому поколінні ІЧП є дві центральні складові: алгоритм просторового агрегування (англ. spatial pooling),[7] який видає розріджені розподілені подання (РРП, англ. sparse distributed representations, SDR), та алгоритм пам'яті послідовностей (англ. sequence memory),[8] який вчиться представляти та передбачувати складні послідовності.
В цьому новому поколінні розглянуто та частково змодельовано шари (англ. layers) та мініколонки (англ. minicolumns) кори головного мозку. Кожен шар ІЧП (не плутати з рівнем ІЧП ієрархії ІЧП, який описано вище) складається з ряду сильно пов'язаних між собою мініколонок. Шар ІЧП створює розріджене розподілене подання свого входу, так що в будь-який момент часу активним є лише фіксований відсоток мініколонок.[прояснити: ком.] Мініколонку розуміють як групу клітин, які мають одне й те ж рецептивне поле. Кожна з мініколонок має ряд клітин, здатних пам'ятати декілька попередніх станів. Клітина може бути в одному з трьох станів: активному (англ. active), неактивному (англ. inactive) та передбачувальному (англ. predictive).
Просторове агрегування
Рецептивне поле кожної з мініколонок є фіксованим числом входів, які випадково обираються з набагато більшого числа входів вузла. Залежно від (конкретних) образів на вході, деякі колонки будуть більш або менш пов'язаними з активними входовими значеннями. Просторове агрегування (англ. spatial pooling) обирає відносно стале число найактивніших мініколонок та деактивує (пригнічує) інші мініколонки по сусідству з активними. Подібні входові образи схильні активувати стійкий набір мініколонок. Кількість пам'яті, що використовується кожним шаром, може бути збільшувано з метою навчання складніших просторових образів, або зменшувано з метою навчання простіших образів.
Активні, неактивні та передбачувальні клітини
Як зазначено вище, клітина (або нейрон) мініколонки в будь-який момент часу може бути в активному, неактивному, або передбачувальному стані. Початково клітини є неактивними.
Як клітини стають активними?
Якщо одна або більше клітин в активній мініколонці перебувають у передбачувальному стані (див. нижче), вони будуть єдиними клітинами, які зможуть стати активними в поточний момент часу. Якщо жодна з клітин в активній мініколонці не перебуває в передбачувальному стані (що відбувається в початковий момент часу, або коли активування мініколонки було неочікуваним), активними стають усі клітини.
Як клітини стають передбачувальними?
Коли клітина стає активною, вона поступово утворює з'єднання з сусідніми клітинами, що є схильними бути активними протягом декількох попередніх кроків часу. Таким чином клітина вчиться розпізнавати відому послідовність, перевіряючи, чи є активними з'єднані клітини. Якщо велике число з'єднаних клітин є активними, ця клітина перемикається до передбачувального стану в очікуванні одного або декількох наступних входів послідовності.
Вихід мініколонки
Вихід шару включає мініколонки як в активному, так і в передбачувальному станах. Таким чином, мініколонки є активними протягом довгих періодів часу, що веде до вищої часової стабільності, яку бачить батьківський шар.
Висновування та інтерактивне навчання
Кортикальні алгоритми навчання є здатними навчатися безперервно з кожного нового входового образу, відтак потреби в окремому режимі висновування немає. Під час висновування ІЧП намагається співставляти потік входів з фрагментами попередньо навчених послідовностей. Це дозволяє кожному шарові ІЧП постійно передбачувати правдоподібне продовження розпізнаних послідовностей. Виходом шару є індекс передбаченої послідовності. Оскільки передбачення є схильними змінюватися не так часто, як входові образи, це веде до підвищення часової стабільності виходу у вищих рівнях ієрархії. Передбачування також дозволяє заповнювати пропущені образи в послідовності, та інтерпретувати неоднозначні дані шляхом схиляння системи до передбачуваного висновку.
Застосування КАН
Numenta наразі пропонує кортикальні алгоритми навчання як комерційне програмне забезпечення як послугу (таке як Grok[9]).
