OPTICS
OPTICS (англ. Ordering points to identify the clustering structure) — алгоритм знаходження кластерів у просторових даних на основі щільності. Він був представлений Міхаелем Анкерстом, Маркусом Брюінгом, Хансом Крігелем і Йоргом Сандером.[1] Його основна ідея схожа на DBSCAN,[2] але він вирішує одну з основних слабостей DBSCAN: проблему визначення значущих кластерів в наборах даних різної щільності. Для цього об'єкти бази даних повинні бути впорядковані(за лін. час) так, що об'єкти, які просторово близькі, будуть сусідами в упорядкуванні. Крім того, особлива відстань зберігається для кожної точки, яка являє собою щільність, яка повинна бути прийнятна для кластера, щоб мати обидві сусідні точки належали до тієї ж групи. Як це представлено в дендрограмі.
Ідея
Як і DBSCAN, OPTICS вимагає двох параметрів: , що є максимальною відстанню (радіусом) і , що показує мінімальну кількість об'єктів, необхідних для формування кластера. Точка(об'єкт) є ядром, якщо хоча б точок (об'єктів) знаходяться в межах -відстані . Всупереч DBSCAN, OPTICS також розглядає об'єкти, які є частиною більш «щільних» кластерів, так, щоб кожна точка була присвоєна основній відстані до th її найближчої точки:






Досяжність до об'єкта від об'єкта знаходиться, як відстань між і , або, як основна відстань від :



Якщо і є найближчими сусідами, тобто ми повинні припускати, що і належать до одного кластеру.

Обидва значення основної відстані і досяжності є невідомими, якщо недоступний кластер достатньої щільності (w.r.t. ). Якщо взяти велике значення , то цього не станеться, проте тоді кожен запит -сусідів може повертати навіть всю базу даних, що приведе до складності виконання . Отже, параметр потрібно вибрати, враховуючи щільність кластерів, які не представляють інтересу, щоб пришвидшити час виконання алгоритму.

Строго кажучи, параметр не є необхідним. Він можу бути просто встановленим максимально можливого значення.
Псевдокод
Базова реалізація OPTICS схожа до реалізації DBSCAN, але використовується не множина відомих, але не кластеризованих даних, a черга з пріоритетом (з використанням індексації heap) .
OPTICS(DB, eps, MinPts)
for each point p of DB
p.reachability-distance = UNDEFINED
for each unprocessed point p of DB
N = getNeighbors(p, eps)
mark p as processed
output p to the ordered list
if (core-distance(p, eps, Minpts) != UNDEFINED)
Seeds = empty priority queue
update(N, p, Seeds, eps, Minpts)
for each next q in Seeds
N' = getNeighbors(q, eps)
mark q as processed
output q to the ordered list
if (core-distance(q, eps, Minpts) != UNDEFINED)
update(N', q, Seeds, eps, Minpts)
В update(), черга з пріоритетом Seeds заповнена -сусідами і , відповідно:

