Кластеризація методом к–середніх
Кластериза́ція ме́тодом k-сере́дніх (англ. k-means clustering) — популярний метод кластеризації, — впорядкування множини об'єктів в порівняно однорідні групи. Винайдений в 1950-х роках математиком Гуґо Штайнгаузом[1] і майже одночасно Стюартом Ллойдом[2]. Особливу популярність отримав після виходу роботи МакКвіна[3].
Мета методу — розділити n спостережень на k кластерів, так щоб кожне спостереження належало до кластера з найближчим до нього середнім значенням. Метод базується на мінімізації суми квадратів відстаней між кожним спостереженням та центром його кластера, тобто функції
- ,

де d — метрика, — і-ий об'єкт даних, а — центр кластера, якому на j-ій ітерації приписаний елемент .


Історія
Термін «k-середніх» був уперше вжитий Джеймсом МакКвіном (англ. James MacQueen) у 1967 році[3], хоча ідею методу вперше озвучив Гуґо Штайнгауз (англ. Hugo Steinhaus) у 1957 році[1]. Стандартний алгоритм був вперше запропонований Стюартом Лойдом (англ. Stuart Lloyd) у 1957 р[2].
Алгоритм
Опис алгоритму
Маємо масив спостережень (об'єктів), кожен з яких має певні значення по ряду ознак. Відповідно до цих значень об'єкт розташовується у багатовимірному просторі.
- Дослідник визначає кількість кластерів, що необхідно утворити
- Випадковим чином обирається k спостережень, які на цьому кроці вважаються центрами кластерів
- Кожне спостереження «приписується» до одного з n кластерів — того, відстань до якого найкоротша
- Розраховується новий центр кожного кластера як елемент, ознаки якого розраховуються як середнє арифметичне ознак об'єктів, що входять у цей кластер
- Відбувається така кількість ітерацій (повторюються кроки 3-4), поки кластерні центри стануть стійкими (тобто при кожній ітерації в кожному кластері опинятимуться одні й ті самі об'єкти), дисперсія всередині кластера буде мінімізована, а між кластерами — максимізована
Вибір кількості кластерів відбувається на основі дослідницької гіпотези. Якщо її немає, то рекомендують створити 2 кластери, далі 3,4,5, порівнюючи отримані результати.
- Демонстрація алгоритму
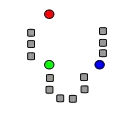 1. k початкових «середніх» (тут k=3) випадково згенеровані у межах домени даних (кольорові).
1. k початкових «середніх» (тут k=3) випадково згенеровані у межах домени даних (кольорові).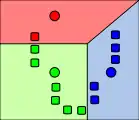 2. створено k кластерів, асоціюючи кожне спостереження з найближчим середнім. Розбиття відбувається згідно з діаграмою Вороного утвореною середніми.
2. створено k кластерів, асоціюючи кожне спостереження з найближчим середнім. Розбиття відбувається згідно з діаграмою Вороного утвореною середніми. 3. Центроїд кожного з k кластерів стає новим середнім.
3. Центроїд кожного з k кластерів стає новим середнім.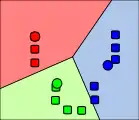 4. Кроки 2 і 3 повторюються до досягнення збіжності.
4. Кроки 2 і 3 повторюються до досягнення збіжності.
Принцип дії
Принцип алгоритму полягає в пошуку таких центрів кластерів та наборів елементів кожного кластера при наявності деякої функції Ф(°), що виражає якість поточного розбиття множини на k кластерів, коли сумарне квадратичне відхилення елементів кластерів від центрів цих кластерів буде найменшим:

де — число кластерів, — отримані кластери, , — центри мас векторів .





В початковий момент роботи алгоритму довільним чином обираються центри кластерів, далі для кожного елемента множини ітеративно обраховується відстань від центрів з приєднанням кожного елемента до кластера з найближчим центром. Для кожного з отриманих кластерів обчислюються нові значення центрів, намагаючись при цьому мінімізувати функцію Ф(°), після чого повторюється процедура перерозподілу елементів між кластерами.
Алгоритм методу «Кластеризація за схемою к-середніх»:
- вибрати k інформаційних точок як центри кластерів поки не завершиться процес зміни центрів кластерів;
- зіставити кожну інформаційну точку з кластером, відстань до центра якого мінімальна;
- переконатися, що в кожному кластері міститься хоча б одна точка. Для цього кожний порожній кластер потрібно доповнити довільною точкою, що розташована «далеко» від центра кластера;
- центр кожного кластера замінити середнім від елементів кластера;
- кінець.
Переваги
Головні переваги методу k-середніх — його простота та швидкість виконання. Метод k-середніх більш зручний для кластеризації великої кількості спостережень, ніж метод ієрархічного кластерного аналізу (у якому дендограми стають перевантаженими і втрачають наочність).
Недоліки
Одним із недоліків простого методу є порушення умови зв'язності елементів одного кластера, тому розвиваються різні модифікації методу, а також його нечіткі аналоги (англ. fuzzy k-means methods), у яких на першій стадії алгоритму допускається приналежність одного елемента множини до декількох кластерів (із різним ступенем приналежності).
Незважаючи на очевидні переваги методу, він має суттєві недоліки:
- Результат класифікації сильно залежить від випадкових початкових позицій кластерних центрів
- Алгоритм чутливий до викидів, які можуть викривлювати середнє
- Кількість кластерів повинна бути заздалегідь визначена дослідником
Застосування
Метод k-середніх є доволі простим і прозорим, тому успішно використовується у різноманітних сферах — маркетингових сегментаціях, геостатистиці, астрономії, сільському господарстві тощо.
Примітки
- Steinhaus, Hugo. (1957). Sur la division des corps matériels en parties (in French). Bull. Acad. Polon. Sci. 4 (12): 801–804.
- Lloyd., S. P. (1957). Least square quantization in PCM". Bell Telephone Laboratories Paper.
- Some Methods for classification and Analysis of Multivariate Observations". Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. University of California Press. pp. 281–297. Архів оригіналу за 23 жовтня 2015. Процитовано 16 квітня 2019.
Посилання
- Clustering
- Чисельний приклад кластеризаці методом к-середніх
- Image Segmentation (k-clusters method)
- Журнал «Комп'ютерна графіка та мультимедіа»