Чинність КАН
У вересні 2011 року Джеффові Гокінсу було поставлено таке питання стосовно кортикальних алгоритмів навчання: «Як ви дізнає́теся, чи є зміни, що ви вносите до моделі, добрими, чи ні?» На що Джеффовою відповіддю було «Є дві категорії для цієї відповіді: однією є дивитися на нейронауку, а іншою є методи для машинного інтелекту. В царині нейронауки існує багато передбачень, які ми можемо робити, і їх можливо перевірити. Якщо наші теорії описують широкий спектр спостережень нейронауки, то це каже нам, що ми перебуваємо на правильному шляху. У світі машинного навчання їх це не хвилює, їх хвилює лише те, наскільки добре воно працює на практичних задачах. В нашому випадку це ще треба побачити. Наскільки ви зможете розв'язувати задачі, які ніхто раніше не був здатним розв'язувати, настільки люди це відмітять.»[10]
Третє покоління: сенсо́рно-моторне висновування
Третє покоління будується на другому поколінні, увінчуючи його теорією сенсорно-моторного висновування в новій корі.[11][12] Ця теорія передбачає, що кортикальні колонки на кожному з рівнів ієрархії можуть навчатися цілісних моделей об'єктів у часі, й що вони навчаються ознак у певних місцях об'єктів. 2018 року цю теорію було розширено, і названо Теорією тисячі мізків (англ. Thousand Brains Theory).[13]
Порівняння моделей нейронів
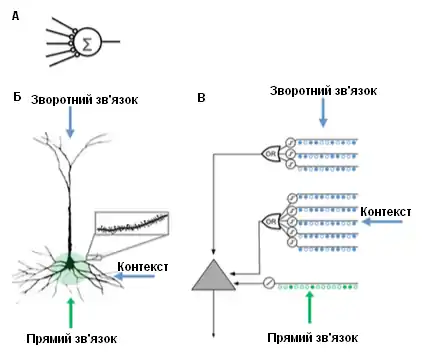
Порівняння моделей нейронів Штучна нейронна мережа (ШНМ) Пірамідний нейрон нової кори (біологічний нейрон) Нейрон моделі ІЧП[8] - Декілька синапсів
- Відсутність дендритів
- Підсумовує входи × ваги
- Навчається, змінюючи ваги синапсів
- Тисячі синапсів на дендритах
- Активні дендрити: клітина розпізнає сотні унікальних образів
- Спільне активування набору синапсів дендритного сегменту призводить до NMDA-спайку[прояснити: ком.] та деполяризації[прояснити: ком.] в сомі
- Джерела входу до клітини:
- Входи прямого зв'язку, які формують синапси проксимально до соми та безпосередньо призводять до потенціалу дії
- NMDA-спайки, породжувані більш дистально базально[прояснити: ком.]
- Апікальні дендрити, що деполяризують сому (зазвичай не достатньо для того, щоби створити соматичний потенціал дії)
- Навчається вирощуванням нових синапсів
- Натхнений пірамідними клітинами в шарах 2/3 та 5 нової кори
- Тисячі синапсів
- Активні дендрити: клітина розпізнає сотні унікальних образів
- Моделює дендрити та NMDA-спайки, так що кожен масив відповідних детекторів має набір синапсів
- Навчається моделюванням росту нових синапсів
Порівняння ІЧП та нової кори
ІЧП намагається втілити функціональність, що є характерною для ієрархічно пов'язаної групи областей нової кори. Область (англ. region) нової кори відповідає одному чи більше рівням (англ. levels) в ієрархії ІЧП, тоді як гіпокамп є віддалено подібним до найвищого рівня ІЧП. Один вузол ІЧП може представляти групу кортикальних колонок в межах певної області.
Хоч вона і є головно функціональною моделлю, було здійснено кілька спроб поставити алгоритми ІЧП у відповідність зі структурою нейронних зв'язків у шарах нової кори.[14][15] Організація нової кори являє собою вертикальні колонки з 6 горизонтальних шарів (англ. layers). Ці 6 шарів клітин у новій корі не слід плутати з рівнями ієрархії ІЧП.