update(N, p, Seeds, eps, Minpts)
coredist = core-distance(p, eps, MinPts)
for each o in N
if (o is not processed)
new-reach-dist = max(coredist, dist(p,o))
if (o.reachability-distance == UNDEFINED) // o is not in Seeds
o.reachability-distance = new-reach-dist
Seeds.insert(o, new-reach-dist)
else // o in Seeds, check for improvement
if (new-reach-dist < o.reachability-distance)
o.reachability-distance = new-reach-dist
Seeds.move-up(o, new-reach-dist)
Отже, OPTICS видає об'єкти(точки) в певному порядку, анотованих з їх найменшою досяжністю (в оригінальному алгоритмі, основна відстань теж враховується, але це не потрібно для подальшої обробки).
Визначення кластерів
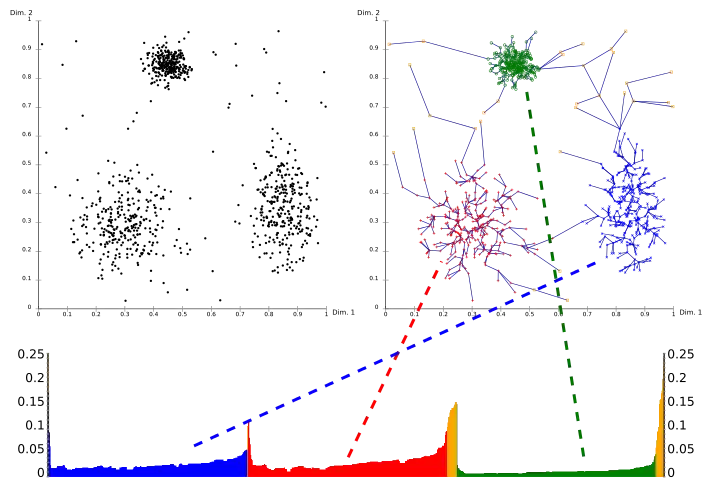
Використовуючи графік досяжності (спеціальний вид дендрограми), легко отримати ієрархічну структуру кластерів. Це 2D графік, з упорядкуванням точок, оброблених OPTICS на осі Ох, а відстань досяжності на осі Oy. Так, як точки, що належать до одного кластера мають низьку досяжність для найближчих сусідів, кластери показують ділянки досяжності. Чим глибша ділянка, тим щільніший кластер.
Зображення вище ілюструє цю концепцію. У верхній лівій частині, показано штучний набір даних. Верхня права частина візуалізує сполучне дерево, створене за допомогою OPTICS, і нижня частина показує ділянку досяжності, обчислену OPTICS. Виявлення кластерів з допомогою цього графіку може бути зроблене вручну, вибравши діапазон на осі Ох після візуального огляду, вибравши поріг на осі Оу (результат буде схожий на результат DBSCAN кластеризації з тимb ж і minPts параметри, тут значення 0,1 може дати добрі результати), або за допомогою різних алгоритмів, які намагаються виявити ділянки, використовуючи крутизну, виявлення коліна або локальні максимуми. Кластери, отримані таким чином можуть мати ієрархічну структуру, чого не може бути досягнуто за допомогою DBSCAN.
Складність
OPTICS проходить кожну точку один раз, при цьому вираховує -найближчих сусідів для кожної. Враховуючи використання просторового індексу, що повертає запит на сусідів в час runtime, загальна складність алгоритму буде .Автори оригінального OPTICS повідомили, що фактичний константний коефіцієнт уповільнення буде 1.6 в порівнянні з DBSCAN. Варто зауважити, що може мати великий вплив на час виконання алгоритму, бо його велике значення може збільшувати складність запиту на найближчих сусідів до лінійної.


Вибір (більшим, ніж максимальна відстань між даними в наборі даних) is але приведе до квадратичної складності алгоритму. Ось, чому потрібно вибирати під кожен набір даних окремо.

Розширення
•OPTICS-OF[3] це алгоритм визначення аномалій, який базується на OPTICS. Це знаходження викидів в даному алгоритмі OPTICS, з затратами меншими, ніж за допомогою інших алгоритмів виявлення аномалій.
•DeLi-Clu,[4] (англ. Density-Link-Clustering) поєднує ідею single-linkage clustering і OPTICS, усуваючи параметр , покращуючи час виконання OPTICS.
•HiSC[5] метод ієрархічної кластеризації підпростору (паралельно осі), на основі OPTICS.
•HiCO[6]
•DiSH[7] — це покращення HiSC, з допомогою якого можна знаходити складніші ієрархії.
•FOPTICS[8] — це швидша реалізація з використанням випадкових проекцій.
Реалізація
Реалізація OPTICS, OPTICS-OF, DeLi-Clu, HiSC, HiCO і DiSH доступна в фреймворку ELKI(з підтримкою індексів) . Також, неповна і повільна імплементація доступна в розширеннях Weka.MRCангл. The National Institute for Medical Research забезпечує C reimplementation of OPTICS без підтримки індексів.
Посилання
- Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander (1999). OPTICS: Ordering Points To Identify the Clustering Structure ACM SIGMOD international conference on Management of data. ACM Press. с. 49–60.
- Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu (1996). У Evangelos Simoudis, Jiawei Han, Usama M. Fayyad. A density-based algorithm for discovering clusters in large spatial databases with noise Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). AAAI Press. с. 226–231. ISBN 1-57735-004-9.
- Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng and Jörg Sander (1999). OPTICS-OF: Identifying Local Outliers. Principles of Data Mining and Knowledge Discovery. Springer-Verlag. с. 262–270. ISBN 978-3-540-66490-1. doi:10.1007/b72280.
- DOI:10.1007/11731139_16
Нема шаблону {{Cite doi/10.1007/11731139_16}}.заповнити вручну - DOI:10.1007/11871637_42
Нема шаблону {{Cite doi/10.1007/11871637_42}}.заповнити вручну - DOI:10.1109/SSDBM.2006.35
Нема шаблону {{Cite doi/10.1109/SSDBM.2006.35}}.заповнити вручну - DOI:10.1007/978-3-540-71703-4_15
Нема шаблону {{Cite doi/10.1007/978-3-540-71703-4_15}}.заповнити вручну - DOI:10.1145/2505515.2505590
Нема шаблону {{Cite doi/10.1145/2505515.2505590}}.заповнити вручну