Вузли ІЧП намагаються моделювати частину кортикальних колонок (від 80 до 100 нейронів) із приблизно 20 «клітинами» ІЧП на колонку. ІЧП моделюють лише шари 2 та 3, щоби виявляти просторові та часові ознаки входу, з 1 клітиною на колонку в шарі 2 для просторового «агрегування», й від 1 до 2 дюжин на колонку в шарі 3 для часового агрегування. Ключовою для ІЧП та кори є їхня здатність обходитися з шумом та варіативністю у вході, яка є результатом використання «розрідженого розподіленого подання», в якому в кожен момент часу є активними лише близько 2% колонок.
ІЧП намагається моделювати частину процесу навчання та пластичності кори, як описано вище. До відмінностей між ІЧП та нейронами належать:[16]
- строго двійкові сигнали та синапси
- відсутність прямого пригнічування синапсів та дендритів (але імітованого опосередкованого)
- наразі моделює лише шари 2/3 та 4 (не 5 та 6)
- відсутність «моторного» керування (шар 5)
- відсутність зворотного зв'язку між областями (від рівня 6 вищої до рівня 1 нижчої)
Розріджені розподілені подання
Інтегрування компоненти пам'яті з нейронними мережами має довгу історію, що сягає ранніх досліджень у розподілених поданнях[17][18] та самоорганізаційних відображеннях. Наприклад, у розрідженій розподіленій пам'яті (англ. sparse distributed memory, SDM) образи, кодовані нейронними мережами, використовують як адреси для асоціативної пам'яті, де «нейрони» по суті слугують кодувальниками та декодувальниками адреси.[19][20]
Комп'ютери зберігають інформацію у щільних (англ. dense) поданнях, таких як 32-бітове слово, в якому є можливими всі комбінації одиниць та нулів. На відміну від цього, мозок використовує розріджені розподілені подання (РРП, англ. sparse distributed representations, SDR).[21] Людська нова кора має приблизно 16 мільярдів нейронів, але в кожен момент часу активним є лише невеликий відсоток. Активності нейронів подібні до бітів у комп'ютері, тож це подання є розрідженим. Подібно до розрідженої розподіленої пам'яті, розробленої НАСА у 80-х роках,[19] та векторно-просторових моделей, що використовують у латентно-семантичному аналізі, ІЧП використовує розріджені розподілені подання.[22]
РРП, що використовують в ІЧП, є двійковими поданнями даних, що складаються з багатьох бітів, серед яких активним (одиниці) є лише невеликий відсоток. Типове втілення може мати 2048 колонок та 64 000 штучних нейронів, де лише 40 можуть бути активними одночасно. І хоча залишатися «невикористаними» для більшості бітів у будь-якому взятому поданні може видаватися менш ефективним, РРП мають дві важливі переваги над традиційними щільними поданнями. По-перше, РРП є стійкими до спотворення та неоднозначності через те, що сенс подання розподіляється (розподіленість) на невеликий відсоток (розрідженість) активних бітів. У щільному поданні перекидання єдиного біту повністю змінює сенс, тоді як в РРП один біт може не мати значного впливу на загальний сенс. Це веде до другої переваги РРП: оскільки сенс подання розподілено на всі активні біти, подібність між двома поданнями можливо використовувати як міру семантичної подібності об'єктів, що вони подають. Тобто, якщо два вектори в РРП мають одиниці в одній і тій же позиції, то вони є семантично подібними за цією властивістю. Біти в РРП мають семантичний сенс, і цей сенс розподілено між цими бітами.[22]
На цих властивостях РРП ґрунтується теорія семантичного згортання,[23] щоби запропонувати нову модель для мовної семантики, де слова кодують їхніми РРП, і подібність між термінами, реченнями та текстами можливо обчислювати за допомогою простих мір відстані.
Подібність до інших моделей
Баєсові мережі
Подібно до баєсової мережі, ІЧП складається з набору вузлів, впорядкованих у деревну ієрархію. Кожен вузол в цій ієрархії виявляє масив причин в отримуваних ним входових шаблонах та часових послідовностях. Для прямого та зворотного поширення переконань від дочірніх до батьківських вузлів і назад використовують баєсів алгоритм перегляду переконань. Проте аналогія з баєсовими мережами є обмеженою, оскільки ІЧП можуть бути самотренованими (таким чином, що кожен з вузлів має однозначні родинні зв'язки), управляються з даними, залежними від часу, та надають механізми для прихованої уваги.
Тай Сін Лі (англ. Таі Sing Lee) та Девід Мамфорд раніше були запропонували теорію ієрархічного кортикального обчислення на основі баєсового поширення переконання.[24] І хоча ІЧП здебільшого відповідає цим ідеям, вона додає подробиці стосовно обробки інваріантних подань у зоровій корі.[25]
Нейронні мережі
Як і будь-яку систему, яка моделює деталі нової кори, ІЧП можливо розглядати як штучну нейронну мережу. Деревна ієрархія, зазвичай використовувана в ІЧП, нагадує звичну топологію традиційних нейронних мереж. ІЧП намагаються моделювати кортикальні колонки (від 80 до 100 нейронів) та їхні взаємодії меншою кількістю «нейронів» ІЧП. Метою нинішніх ІЧП є охопити якомога більше функцій нейронів та мережі (як їх наразі розуміють) в межах можливостей типових комп'ютерів та в областях, які можливо легко зробити корисними, таких як обробка зображень. Наприклад, спроб зворотного зв'язку від вищих рівнів та моторного керування не роблять через те, що наразі не зрозуміло, як їх вбудувати, а замість мінливих синапсів використовують двійкові, оскільки було визначено, що в поточних можливостях ІЧП вони є достатніми.
LAMINART та подібні мережі, які досліджує Стівен Гросберг, намагаються моделювати як інфраструктуру кори, так і поведінку нейронів у часовій системі, щоби пояснити нейрофізіологічні та психофізичні дані. Проте ці мережі наразі є занадто складними для реалістичного застосування.[26]
ІЧП є також пов'язаною з працею Томасо Поджо, включно з підходом до моделювання вентрального потоку зорової кори, відомим як HMAX. Подібності ІЧП до різних ідей ШІ описано в грудневому випуску 2005 року журналу «Artificial Intelligence».[27]
Неокогнітрон
Неокогнітрон, ієрархічна багатошарова нейронна мережа, запропонована професором Куніхіко Фукусімою 1987 року, є однією з перших моделей нейронних мереж глибинного навчання.[28]
Платформа та розробницькі інструменти NuPIC
Numenta Platform for Intelligent Computing (NuPIC) є одним із декількох доступних втілень ІЧП. Деякі забезпечує компанія Numenta, тоді як деякі розробляє та підтримує спільнота ІЧП з відкритим кодом.
NuPIC включає втілення просторового агрегування та часової пам'яті як мовою C++, так і мовою Python. Вона також включає 3 ППІ. Користувачі можуть будувати системи ІЧП, використовуючи прямі втілення цих алгоритмів, або будуючи мережу із застосуванням мережного ППІ, що є гнучкою системою для побудови складних залежностей між різними рівнями кори.
NuPIC 1.0 було випущено в липні 2017 року, після чого базу коду було переведено до режиму підтримування. Поточні дослідження продовжуються в дослідницьких базах коду Numenta.
Застосування
Існують наступні комерційні застосунки з використанням NuPIC:
- Grok — виявляння аномалій для серверів ІТ, див. www.grokstream.com
- Cortical.io — розвинена обробка природної мови, див. www.cortical.io
На NuPIC є доступними такі інструменти:
- HTM Studio — знаходить аномалії в часових рядах з використанням ваших власних даних, див. numenta.com/htm-studio/
- Numenta Anomaly Benchmark — порівнюйте ІЧП-аномалії з іншими методиками виявляння аномалій, див. numenta.com/numenta-anomaly-benchmark/
На NuPIC є доступними наступні приклади застосунків, див. numenta.com/applications/:
- HTM for stocks — приклад відстежування аномалій у ринку цінних паперів (приклад коду)
- Rogue behavior detection — приклад шукання аномалій в людській поведінці (довідка та приклад коду)
- Geospatial tracking — приклад шукання аномалій в русі цілей простором та часом (довідка та приклад коду)
Див. також
- Неокогнітрон
- Глибинне навчання
- Згорткова нейронна мережа
- Сильний ШІ
- Штучна свідомість
- Когнітивна архітектура
- «Про інтелект»
- Система пам'яті—передбачування
- Перегляд переконань
- Поширення переконання
- Біоніка
- Перелік проєктів штучного інтелекту
- Мережа пам'яті
- Нейронна машина Тюрінга
- Теорія множинних слідів
Пов'язані моделі
- Ієрархічна прихована марковська модель
- Баєсова мережа
- Нейронні мережі
Примітки
- Cui, Yuwei; Ahmad, Subutai; Hawkins, Jeff (2016). Continuous Online Sequence Learning with an Unsupervised Neural Network Model. Neural Computation 28 (11): 2474–2504. PMID 27626963. arXiv:1512.05463. doi:10.1162/NECO_a_00893. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Ahmad, Subutai; Lavin, Alexander; Purdy, Scott; Agha, Zuha (2017). Unsupervised real-time anomaly detection for streaming data. Neurocomputing 262: 134–147. doi:10.1016/j.neucom.2017.04.070. Проігноровано невідомий параметр
|doi-access=(довідка) (англ.) - Preliminary details about new theory work on sensory-motor inference. HTM Forum (англ.). 3 червня 2016. (англ.)
- HTM Retrospective на YouTube (англ.)
- Numenta old documentation. numenta.com. Архів оригіналу за 27 травня 2009. (англ.)
- Jeff Hawkins lecture describing cortical learning algorithms на YouTube (англ.)
- Cui, Yuwei; Ahmad, Subutai; Hawkins, Jeff (2017). The HTM Spatial Pooler—A Neocortical Algorithm for Online Sparse Distributed Coding. Frontiers in Computational Neuroscience 11: 111. PMC 5712570. PMID 29238299. doi:10.3389/fncom.2017.00111. (англ.)
- Hawkins, Jeff; Ahmad, Subutai (30 березня 2016). Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex. Front. Neural Circuits 10: 23. PMC 4811948. PMID 27065813. doi:10.3389/fncir.2016.00023. (англ.)
- Grok Product Page. grokstream.com. (англ.)
- Laserson, Jonathan (September 2011). From Neural Networks to Deep Learning: Zeroing in on the Human Brain. XRDS 18 (1). doi:10.1145/2000775.2000787. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Hawkins, Jeff; Ahmad, Subutai; Cui, Yuwei (2017). A Theory of How Columns in the Neocortex Enable Learning the Structure of the World. Frontiers in Neural Circuits 11: 81. PMC 5661005. PMID 29118696. doi:10.3389/fncir.2017.00081. (англ.)
- Have We Missed Half of What the Neocortex Does? Allocentric Location as the Basis of Perception на YouTube (англ.)
- Numenta publishes breakthrough theory for intelligence and cortical computation. eurekalert.org. 14 січня 2019. (англ.)
- Hawkins, Jeff; Blakeslee, Sandra. On Intelligence. (англ.) (рос.)
- George, Dileep; Hawkins, Jeff (2009). Towards a Mathematical Theory of Cortical Micro-circuits. PLOS Computational Biology 5 (10): e1000532. Bibcode:2009PLSCB...5E0532G. PMC 2749218. PMID 19816557. doi:10.1371/journal.pcbi.1000532. Проігноровано невідомий параметр
|doi-access=(довідка) (англ.) - HTM Cortical Learning Algorithms. numenta.org. (англ.)
- Hinton, Geoffrey E. (1984). Distributed representations. Архів оригіналу за 14 листопада 2017. (англ.)
- Plate, Tony (1991). Holographic Reduced Representations: Convolution Algebra for Compositional Distributed Representations. IJCAI. (англ.)
- Kanerva, Pentti (1988). Sparse distributed memory. MIT press. (англ.)
- Snaider, Javier; Franklin, Stan (2012). Integer sparse distributed memory Twenty-fifth international flairs conference. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Olshausen, Bruno A.; Field, David J. (1997). Sparse coding with an overcomplete basis set: A strategy employed by V1?. Vision Research 37 (23): 3311–3325. PMID 9425546. doi:10.1016/S0042-6989(97)00169-7. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Ahmad, Subutai; Hawkins, Jeff (2016). «Numenta NUPIC – sparse distributed representations». arXiv:1601.00720 [q-bio.NC]. (англ.)
- De Sousa Webber, Francisco (2015). «Semantic Folding Theory And its Application in Semantic Fingerprinting». arXiv:1511.08855 [cs.AI]. (англ.)
- Lee, Tai Sing; Mumford, David (2002). Hierarchical Bayesian Inference in the Visual Cortex. Journal of the Optical Society of America. A, Optics, Image Science, and Vision 20 (7): 1434–48. PMID 12868647. doi:10.1364/josaa.20.001434. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - George, Dileep (24 липня 2010). Hierarchical Bayesian inference in the visual cortex. dileepgeorge.com. Архів оригіналу за 1 серпня 2019. (англ.)
- Grossberg, Stephen (2007). У Cisek, Paul; Drew, Trevor; Kalaska, John. Towards a unified theory of neocortex: Laminar cortical circuits for vision and cognition. Technical Report CAS/CNS-TR-2006-008. For Computational Neuroscience: From Neurons to Theory and Back Again. Amsterdam: Elsevier. с. 79–104. Архів оригіналу за 29 серпня 2017. (англ.)
- ScienceDirect – Artificial Intelligence 169 (2). December 2005. с. 103–212. (англ.)
- Fukushima, Kunihiko (2007). Neocognitron. Scholarpedia 2 (1): 1717. Bibcode:2007SchpJ...2.1717F. doi:10.4249/scholarpedia.1717. Проігноровано невідомий параметр
|doi-access=(довідка) (англ.)
Посилання
Офіційні
- Cortical Learning Algorithm overview (Accessed May 2013) (англ.)
- HTM Cortical Learning Algorithms (PDF Sept. 2011) (англ.)
- Numenta, Inc. (англ.)
- HTM Cortical Learning Algorithms Archive (англ.)
- Association for Computing Machinery talk from 2009 by Subutai Ahmad from Numenta (англ.)
- OnIntelligence.org Forum, веб-форум для обговорення відповідних тем, особливо відповідним є форум Models and Simulation Topics. (англ.)
- Hierarchical Temporal Memory (презентація Microsoft PowerPoint) (англ.)
- Cortical Learning Algorithm Tutorial: CLA Basics, розмова на YouTube про кортикальний алгоритм навчання (КАН, англ. cortical learning algorithm, CLA), що використовує модель ІЧП (англ.)
Інші
- Pattern Recognition by Hierarchical Temporal Memory by Davide Maltoni, April 13, 2011 (англ.)
- Vicarious Startup rooted in HTM by Dileep George (англ.)
- The Gartner Fellows: Jeff Hawkins Interview by Tom Austin, Gartner, March 2, 2006 (англ.)
- Emerging Tech: Jeff Hawkins reinvents artificial intelligence by Debra D'Agostino and Edward H. Baker, CIO Insight, May 1, 2006 (англ.)
- "Putting your brain on a microchip" by Stefanie Olsen, CNET News.com, May 12, 2006 (англ.)
- "The Thinking Machine" by Evan Ratliff, Wired, March 2007 (англ.)
- Think like a human by Jeff Hawkins, IEEE Spectrum, April 2007 (англ.)
- Neocortex – Memory-Prediction Framework — відкрите втілення з ліцензією GNU General Public License (англ.)
- Hierarchical Temporal Memory related Papers and Books (англ.)